ZooKeeper ��һ���ֲ�ʽЭ������ ���� Apache ����ά����
ZooKeeper ������Ϊһ���߿��õ��ļ�ϵͳ��
ZooKeeper �������ڷ���/���ġ����ؾ��⡢������ֲ�ʽЭ��/֪ͨ����Ⱥ������Master ѡ�١��ֲ�ʽ���ͷֲ�ʽ���еȹ��� ��
Ŀ¼
ZooKeeper ������ʲô��������� ZooKeeper һ��ZooKeeper ���
һ��Zookeeper �������
1.1 ZooKeeper ��ʲô
1.2 ZooKeeper ������
1.3 ZooKeeper �����Ŀ��
����ZooKeeper ���ĸ���
2.1 ����ģ��
2.2 �ڵ���Ϣ
2.3 ��Ⱥ��ɫ
2.4 ACL
����ZooKeeper ����ԭ��
3.1 ������
3.2 ���
3.3 ����
3.4 �۲�
3.5 �Ự
�ġ�ZAB Э��
4.1 ѡ�� Leader
4.2 ԭ�ӹ㲥��Atomic Broadcast��
�塢ZooKeeper Ӧ��
5.1 ��������
5.2 ���ù���
5.3 �ֲ�ʽ��
5.4 ��Ⱥ����
5.5 ѡ�� Leader �ڵ�
5.6 �����
ZooKeeper ������ʲô��������� ZooKeeper һ��ZooKeeper ���
һ��Zookeeper �������
1.1 ZooKeeper ��ʲô
ZooKeeper �� Apache �Ķ�����Ŀ��ZooKeeper Ϊ�ֲ�ʽӦ���ṩ�˸�Ч�ҿɿ��ķֲ�ʽЭ�������ṩ������ͳһ�����������ù����ͷֲ�ʽ���ȷֲ�ʽ�Ļ��������ڽ���ֲ�ʽ����һ���Է��棬ZooKeeper ��û��ֱ�Ӳ��� Paxos �㷨�����Dz�������Ϊ ZAB ��һ����Э�顣
ZooKeeper ��Ҫ��������ֲ�ʽ��Ⱥ��Ӧ��ϵͳ��һ�������⣬�����ṩ�����������ļ�ϵͳ��Ŀ¼�ڵ�����ʽ�����ݴ洢������ ZooKeeper ����������ר�Ŵ洢���ݵģ�����������Ҫ������ά���ͼ�ش洢���ݵ�״̬�仯��ͨ�������Щ����״̬�ı仯���Ӷ����Դﵽ�������ݵļ�Ⱥ������
�ܶ���������Ŀ�ܶ����� ZooKeeper ��ʵ�ֲַ�ʽ�߿��ã��磺Dubbo��Kafka �ȡ�
1.2 ZooKeeper ������
ZooKeeper �����������ԣ�
-
˳��һ���ԣ����пͻ��˿����ķ��������ģ�Ͷ���һ�µģ���һ���ͻ��˷���������������ն����ϸ����䷢��˳��Ӧ�õ� ZooKeeper �С������ʵ�ֿɼ����ģ�ԭ�ӹ㲥��
-
ԭ���ԣ�������������Ĵ��������������Ⱥ�����л����ϵ�Ӧ�������һ�µģ���������ȺҪô���ɹ�Ӧ����ij������Ҫô��û��Ӧ�á�ʵ�ַ�ʽ�ɼ����ģ�����
-
��һ��ͼ�����ۿͻ������ӵ����ĸ� Zookeeper ���������俴���ķ��������ģ�Ͷ���һ�µġ�
-
�����ܣ�ZooKeeper ������ȫ���洢���ڴ��У����������ܸܺߡ���Ҫע����ǣ����� ZooKeeper �����и��º�ɾ�����ǻ�������ģ���� ZooKeeper �ڶ���д�ٵ�Ӧ�ó����������ܱ��ֽϺã����д����Ƶ�������ܻ����»���
