ФуецЕФСЫНт defer Т№
ЩЯвЛЦЊЮФеТЮвУЧжївЊДгЪЙгУЕФНЧЖШНщЩмСЫ defer ЕФЛљДЁжЊЪЖЃЌБОЮФЮвУЧРДЗжЮівЛЯТ defer ЕФЪЕЯжЛњжЦЁЃ
ЛЙЪЧДгвЛИіР§згГЬађПЊЪМЁЃ
package mainimport "fmt"func sum(a, b int) {c := a + bfmt.Println("sum:" , c)
}func f(a, b int) {defer sum(a, b)fmt.Printf("a: %d, b: %d\n", a, b)
}func main() {a, b := 1, 2f(a, b)
}
ДгЧАвЛЦЊЮФеТЮвУЧЕУжЊЃЌБрвыЦїЛсАб defer гяОфЗвыГЩЖд deferproc КЏЪ§ЕФЕїгУЃЌЭЌЪБЃЌБрвыЦївВЛсдкЪЙгУСЫ defer гяОфЕФ go КЏЪ§ЕФФЉЮВВхШыЖд deferreturn КЏЪ§ЕФЕїгУЃЌЯТУцЮвУЧРДПДвЛЯТетСНИіКЏЪ§ЕФЪЕЯжДњТыЁЃ
ЙизЂЮв code дгЬГЃЌСЫНтИќЖр......
deferproc КЏЪ§
ЯШРДПДПД deferproc ЕФКЏЪ§даЭЃК
runtime/panic.go : 89
// Create a new deferred function fn with siz bytes of arguments. // The compiler turns a defer statement into a call to this. //go:nosplit func deferproc(siz int32, fn *funcval)
deferproc КЏЪ§ЕФЕквЛИіВЮЪ§ siz ЪЧ defered КЏЪ§ЃЈБШШчБОР§жаЕФ sum КЏЪ§ЃЉЕФВЮЪ§вдзжНкЮЊЕЅЮЛЕФДѓаЁЃЌЕкЖўИіВЮЪ§ funcval ЪЧвЛИіБфГЄНсЙЙЬхЃК
proc/runtime2.go : 139
type funcval struct {fn uintptr// variable-size, fn-specific data here
}
гкЪЧЃЌдк64ЮЛЯЕЭГжаБОЮФР§згжаЕФ defer sum(a, b) ДѓжТЕШМлгк
deferproc(16, &funcval{sum})
вђЮЊ sum КЏЪ§га 2 Иі int аЭЕФВЮЪ§ЙВ 16 зжНкЃЌЫљвддкЕїгУ deferproc КЏЪ§ЪБЕквЛИіВЮЪ§ЮЊ16ЃЌЕкЖўИіВЮЪ§ funcval НсЙЙЬхЖдЯѓЕФ fn ГЩдБЮЊ sum КЏЪ§ЕФЕижЗЁЃЮвУЧПЩвдЯШЯывЛЯТЮЊЪВУДашвЊАб sum КЏЪ§ЕФВЮЪ§ДѓаЁДЋЕнИј deferproc() КЏЪ§ЃПСэЭтЮЊЪВУДУЛПДЕН sum КЏЪ§ашвЊЕФСНИіВЮЪ§ФиЃП
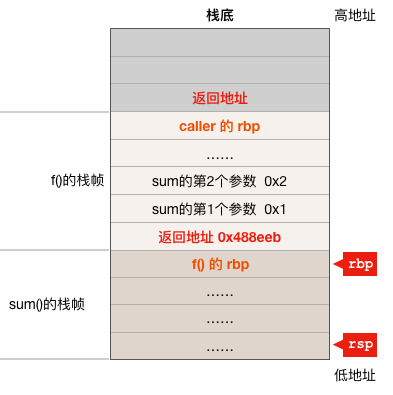
ЮЊСЫИуЧхГўБрвыЦїЕНЕзЛсдѕУДЗвы defer ЙиМќзжЃЌЮвУЧашвЊПДвЛЯТ f() КЏЪ§ЕФЛуБрДњТыЃК
0x0000000000488de0 <+0>: mov %fs:0xfffffffffffffff8,%rcx 0x0000000000488de9 <+9>: cmp 0x10(%rcx),%rsp 0x0000000000488ded <+13>: jbe 0x488f10 <main.f+304> 0x0000000000488df3 <+19>: sub $0x80,%rsp 0x0000000000488dfa <+26>: mov %rbp,0x78(%rsp) 0x0000000000488dff <+31>: lea 0x78(%rsp),%rbp # етвЛЬѕжИСювдМАЧАУцМИЬѕжИСюЪЧКЏЪ§ађбдЃЌИњdeferЮоЙи 0x0000000000488e04 <+36>: movl $0x10,(%rsp) # deferprocЕФЕквЛИіВЮЪ§siz 0x0000000000488e0b <+43>: lea 0x39076(%rip),%rax 0x0000000000488e12 <+50>: mov %rax,0x8(%rsp) # ЕкЖўИіВЮЪ§funcvalНсЙЙЬхЖдЯѓЕФЕижЗ 0x0000000000488e17 <+55>: mov 0x88(%rsp),%rax 