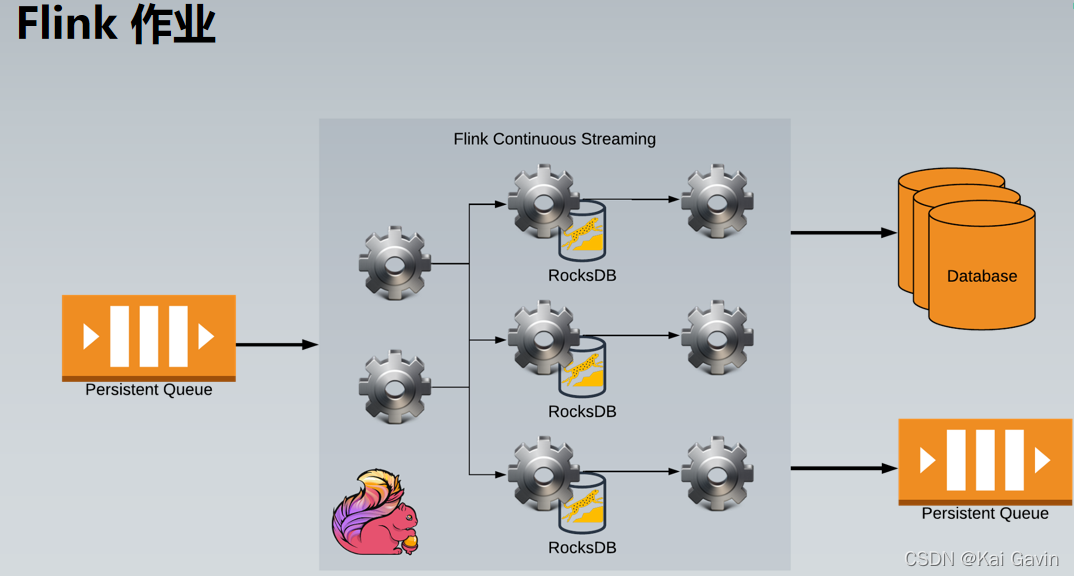
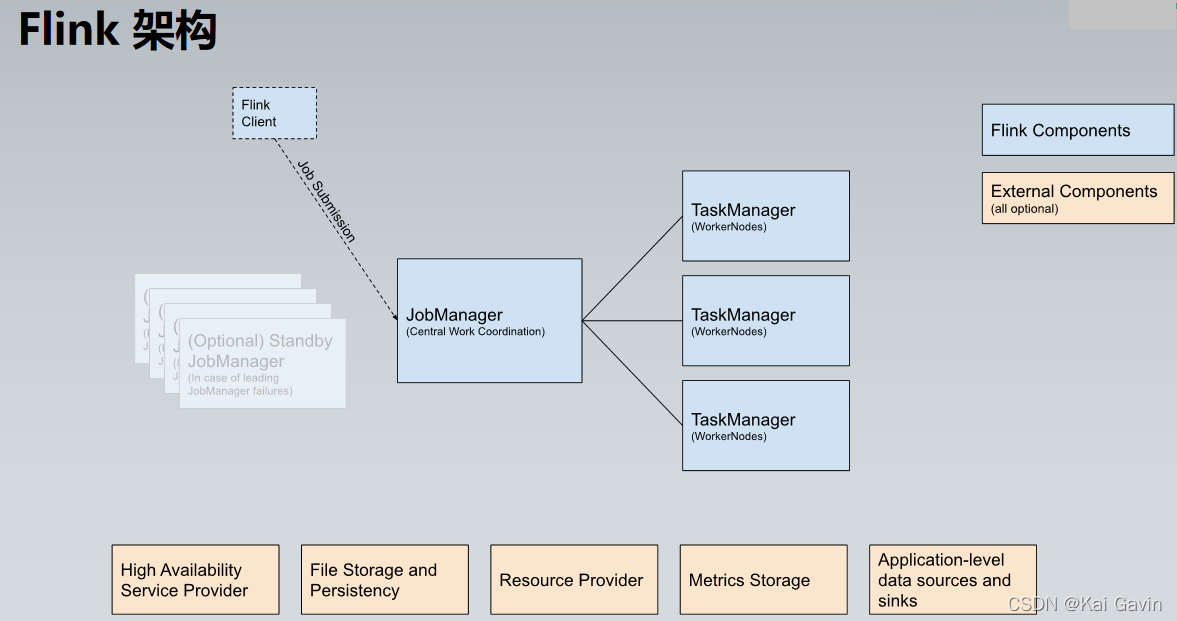

Flink �����Ų� - ��ҵ����ʧ�� ������ҵ�������ύ������
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| ����������뼯Ⱥ�������ڰ汾��ͻ |
��־��NoSuchMethodError/ IncompatibleClassChangeError/ ClassCastException |
1. ������� Flink/Hadoop ���������Ϊ provided2. ʹ�� Maven-Shade-Plugin 3. ���� classloader.resolve-order |
| �����ȱ������ |
��־��1.NoClassDefFoundError 2.NoMatchingTableFactory 3.Could not instantiate the executor |
����������� connector ���� ����������� planner ���� ���� 1.11 ֮�������Ҫ���� flink-client ���� |
| Flink Client ȱ������ |
Client ��־��Could not build the program from jar file. NoClassDefFoundError: hadoop/jersey |
Flink lib Ŀ¼���� flink-hadoop-shade-uber-jar Flink lib Ŀ¼���� jersey-core-jar |
| ��Ⱥ��Դ���� |
Client ��־��Deploy took more than 60s Slot allocation request timed out |
���伯Ⱥ��Դ ���������ж� |
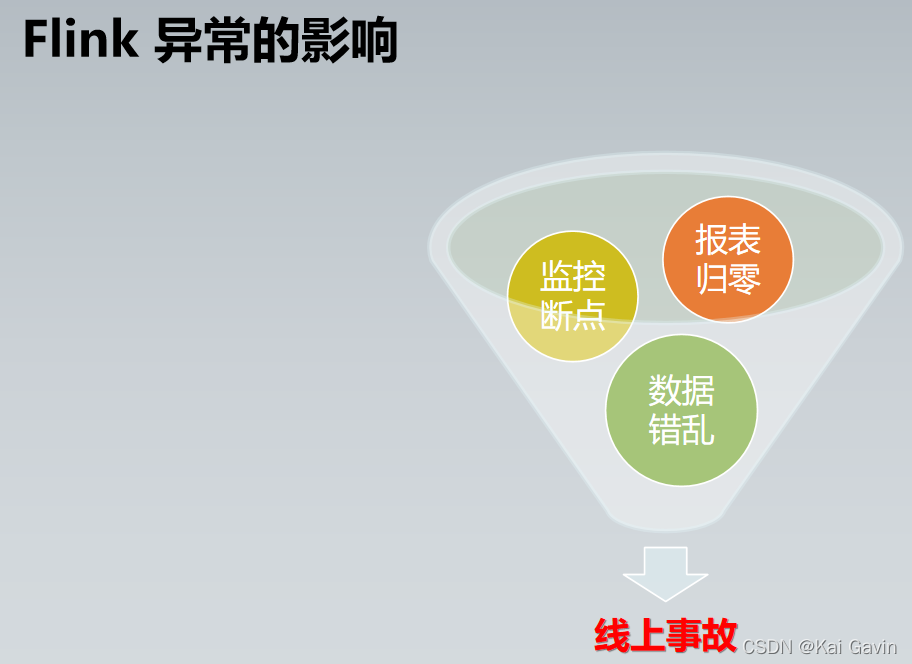