-
�߿��ã�ZooKeeper �ĸ߿����ǻ��ڸ�������ʵ�ֵģ����� ZooKeeper ֧�ֹ��ϻָ����ɼ����ģ�ѡ�� Leader��
1.3 ZooKeeper �����Ŀ��
-
������ģ��
-
���Թ�����Ⱥ
-
˳�����
-
������
����ZooKeeper ���ĸ���
2.1 ����ģ��
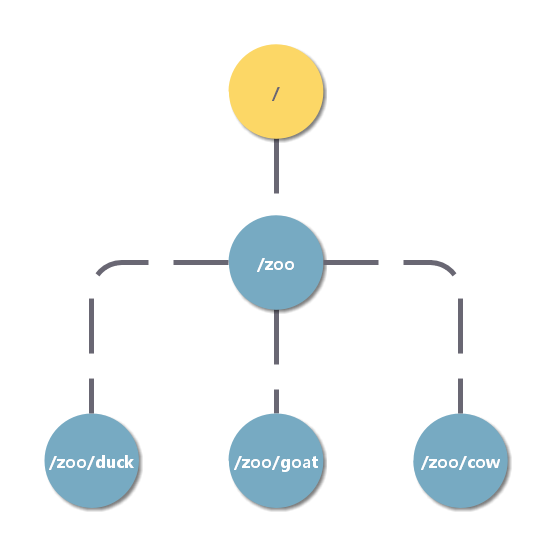
ZooKeeper ������ģ����һ�����νṹ���ļ�ϵͳ��
���еĽڵ㱻��Ϊ znode�����и��ڵ�Ϊ /��ÿ���ڵ��϶��ᱣ���Լ������ݺͽڵ���Ϣ��znode �������ڴ洢���ݣ�������һ����֮������� ACL������ɼ� ACL����ZooKeeper �����Ŀ����ʵ��Э���������������Ϊһ���ļ��洢����� znode �洢���ݵ���С�������� 1MB ���ڡ�
ZooKeeper �����ݷ��ʾ���ԭ���ԡ����д��������Ҫôȫ���ɹ���Ҫôȫ��ʧ�ܡ�
znode ͨ��·�������á�znode �ڵ�·�������Ǿ���·����
znode ���������ͣ�
-
��ʱ�ģ� EPHEMERAL �����ͻ��˻Ự����ʱ��ZooKeeper �ͻ�ɾ����ʱ�� znode��
-
�־õģ�PERSISTENT �������ǿͻ�������ִ��ɾ������������ ZooKeeper ����ɾ���־õ� znode��
2.2 �ڵ���Ϣ
znode ����һ��˳���־�� SEQUENTIAL ��������ڴ��� znode ʱ��������˳���־�� SEQUENTIAL ������ô ZooKeeper ��ʹ�ü�����Ϊ znode ����һ��������������ֵ���� zxid��ZooKeeper �������� zxid ʵ�����ϸ��˳����ʿ���������
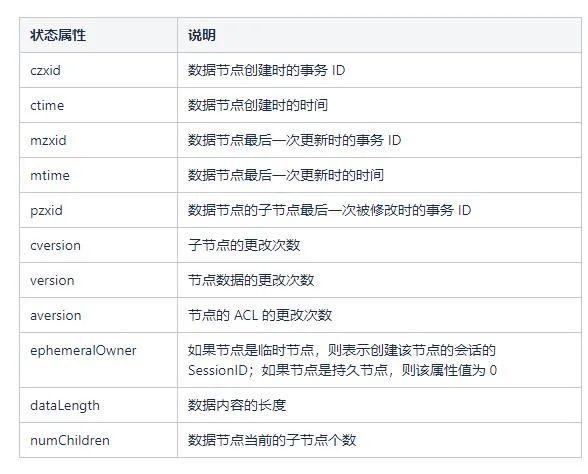
ÿ�� znode �ڵ��ڴ洢���ݵ�ͬʱ������ά��һ������ Stat �����ݽṹ������洢�˹��ڸýڵ��ȫ��״̬��Ϣ�����£�
2.3 ��Ⱥ��ɫ
Zookeeper ��Ⱥ��һ���������Ӹ��Ƶĸ߿��ü�Ⱥ��ÿ���������е��������ֽ�ɫ�е�һ�֡�
-
Leader�������� ����ά����� Follwer �� Observer ������������е�д��������Ҫͨ�� Leader ������� Leader ��д�����㲥��������������һ�� Zookeeper ��Ⱥͬһʱ��ֻ����һ��ʵ�ʹ����� Leader��
-
Follower��������Ӧ Leader ��������Follower ��ֱ�Ӵ��������ؿͻ��˵Ķ�����ͬʱ�Ὣд����ת���� Leader ���������Ҹ����� Leader ����д����ʱ���������ͶƱ��һ�� Zookeeper ��Ⱥ����ͬʱ���ڶ�� Follower��
-
Observer����ɫ�� Follower ���ƣ�������ͶƱȨ��
2.4 ACL
ZooKeeper ���� ACL��Access Control Lists������������Ȩ���ơ�
ÿ�� znode ����ʱ�������һ�� ACL �б������ھ���˭���Զ���ִ�к��ֲ�����
