1.HashMap ЕФЕзВуЪ§ОнНсЙЙвдМАРЉШнЛњжЦЪЧдѕбљЕФЃП
ЕзВуЪ§ОнНсЙЙ:
JDK1.8 жЎЧА HashMap ЕзВуЪЧ Ъ§зщКЭСДБэ НсКЯдквЛ Ц№ЕФ,Ъ§зщРяУПИіДцДЂЕФЖдЯѓЪЧEntry<keyЃЌvalue>ЖдЯѓЃЌУПИіEntry<keyЃЌvalue>ЖдЯѓЖМАќКЌвЛИіЖдЯТИідЊЫиЕФв§гУ,РрЫЦгкРСД. ЕБHashMap ЕїгУputЗНЗЈдіМгдЊЫиЪБ,ЪзЯШЕїгУ key ЕФ hashCodeЗНЗЈ,ШЛКѓдйЭЈЙ§ЮЛдЫЫуДІРэЙ§КѓЕУЕН hash жЕ.,етЪЧЮЊСЫЗРжЙвЛаЉЪЕЯжБШНЯВюЕФ hashCode() ЗНЗЈ ЛЛОфЛАЫЕЪЙгУШХЖЏКЏЪ§жЎКѓПЩвдМѕЩйХізВ,ФмЙЛзюДѓЯоЖШЪЙгУЪ§зщПеМф,МѕЩйРЫЗб
int hash = hash(key) //ЕїгУЗНЗЈЫуГіhash//ЧѓГіHashжЕ
final int hash(Object k) {int h = hashSeed;if (0 != h && k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}ШЛКѓЭЈЙ§ hash & (n - 1) ХаЖЯЕБЧАдЊЫиДцЗХЕФЮЛжУЃЈетРяЕФ n жИЕФЪЧЪ§зщЕФГЄЖШЃЉЃЌШчЙћЕБЧАЮЛжУДцдк дЊЫиЕФЛАЃЌОЭХаЖЯИУдЊЫигывЊДцШыЕФдЊЫиЕФ hash жЕвдМА key ЪЧЗёЯрЭЌЃЌШчЙћЯрЭЌЕФЛА,жБНгИВИЧ,ВЛЯрЭЌОЭЭЈЙ§РСДЗЈНтОіГхЭЛ,АбзюаТЕФЪ§ОнЗХдкзюЧАУцРЯЕФЪ§ОнЭљКѓУцвЦЮЛ,вђЮЊВйзїЯЕЭГзмЪЧШЯЮЊзюНќЪЙгУЕФЪ§ОнЛсзюШнвзБЛЪЙгУЁЃ
ЭЌбљgetЗНЗЈЕїгУЪБЪЧЭЈЙ§keyЕФhashжЕОЙ§ЮЛдЫЫуЃЌШЛКѓдй&дЫЫуЧѓГіЪ§зщЯТБъЁЃШЁГіСДЬѕЁЃСДЬѕжЛгавЛЬѕЪ§ОнОЭЪЧетИіЪ§ОнЁЃШчЙћВЛЪЧОЭашвЊБщРњСДЬѕЩЯЕФЪ§Он(ЭЈЙ§hashCodeКЭequlsЗНЗЈХаЖЯ)ШЁГіЖдгІЕФkeyЕФvalueжЕЁЃ
public V put(K key, V value) {if (table == EMPTY_TABLE) {inflateTable(threshold);}if (key == null)return putForNullKey(value);int hash = hash(key); //ЫуГіhashжЕint i = indexFor(hash, table.length); //ЧѓГіЪ§зщЯТБъfor (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;//ЭЈЙ§етИіkeyЕФhashCodeКЭequalsЗНЗЈРДХаЖЯЕБЧАЕФkeyЪЧЗёДцдкif (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(hash, key, value, i);return null;}int i = indexFor(hash, table.length)//ЕїгУЗНЗЈЛёШЁЪ§зщЯТБъжЕ//ЭЈЙ§hashжЕКЭЪ§зщГЄЖШlength-1ЕФгыдЫЫуЧѓГіЪ§зщЯТБъжЕ
static int indexFor(int h, int length) {// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";return h & (length-1);}//ДДНЈЪ§зщдЊЫиENtryЖдЯѓ
void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);size++;}HashMapЕФФкДцЪ§зщНсЙЙ,УПИіЪ§зщдЊЫиЯТУцЛсСДЬѕдЊЫиЃЌЪ§зщМгСДБэЕФНсЙЙЃЌзюаТputНјРДЕФдЊЫизмЪЧЗХдкзюЩЯУц,РЯЕФдЊЫиЭљКѓУцвЦЮЛЁЃ
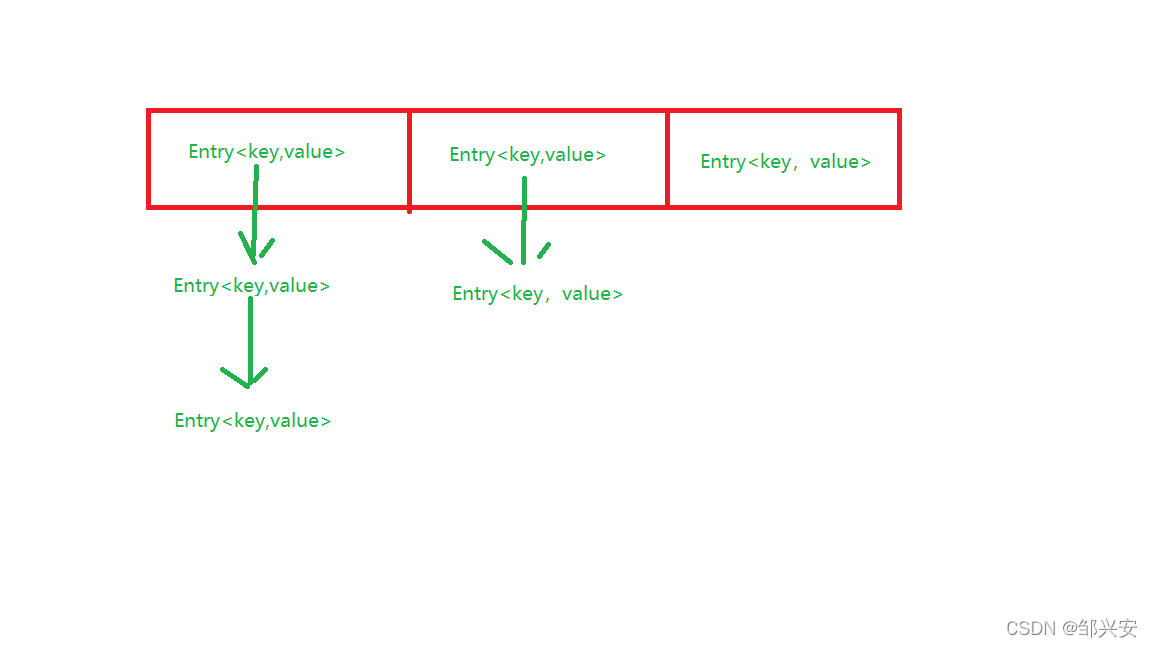
JDK1.8 жЎКѓ ПЊЪМФЌШЯЪ§ОнНсЙЙвВЪЧЪ§зщКЭСДБэ,Ъ§зщРяУцЕФдЊЫиВЛдйЪЧEntry<keyЃЌvalue>ЖдЯѓ,ЖјЪЧNode<keyЃЌvalue>ЖдЯѓ(Node<key,value>ЪЕЯжСЫMap.Entry<key,value>НгПк,ЪєадИњдРДВюВЛЖр)ЁЃЕБСДБэГЄЖШДѓгкуажЕЃЈФЌШЯЮЊ 8ЃЉМѕ1ЪБЃЌЛсЪзЯШЕїгУ treeifyBin()ЗНЗЈЁЃетИіЗНЗЈЛсИљОн HashMap Ъ§зщРДОіЖЈЪЧЗёзЊЛЛЮЊКьКкЪїЁЃжЛгаЕБЪ§зщГЄЖШДѓгкЛђепЕШгк 64 ЕФЧщПіЯТЃЌВХЛс жДаазЊЛЛКьКкЪїВйзїЃЌвдМѕЩйЫбЫїЪБМфЁЃЗёдђЃЌОЭЪЧжЛЪЧжДаа resize() ЗНЗЈЖдЪ§зщРЉШнЁЃжЎЫљвдвЊДяЕН64ГЄЖШЪЧвђЮЊжЛгаДяЕНетИіГЄЖШЪБВХФмЬхЯжКьКкЪїЕФЫбЫїаЇТЪБШжЎЧАЕФНсЙЙвЊПьЁЃЕБЗХШыдЊЫиВњЩњhashГхЭЛЪБЪЧЭљСДЬѕЯТУцЗХдЊЫи(jdk1.7жЎЧАЪЧЪЙгУЭЗВхЗЈ,JDK1.8ЪЙгУЮВВхЗЈ)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length; //ГѕЪМЛЏГЄЖШЮЊ16if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;//ХаЖЯдЊЫиЪЧЗёДцдкЕФЬѕМўИњJDK8жЎЧАвЛбљif (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {//аТЗХШыЕФдЊЫиЪЧЭљСДЬѕЯТУцвЦЮЛ,ЖјВЛЪЧдкJDK8жЎЧАаТЗХНјШЅЪ§ОндкзюЧАУцЁЃp.next = newNode(hash, key, value, null);//ЕБСДБэГЄЖШЕНДяуажЕВХЛсЕїгУtreeifyBin(tab, hash)ЗНЗЈif (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}//етИіЗНЗЈзюжеХаЖЯЪЧЗёашвЊзЊКьКкЪї
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)//Ъ§зщГЄЖШЪЧЗёДѓгк64ЃЌБШ //64аЁОЭРЉШнresize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);//зЊЛЛКьКкЪї}}РЉШнЛњжЦ:
jdk8жЎЧАКЭжЎКѓРЉШнЛњжЦВюВЛЖрЪЧвЛбљЕФЃЌЕБдЊЫиЪ§СПГЌЙ§уажЕЪББуЛсДЅЗЂРЉШнЁЃУПДЮРЉШнЕФШнСПЖМЪЧжЎЧАШнСПЕФ 2 БЖHashMap ЕФШнСПЪЧгаЩЯЯоЕФЃЌБиаыаЁгк 1<<30ЃЌМД 1073741824ЁЃШчЙћШнСПГЌГіСЫетИі Ъ§ЃЌдђВЛдйдіГЄЃЌЧвуажЕЛсБЛЩшжУЮЊ Integer.MAX_VALUEЁЃетИіуажЕЪЧЪ§зщЕФГЄЖШlength * ИКдивђзг(ФЌШЯЪЧ0.75f).РЉШнКѓЛсжиаТМЦЫуОЩЪ§зщжадЊЫиЕФДцДЂЮЛжУЁЃдЊЫидкаТЪ§зщжаЕФЮЛжУжЛгаСНжжЃЌдЯТБъЮЛжУЛђдЯТБъ+ОЩЪ§зщЕФДѓаЁ
жЕЕУзЂвтЕФЪЧ jdk1.8жаКьКкЪїКЭСДБэЛсЯрЛЅзЊЛЛ,ЕБСДБэаЁгк8ЪБЛсзЊЛЛЮЊСДБэ,ЗДжЎдђзЊЛЛКьКкЪїЁЃ
КѓМЧЃКжЎЫљвдбЁдёКьКкЪїЪЧЮЊСЫНтОіЖўВцВщевЪїЕФШБЯнЃЌЖўВцВщевЪїдкЬиЪтЧщПіЯТЛсБфГЩвЛЬѕЯпадНсЙЙЃЈетОЭИњдРДЪЙгУСДБэНсЙЙвЛбљСЫЃЌдьГЩКмЩюЕФЮЪЬтЃЉЃЌБщРњВщевЛсЗЧГЃТ§ЁЃЖјКьКкЪїдкВхШыаТЪ§ОнКѓПЩФмашвЊЭЈЙ§зѓа§ЃЌгва§ЁЂБфЩЋетаЉВйзїРДБЃГжЦНКтЃЌв§ШыКьКкЪїОЭЪЧЮЊСЫВщевЪ§ОнПьЃЌНтОіСДБэВщбЏЩюЖШЕФЮЪЬтЃЌЮвУЧжЊЕРКьКкЪїЪєгкЦНКтЖўВцЪїЃЌЕЋЪЧЮЊСЫБЃГжЁАЦНКтЁБЪЧашвЊИЖГіДњМлЕФЃЌЕЋЪЧИУДњМлЫљЫ№КФЕФзЪдДвЊБШБщРњЯпадСДБэвЊЩйЃЌЫљвдЕБГЄЖШДѓгк8ЕФЪБКђЃЌЛсЪЙгУКьКкЪїЃЌШчЙћСДБэГЄЖШКмЖЬЕФЛАЃЌИљБОВЛашвЊв§ШыКьКкЪїЃЌв§ШыЗДЖјЛсТ§
void addEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<K,V>(hash, key, value, e);if (size++ >= threshold)//threshold жЕЕШгкЪ§зщГЄЖШ * ИКдивђзгresize(2 * table.length); //РЉШнЪЧ2БЖГЄЖШ}НтОіhashГхЭЛЕФАьЗЈгаФФаЉ?HashMapгУЕФФФжжЃП
НтОіHashГхЭЛЗНЗЈгаЃКПЊЗХЖЈжЗЗЈЁЂдйЙўЯЃЗЈЁЂСДЕижЗЗЈЃЈHashMapжаГЃМћЕФРСДЗЈЃЉЁЂМђРњЙЋ ЙВвчГіЧјЁЃHashMapжаВЩгУЕФЪЧСДЕижЗЗЈЁЃ
-
ПЊЗХЖЈжЗЗЈвВГЦЮЊдйЩЂСаЗЈЃЌЛљБОЫМЯыОЭЪЧЃЌШчЙћp=H(key)ГіЯжГхЭЛЪБЃЌдђвдpЮЊЛљДЁЃЌдйДЮhashЃЌp1=H(p)ЃЌШчЙћp1дйДЮГіЯжГхЭЛЃЌдђвдp1ЮЊЛљДЁЃЌвдДЫРрЭЦЃЌжБЕНевЕНвЛИіВЛГхЭЛЕФЙўЯЃЕижЗpiЁЃвђДЫПЊЗХЖЈжЗЗЈЫљашвЊЕФhashБэЕФГЄЖШвЊДѓгкЕШгкЫљашвЊДцЗХЕФдЊЫиЃЌЖјЧввђЮЊДцдкдйДЮhashЃЌЫљвджЛФмдкЩОГ§ЕФНкЕуЩЯзіБъМЧЃЌЖјВЛФмеце§ЩОГ§НкЕу
-
дйЙўЯЃЗЈЃЈЫЋжиЩЂСаЃЌЖржиЩЂСаЃЉЃЌЬсЙЉЖрИіВЛЭЌЕФhashКЏЪ§ЃЌR1=H1(key1)ЗЂЩњГхЭЛЪБЃЌдйМЦЫуR2=H2ЃЈkey1ЃЉЃЌжБЕНУЛгаГхЭЛЮЊжЙЁЃетбљзіЫфШЛВЛвзВњЩњЖбМЏЃЌЕЋдіМгСЫМЦЫуЕФЪБМфЁЃ
-
СДЕижЗЗЈЃЈРСДЗЈЃЉЃЌНЋЙўЯЃжЕЯрЭЌЕФдЊЫиЙЙГЩвЛИіЭЌвхДЪЕФЕЅСДБэЃЌВЂНЋЕЅСДБэЕФЭЗжИеыДцЗХдкЙўЯЃБэЕФЕкiИіЕЅдЊжаЃЌВщевЁЂВхШыКЭЩОГ§жївЊдкЭЌвхДЪСДБэжаНјааЃЌСДБэЗЈЪЪгУгкОГЃНјааВхШыКЭЩОГ§ЕФЧщПіЁЃ
-
НЈСЂЙЋЙВвчГіЧјЃЌНЋЙўЯЃБэЗжЮЊЙЋЙВБэКЭвчГіБэЃЌЕБвчГіЗЂЩњЪБЃЌНЋЫљгавчГіЪ§ОнЭГвЛЗХЕНвчГіЧј
зЂвтПЊЗХЖЈжЗЗЈКЭдйЙўЯЃЗЈЕФЧјБ№ЪЧ
-
ПЊЗХЖЈжЗЗЈжЛФмЪЙгУЭЌвЛжжhashКЏЪ§НјаадйДЮhashЃЌдйЙўЯЃЗЈПЩвдЕїгУЖржжВЛЭЌЕФhashКЏЪ§НјаадйДЮhash
HashMapЮЊЪВУДЯпГЬВЛАВШЋЃП
-