0x0000000000488e1f <+63>: mov %rax,0x10(%rsp) # f()КЏЪ§ЕФЕквЛИіВЮЪ§aЃЌa = 1 0x0000000000488e24 <+68>: mov 0x90(%rsp),%rcx 0x0000000000488e2c <+76>: mov %rcx,0x18(%rsp) # f()КЏЪ§ЕФЕкЖўИіВЮЪ§b, b = 2 0x0000000000488e31 <+81>: callq 0x426c00 <runtime.deferproc> # ЕїгУdeferprocКЏЪ§ # зЂвтdeferprocКЏЪ§БОРДЪЧУЛгаЗЕЛижЕЕФЃЌЯТУцЕФtestжИСюдкМьВщdeferprocЕФвўадЗЕЛижЕ # етЬѕжИСюЪЧБрвыЦїзЈУХеыЖдdeferprocКЏЪ§ЖјВхШыЕФЃЌЖдЦфЫќgoКЏЪ§ЕїгУЪББрвыЦїВЛЛсВхШыИУжИСю 0x0000000000488e36 <+86>: test %eax,%eax # ШчЙћdeferprocЗЕЛиВЛЮЊ0дђжБНгЬјзЊЕНКЏЪ§НсЮВШЅжДааdeferreturnКЏЪ§ 0x0000000000488e38 <+88>: jne 0x488efd <main.f+285> 0x0000000000488e3e <+94>: mov 0x88(%rsp),%rax ...... 0x0000000000488ee5 <+261>: callq 0x480b20 <fmt.Fprintf> #ЪфГіa bЕФжЕ 0x0000000000488eea <+266>: nop #ЕїгУdeferreturnКЏЪ§ЭъГЩЖдsumКЏЪ§ЕФбгГйЕїгУ 0x0000000000488eeb <+267>: callq 0x427490 <runtime.deferreturn> 0x0000000000488ef0 <+272>: mov 0x78(%rsp),%rbp 0x0000000000488ef5 <+277>: add $0x80,%rsp 0x0000000000488efc <+284>: retq 0x0000000000488efd <+285>: nop 0x0000000000488efe <+286>: callq 0x427490 <runtime.deferreturn> 0x0000000000488f03 <+291>: mov 0x78(%rsp),%rbp 0x0000000000488f08 <+296>: add $0x80,%rsp 0x0000000000488f0f <+303>: retq 0x0000000000488f10 <+304>: callq 0x44f300 <runtime.morestack_noctxt> #РЉеЛДІРэ 0x0000000000488f15 <+309>: jmpq 0x488de0 <main.f>
Дг f() КЏЪ§ЕФЛуБрДњТыПЩвдПДГіЃЌдкЕїгУ runtime.deferproc ЪБЃЌеЛЩЯГ§СЫБЃДцСЫ deferproc КЏЪ§ашвЊЕФСНИіВЮЪ§жЎЭтЃЌЛЙБЃДцСЫ defered КЏЪ§ЫљашвЊЕФВЮЪ§ЃЈЮвУЧетИіР§згжа defered КЏЪ§ЪЧ sum КЏЪ§ЃЌЫќЕФ2ИіВЮЪ§ a КЭ b вВЖМБЃДцдкСЫеЛЩЯЃЌЫќУЧНєСк deferproc КЏЪ§ЕФЕкЖўИіВЮЪ§ЃЉЃЌвВОЭЪЧЫЕЃЌдкжДаа defer гяОфЪБЃЌdefer КѓУцЕФКЏЪ§ЕФВЮЪ§вбОШЗЖЈСЫЁЃ
СэЭташвЊзЂвтЕФЪЧЃЌДг deferproc КЏЪ§ЕФдаЭПЩвджЊЕРЫќВЂУЛгаЗЕЛижЕЃЌЕЋЩЯУцЕФЛуБрДњТыдкЕїгУСЫ deferproc КЏЪ§жЎКѓШДМьВщСЫ rax МФДцЦїЕФжЕЪЧЗёЮЊ0(0x0000000000488e36 <+86>: test %eax,%eax)ЃЌвВОЭЪЧЫЕ deferproc КЏЪ§ЪЕМЪЩЯЛсЭЈЙ§ rax МФДцЦїЗЕЛивЛИівўадЕФЗЕЛижЕЃЁ
НгзХЮвУЧМЬајПД deferproc КЏЪ§ЕФЪЕЯж:
proc/panic.go : 89
// Create a new deferred function fn with siz bytes of arguments.
// The compiler turns a defer statement into a call to this.