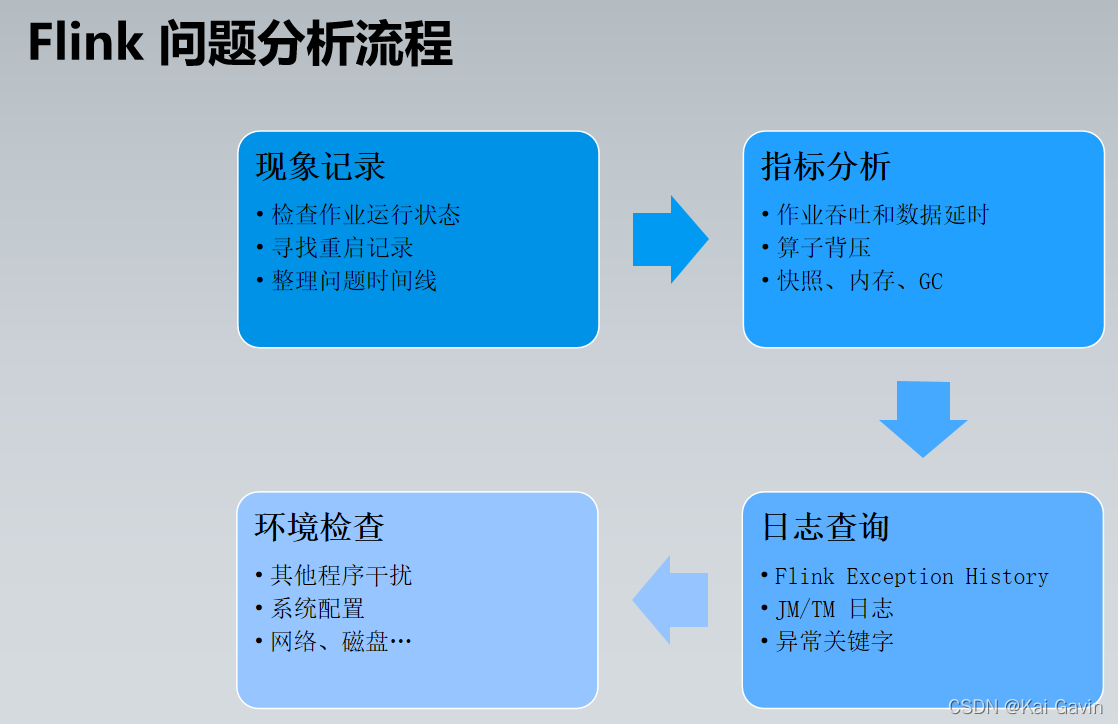
Flink �����Ų� - ��ҵ�����쳣 ������ҵͻȻֹͣ�����Ҳ��ָ�
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| Source ����ʵ�ַ�������ȷ |
JM ��־����ҵ������ FINISHED (SUCCEEDED) ״̬ |
�� Source ���ӵ�ʵ�֣����� while true ѭ�� |
| ��ҵ���������ﵽ��ֵ |
TM ��־��restart strategy prevented it |
1. �ҳ���ҵ��������ԭ�� 2. ���� RestartStrategy ��ֵ���� yarn.application-attempt ��ֵ |
| JVM �ڴ��������� YARN/K8s ��ֵ |
JM ��־��Killing container |
ͨ����Ϊ RocksDB �ڴ治�ܿص��£�������Ϊ Flink 1.11 ���ϰ汾 Ҳ�������û����������ֱ���ڴ� |
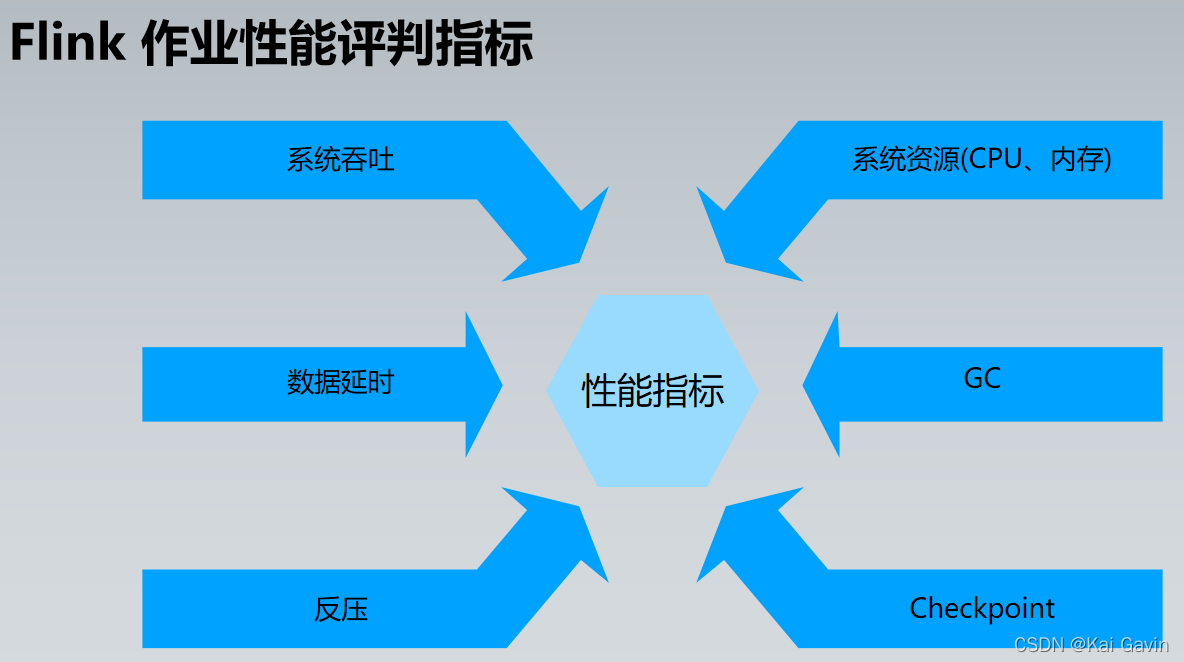
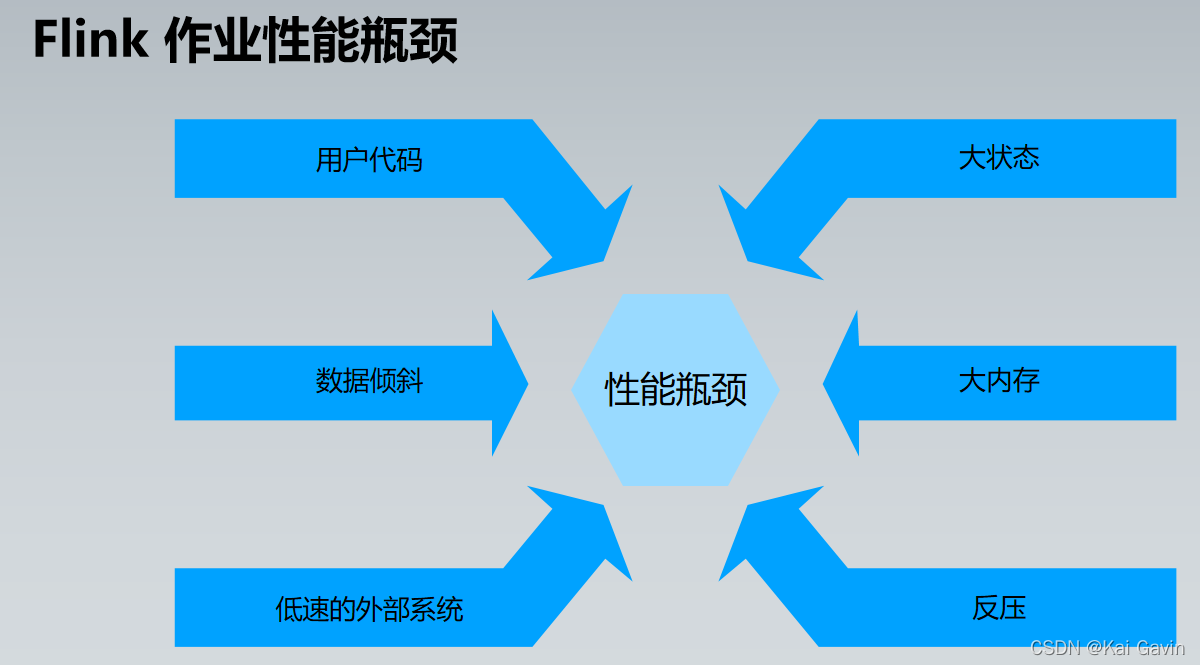
Flink �����Ų� - ��ҵ�������� ������ҵ��������ȶ������Dz���Ԥ��ֵ��5000 ~ 20000 ��/��/�ˣ�
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| ���������������� |
ָ�꣺CPU ʹ���ʺܸ� ������Kryo �ȷ���ռ�Ⱥܸ� |
1. ���ٲ���Ҫ�� rebalance 2. ���ø���Ч�� ���л���� |
| �㷨ʱ�临�Ӷȸߣ����� hashCode�� |
ָ�꣺CPU ʹ���ʺܸ� �������û��Զ��巽��ռ�ȸ� |