ЖрЯпГЬЯТРЉШнЫРбЛЗЁЃJDK1.7жаЕФHashMapЪЙгУЭЗВхЗЈВхШыдЊЫиЃЌдкЖрЯпГЬЕФЛЗОГЯТЃЌРЉШнЕФЪБКђгаПЩФмЕМжТЛЗаЮСДБэЕФГіЯжЃЌаЮГЩЫРбЛЗЁЃвђДЫJDK1.8ЪЙгУЮВВхЗЈВхШыдЊЫиЃЌдкРЉШнЪБЛсБЃГжСДБэдЊЫидБОЕФЫГађЃЌВЛЛсГіЯжЛЗаЮСДБэЕФЮЪЬт
-
ЖрЯпГЬЕФputПЩФмЕМжТдЊЫиЕФЖЊЪЇЁЃЖрЯпГЬЭЌЪБжДааputВйзїЃЌШчЙћМЦЫуГіРДЕФЫїв§ЮЛжУЪЧЯрЭЌЕФЃЌФЧЛсдьГЩЧАвЛИіkeyБЛКѓвЛИіkeyИВИЧЃЌДгЖјЕМжТдЊЫиЕФЖЊЪЇЁЃДЫЮЪЬтдкJDK1.7КЭJDK1.8жаЖМДцдк
-
putКЭgetВЂЗЂЪБЃЌПЩФмЕМжТgetЮЊnullЁЃЯпГЬ1жДааputЪБЃЌвђЮЊдЊЫиИіЪ§ГЌГіthresholdЖјЕМжТrehashЃЌЯпГЬ2ДЫЪБжДааgetЃЌгаПЩФмЕМжТетИіЮЪЬтЃЌДЫЮЪЬтдкJDK1.7КЭJDK1.8жаЖМДцдк
2.ConcurrentHashMap ЕФДцДЂНсЙЙЪЧдѕбљЕФЃП
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching argumentsint sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}segmentShift = 32 - sshift;segmentMask = ssize - 1;this.segments = Segment.newArray(ssize);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = 1;while (cap < c)cap <<= 1;for (int i = 0; i < this.segments.length; ++i)//ГѕЪМЛЏSegmentsЪ§зщжаУПИіЖдЯѓthis.segments[i] = new Segment<K,V>(cap, loadFactor);}//putЗНЗЈДцШыдЊЫи
V put(K key, int hash, V value, boolean onlyIfAbsent) {lock();//УПИіSegmentЖдЯѓНјРДЪЧЫјзЁtry {int c = count;if (c++ > threshold) // ensure capacityrehash();//РЉШнЛњжЦКЭHahshMapвЛбљHashEntry<K,V>[] tab = table;int index = hash & (tab.length - 1);HashEntry<K,V> first = tab[index];HashEntry<K,V> e = first;while (e != null && (e.hash != hash || !key.equals(e.key)))e = e.next;V oldValue;if (e != null) {oldValue = e.value;if (!onlyIfAbsent)e.value = value;}else {oldValue = null;++modCount;tab[index] = new HashEntry<K,V>(key, hash, first, value);count = c; // write-volatile}return oldValue;} finally {unlock();}}LinkedHashMap БЃДцСЫМЧТМЕФВхШыЫГађЃЌЮЌЛЄСЫвЛИіЫЋЯђСДБэ(ИњLinkedListгаЕуРрЫЦ)дкгУ Iterator БщРњЪБЃЌЯШШЁЕНЕФМЧТМПЯЖЈЪЧЯШВхШыЕФ;БщРњБШ HashMap Т§ЁЃвЛАудкашвЊЪфГіЕФЫГађКЭЪфШыЕФЫГађЯрЭЌЕФЧщПіЯТЪЙгУЁЃ
TreeMap ЪЕЯж SortMap НгПкЃЌФмЙЛАбЫќБЃДцЕФМЧТМИљОнМќХХађЃЈФЌШЯАДМќжЕЩ§ађХХађЃЌвВПЩвджИ ЖЈХХађЕФБШНЯЦїЃЌcompareЃЉЁЃ
HashTableЪЧЗНЗЈЪЧгУsynchronizedЙиМќаоЪЮЕФ,ЫљвдЪЧЯпГЬАВШЋЁЃвВЪЧвђЮЊетЫќБШHashMapаЇТЪ ЛсЕЭ
LinkedListЪЧЫЋЯђСДБэМЏКЯЃЌУПвЛИідЊЫиЖМСНИіЪєаджИЯђЧАУцКЭКѓУцЕФдЊЫи,LinkedList БШ ArrayList ИќеМФкДцЃЌвђЮЊ LinkedList ЕФНкЕуГ§СЫДцДЂЪ§ОнЃЌЛЙДцДЂСЫСНИів§гУЃЌвЛИіжИЯђЧАвЛИідЊЫиЃЌвЛИіжИЯђКѓвЛИідЊЫиЁЃЪЙгУСДБэЪЕЯжЃЌЮоашРЉШнЁЃ LinkedList ВЩгУСДБэДцДЂЃЌЫљвдЃЌШчЙћЪЧдкЭЗЮВВхШыЛђепЩОГ§дЊЫиВЛЪмдЊЫиЮЛжУЕФгА ЯьЃЈadd(E e)ЁЂaddFirst(E e)ЁЂaddLast(E e)ЁЂremoveFirst() ЁЂ removeLast()ЃЉЃЌНќЫЦ O(1)ЃЌШчЙћЪЧвЊдкжИЖЈЮЛжУ i ВхШыКЭЩОГ§дЊЫиЕФЛАЃЈadd(int index, E element)ЃЌremove(Object o)ЃЉ ЪБМфИДдгЖШНќЫЦЮЊ O(n) ЃЌвђЮЊашвЊЯШвЦЖЏЕНжИЖЈЮЛжУдйВхШыЁЃ
ArryList ЪЧЪ§зщДцДЂЃЌЕБашвЊВщбЏБШНЯЖрЪБ,ЪЙгУетИіБШНЯПьЃЌжБНгВщбЏЯТБъОЭФмевЕНдЊЫиЁЃЪЙгУЪ§зщЪЕЯжЃЌашвЊРЉШнЁЃArrayList ВЩгУЪ§зщДцДЂЃЌЫљвдВхШыКЭЩОГ§дЊЫиЕФЪБМфИДдгЖШЪмдЊЫиЮЛжУЕФгАЯьЁЃБШШчЃКжДаа add(E e)ЗНЗЈЕФЪБКђЃЌ ArrayList ЛсФЌШЯдкНЋжИЖЈЕФдЊЫизЗМгЕНДЫСаБэЕФФЉЮВЃЌетжжЧщПіЪБМфИДдгЖШОЭЪЧ O(1)ЁЃЕЋЪЧШчЙћвЊдкжИЖЈЮЛжУ i ВхШыКЭЩОГ§дЊЫиЕФЛАЃЈadd(int index, E element)ЃЉЪБМфИДдгЖШОЭЮЊ O(n-i)ЁЃвђЮЊдкНјааЩЯЪіВйзїЕФЪБКђМЏКЯжаЕк i КЭЕк i ИідЊЫижЎКѓЕФ(n-i)ИідЊЫиЖМвЊжДааЯђКѓЮЛ/ЯђЧАвЦвЛЮЛЕФВйзїЁЃ
HashSetЕзВуЪЧгУHashMapРДЪЕЯжЕФЃЌЬэМгЕФдЊЫиЪБВЛФмжиИДЕФЃЌвђЮЊkeyЕФЮЈвЛадОіЖЈЕФЁЃ
4ЁЂ Queue гы Deque ,PriorityQueue ЕФЧјБ№
Queue ЪЧЕЅЖЫЖгСаЃЌжЛФмДгвЛЖЫВхШыдЊЫиЃЌСэвЛЖЫЩОГ§дЊЫиЃЌЪЕЯжЩЯвЛАузёбЯШНјЯШГі ЃЈFIFOЃЉ ЙцдђЁЃQueue РЉеЙСЫ Collection ЕФНгПкЃЌИљОн вђЮЊШнСПЮЪЬтЖјЕМжТВйзїЪЇАмКѓДІРэЗНЪНЕФВЛЭЌ ПЩвдЗжЮЊСНРрЗНЗЈ: вЛжждкВйзїЪЇАмКѓЛсХзГівьГЃЃЌСэвЛжждђЛсЗЕЛиЬиЪтжЕЁЃQueue НгПкХзГівьГЃ ЗЕЛиЬиЪтжЕ
ВхШыЖгЮВ add(E e) offer(E e)
ЩОГ§ЖгЪз remove() poll()
ВщбЏЖгЪздЊЫи element() peek()
Deque ЪЧЫЋЖЫЖгСаЃЌдкЖгСаЕФСНЖЫОљПЩвдВхШыЛђЩОГ§дЊЫиЁЃ Deque РЉеЙСЫ Queue ЕФНгПк, діМгСЫдкЖгЪзКЭЖгЮВНјааВхШыКЭЩОГ§ЕФЗНЗЈЃЌЭЌбљИљОнЪЇАмКѓДІРэЗНЪНЕФВЛЭЌЗжЮЊСНРрЃК
Deque НгПк ХзГівьГЃ ЗЕЛиЬиЪтжЕ133
ВхШыЖгЪз addFirst(E e) offerFirst(E e)
ВхШыЖгЮВ addLast(E e) offerLast(E e)
ЩОГ§ЖгЪз removeFirst() pollFirst()
ЩОГ§ЖгЮВ removeLast() pollLast()
ВщбЏЖгЪздЊЫи getFirst() peekFirst()
ВщбЏЖгЮВдЊЫи getLast() peekLast()
ЪТЪЕЩЯЃЌDeque ЛЙЬсЙЉга push() КЭ pop() ЕШЦфЫћЗНЗЈЃЌПЩгУгкФЃФтеЛЁЃ
PriorityQueue ЪЧдк JDK1.5 жаБЛв§ШыЕФ, Цфгы Queue ЕФЧјБ№дкгкдЊЫиГіЖгЫГађЪЧгыгХЯШ МЖЯрЙиЕФЃЌМДзмЪЧгХЯШМЖзюИпЕФдЊЫиЯШГіЖгЁЃетРяСаОйЦфЯрЙиЕФвЛаЉвЊЕуЃК PriorityQueue РћгУСЫЖўВцЖбЕФЪ§ОнНсЙЙРДЪЕЯжЕФЃЌЕзВуЪЙгУПЩБфГЄЕФЪ§зщРДДцДЂЪ§Он