//go:nosplit
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fnif getg().m.curg != getg() { //гУЛЇgoroutineВХФмЪЙгУdefer// go code on the system stack can't deferthrow("defer on system stack")}// the arguments of fn are in a perilous state. The stack map// for deferproc does not describe them. So we can't let garbage// collection or stack copying trigger until we've copied them out// to somewhere safe. The memmove below does that.// Until the copy completes, we can only call nosplit routines.// Ждgetcallersp()КЭgetcallerpc() КЏЪ§ЕФЗжЮіПЩвдВЮПМБОЙЋжкКХЕФЦфЫќЮФеТsp := getcallersp() //sp = ЕїгУdeferprocжЎЧАЕФrspМФДцЦїЕФжЕ// argpжИЯђdeferКЏЪ§ЕФЕквЛИіВЮЪ§ЃЌБОР§ЮЊsumКЏЪ§ЕФВЮЪ§aargp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)callerpc := getcallerpc() // deferprocКЏЪ§ЕФЗЕЛиЕижЗd := newdefer(siz)if d._panic != nil {throw("deferproc: d.panic != nil after newdefer")}d.fn = fn //ашвЊбгГйжДааЕФКЏЪ§d.pc = callerpc //МЧТМdeferprocКЏЪ§ЕФЗЕЛиЕижЗЃЌжївЊгУгкpanic/recoverd.sp = sp //ЕїгУdeferprocжЎЧАrspМФДцЦїЕФжЕ//АбdeferКЏЪ§ашвЊгУЕНЕФВЮЪ§ПНБДЕНdНсЙЙЬхКѓУцЃЌЯТУцЕФdeferrArgsЗЕЛиЕФЪЧвЛИіЕижЗ//deferArgs(d) = d + sizeof(d) ЃЌnewdeferЗЕЛиЕФФкДцПеМф >= deferArgs(d)switch siz {case 0:// Do nothing.case sys.PtrSize: //ШчЙћdeferedКЏЪ§ЕФВЮЪ§жЛгажИеыДѓаЁдђжБНгЭЈЙ§ИГжЕРДПНБДВЮЪ§*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))default: //ЭЈЙ§memmoveПНБДdeferedКЏЪ§ЕФВЮЪ§memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))}// deferproc returns 0 normally.// a deferred func that stops a panic// makes the deferproc return 1.// the code the compiler generates always// checks the return value and jumps to the// end of the function if deferproc returns != 0.return0() //ЭЈЙ§ЛуБржИСюЩшжУrax = 0// No code can go here - the C return register has// been set and must not be clobbered.
}
deferproc КЏЪ§СїГЬКмЧхЮњЃЌЫќЪзЯШЭЈЙ§ newdefer КЏЪ§ЗжХфвЛИі _defer НсЙЙЬхЖдЯѓЃЌШЛКѓАбашвЊбгГйжДааЕФКЏЪ§вдМАИУКЏЪ§ашвЊгУЕНЕФВЮЪ§ЁЂЕїгУ deferproc КЏЪ§ЪБЕФ rsp МФДцЦїЕФжЕвдМА deferproc КЏЪ§ЕФЗЕЛиЕижЗБЃДцдк _defer НсЙЙЬхЖдЯѓжЎжаЃЌзюКѓЭЈЙ§ return0() ЩшжУ rax МФДцЦїЕФжЕЮЊ 0 вўадЕФИјЕїгУепЗЕЛивЛИі 0 жЕЁЃ
ВЛжЊЕРДѓМвЪЧЗёЛсОѕЕУКмЦцЙжЃЌdeferproc УїУїжЛЛсвўадЕФЗЕЛи 0 жЕЃЌЕЋЮЊЪВУДЩЯУцЕФ f() КЏЪ§дкЕїгУСЫ deferproc жЎКѓЛЙгУСЫвЛЬѕжИСюРДХаЖЯЗЕЛижЕЪЧЗёЪЧ 0 ФиЃЌетВЛЖрДЫвЛОйТ№ЃПЪТЪЕЩЯетРяжївЊгы panic КЭ recover ЕФЪЕЯжЛњжЦгаЙиЃЌЕБГЬађЗЂЩњ panic жЎКѓЃЌГЬађЛсЁАдйДЮДг deferproc КЏЪ§ЗЕЛиЁБЃЌетжжЧщПіЯТЗЕЛижЕОЭВЛЪЧ 0 СЫЃЌвђЮЊ panic/recover ЛњжЦетвЛПщБШНЯИДдгЃЌЫљвдЮвУЧвдКѓЛсзЈУХаДвЛЦЊЮФеТРДЗжЮіЃЌЯждкТдЙ§ЁЃ
ЛиЕНжїЬтЃЌ_defer НсЙЙЬхЕФЖЈвхЮЊЃК
runtime/runtime2.go : 727
// A _defer holds an entry on the list of deferred calls.
// If you add a field here, add code to clear it in freedefer.