�Ż��Զ��巽������ʵ�� ������ҵ���ж� |
| ������б |
ָ�꣺ij���ӵIJ�ͬ������ ���롢���ָ�����ܴ� |
key ��ɢ��rebalance��Ԥ�ۺ� |
| �����ⲿϵͳ |
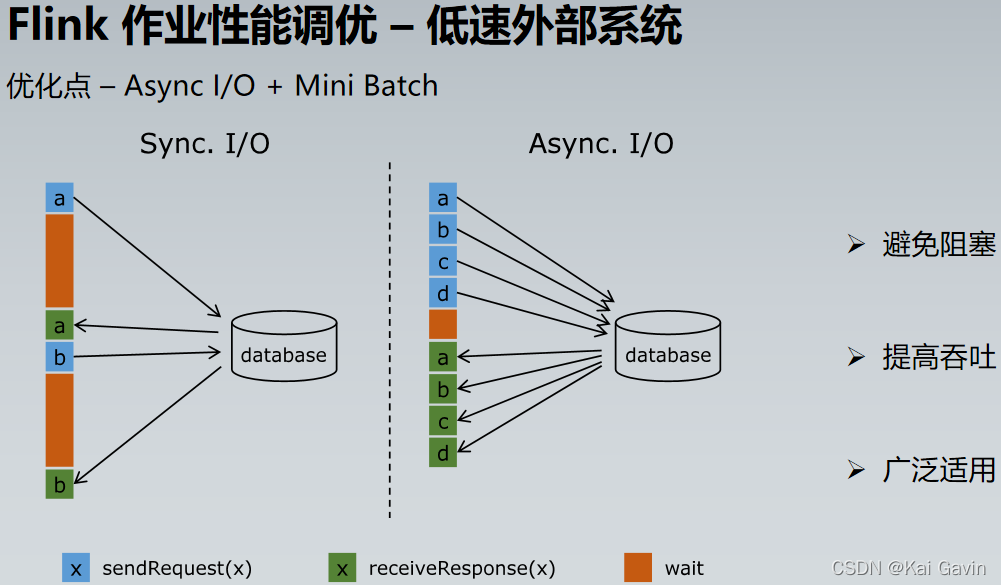
ָ�꣺CPU �����ʵ� �������ⲿ IO ��ʱ�� |
1. ������ȡ 2. ���ػ��� 3. Async I/O �첽���� |
Flink �����Ų� - ��ҵ�������� ������ҵ��������٣�������ȫ�����
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| ���ӱ�ѹ�ϸ� |
ָ�꣺Flink UI ��ѹ���� ��ʾ��ɫ��HIGH�� |
�ɸ��� ��ѹ������ �ж�ƿ�����ӣ�������е��� |
| Full GC ʱ�䳤 |
ָ�꣺GC ʱ������Ѹ�� ��־��GC ��־�� Full GC Ƶ�� |
1. ���Ӷ��ڴ����� 2. �Ż����ڴ�ʹ�� |
| ����Դ��Source�������/�����쳣 |
�½���ҵ��ֻ��������Դ�������������ӣ������ Blackhole Sink |
�����������Ȼ����������˵������Դ������ |
| ����Ŀ�ģ�Sink��д����/�����쳣 |
ʹ�� Datagen Source��ֱ�����������Ŀ�� |
�����������Ȼ����������˵������Ŀ�������� |
| ���ݸ�ʽ�쳣�������� |
��־�����ڴ��������쳣�������������ݱ����������������� |
�������������쳣���� |
| ����̫Ƶ�� �������չ��� ���ڴ���״̬���� |
ָ�꣺Flink UI �鿴�������յĴ�С�Լ����ʱ�䡣 ָ�꣺�鿴ÿ�� TaskManager �Ķ��ڴ������� |