ACL ������ ZooKeeper �Ŀͻ�����֤���ơ�ZooKeeper �ṩ�����¼�����֤��ʽ��
-
digest�� �û��������� ��ʶ��ͻ���
-
sasl��ͨ�� kerberos ��ʶ��ͻ���
-
ip��ͨ�� IP ��ʶ��ͻ���
ZooKeeper ��������������Ȩ�ޣ�
-
CREATE�����������ӽڵ㣻
-
READ�������ӽڵ��ȡ���ݲ��г����ӽڵ㣻
-
WRITE�� ����Ϊ�ڵ��������ݣ�
-
DELETE������ɾ���ӽڵ㣻
-
ADMIN�� ����Ϊ�ڵ�����Ȩ�ޡ�
����ZooKeeper ����ԭ��
��ע�� code ��̳���˽����.......
3.1 ������
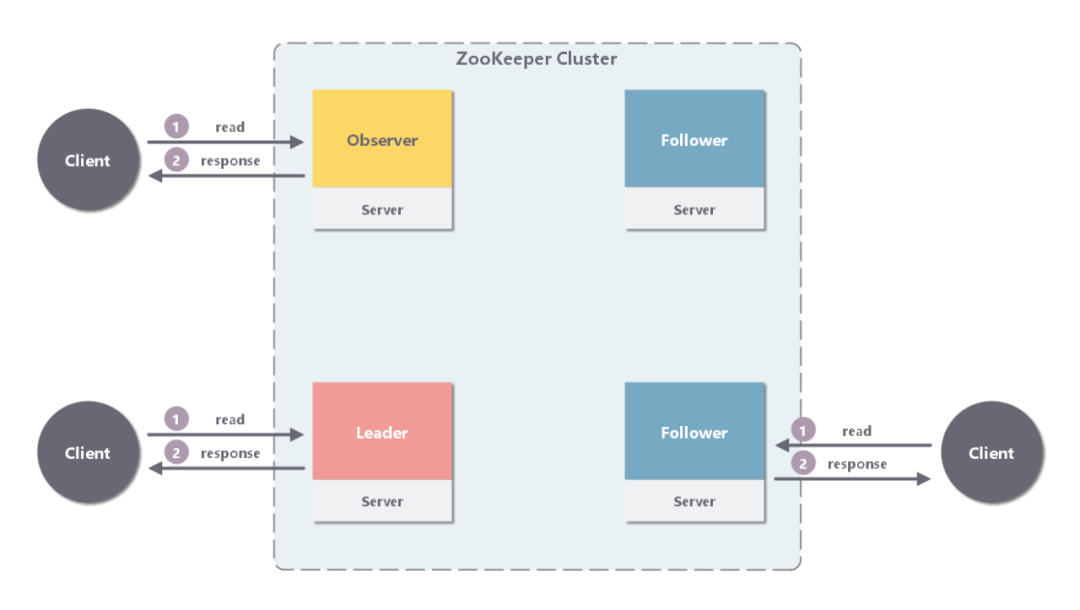
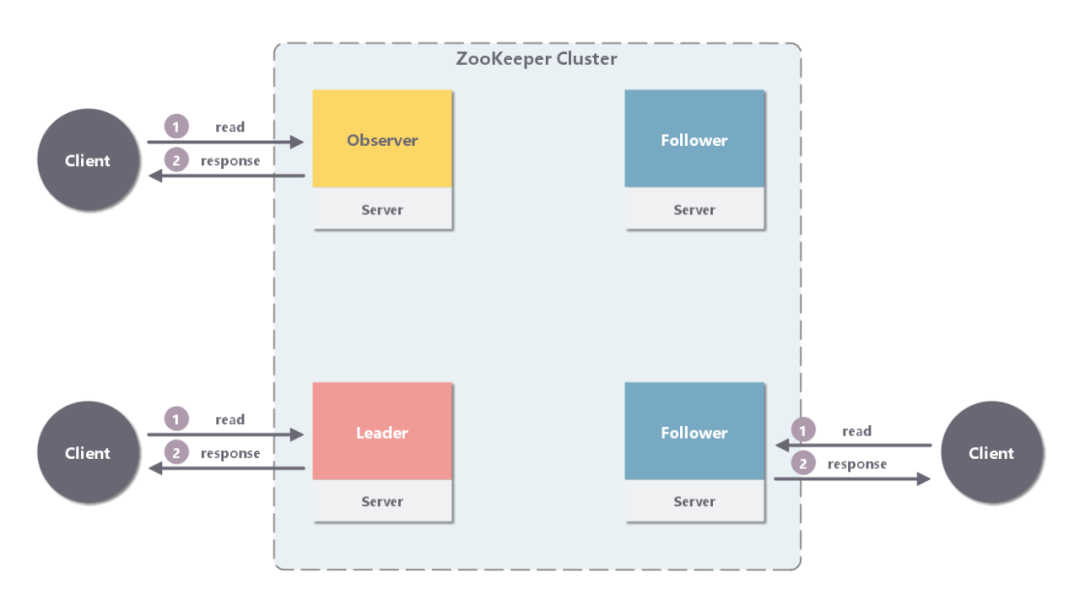
Leader/Follower/Observer ����ֱ�Ӵ��������ӱ����ڴ��ж�ȡ���ݲ����ظ��ͻ��˼��ɡ�
���ڴ�����������Ҫ������֮��Ľ�����Follower/Observer Խ�࣬����ϵͳ�Ķ�����������Խ����Ҳ��������Խ�á�
3.2 ���
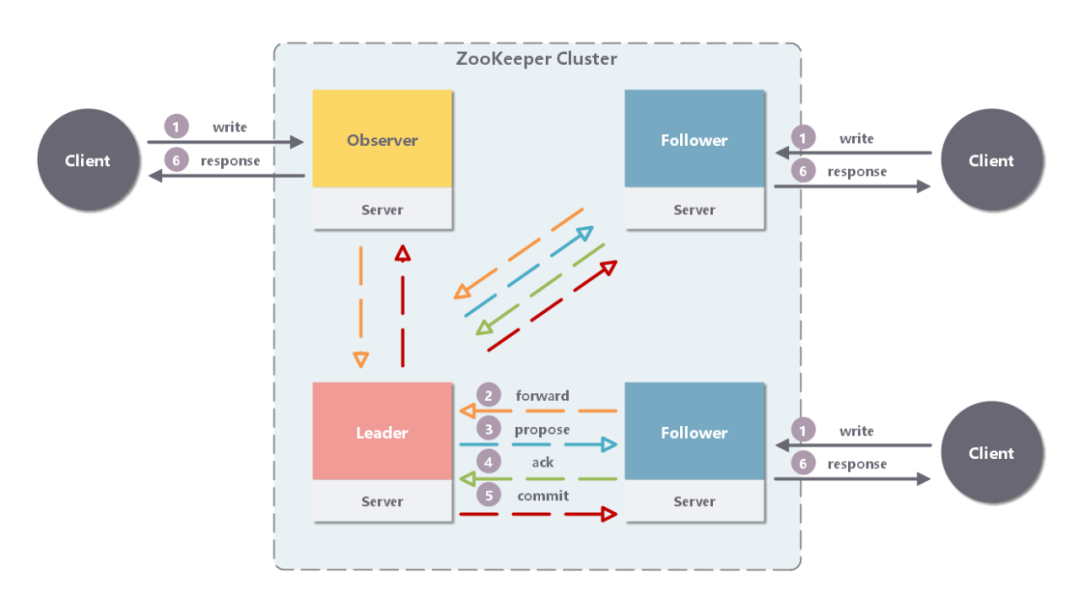
���е�д����ʵ���϶�Ҫ���� Leader ������Leader ��д������������ʽ�������� Follower ���ȴ� ACK��һ���յ��������� Follower �� ACK������Ϊд�����ɹ���
3.2.1 д Leader
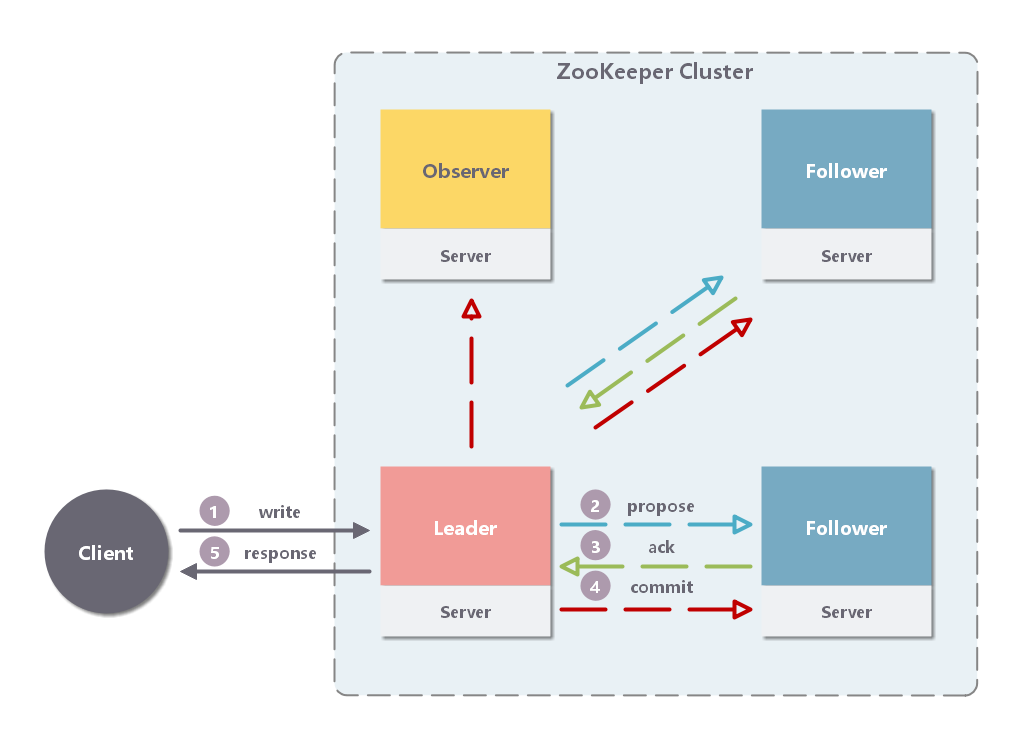
����ͼ�ɼ���ͨ�� Leader ����д��������Ҫ��Ϊ�岽��
-
�ͻ����� Leader ����д����
-
Leader ��д���������� Proposal ����ʽ�������� Follower ���ȴ� ACK��
-
Follower �յ� Leader ������ Proposal �� ACK��
-
Leader �õ��������� ACK��Leader ���Լ�Ĭ����һ�� ACK���������е� Follower �� Observer ���� Commmit��
-
Leader ������������ظ��ͻ��ˡ�
ע��
-
Leader ����Ҫ�õ� Observer �� ACK���� Observer ��ͶƱȨ��
-
Leader ����Ҫ�õ����� Follower �� ACK��ֻҪ�յ������ ACK ���ɣ�ͬʱ Leader �������Լ���һ�� ACK����ͼ���� 4 �� Follower��ֻ�������������� ACK ���ɣ���Ϊ $$(2+1) / (4+1) > 1/2$$ ��
-
Observer ��Ȼ��ͶƱȨ��������ͬ�� Leader �����ݴӶ��ڴ���������ʱ���Է��ؾ������µ����ݡ�
3.2.2 д Follower/Observer
Follower/Observer ���ɽ���д��������ֱ�Ӵ���������Ҫ��д����ת���� Leader ������
���˶���һ������ת��������������ֱ��д Leader ���κ�����
3.3 ����
�������Կͻ��˵�ÿ����������ZooKeeper �߱��ϸ��˳����ʿ���������
Ϊ�˱�֤�����˳��һ���ԣ�ZooKeeper �����˵��������� id �ţ�zxid������ʶ����
Leader �����Ϊÿһ�� Follower ����������һ�������Ķ��У�Ȼ������ Proposal ���η�������У������� FIFO(�Ƚ��ȳ�) �IJ��Խ�����Ϣ���͡�Follower �����ڽ��յ� Proposal �Ὣ����������־����ʽд�뱾�ش����У�����д��ɹ������� Leader һ�� Ack ��Ӧ���� Leader ���յ��������� Follower �� Ack ��Ӧ�ͻ�㲥һ�� Commit ��Ϣ�����е� Follower ��֪ͨ����������ύ��֮�� Leader ����Ҳ����ɶ�������ύ����ÿһ�� Follower ���ڽ��յ� Commit ��Ϣ�����������ύ��
���е����飨proposal�����ڱ������ʱ������� zxid��zxid ��һ�� 64 λ�����֣����ĸ� 32 λ�� epoch ������ʶ Leader ��ϵ�Ƿ�ı䣬ÿ��һ�� Leader ��ѡ��������������һ���µ� epoch����ʶ��ǰ�����Ǹ� leader ��ͳ��ʱ�ڡ��� 32 λ���ڵ���������
��ϸ�������£�
-
Leader �ȴ� Server ���ӣ�
-
Follower ���� Leader�������� zxid ���� Leader��
-
Leader ���� Follower �� zxid ȷ��ͬ���㣻
-
���ͬ����֪ͨ follower �Ѿ���Ϊ uptodate ״̬��
-
Follower �յ� uptodate ��Ϣ���ֿ������½��� client ��������з����ˡ�
3.4 �۲�
�ͻ���ע����������ĵ� znode���� znode ״̬�����仯�����ݱ仯���ӽڵ������仯��ʱ��ZooKeeper �����֪ͨ�ͻ��ˡ�
�ͻ��˺ͷ���˱�������һ����������ʽ��
-
�ͻ��������˲�����ѯ
-
�������ͻ�������״̬
Zookeeper ��ѡ���Ƿ������������״̬��Ҳ���ǹ۲���ƣ� Watch ����
ZooKeeper �Ĺ۲���������û���ָ���ڵ�����Ը���Ȥ���¼�ע����������¼�����ʱ���������ᱻ�����������¼���Ϣ���͵��ͻ��ˡ�
�ͻ���ʹ�� getData �Ƚӿڻ�ȡ znode ״̬ʱ������һ�����ڴ����ڵ����Ļص�����ô����˾ͻ�������ͻ������ͽڵ�ı����
����������д���� Watcher ����ʵ������Ӧ�� process ������ÿ�ζ�Ӧ�ڵ������״̬�ĸı䣬WatchManager ����ͨ�����µķ�ʽ���ô��� Watcher �ķ�����
???????Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) { WatchedEvent e = new WatchedEvent(type, KeeperState.SyncConnected, path); Set<Watcher> watchers; synchronized (this) { watchers = watchTable.remove(path); } for (Watcher w : watchers) { w.process(e); } returnZookeeper �е�����������ʵ������һ����Ϊ DataTree �����ݽṹ�����ģ����еĶ�д���ݵ��������ն���ı�����������ݣ��ڷ���������ʱ���ܻᴫ�� Watcher ע��һ���ص���������д����Ϳ��ܻᴥ����Ӧ�Ļص����� WatchManager ֪ͨ�ͻ������ݵı仯��
֪ͨ���Ƶ�ʵ����ʵ���DZȽϼģ�ͨ������������ Watcher �����¼���д�����ڴ����¼�ʱ���ܽ�֪ͨ����ָ���Ŀͻ��ˡ�
3.5 �Ự
ZooKeeper �ͻ���ͨ�� TCP ���������ӵ� ZooKeeper ����Ⱥ���Ự (Session) �ӵ�һ�����ӿ�ʼ���Ѿ�������֮��ͨ��������������������Ч�ĻỰ״̬��ͨ��������ӣ��ͻ��˿��Է�����������Ӧ��ͬʱҲ���Խ��յ� Watch �¼���֪ͨ��
ÿ�� ZooKeeper �ͻ��������ж������� ZooKeeper ��������Ⱥ�б�������ʱ���ͻ��˻�����б�ȥ���Խ������ӡ����ʧ�ܣ����᳢��������һ�����������������ơ�
һ��һ̨�ͻ�����һ̨�������������ӣ���̨��������Ϊ����ͻ��˴���һ���µĻỰ��ÿ���Ự������һ����ʱʱ�䣬���������ڳ�ʱʱ����û���յ��κ���������Ӧ�Ự����Ϊ���ڡ�һ���Ự���ڣ����������´����κ���ûỰ��ص���ʱ znode ���ᱻɾ����
ͨ����˵���ỰӦ�ó��ڴ��ڣ�������Ҫ�ɿͻ�������֤���ͻ��˿���ͨ��������ʽ��ping�������ֻỰ�����ڡ�
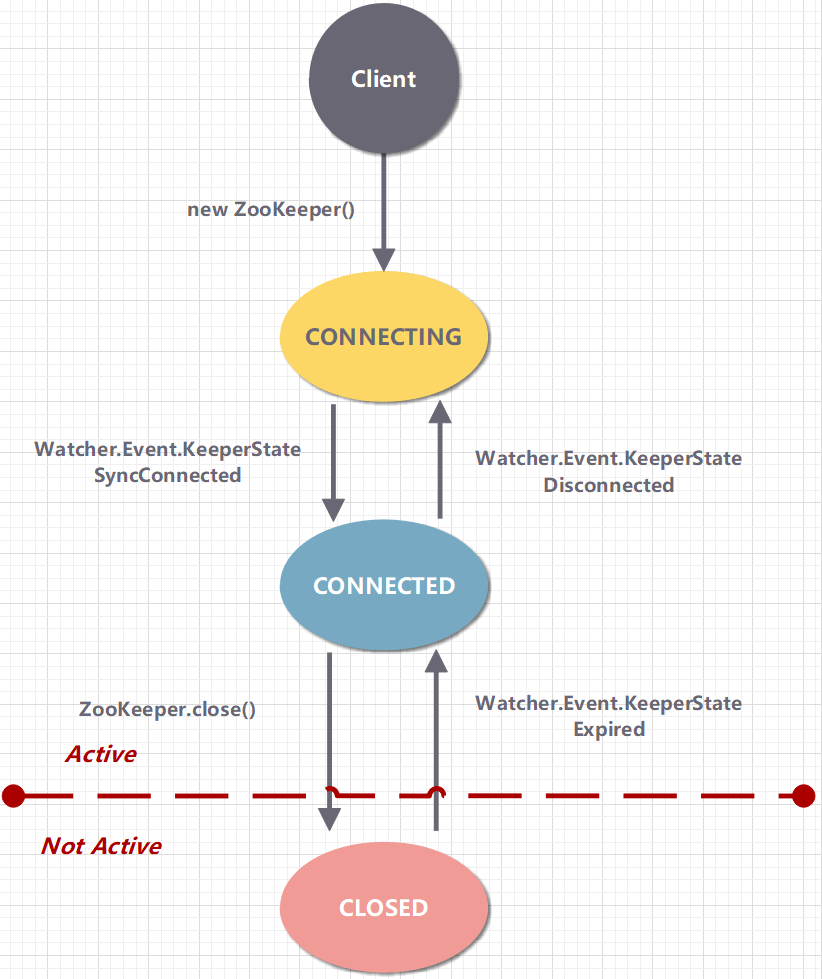
ZooKeeper �ĻỰ�����ĸ�����
-
sessionID���Ự ID��Ψһ��ʶһ���Ự��ÿ�οͻ��˴����µĻỰʱ��Zookeeper ����Ϊ�����һ��ȫ��Ψһ�� sessionID��
-
TimeOut���Ự��ʱʱ�䣬�ͻ����ڹ��� Zookeeper ʵ��ʱ�������� sessionTimeout ��������ָ���Ự�ij�ʱʱ�䣬Zookeeper �ͻ��������˷��������ʱʱ�����˻�����Լ��ij�ʱʱ����������ȷ���Ự�ij�ʱʱ�䡣
-
TickTime���´λỰ��ʱʱ��㣬Ϊ�˱��� Zookeeper �ԻỰʵ�С���Ͱ���ԡ�������ͬʱΪ�˸�Ч�ͺĵ�ʵ�ֻỰ�ij�ʱ�����������Zookeeper ��Ϊÿ���Ự���һ���´λỰ��ʱʱ��㣬��ֵ���µ��ڵ�ǰʱ����� TimeOut��
-
isClosing�����һ���Ự�Ƿ��Ѿ����رգ�������˼��Ự�Ѿ���ʱʧЧʱ���Ὣ�ûỰ�� isClosing ���Ϊ���ѹرա�����������ȷ�����ٴ������ԸûỰ���������ˡ�
Zookeeper �ĻỰ������Ҫ��ͨ�� SessionTracker ���������������Ͱ�����������ƵĻỰ����ͬһ�����н��й��������й������Ա� Zookeeper �ԻỰ���в�ͬ����ĸ��봦���Լ�ͬһ�����ͳһ������
��ע�� code ��̳���˽����.......