type _defer struct {siz int32 //deferКЏЪ§ЕФВЮЪ§ДѓаЁstarted boolsp uintptr // sp at time of deferpc uintptr // deferгяОфЯТвЛЬѕгяОфЕФЕижЗfn *funcval //ашвЊБЛбгГйжДааЕФКЏЪ§_panic *_panic // panic that is running deferlink *_defer //ЭЌвЛИіgoroutineЫљгаБЛбгГйжДааЕФКЏЪ§ЭЈЙ§ИУГЩдБСДдквЛЦ№аЮГЩвЛИіСДБэ
}
ИУНсЙЙжаЕФ spЁЂpcвдМА _panic ГЩдБжївЊгы panic/recover гаЙиЃЌетРяЮвУЧЮоашЙ§ЖрЙизЂЃЈ sp ГЩдБЛЙЛсБЛгУРДХаЖЯ _defer НсЙЙЬхЖдЯѓжаБЃДцЕФбгГйжДааКЏЪ§ЪЧЗёгІИУдкЕБЧАКЏЪ§НсЪјЪБжДааЃЌКѓУцЮвУЧЛсЗжЮіЕНЃЉЁЃ
ЖдгкБОЮФЕФР§згЃЌГѕЪМЛЏЭъГЩКѓЕФ _defer НсЙЙЬхЖдЯѓИїГЩдБЕФжЕДѓжТШчЯТЃК
d.siz = 16
d.started = false
d.sp = ЕїгУdeferprocКЏЪ§жЎЧАЕФrspМФДцЦїЕФжЕ
d.pc = 0x0000000000488e36
d.fn = &funcval{sum}
d._panic = nil
d._defer = nil
sumКЏЪ§ЕФВЮЪ§a
sumКЏЪ§ЕФВЮЪ§b
зЂвтЃЌdefered КЏЪ§ЕФВЮЪ§ВЂЮДдк _defer НсЙЙЬхжаЖЈвхЃЌЫќЫљашвЊЕФВЮЪ§дкФкДцжаНєИњдк _defer НсЙЙЬхЖдЯѓЕФКѓУцЁЃ
ЮвУЧНгзХПД newdefer ЪЧШчКЮЗжХф _defer НсЙЙЬхЖдЯѓЕФЃК
proc/panic.go : 205
// Allocate a Defer, usually using per-P pool.
// Each defer must be released with freedefer.
//
// This must not grow the stack because there may be a frame without
// stack map information when this is called.
//
//go:nosplit
func newdefer(siz int32) *_defer {var d *_defersc := deferclass(uintptr(siz))gp := getg() //ЛёШЁЕБЧАgoroutineЕФgНсЙЙЬхЖдЯѓif sc < uintptr(len(p{}.deferpool)) {pp := gp.m.p.ptr() //гыЕБЧАЙЄзїЯпГЬАѓЖЈЕФpif len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {// Take the slow path on the system stack so// we don't grow newdefer's stack.systemstack(func() { //ЧаЛЛЕНЯЕЭГеЛlock(&sched.deferlock)//ДгШЋОж_deferЖдЯѓГиФУвЛаЉЕНpЕФБОЕи_deferЖдЯѓГиfor len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {d := sched.deferpool[sc]sched.deferpool[sc] = d.linkd.link = nilpp.deferpool[sc] = append(pp.deferpool[sc], d)}unlock(&sched.deferlock)})}if n := len(pp.deferpool[sc]); n > 0 {d = pp.deferpool[sc][n-1]pp.deferpool[sc][n-1] = nilpp.deferpool[sc] = pp.deferpool[sc][:n-1]}}if d == nil { //ШчЙћpЕФЛКДцжаУЛгаПЩгУЕФ_deferНсЙЙЬхЖдЯѓдђДгЖбЩЯЗжХф// Allocate new defer+args.//вђЮЊroundupsizeвдМАmallocgcКЏЪ§ЖМВЛЛсДІРэРЉеЛЃЌЫљвдашвЊЧаЛЛЕНЯЕЭГеЛжДааsystemstack(func() { total := roundupsize(totaldefersize(uintptr(siz)))d = (*_defer)(mallocgc(total, deferType, true))})if debugCachedWork {// Duplicate the tail below so if there's a// crash in checkPut we can tell if d was just// allocated or came from the pool.d.siz = siz//АбаТЗжХфГіРДЕФdЗХШыЕБЧАgoroutineЕФ_deferСДБэЭЗd.link = gp._defergp._defer = dreturn d}}d.siz = siz//АбаТЗжХфГіРДЕФdЗХШыЕБЧАgoroutineЕФ_deferСДБэЭЗd.link = gp._defergp._defer = d //АбаТЗжХфГіРДЕФdЗХШыЕБЧАgoroutineЕФ_deferСДБэЭЗreturn d
}
newdefer КЏЪ§БШНЯГЄЃЌДѓМвПЩвдВЮПМЩЯУцЕФДњТыКЭзЂЪЭМгвдРэНтЁЃnewdefer КЏЪ§ЪзЯШЛсГЂЪдДггыЕБЧАЙЄзїЯпГЬАѓЖЈЕФ p ЕФ _defer ЖдЯѓГиКЭШЋОжЖдЯѓГижаЛёШЁвЛИіТњзуДѓаЁвЊЧѓ(sizeof(_defer) + sizЯђЩЯШЁећжС16ЕФБЖЪ§)ЕФ _defer НсЙЙЬхЖдЯѓЃЌШчЙћУЛгаФмЙЛТњзувЊЧѓЕФПеЯа _defer ЖдЯѓдђДгЖбЩЯЗжвЛИіЃЌзюКѓАбЗжХфЕНЕФЖдЯѓСДШыЕБЧА goroutine ЕФ _defer СДБэЕФБэЭЗЁЃ
ЕНДЫ defer гяОфжаБЛбгГйжДааЕФКЏЪ§вбОЙвШыЕБЧА goroutine ЕФ _defer СДБэЃЌЮвУЧРДМђЕЅЕФзмНсвЛЯТетИіЙ§ГЬЃК
-
БрвыЦїЛсАб go ДњТыжа defer гяОфЗвыГЩЖд deferproc КЏЪ§ЕФЕїгУЃЛ
-
deferproc КЏЪ§ЭЈЙ§ newdefer КЏЪ§ЗжХфвЛИі _defer НсЙЙЬхЖдЯѓВЂЗХШыЕБЧА goroutine ЕФ _defer СДБэЕФБэЭЗЃЛ
-
дк _defer НсЙЙЬхЖдЯѓжаБЃДцБЛбгГйжДааЕФКЏЪ§ fn ЕФЕижЗвдМА fn ЫљашЕФВЮЪ§ЃЛ
-
ЗЕЛиЕНЕїгУ deferproc ЕФКЏЪ§МЬајжДааКѓУцЕФДњТыЁЃ
deferreturn КЏЪ§
ЗжЮіЭъ deferprocЃЌЮвУЧНгзХЗжЮі deferreturnЃК
runtime/panic.go : 331
// Run a deferred function if there is one.
// The compiler inserts a call to this at the end of any
// function which calls defer.
// If there is a deferred function, this will call runtimeЁЄjmpdefer,
// which will jump to the deferred function such that it appears
// to have been called by the caller of deferreturn at the point
// just before deferreturn was called. The effect is that deferreturn
// is called again and again until there are no more deferred functions.
// Cannot split the stack because we reuse the caller's frame to
// call the deferred function.// The single argument isn't actually used - it just has its address
// taken so it can be matched against pending defers.
//go:nosplit
func deferreturn(arg0 uintptr) {gp := getg() //ЛёШЁЕБЧАgoroutineЖдгІЕФgНсЙЙЬхЖдЯѓd := gp._defer //deferКЏЪ§СДБэif d == nil { //УЛгаашвЊжДааЕФКЏЪ§жБНгЗЕЛиЃЌdeferreturnКЭdeferprocЪЧХфЖдЪЙгУЕФ//ЮЊЪВУДетРяdПЩФмЮЊnilЃПвђЮЊdeferreturnЦфЪЕЪЧвЛИіЕнЙщЕїгУЃЌетИіЪЧЕнЙщНсЪјЬѕМўжЎвЛreturn}sp := getcallersp() //ЛёШЁЕїгУdeferreturnЪБЕФеЛЖЅЮЛжУif d.sp != sp { //ЕнЙщНсЪјЬѕМўжЎЖў//ШчЙћБЃДцдк_deferЖдЯѓжаЕФspжЕгыЕїгУdeferretuenЪБЕФеЛЖЅЮЛжУВЛвЛбљЃЌжБНгЗЕЛи//вђЮЊspВЛвЛбљБэЪОdДњБэЕФЪЧдкЦфЫћКЏЪ§жаЭЈЙ§deferзЂВсЕФбгГйЕїгУКЏЪ§ЃЌБШШч://a()->b()->c()ЫќУЧЖМЭЈЙ§deferзЂВсСЫбгГйКЏЪ§ЃЌФЧУДЕБc()жДааЭъЪБжЛФмжДаадкcжазЂВсЕФКЏЪ§return}// Moving arguments around.//// Everything called after this point must be recursively// nosplit because the garbage collector won't know the form// of the arguments until the jmpdefer can flip the PC over to// fn.//АбБЃДцдк_deferЖдЯѓжаЕФfnКЏЪ§ашвЊгУЕНЕФВЮЪ§ПНБДЕНеЛЩЯЃЌзМБИЕїгУfn//зЂвтfnЕФВЮЪ§ЗХдкСЫЕїгУЕїгУепЕФеЛжЁжаЃЌЖјВЛЪЧДЫКЏЪ§ЕФеЛжЁжаswitch d.siz {case 0:// Do nothing.case sys.PtrSize:*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))default:memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))}fn := d.fnd.fn = nilgp._defer = d.link //ЪЙgp._deferжИЯђЯТвЛИі_deferНсЙЙЬхЖдЯѓ//вђЮЊашвЊЕїгУЕФКЏЪ§d.fnвбОБЃДцдкСЫfnБфСПжаЃЌЫќЕФВЮЪ§вВвбОПНБДЕНСЫеЛЩЯЃЌЫљвдЪЭЗХ_deferНсЙЙЬхЖдЯѓfreedefer(d) jmpdefer(fn, uintptr(unsafe.Pointer(&arg0))) //ЕїгУfn