1. ������սϴ����ʱ��ϳ������Ǽ��ٿ���Ƶ�ʣ�����ʱʱ�䡣 2. snapshotState ��������ͬ������ 3. �����������ջ�Ƕ�����㡣 4. ����õ����ڣ����Լ��ٴ��ڴ�С������ Sliding ���ڵ��ƶ����ڡ� 5. ����õ� GROUP BY������ Idle State Retention Time. 6. �Զ���״̬������ State TTL. |
| Watermark ���쳣���ݴ��� |
ָ�꣺���ӵ� Watermark ֵԶ���ڵ�ǰʱ����� |
�ҳ�������ʱ��������쳣�����ݣ����糬����ǰʱ���̫�õ����ݣ� |
Flink �����Ų� - ��ҵ�����쳣 �����������ݶ�ʧ
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| ������̣����� |
��־���۲���־���Ƿ����쳣�� �������ر� Operator Chaining��Ȼ��������ӹ۲�ָ�ꡢ������ |
�������⣬�� Savepoint ����������ҵ |
| �������ݸ�ʽ�쳣����������α����� |
ͬ�� |
����쳣�������ݴ�����������ʱ�ر������������ܡ� |
| ����Դ��Ԫ���ݸı� |
����Ƿ��������ڼ�ı�������Դ�ķ��������������Ԫ���� |
��������ʱ�����Զ����� �����������ڼ�������Դ |
| ����Ŀ�IJ�����ijЩ���� |
��־���������Ŀ�ģ�Sink������ر������쳣 |
�ſ����ݿ�������ơ� ���˻�ȫ�쳣���ݡ� |
Flink �����Ų� - ��ҵ�����쳣 ������������������
| ���ܳ��� |
ȷ�Ϸ��� |
