分片(sharding)是指将数据拆分,将其分散存在不同的机器上的过程。有时也用分区(partitioning)来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存更多的数据,处理更多的负载。
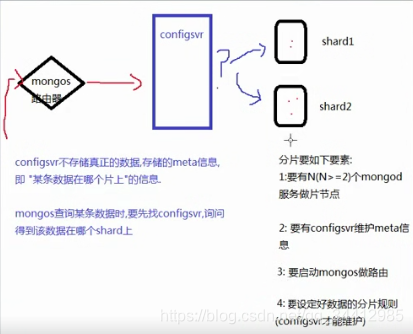
MongoDB分片的基本思想就是将集合切分成小块。这些块分散到若干片里面,每个片只负责总数据的一部分。应用程序不必知道哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,该进程名为mongos。这个路由器知道所有数据的存放位置,所以应用可以连接它来正常发送请求。对应用来说,它仅知道连接了一个普通的mongod。路由器知道数据和片的对应关系,能够转发请求道正确的片上。如果请求有了回应,路由器将其收集起来回送给应用。
设置分片时,需要从集合里面选一个键,用该键的值作为数据拆分的依据。这个键称为片键(shard key)。
用个例子来说明这个过程:假设有个文档集合表示的是人员。如果选择名字("name")作为片键,第一片可能会存放名字以A~F开头的文档,第二片存的G~P的名字,第三片存的Q~Z的名字。随着添加或者删除片,MongoDB会重新平衡数据,使每片的流量都比较均衡,数据量也在合理范围内。
mongos就是一个路由服务器,它会根据管理员设置的“片键”将数据分摊到自己管理的mongod集群,数据和片的对应关系以及相应的配置信息保存在“config服务器”上。
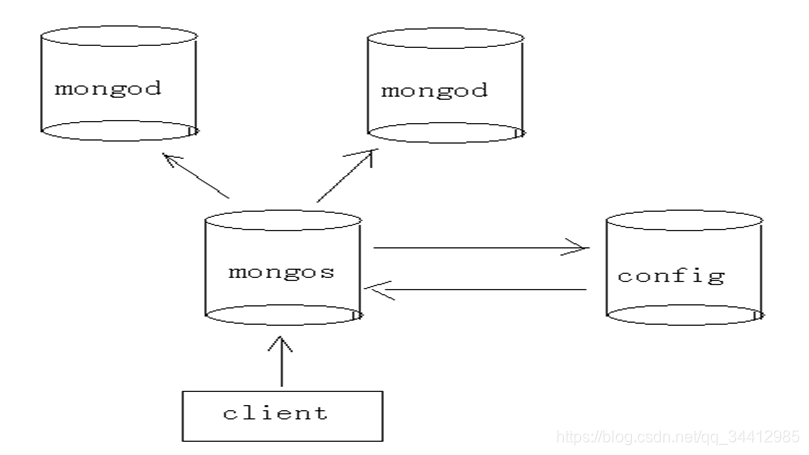
mongod:一个普通的数据库实例,如果不分片的话,我们会直接连上mongod。
1、创建三个目录,分别存放两个mongod服务的数据文件和config服务的数据文件
[wj@localhost data]$ sudo mkdir 20 21 22
启动两台实例服务器:
[wj@localhost data]$ sudo ./mongod --port 27020 --dbpath /usr/local/mongodb/data/20 --smallfiles --fork --logpath /usr/local/mongodb/logs/mongo20.log
[wj@localhost bin]$ sudo ./mongod --port 27021 --dbpath /usr/local/mongodb/data/21 --smallfiles --fork --logpath /usr/local/mongodb/logs/mongo21.log
准备configsvr
[wj@localhost bin]$ sudo ./mongod --port 27022 --dbpath /usr/local/mongodb/data/22 --configsvr --fork --logpath /usr/local/mongodb/logs/mongo22.log
准备mongos路由 configdb后面是configsvr的ip及端口
[wj@localhost bin]$ sudo ./mongos --port 30000 --configdb 192.168.125.128:27022 --fork --logpath /usr/local/mongodb/logs/mongo30.log
连接mongos路由
[wj@localhost bin]$ ./mongo --port 30000
添加分片shard
mongos> sh.addShard("192.168.125.128:27020");
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> sh.addShard("192.168.125.128:27021");
{ "shardAdded" : "shard0001", "ok" : 1 }
查看分片状态
mongos> sh.status()
选择库分片
mongos> sh.enableSharding("shop");
指定分片的库的collection的片键
mongos> sh.shardCollection('shop.goods',{goods_id:1});
mongos> use shop
添加测试数据
mongos> for(var i=1;i<=30000;i++){db.goods.insert({goods_id:i,goods_name:'hello world afdjfdkfdjjfajdlfdsfdf'})}
mongos> db.goods.find().count();
mongos> use config
mongos> db.settings.find();
设置chuckSize大小为1M
mongos> db.settings.save({_id:'chunksize',value:1})
mongodb不是从单篇文档的级别,绝对平均的散落在各个片上,
而是N篇文档,形成一个块"chunk",
优先放在某个片上,
当这片上的chunk,比另一个片的chunk,区别比较大时, (>=3) ,会把本片上的chunk,移到另一个片上, 以chunk为单位,
维护片之间的数据均衡
问: 为什么插入了10万条数据,才2个chunk?
答: 说明chunk比较大(默认是64M)
在config数据库中,修改chunksize的值.
问: 既然优先往某个片上插入,当chunk失衡时,再移动chunk,
自然,随着数据的增多,shard的实例之间,有chunk来回移动的现象,这将带来什么问题?
答: 服务器之间IO的增加,
接上问: 能否我定义一个规则, 某N条数据形成1个块,预告分配M个chunk,
M个chunk预告分配在不同片上.
以后的数据直接入各自预分配好的chunk,不再来回移动?
答: 能, 手动预先分片!
以shop.user表为例
1: sh.shardCollection(‘shop.user’,{userid:1}); //user表用userid做shard key
2: for(var i=1;i<=40;i++) { sh.splitAt('shop.user',{userid:i*1000}) } // 预先在1K 2K...40K这样的界限切好chunk(虽然chunk是空的), 这些chunk将会均匀移动到各片上.
3: 通过mongos添加user数据. 数据会添加到预先分配好的chunk上, chunk就不会来回移动了.
添加片后都需要手动分下片吗?configsvr和mongos单点安全可靠吗?replicaSet和sharding时主挂掉后会自动切换吗?