}
deferreturn КЏЪ§жївЊСїГЬЮЊЃК
-
ЭЈЙ§ЕБЧА goroutine ЖдгІЕФ g НсЙЙЬхЖдЯѓЕФ _defer СДБэХаЖЯЪЧЗёгаашвЊжДааЕФ defered КЏЪ§ЃЌШчЙћУЛгаЃЈg._defer == nil Лђдђ defered КЏЪ§ВЛЪЧдк deferreturn ЕФ caller КЏЪ§жазЂВсЕФКЏЪ§ЃЉдђжБНгЗЕЛиЃЛ
-
Дг _defer ЖдЯѓжаАб defered КЏЪ§ашвЊЕФВЮЪ§ПНБДЕНеЛЩЯЃЛ
-
ЪЭЗХ _defer НсЙЙЬхЖдЯѓЃЛ
-
ЭЈЙ§ jmpdefer КЏЪ§ЕїгУ defered КЏЪ§ЃЈБШШчБОЮФЕФsumКЏЪ§ЃЉЁЃ
deferreturn КЏЪ§ЫфШЛБШНЯМђЕЅЃЌЕЋга2ЕуашвЊзЂвтЃК
-
ДњТыжаЕФСНИіЬсЧАreturnЕФЬѕМўЃКd == nil КЭ d.sp != spЁЃЦфжа d == nil дкХаЖЯЪЧЗёга defered КЏЪ§ашвЊжДааЃЌПЩФмгааЉЖСепЛсгавЩЮЪЃЌdeferreturn УїУїЪЧгы deferproc ХфЬзЪЙгУЕФЃЌетРядѕУДЛсЪЧnilФиЃПетИіЪЧвђЮЊdeferreturn КЏЪ§ЦфЪЕЪЧБЛЕнЙщЕїгУЕФЃЌУПДЮЕїгУЫќжЛЛсжДаавЛИі defered КЏЪ§ЃЌБШШчБОЮФЪЙгУЕФР§згдк f() КЏЪ§жазЂВсСЫвЛИі defered КЏЪ§(sumКЏЪ§)ЃЌЫљвд deferreturn КЏЪ§ЛсБЛЕїгУСНДЮЃЌЕквЛДЮНјШыЪБЛсШЅжДаа sum КЏЪ§ЃЌЕкЖўДЮНјШыЪБ d ЮЊ nil ОЭжБНгЗЕЛиСЫЃЛСэЭтвЛИіЬѕМў d.sp != sp дкХаЖЯ d ЖдЯѓЫљАќзАЕФ defered КЏЪ§ЯждкЪЧЗёгІИУБЛжДааЃЌБШШчгаКЏЪ§ЕїгУСДa()->b()->c()ЃЌМД a КЏЪ§ЕїгУСЫ b КЏЪ§ЃЌb КЏЪ§гжЕїгУСЫ c КЏЪ§ЃЌЫќУЧЖМЭЈЙ§ defer зЂВсСЫбгГйКЏЪ§ЃЌФЧУДЕБ c() жДааЭъЪБжЛФмжДаадк c жазЂВсЕФКЏЪ§ЃЌЖјВЛФмжДаа a КЏЪ§КЭ b КЏЪ§зЂВсЕФ defered КЏЪ§ЃЛ
-
defered КЏЪ§ЕФВЮЪ§ВЂВЛЪЧЗХдк deferreturn КЏЪ§ЕФеЛжЁжаЕФЃЌБШШчЧАУцЕФР§згЃЌf() ЕїгУ deferreturn КЏЪ§ЃЌЫљвд deferreturn КЏЪ§ЭЈЙ§ memmove Аб sum КЏЪ§ЕФСНИіВЮЪ§ copy ЕНСЫ f() КЏЪ§ЕФеЛжаЃЌНсКЯЧАУц f() КЏЪ§ЕФЛуБрДњТыЃЌПЩжЊдкЕїгУ jmpdefer КЏЪ§жЎЧАЃЌf() вдМА deferreturn() КЏЪ§ЕФеЛжЁДѓжТШчЯТЃК
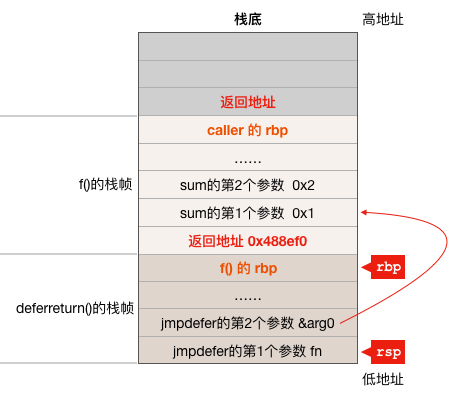
jmpdefer КЏЪ§
ЯТУцЮвУЧРДПД jmpdefer КЏЪ§ЃЌИУКЏЪ§ЪЙгУСЫаЉММЧЩЪЕЯжСЫвЛИіЖд deferreturn КЏЪ§ЕФЕнЙщЕїгУЃК
runtime/asm_amd64.s : 560