�����ʩ |
| �Ӵ���� Checkpoint/Savepoint ��ʼ���� |
��־���۲���־�� Kafka �� Source �� offset �Ƿ���� ָ�꣺�۲����� Lag �Ƿ���� |
ѡ����ȷ�� Savepoint�� ����������ҵ |
| ����Դ�����쳣 |
��־���۲���־�� Kafka �� Source �Ƿ�����쳣 ָ�꣺�۲� Kafka ������ Lag �Ƿ�ӽ� |
�ֶ�ָ�� offset���������� |
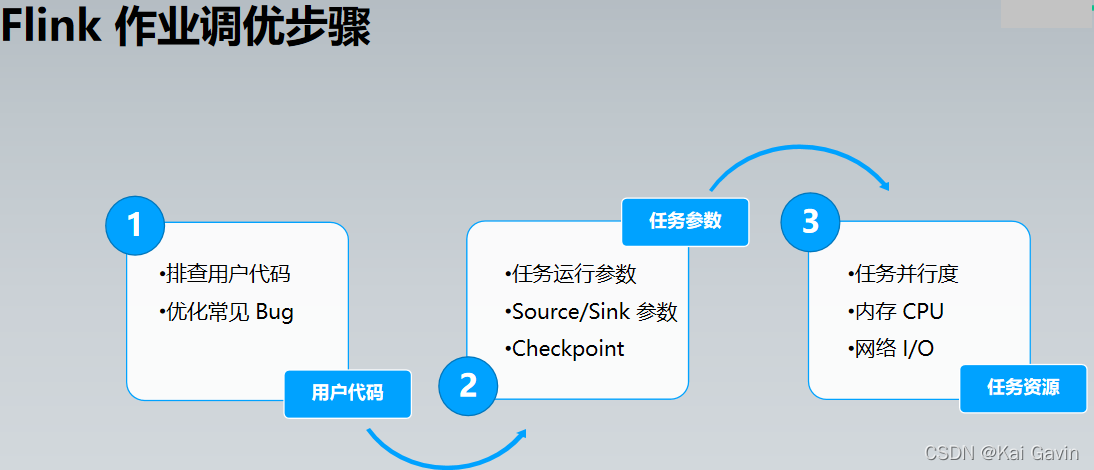
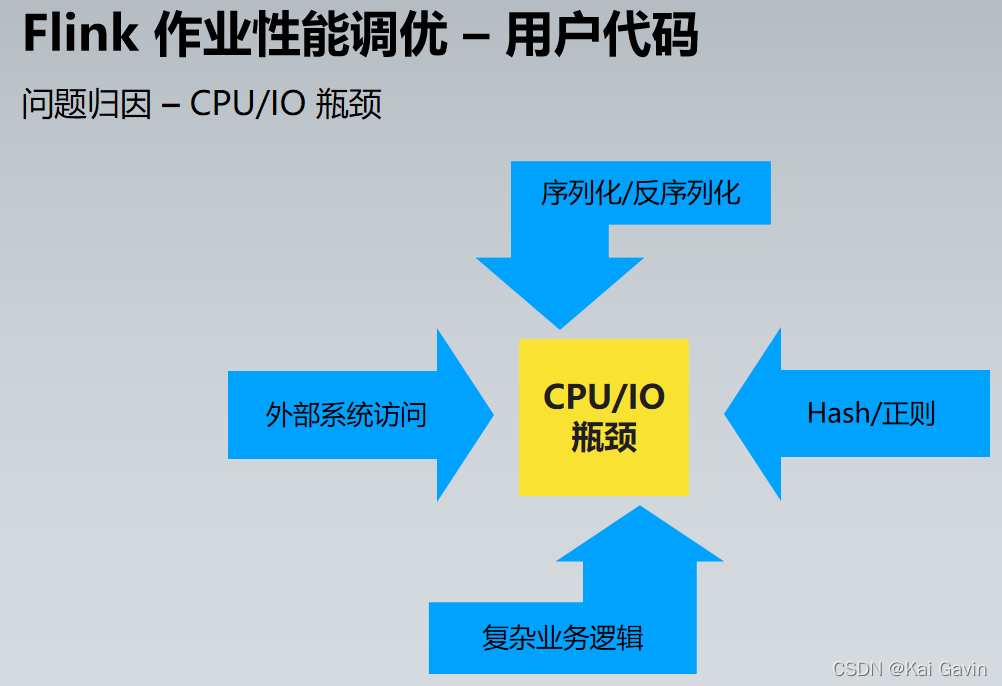

Flink ��ҵ���ܵ��� �C ������Դ
| ����ƿ�� |
����ָ�� |
�����ʩ |
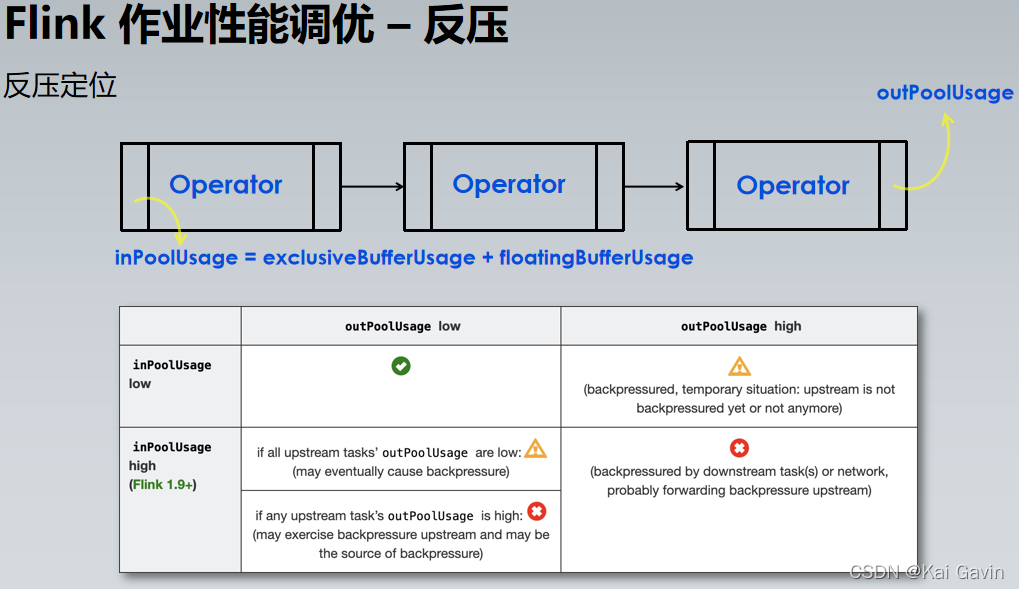
| �����ж� |
ָ�꣺�������� Lag��Operator Subtask ֮������������ |
���ú��ʵĵ������жȣ�һ���� Source �ķ�������ͬ�������ȼ�������>env>������>�����ļ� |
| �ڴ� |
ָ�꣺1. �������� Lag 2. �۲� JM/TM Metrics - Memory & GC �����쳣 |
�����ڴ� �ֶ�ָ���ڴ��������� |
| CPU |
ָ�꣺���� CPU ʹ���ʽӽ� 100%�������ȵ㷽�����Ĵ��� CPU ʱ�� |
JStack/JProfiler �ҵ� CPU ���ĸߵķ�������һ������ |
| ���� |
ָ�꣺Network Memory Netty Shuffle Buffers |
1.�Ӵ� Network Buffer2.���� Operator Chain���������� shuffle 3.ʹ�ô�������� |
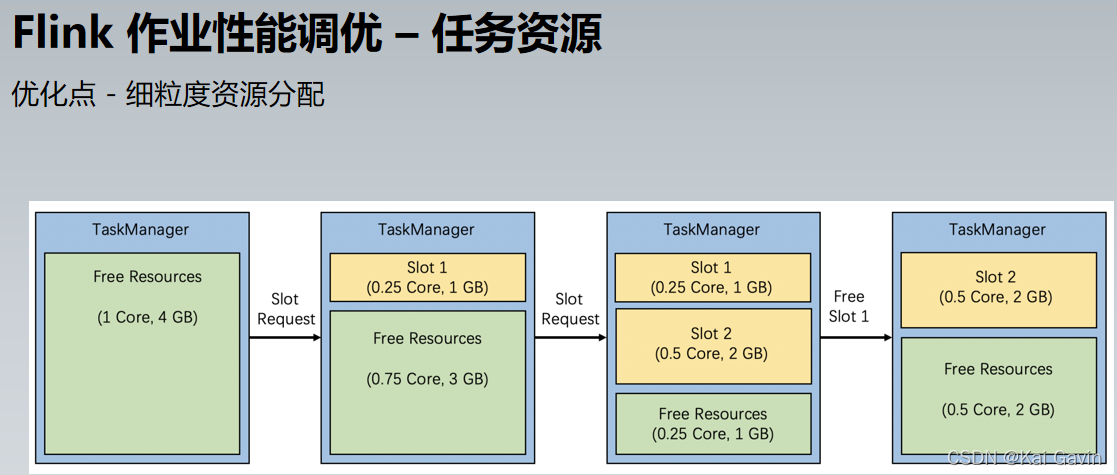