�ġ�ZAB Э��
ZooKeeper ��û��ֱ�Ӳ��� Paxos �㷨�����Dz�������Ϊ ZAB ��һ����Э�顣ZAB Э�鲻�� Paxos �㷨��ֻ�DZȽ����ƣ������ڲ����ϲ�����ͬ��
ZAB Э���� Zookeeper ר����Ƶ�һ��֧�ֱ����ָ���ԭ�ӹ㲥Э�顣
ZAB Э���� ZooKeeper ������һ���Ժ߿��ý��������
ZAB Э�鶨����������������ѭ�������̣�
-
ѡ�� Leader�����ڹ��ϻָ����Ӷ���֤�߿��á�
-
ԭ�ӹ㲥����������ͬ�����Ӷ���֤����һ���ԡ�
4.1 ѡ�� Leader
ZooKeeper �Ĺ��ϻָ�
ZooKeeper ��Ⱥ����һ������Ϊ Leader����ӣ���Ϊ Follower��ģʽ�����ӽڵ�ͨ���������Ʊ�֤����һ�¡�
-
��� Follower �ڵ���� - ZooKeeper ��Ⱥ�е�ÿ���ڵ㶼�ᵥ�����ڴ���ά��������״̬�����Ҹ��ڵ�֮�䶼������ͨѶ��ֻҪ��Ⱥ���а��������ܹ�������������ô������Ⱥ�Ϳ��������ṩ����
-
��� Leader �ڵ���� - ��� Leader �ڵ���ˣ�ϵͳ�Ͳ������������ˡ���ʱ����Ҫͨ�� ZAB Э���ѡ�� Leader ���������й��ϻָ���
ZAB Э���ѡ�� Leader ���Ƽ���˵�����ǣ����ڹ���ѡ�ٻ��Ʋ����µ� Leader��֮���������������µ� Leader ��ͬ��״̬�����й���������״̬ͬ�����˳�ѡ�� Leader ģʽ������ԭ�ӹ㲥ģʽ��
4.1.1 ����
myid��ÿ�� Zookeeper ������������Ҫ�������ļ����´���һ����Ϊ myid ���ļ������ļ��������� Zookeeper ��ȺΨһ�� ID����������
zxid�������� RDBMS �е����� ID�����ڱ�ʶһ�θ��²����� Proposal ID��Ϊ�˱�֤˳���ԣ��� zkid ���뵥����������� Zookeeper ʹ��һ�� 64 λ��������ʾ���� 32 λ�� Leader �� epoch���� 1 ��ʼ��ÿ��ѡ���µ� Leader��epoch ��һ���� 32 λΪ�� epoch �ڵ���ţ�ÿ�� epoch �仯�������� 32 λ��������á�������֤�� zkid ��ȫ�ֵ����ԡ�
4.1.2 ������״̬
-
LOOKING����ȷ�� Leader ״̬����״̬�µķ�������Ϊ��ǰ��Ⱥ��û�� Leader���ᷢ�� Leader ѡ�١�
-
FOLLOWING��������״̬��������ǰ��������ɫ�� Follower��������֪�� Leader ��˭��
-
LEADING���쵼��״̬��������ǰ��������ɫ�� Leader������ά���� Follower ���������
-
OBSERVING���۲���״̬��������ǰ��������ɫ�� Observer���� Folower Ψһ�IJ�ͬ���ڲ�����ѡ�٣�Ҳ�����뼯Ⱥд����ʱ��ͶƱ��
4.1.3 ѡƱ���ݽṹ
ÿ���������ڽ����쵼ѡ��ʱ���ᷢ�����¹ؼ���Ϣ��
-
logicClock��ÿ����������ά��һ����������������Ϊ logicClock������ʾ���Ǹ÷���������ĵڶ�����ͶƱ��
-
state����ǰ��������״̬��
-
self_id����ǰ�������� myid��
-
self_zxid����ǰ������������������ݵ���� zxid��
-
vote_id�����ƾٵķ������� myid��
-
vote_zxid�����ƾٵķ�����������������ݵ���� zxid��
4.1.4 ͶƱ����
��1������ѡ���ִ�
Zookeeper �涨������Ч��ͶƱ��������ͬһ�ִ��С�ÿ���������ڿ�ʼ��һ��ͶƱʱ�����ȶ��Լ�ά���� logicClock ��������������
��2����ʼ��ѡƱ