// func jmpdefer(fv *funcval, argp uintptr) // argp is a caller SP. // called from deferreturn. // 1. pop the caller // 2. sub 5 bytes from the callers return // 3. jmp to the argument TEXT runtimeЁЄjmpdefer(SB), NOSPLIT, $0-16MOVQ fv+0(FP), DX # fnЃЌfn.fn = sumКЏЪ§ЕФЕижЗMOVQ argp+8(FP), BX # caller spLEAQ -8(BX), SP # caller sp after CALLMOVQ -8(SP), BP # restore BP as if deferreturn returned (harmless if framepointers not in use)SUBQ $5, (SP) # return to CALL againMOVQ 0(DX), BX JMP BX # but first run the deferred function
вЊРэНтетИіКЏЪ§ЕФЙІФмЃЌашвЊЖдКЏЪ§ЕїгУеЛМАКЏЪ§ЕїгУЙ§ГЬгаБШНЯЧхЮњЕФШЯЪЖЃЌШчЙћЖдетВПЗжВЛЪьЯЄЃЌПЩвдЯШШЅПДвЛЯТЭјЩЯЕФзЪСЯЛђБОЙЋжкКХжЎЧАаДЕФЮФеТЁЃ
ЯТУцЮвУЧНсКЯБОЮФЧАУцЕФР§згГЬађРДж№ЬѕЗжЮі jmpdefer КЏЪ§ЕФ 7 ЬѕЛуБржИСюЁЃ
Ек1ЬѕжИСюЃК
MOVQ fv+0(FP), DX # fnЃЌfn.fn = sumКЏЪ§ЕФЕижЗ
АбjmpdeferЕФЕквЛИіВЮЪ§вВОЭЪЧНсЙЙЬхЖдЯѓfnЕФЕижЗЗХШыDXМФДцЦїЃЌжЎКѓЕФДњТыОЭПЩвдЭЈЙ§DXМФДцЦїЗУЮЪЕНfn.fnДгЖјФУЕН sum КЏЪ§ЕФЕижЗЁЃ
Ек2ЬѕжИСюЃК
MOVQ argp+8(FP), BX # caller sp
АбjmpdeferЕФЕкЖўИіВЮЪ§ЗХШы BX МФДцЦїЃЌИУВЮЪ§ЪЧвЛИіжИеыЃЌЫќжИЯђ sum КЏЪ§ЕФЕквЛИіВЮЪ§ЃЌМћЩЯЭМЕФМ§ЭЗЁЃ
Ек3ЬѕжИСюЃК
LEAQ -8(BX), SP # caller sp after CALL
ДгЕкЖўЬѕжИСюЕУжЊ BX ДцЗХЕФЪЧвЛИіжИеыЃЌBX - 8ЫљжИЕФЮЛжУЪЧ deferreturn КЏЪ§жДааЭъКѓЕФЗЕЛиЕижЗ 0x488ef0ЃЌЫљвдетЬѕжИСюЕФзїгУЪЧШУ SP МФДцЦїжИЯђ deferreturn КЏЪ§ЕФЗЕЛиЕижЗЫљдкЕФеЛФкДцЕЅдЊЃЌжДааЭъетЬѕжИСюКѓ SP МФДцЦїгыеЛжЎМфЕФЙиЯЕШчЯТЭМЃК
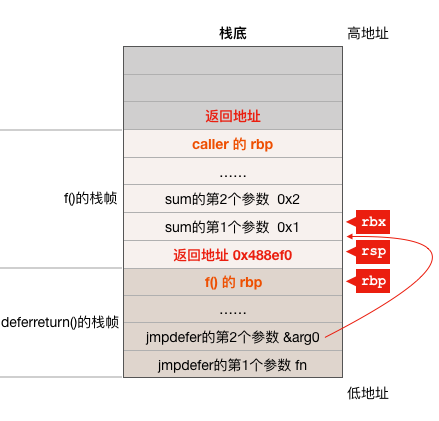
Ек4ЬѕжИСюЃК
MOVQ -8(SP), BP # restore BP as if deferreturn returned (harmless if framepointers not in use)
Еїећ BP МФДцЦїЕФжЕЃЌвђЮЊДЫЪБ SP - 8 ЕФЮЛжУДцЗХЕФЪЧ f() КЏЪ§ЕФ rbp МФДцЦїЕФжЕЃЌЫљвдетЬѕжИСюдкЕїећ rbp МФДцЦїЕФжЕЪЙЦфжИЯђ f() КЏЪ§ЕФеЛжЁЕФЪЪЕБЮЛжУЃЌжДааЭъетЬѕжИСюКѓ rbp МФДцЦїгыеЛжЎМфЕФЙиЯЕШчЯТЭМЃК
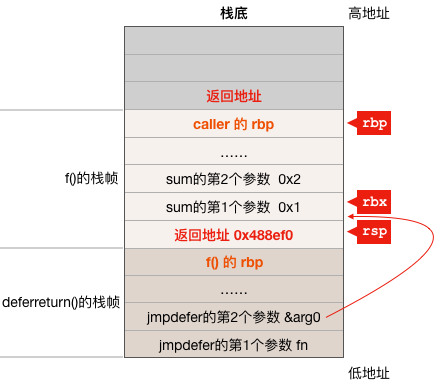
ОЙ§Ек3ЬѕКЭЕк4ЬѕжИСюжЎКѓЃЌdeferreturn КЏЪ§ЕФеЛжЁБЛХзЦњСЫЃЌвђЮЊ jmpdefer КЏЪ§ВЂВЛЛсжБНгЗЕЛиЕН deferreturn жЎжаЃЌЫљвдетРяХзЦњ deferreturn КЏЪ§ЕФеЛжЁУЛгаЮЪЬтЁЃ
Ек5ЬѕжИСюЃК
SUBQ $5, (SP) # return to CALL again