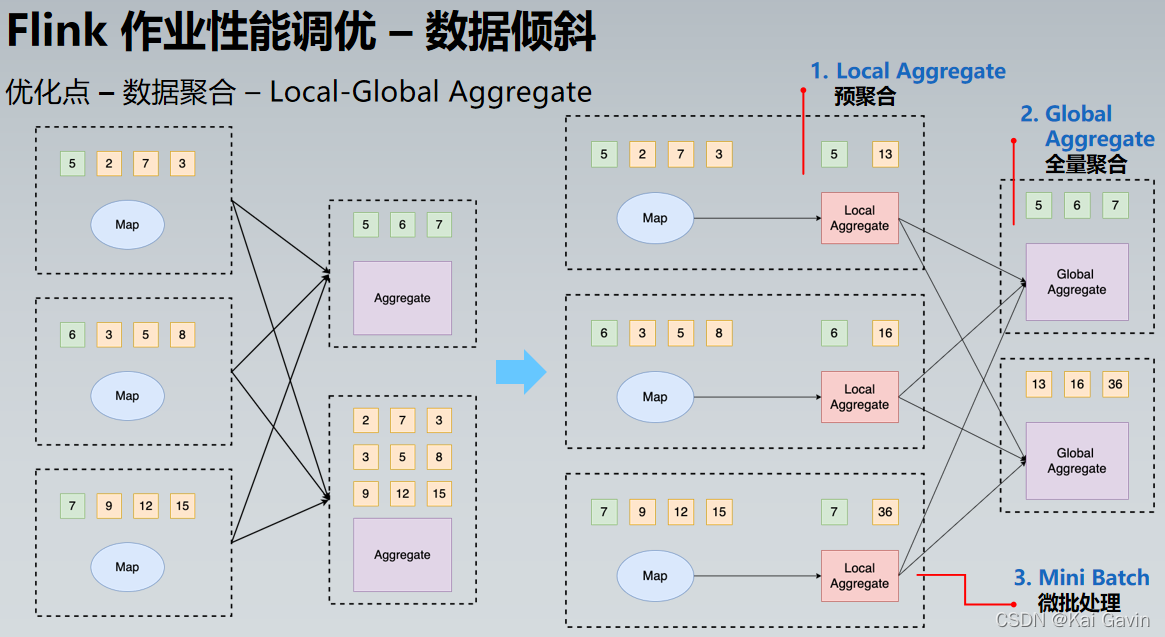
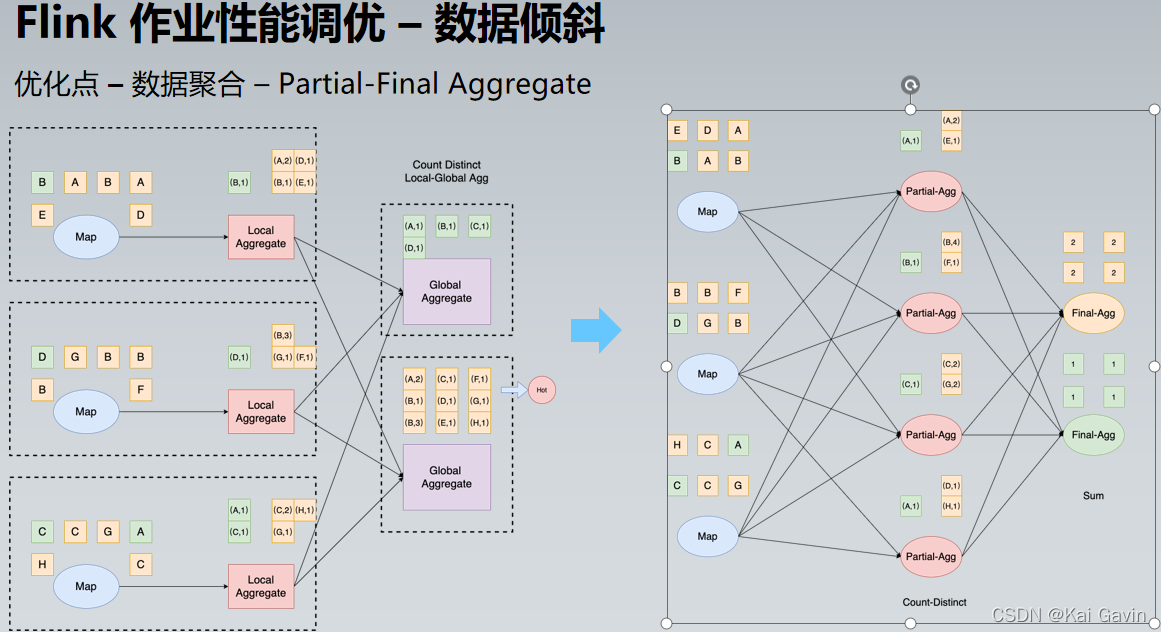
Flink ��ҵ���ܵ��� �C ������б �Ż��� �C ����ȥ��
| �Ż����� |
�ŵ� |
����ȱ�� |
| Flink State + HashMap |
ʵ�ּ� |
Hash ��ͻ���������½� ״̬����� GC �� Checkpoint ���� |
| Bit Map/Roaring Bit Map |
��ȥ�� �ڴ�ռ�ý��� |
���ݱȽ����� |
| Bloom Filter |
�ڴ�ռ���� |
����ȥ�� |
Flink ��ҵ���ܵ��� �C �����ⲿϵͳ �Ż��� �C ά�� Join
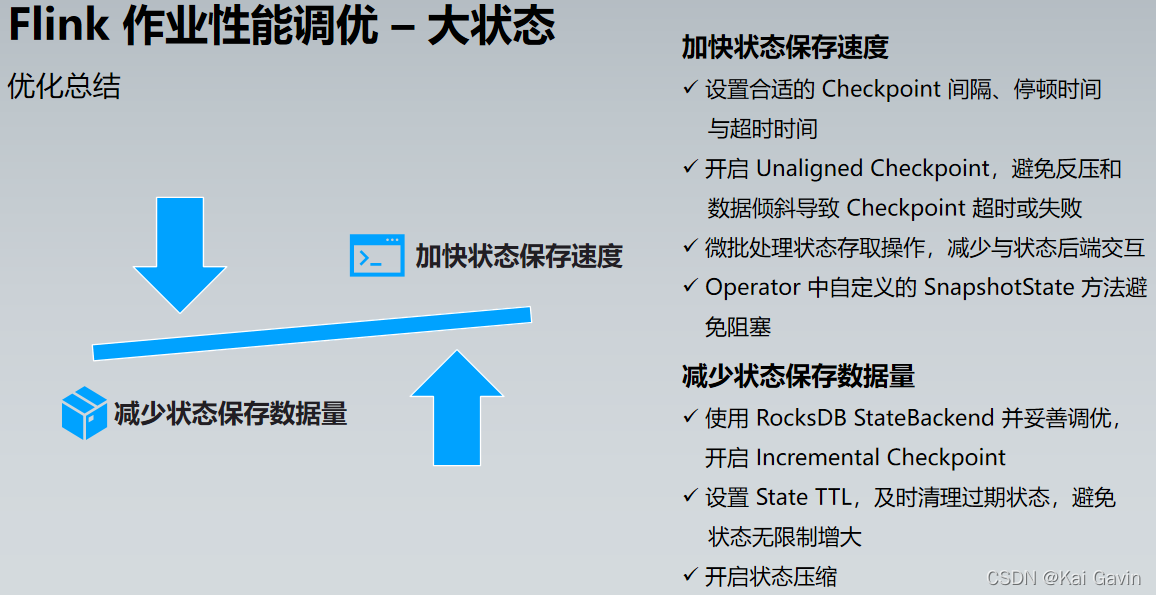
Flink ��ҵ���ܵ��� �C ��״̬ �Ż��嵥
| �Ż��� |
ע������ |
������� |
| Checkpoint ���� |
�������� Checkpoint �����ͣ��ʱ���볬ʱʱ�� |
CheckpointInterval MinPauseBetweenCheckpoints |
| State TTL + ������ȡ |
���� State TTL����ֹ״̬�������� State ������ȡ��������״̬��˽��� |
��� StateTtlConfig |
| StateBackend ���� |
����״̬�����ѡ�� RocksDB StateBackend �����Ƶ��� �������� Checkpointrocksdb localdir ָ����Ӳ�̷ֵ�д��ѹ�� |
�����ҳ |
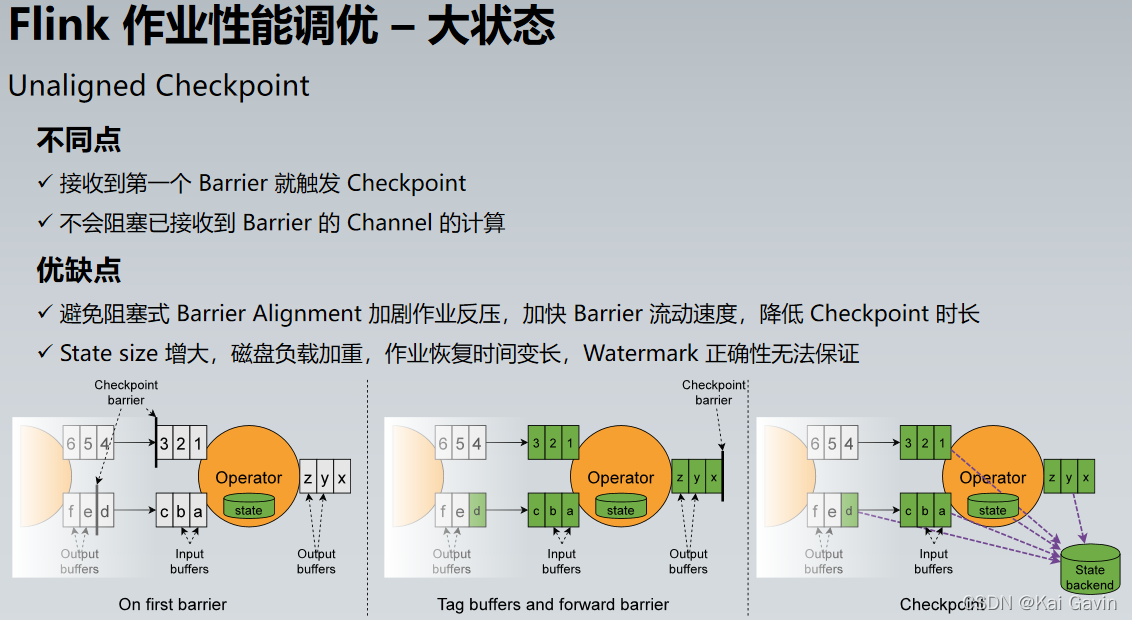
| Unaligned checkpoint |
�߷�ѹ����½���ʹ�� State size ���ܻ��нϴ�����������I/O ������ҵ�ָ�ʱ��䳤 |