PriorityQueue ЭЈЙ§ЖбдЊЫиЕФЩЯИЁКЭЯТГСЃЌЪЕЯжСЫдк O(logn) ЕФЪБМфИДдгЖШФкВхШыдЊЫиКЭЩОГ§ЖбЖЅдЊЫиЁЃPriorityQueue ЪЧЗЧЯпГЬАВШЋЕФЃЌЧвВЛжЇГжДцДЂ NULL КЭ non-comparable ЕФЖдЯѓЁЃ PriorityQueue ФЌШЯЪЧаЁЖЅЖбЃЌЕЋПЩвдНгЪевЛИі Comparator зїЮЊЙЙдьВЮЪ§ЃЌДгЖјРДздЖЈвхдЊЫигХЯШМЖЕФЯШКѓЁЃ
5.TreeMap КЭ TreeSet дкХХађЪБШчКЮБШНЯдЊЫиЃЌCollections ЙЄОпРржаЕФ sort()ЗНЗЈШчКЮБШНЯдЊЫиЃП
TreeSet вЊЧѓДцЗХЕФЖдЯѓЫљЪєЕФРрБиаыЪЕЯж Comparable НгПкЃЌИУНгПкЬсЙЉСЫБШНЯдЊЫиЕФ compareTo()ЗНЗЈЃЌЕБВхШыдЊЫиЪБЛсЛиЕїИУЗНЗЈБШНЯдЊЫиЕФДѓаЁЁЃTreeMap вЊЧѓДцЗХЕФМќжЕЖдгГЩфЕФМќБиаыЪЕЯж Comparable НгПкДгЖјИљОнМќЖддЊЫиНјааХХађЁЃCollections ЙЄОпРрЕФ sort ЗНЗЈгаСНжжжидиЕФаЮЪНЃК
ЕквЛжжвЊЧѓДЋШыЕФД§ХХађШнЦїжаДцЗХЕФЖдЯѓБШНЯЪЕЯж Comparable НгПквдЪЕЯждЊЫиЕФБШ НЯЁЃЕкЖўжжВЛЧПжЦадЕФвЊЧѓШнЦїжаЕФдЊЫиБиаыПЩБШНЯЃЌЕЋЪЧвЊЧѓДЋШыЕкЖўИіВЮЪ§ЃЌВЮЪ§ЪЧ Comparator НгПкЕФзгРраЭЃЈашвЊжиаД compare ЗНЗЈЪЕЯждЊЫиЕФБШНЯЃЉЃЌЯрЕБгквЛИіСйЪБЖЈ вхЕФХХађЙцдђЃЌЦфЪЕОЭЪЧЭЈЙ§НгПкзЂШыБШНЯдЊЫиДѓаЁЕФЫуЗЈЃЌвВЪЧЖдЛиЕїФЃЪНЕФгІгУЃЈJava жаЖдКЏЪ§ЪНБрГЬЕФжЇГжЃЉЁЃ
6.Collection КЭ Collections гаЪВУДЧјБ№ЃП
java.util.Collection ЪЧвЛИіМЏКЯНгПкЃЈМЏКЯРрЕФвЛИіЖЅМЖНгПкЃЉЁЃЫќЬсЙЉСЫЖдМЏКЯЖдЯѓНј ааЛљБОВйзїЕФЭЈгУНгПкЗНЗЈЁЃCollection НгПкдк Java РрПтжагаКмЖрОпЬхЕФЪЕЯжЁЃCollection НгПкЕФвтвхЪЧЮЊИїжжОпЬхЕФМЏКЯЬсЙЉСЫзюДѓЛЏЕФЭГвЛВйзїЗНЪНЃЌЦфжБНгМЬГаНгПкга List гы SetЁЃ
Collections дђЪЧМЏКЯРрЕФвЛИіЙЄОпРр/АяжњРрЃЌЦфжаЬсЙЉСЫвЛЯЕСаОВЬЌЗНЗЈЃЌгУгкЖдМЏКЯ жадЊЫиНјааХХађЁЂЫбЫївдМАЯпГЬАВШЋЕШИїжжВйзїЁЃ