CPU дкжДааетЬѕжИСюЪЧЃЌrsp МФДцЦїжИЯђЕФЪЧ deferreturn КЏЪ§ЕФЗЕЛиЕижЗЃЌвВОЭЪЧ f() КЏЪ§жаЕФ 0x0000000000488ef0 <+272>: mov 0x78(%rsp),%rbp етвЛЬѕжИСюЕФЕижЗЃЌМД0x488ef0ЃЌЫљвдетЬѕжИСюАб rsp МФДцЦїЫљжИЕФФкДцжаЕФжЕ 0x488ef0 МѕСЫ 5 ЕУЕН 0x488eebЃЌЖдееЧАУцfКЏЪ§ЕФЛуБрДњТыПЩжЊЃЌетИіЕижЗжИЯђЕФЪЧ 0x0000000000488eeb <+267>: callq 0x427490 <runtime.deferreturn> етЬѕжИСюЁЃзЂвтПДЯТЭМжаrspМФДцЦїЫљжИЕФФкДцЕЅдЊжаЕФжЕЕФБфЛЏЃК
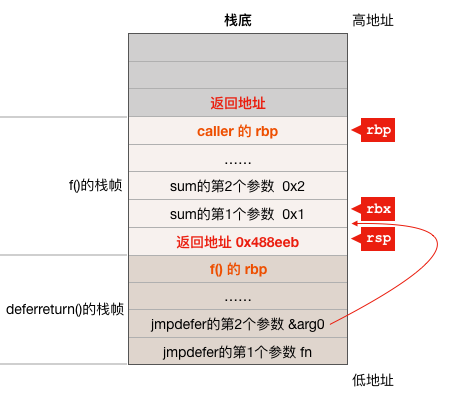
ЕНДЫЃЌsum КЏЪ§ЕФВЮЪ§вдМА sum КЏЪ§жДааЭъЕФЗЕЛиЕижЗдкеЛЩЯвбОЙЙдьЭъГЩЃЌЯТУцПЊЪМЕїгУ sum КЏЪ§ЁЃ
Ек6ЁЋ7ЬѕжИСю
MOVQ 0(DX), BX # BX = fn.fn JMP BX # but first run the deferred function
ЛсЬјзЊЕН sum КЏЪ§ШЅжДааЃЌЭъГЩЖд sum КЏЪ§ЕФЕїгУЃЌдк sum КЏЪ§ЕФжДааЙ§ГЬжаЃЌеЛШчЯТЭМЫљЪОЃК
вђЮЊ sum КЏЪ§ЕФЗЕЛиЕижЗБЛЩЯУцЕФЕк5ЬѕжИСюЩшжУГЩСЫ 0x488eebЃЌЫљвдЕШ sum КЏЪ§жДааЭъГЩжЎКѓЫќЛсжБНгЗЕЛиЕН f() КЏЪ§ЕФ
0x0000000000488eeb <+267>: callq 0x427490 <runtime.deferreturn>
жИСюДІМЬајжДааЃЌЖјетЬѕжИСюгжЕїгУСЫ deferreturn КЏЪ§ЁЃЛивфвЛЯТsumКЏЪ§ЕФЕїгУТЗОЖ f()->deferreturn()->jmpdefer()->sum()ЃЌsumКЏЪ§ЗЕЛиЕН f() ЪБгждйвЛДЮЕїгУСЫ deferreturn ЃЌетИіЙ§ГЬДгаЮЪНЩЯПДЦ№РДОЭЪЧвЛИіЕнЙщЃЌжЛВЛЙ§УПДЮЁАЕнЙщЁБЪБВЂУЛгадіМгеЛПеМфЃЁ
вђЮЊ f КЏЪ§жЛЪЙгУСЫвЛДЮ defer гяОфЃЌЫљвдетРяЕФЕкЖўДЮНјШы deferreturn КЏЪ§ЛсвђЮЊ d == nil етИіЬѕМўНсЪјЕнЙщЃЌШЛКѓЗЕЛиЕН f() КЏЪ§жаМЬајжДааКѓУцЕФжИСюЁЃ
ЙизЂЮв code дгЬГЃЌСЫНтИќЖр......
змНс
зюКѓЮвУЧРДзмНсвЛЯТ defer ЕФЪЕЯжЛњжЦЁЃ
ЖдгкШчЯТЫљЪОЕФ defer гяОф
func x() {.......defer y(......).......
}
ЪзЯШЃЌБрвыЦїЛсАб defer гяОфЗвыГЩЖд deferproc КЏЪ§ЕФЕїгУЃЌdeferproc ИКд№ЙЙдьвЛИігУРДБЃДц y КЏЪ§ЕФЕижЗвдМА y КЏЪ§ашвЊгУЕНЕФВЮЪ§ЕФ _defer НсЙЙЬхЖдЯѓЃЌВЂАбИУЖдЯѓМгШыЕБЧА goroutine ЖдгІЕФ g НсЙЙЬхЖдЯѓЕФ _defer СДБэБэЭЗЃЛ
ШЛКѓЃЌБрвыЦїЛсдк x КЏЪ§ЕФНсЮВДІВхШыЖд deferreturn ЕФЕїгУЃЌdeferreturn ИКд№ЕнЙщЕФЕїгУ x КЏЪ§ЭЈЙ§ defer гяОфзЂВсЕФКЏЪ§ЁЃ
змЬхЫЕРДЃЌдкВЛПМТЧ panic/recover ЕФЧщПіЯТЃЌgoгябдЖд defer ЕФЪЕЯжЛњжЦЛЙЪЧБШНЯМђЕЅЃЌЕЋЦфОпЬхЪЕЯжЯИНкЛЙЪЧгаКмЖрЕиЗНжЕЕУЮвУЧзаЯИЫМПМКЭбЇЯАЕФЁЃ
ЙизЂЮв code дгЬГЃЌСЫНтИќЖр......