ÿ���������ڹ㲥�Լ���ѡƱǰ���Ὣ�Լ���ͶƱ����ա���ͶƱ���¼�����յ���ѡƱ������������ 2 ͶƱ�������� 3�������� 3 ͶƱ�������� 1��������� 1 ��ͶƱ��Ϊ(2, 3), (3, 1), (1, 1)��Ʊ����ֻ���¼ÿһͶƱ�ߵ����һƱ����ͶƱ�߸����Լ���ѡƱ���������������յ�����ѡƱ������Լ�Ʊ���и��¸÷�������ѡƱ��
��3�����ͳ�ʼ��ѡƱ
ÿ���������ʼ����ͨ���㲥��ƱͶ���Լ���
��4�������ⲿͶƱ
�������᳢�Դ�������������ȡͶƱ���������Լ���ͶƱ���ڡ��������ȡ�κ��ⲿͶƱ�����ȷ���Լ��Ƿ��뼯Ⱥ��������������������Ч���ӡ�����ǣ����ٴη����Լ���ͶƱ���������������֮�������ӡ�
��5���ж�ѡ���ִ�
�յ��ⲿͶƱ�����Ȼ����ͶƱ��Ϣ���������� logicClock �����в�ͬ������
-
�ⲿͶƱ�� logicClock �����Լ��� logicClock��˵���÷�������ѡ���ִ������������������ѡ���ִΣ���������Լ���ͶƱ�䲢���Լ��� logicClock ����Ϊ�յ��� logicClock��Ȼ���ٶԱ��Լ�֮ǰ��ͶƱ���յ���ͶƱ��ȷ���Ƿ���Ҫ����Լ���ͶƱ�������ٴν��Լ���ͶƱ�㲥��ȥ��
-
�ⲿͶƱ�� logicClock С���Լ��� logicClock����ǰ������ֱ�Ӻ��Ը�ͶƱ������������һ��ͶƱ��
-
�ⲿͶƱ�� logickClock ���Լ����������ʱ����ѡƱ PK��
��6��ѡƱ PK
ѡƱ PK �ǻ���(self_id, self_zxid)��(vote_id, vote_zxid)�ĶԱȣ�
-
�ⲿͶƱ�� logicClock �����Լ��� logicClock�����Լ��� logicClock ���Լ���ѡƱ�� logicClock ���Ϊ�յ��� logicClock��
-
�� logicClock һ������Աȶ��ߵ� vote_zxid�����ⲿͶƱ�� vote_zxid �Ƚϴ����Լ���Ʊ�е� vote_zxid �� vote_myid ����Ϊ�յ���Ʊ�е� vote_zxid �� vote_myid ���㲥��ȥ�����⽫�յ���Ʊ���Լ����º��Ʊ�����Լ���Ʊ�䡣���Ʊ�����Ѵ���(self_myid, self_zxid)��ͬ��ѡƱ����ֱ�Ӹ��ǡ�
-
������ vote_zxid һ�£���Ƚ϶��ߵ� vote_myid�����ⲿͶƱ�� vote_myid �Ƚϴ����Լ���Ʊ�е� vote_myid ����Ϊ�յ���Ʊ�е� vote_myid ���㲥��ȥ�����⽫�յ���Ʊ���Լ����º��Ʊ�����Լ���Ʊ�䡣
��7��ͳ��ѡƱ
����Ѿ�ȷ���й���������Ͽ����Լ���ͶƱ�������Ǹ��º��ͶƱ��������ֹͶƱ�������������������������ͶƱ��
��8�����·�����״̬
ͶƱ��ֹ��������ʼ��������״̬���������ƱͶ�����Լ������Լ��ķ�����״̬����Ϊ LEADING�������Լ���״̬����Ϊ FOLLOWING��
ͨ���������̷��������Dz��ѿ�����Ҫʹ Leader ��ö��� Server ��֧�֣��� ZooKeeper ��Ⱥ�ڵ����������������Ҵ��Ľڵ���Ŀ�������� N + 1 ��
ÿ�� Server �������ظ��������̡��ڻָ�ģʽ�£�����Ǹմӱ���״̬�ָ��Ļ��߸������� server ����Ӵ��̿����лָ����ݺͻỰ��Ϣ��zk ���¼������־�����ڽ��п��գ������ڻָ�ʱ����״̬�ָ���
4.2 ԭ�ӹ㲥��Atomic Broadcast��
ZooKeeper ͨ������������ʵ�ָ߿��á�
��ô��ZooKeeper �����ʵ�ָ������Ƶ��أ����ǣ�ZAB Э���ԭ�ӹ㲥��
ZAB Э���ԭ�ӹ㲥Ҫ��
���е�д���ᱻת���� Leader��Leader ����ԭ�ӹ㲥�ķ�ʽ֪ͨ Follow�����������ϵ� Follow �Ѿ�����״̬�־û���Leader �Ż��ύ������£�Ȼ��ͻ��˲Ż��յ�һ�����³ɹ�����Ӧ������Щ�������ݿ��е������ύЭ�顣
��������Ϣ�Ĺ㲥�����У�Leader ��������ÿ�������������ɶ�Ӧ�� Proposal����Ϊ�����һ��ȫ��Ψһ�ĵ��������� ID(ZXID)��֮���ٶ�����й㲥��
��ע�� code ��̳���˽����.......
�塢ZooKeeper Ӧ��
ZooKeeper �������ڷ���/���ġ����ؾ��⡢������ֲ�ʽЭ��/֪ͨ����Ⱥ������Master ѡ�١��ֲ�ʽ���ͷֲ�ʽ���еȹ��� ��
5.1 ��������
�ڷֲ�ʽϵͳ�У�ͨ����Ҫһ��ȫ��Ψһ�����֣�������ȫ��Ψһ�Ķ����ŵȣ�ZooKeeper ����ͨ��˳��ڵ������������ȫ��Ψһ ID���Ӷ����ԶԷֲ�ʽϵͳ�ṩ��������
5.2 ���ù���
���� ZooKeeper �Ĺ۲���ƣ����Խ�����Ϊһ���߿��õ����ô洢���������ֲ�ʽӦ�õIJ����������������ļ���
5.3 �ֲ�ʽ��
����ͨ�� ZooKeeper ����ʱ�ڵ�� Watcher ������ʵ�ֲַ�ʽ����
������˵����һ���ֲ�ʽϵͳ���������ڵ� A��B��C����ͼͨ�� ZooKeeper ��ȡ�ֲ�ʽ����
��1������ /lock �����Ŀ¼·���ɳ����Լ������������� �����кŵ���ʱ�ڵ㣨EPHEMERAL�� ��
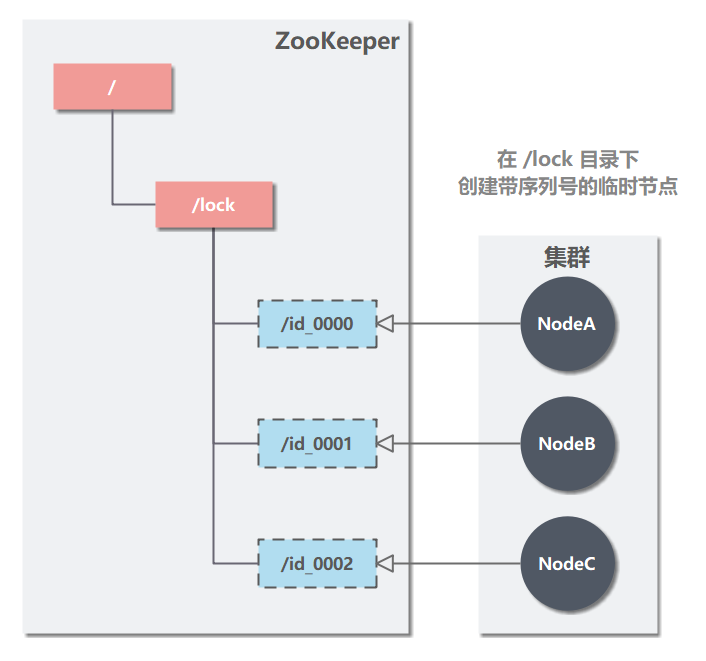
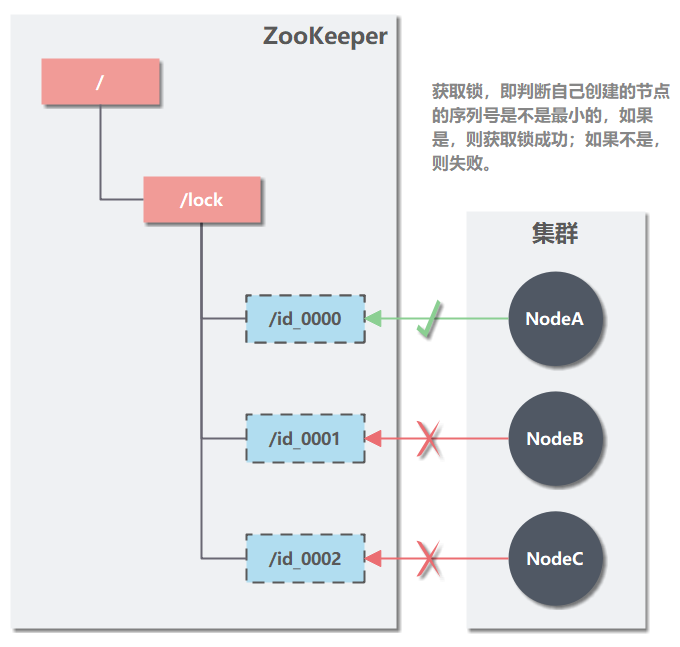
��2��ÿ���ڵ㳢�Ի�ȡ��ʱ���õ� /locks�ڵ��µ������ӽڵ㣨id_0000,id_0001,id_0002�����ж��Լ������Ľڵ��Dz�����С�ġ�
-
����ǣ����õ�����
�ͷ�����ִ��������Ѵ����Ľڵ��ɾ����
-
������ǣ���������Լ�ҪС 1 �Ľڵ�仯��
��3���ͷ�������ɾ���Լ������Ľڵ㡣
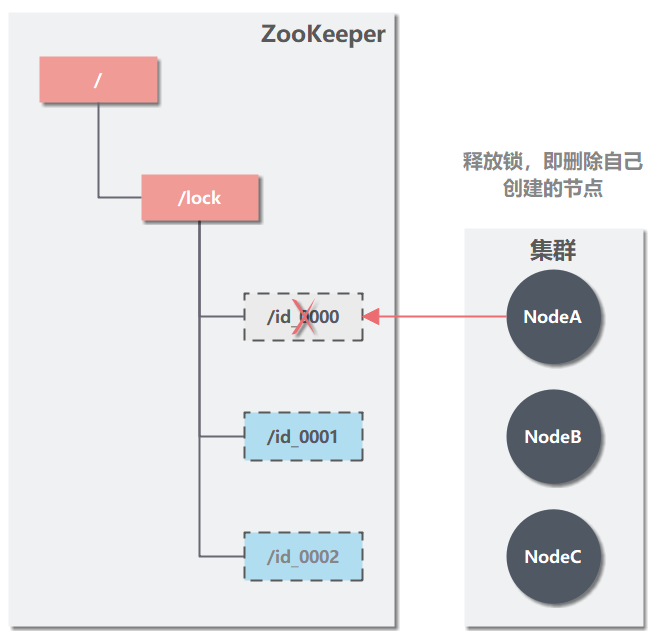
ͼ�У�NodeA ɾ���Լ������Ľڵ� id_0000��NodeB �������仯�������Լ��Ľڵ��Ѿ�����С�ڵ㣬���ɻ�ȡ������
5.4 ��Ⱥ����
ZooKeeper ���ܽ��������ֲ�ʽϵͳ�е����⣺
-
�����ͨ��������ʱ�ڵ����������������ơ�����ֲ�ʽϵͳ��ij������ڵ�崻��ˣ�������еĻỰ�ᳬʱ����ʱ����ʱ�ڵ�ᱻɾ������Ӧ�ļ����¼��ͻᱻ������
-
�ֲ�ʽϵͳ��ÿ������ڵ㻹���Խ��Լ��Ľڵ�״̬д����ʱ�ڵ㣬�Ӷ����״̬�����ڵ㹤�����Ȼ㱨��
-
ͨ�����ݵĶ��ĺͷ������ܣ�ZooKeeper ���ܶԷֲ�ʽϵͳ����ģ��Ľ��������ĵ��ȡ�
-
ͨ���������ƣ����ܶԷֲ�ʽϵͳ�ķ���ڵ���ж�̬�����ߣ��Ӷ�ʵ�ַ���Ķ�̬���ݡ�
5.5 ѡ�� Leader �ڵ�
�ֲ�ʽϵͳһ����Ҫ��ģʽ��������ģʽ (Master/Salves)��ZooKeeper �������ڸ�ģʽ�µ� Matser ѡ�١����������з���ڵ�ȥ�����Եش���ͬһ�� ZNode������ ZooKeeper ������·����ͬ�� ZNode����Ȼֻ��һ������ڵ��ܹ������ɹ��������÷���ڵ�Ϳ��Գ�Ϊ Master �ڵ㡣
5.6 �����
ZooKeeper ���Դ����������͵Ķ��У�
-
��һ�����еij�Ա������ʱ��������вſ��ã�����һֱ�ȴ����г�Ա���������ͬ�����С�
-
���а��� FIFO ��ʽ������Ӻͳ��Ӳ���������ʵ�������ߺ�������ģ�͡�
ͬ�������� ZooKeeper ʵ�ֵ�ʵ��˼·���£�
����һ����Ŀ¼ /synchronizing��ÿ����Ա����ر�־��Set Watch��λĿ¼ /synchronizing/start �Ƿ���ڣ�Ȼ��ÿ����Ա������������У�������еķ�ʽ���Ǵ��� /synchronizing/member_i ����ʱĿ¼�ڵ㣬Ȼ��ÿ����Ա��ȡ / synchronizing Ŀ¼������Ŀ¼�ڵ㣬Ҳ���� member_i���ж� i ��ֵ�Ƿ��Ѿ��dz�Ա�ĸ��������С�ڳ�Ա�����ȴ� /synchronizing/start �ij��֣�����Ѿ���Ⱦʹ��� /synchronizing/start��
��ע�� code ��̳���˽����.......