execution.checkpointing. unaligned execution.checkpointing. alignment-timeout |
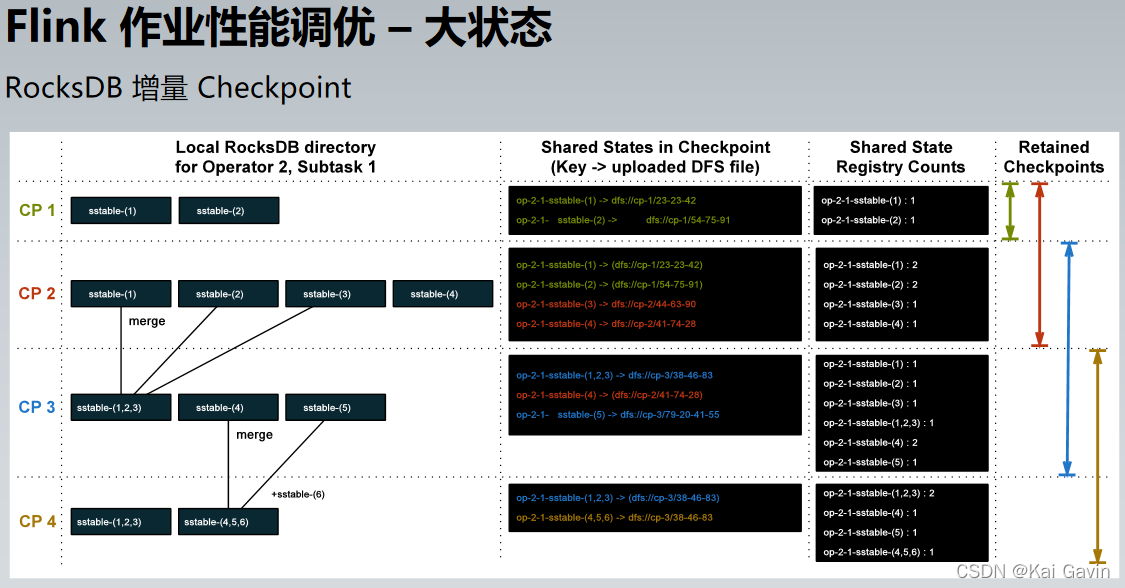
Flink ��ҵ���ܵ��� �C ��״̬ RocksDB ��������
MemTable ϵ�в��� Write Buffer Size������ MemTable ����ֵ��
Write Buffer Խ��д�Ŵ�ЧӦԽС��д����Ҳ����ơ�Ĭ�ϴ�С�� 64 MB�����Ը���ʵ������ʵ�����
Write Buffer Count�������ڴ������������� MemTable ��������Ĭ��Ϊ 2���������õ� 5 ���ҡ�
Block Cache ϵ�в���
Block Size�����Ӹ����õ���д��������ǿ����ȡ�����½�����Ҫ���� Block Cache Size ������������������������ 16 ~ 32 KB���ڴ���������Ϊ 128 KB��
Block Cache Size������ Block �����ÿ����������Ӷ����ܡ�Ĭ�ϴ�СΪ 8 MB���������õ� 64 ~ 256 MB��
Generic ����
Max Open Files�������� RocksDB ���Դ�����ļ��������Ĭ��ֵ�� 5000��������̵� ulimit û�����ƣ������Ϊ -1�������ƣ���
Index �� Bloom Filter ϵ�в���
Cache Index And Filter Blocks����ʾ�Ƿ����ڴ��ﻺ������������ Block�������� Key ���оֲ��ȵ�ʱ��
Optimize Filter For Hits����ʾ�Ƿ��� L0 ���� Bloom Filter�������� Key ���оֲ��ȵ�ʱ��
Flush �� Compaction ��ز���
Max Bytes For Level Base����ʾ L1 ���С��ֵ���ò���̫С��ÿ���ܴ�ŵ� SSTable ���٣����²㼶�ܶ࣬��ɲ������ѣ��ò���̫��ÿ�� SSTable �϶࣬����ִ�� Compaction �Ȳ����ĺ�ʱ�ϳ�����ʱ���׳��� Write Stall��дֹͣ���������д���жϡ�Ĭ��ֵΪ256MB��������Ϊ target_file_size �ı�����
Max Bytes For Level Multiplier��������LSM Tree ÿ�㼶�Ĵ�С��ֵ�ı�����ϵ������ʵ��������е�����
Target File Size����ʾ��һ���� SST �ļ��ﵽ���ʱ���� Compaction ������Ĭ��ֵ�� 64MB��ÿ����һ������ֵ���Զ����� target_file_size_multiplier���� Ϊ�˼��� Compaction ��Ƶ�ʣ����������ɵ���Ϊ 128MB ��
Thread Num����ʾ��̨���� Compaction �� Flush �������߳�����Ĭ��Ϊ 1�����������������Ϊ 4 ��




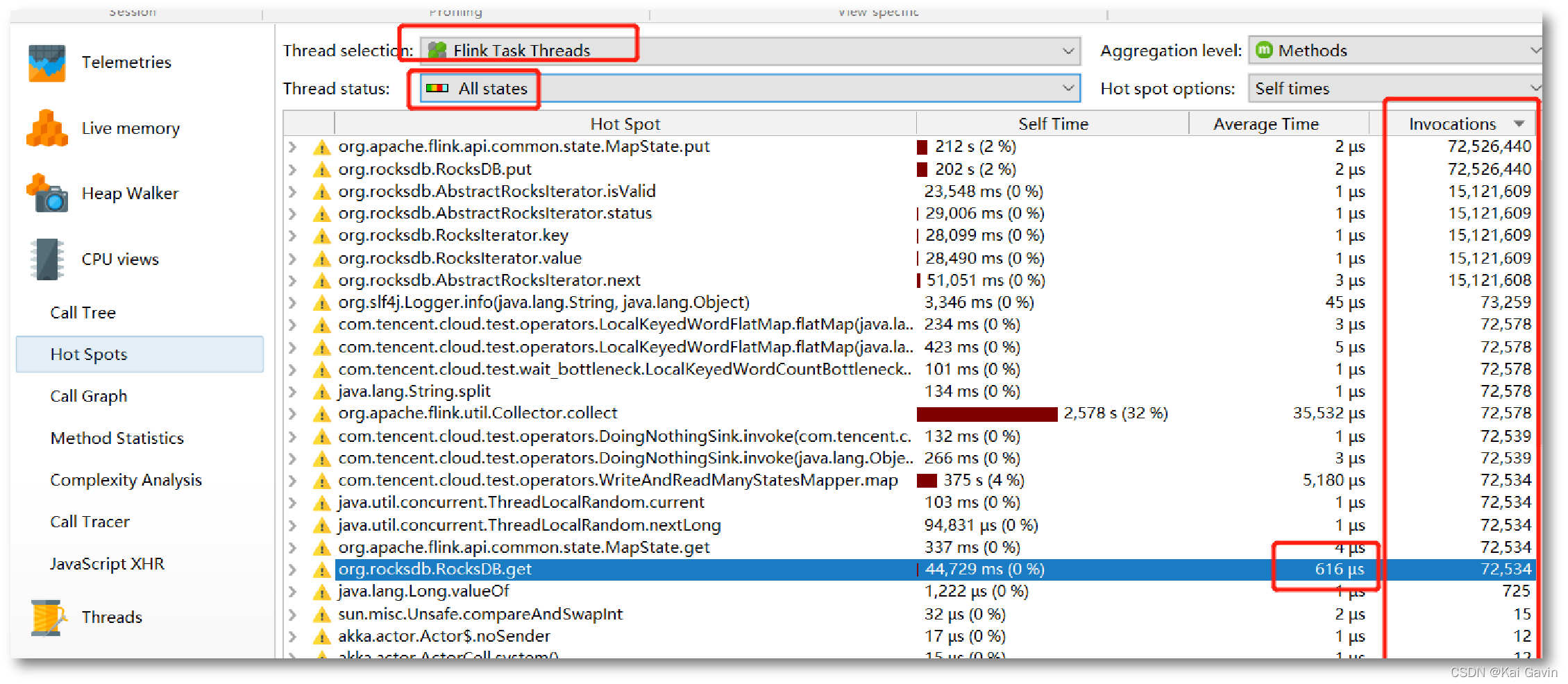
������ʵ�� ���ܷ��� �C JProfiler �ҳ��ȵ㷽��
������ʵ�� ���ܷ��� �C Java Flight Recorder ���ɻ���ͼ

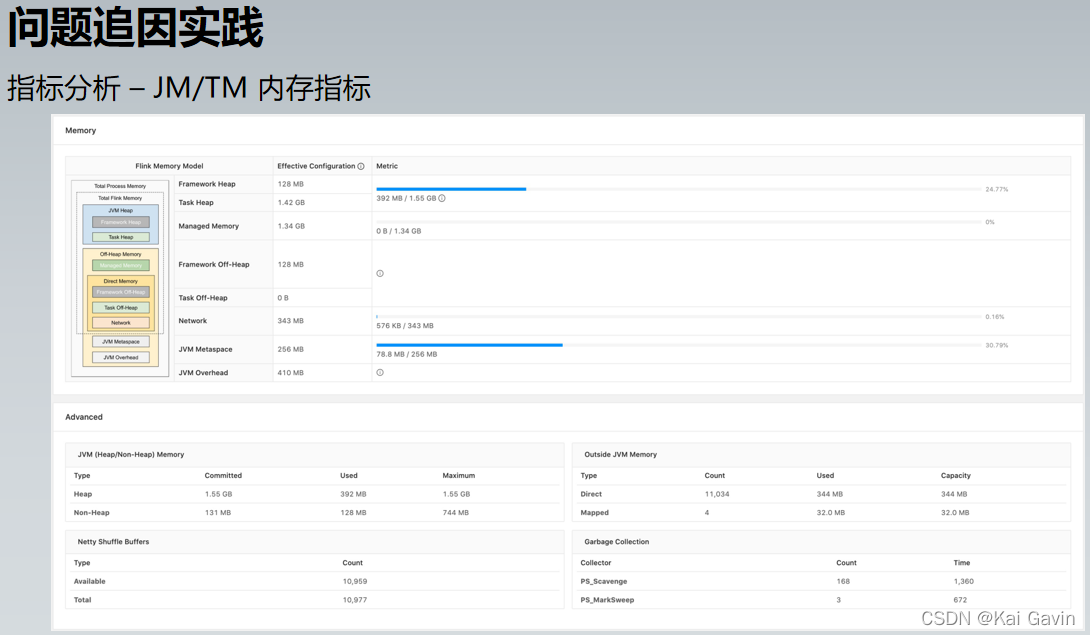


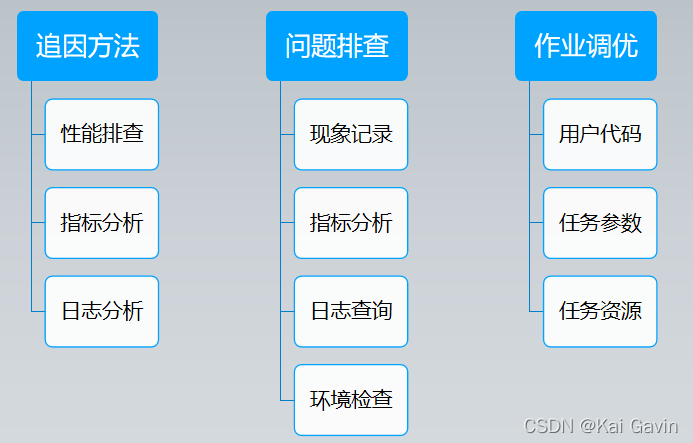
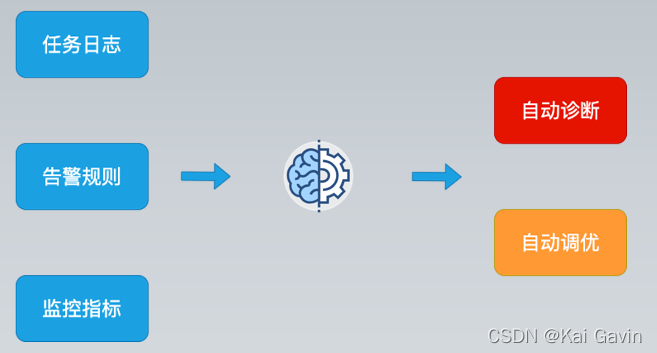
���ѧϰȸʳ��Ҫǿ�����־���������ĸ��ţ�����ѧ�����Ǿ����ܳ�Ϊ��ǿ��