
�����˼¼.
�����Ը���Ϊʳ
������е����£����Ժ��Ҳ����˾�ת��һ��
Ե��
����������ڴ��ģ����Flink SQL��ҵ�����ȣ��ڽ�����������ʼ������ʷ���ݺ�ʣ�µľ�������Kafka��ʷ���ݽ������ˡ����Ƿ���ijЩ��ҵ��������ʮ�ֻ�����Ҫ����һ��������������������������ݡ�������ʵʱ����ָ��������߳��ڣ�������֤��ҵ���������͵��ص�������������Ч�ʺܵͣ������ҿ�ʼ����Flink SQL���Ż���
����
insert into tableBselect a, max(b), max(c), sum(d) ...from tableAgroup by a
���������ҵ�ļ�SQL����Ҫ������һ������ۺϣ�
-
��tableA����ۺϳ��������tableB
-
tableA�����������ǣ�a,b������a����ɢ���Ѿ��ܸ��ˣ�
-
tableA��Flink������Ϊupset-kafka
-
tableB��Flink������ΪHBase
��������
�����ҵ���ڼ�Ⱥ�ϵ�job graph���£�
���Կ���������vertex��
-
��һ����TableSourceScan
-
�ڶ�����ChangelogNormalize
-
��������GroupAggregate
TableSourceScan����tableA����upsert-kafka����
ChangelogNormalize��upset-kafka���г�������Ľ�����
GroupAggregate�Գ��������з���ۺϣ�Ȼ��д��tableB��HBase��
�Ż�˼·1��local/global agg
agg���ࣺ
-
group agg
select count(a) from t group by b-
over agg
select count(a) over (partition by b order by c) from t-
window agg
select count(a) from t group by tumble(ts, interval '10' seconds), blocal/global agg��
![]()
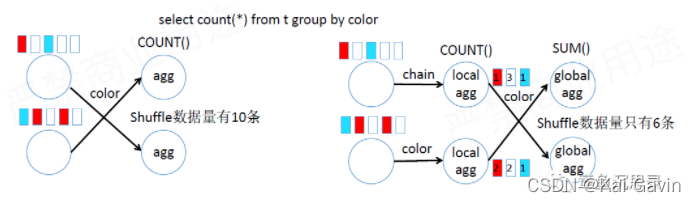
����˼����hadoop��combiner��һ�µģ�������mapreduce�Ĺ����У���map�ξ���һ��Ԥ�ۺϣ���combine������
�����������ǣ���������shuffle���ݣ�����������������ܡ�
ǰ������
-
agg������agg function����mergeable��ʵ��merge������
-
table.optimizer.agg-phase-strategyΪAUTO��TWO_PHASE
-
Stream�£�minibatch������Batch�£�AUTO�����costѡ��
����˵����
mergeable��ʵ�������÷��η�����ļ������⣬����sum��count�ȣ���avg�Ͳ����÷��η��ȼ��㲿��Ԫ�ص�avg���ټ�������avg�ˣ������ʱ��������
table.optimizer.agg-phase-strategy��Ĭ��ΪAUTO����˼�����澡����Ԥ�ۺϣ�TWO_PHASE��ʾ���оۺϲ�������Ԥ�ۺϣ�ONE_PHASE��ʾ���оۺ϶�����Ԥ�ۺϡ�
minibatch����������ģʽ����Ҫ������������
-
table.exec.mini-batch.enabled���Ƿ�����Ĭ�ϲ�����
-
table.exec.mini-batch.size������record buffer��С
-
table.exec.mini-batch.allow-latency������time buffer��С
minibatch�ı��ʾ���ƽ��ʵʱ�Ժ��������Ŀ̶ȳߡ�
���ԣ�local/global aggһ����Ҫ�����������ơ�
��֤
�����Ա���֤�������SQL�����µ�Ч��������С��
local/global agg�����˵ڶ���vertex��ChangelogNormalize��sent records��������������û��ʹ�õ�һ��vertex�����ݴ���Ч��������������
���ԣ������ҵ��ƿ��������vertex��, �����ڵ�һ��vertex�Ĵ�������Ч�ʡ�
�Ż�˼·���������ж�
���˼·�Ĺؼ�����source upsert-kafka�ķ�������������Լ��������ƿ������Ϊ��upsert-kafka�У�ÿ��partition��౻һ��Flink�̶߳�ȡ��
������10���IJ��жȣ�source����Ҳ����10������ҵ��תʱ�������˽���һ�롣
�Ż�˼·����RocksDB���ܵ���
��ϸ�������SQL��ҵ���Ƕ�һ�������������ֶ���group by����ôstateһ����dz���
�����ڶ�������������е����ݽ��з�������������ֶε���ɢ�ȼ����ӽ�����������ɢ�ȡ�
������group by��ȻҪ����ÿһ��upsert kafka������ȥ������flink statebackend���ﻯ��source table�и��ֶ�ֵ�ķֲ��������Ӧ���Dz���ƿ�����ڣ�
�������˼·����ʼ����Flink��statebackend���ơ�
�������Ǽع�һ��Flink statebackend����������ר���ܽᣩ��
�� Flink ������ keyed state ��һ�ַ�Ƭ�ļ�/ֵ�洢��ÿ�� keyed state �Ĺ��������������ڸ���ü��� taskmanager �����С����⣬Operator state Ҳ�����ڻ����ڵ㱾�ء�Flink ���ڻ�ȡ����״̬�Ŀ��գ�������Щ���ո��Ƶ��־û���λ�ã�����ֲ�ʽ�ļ�ϵͳ��
����������ϣ�Flink ���Իָ�Ӧ�ó��������״̬����������������ͬû�г��ֹ��쳣��
Flink ������״̬�洢�� state backend �С�Flink ������ state backend ��ʵ�� �C һ�ֻ��� RocksDB ��Ƕ key/value �洢���乤��״̬�����ڴ����ϵģ���һ�ֻ��ڶѵ� state backend�����乤��״̬������ Java �Ķ��ڴ��С����ֻ��ڶѵ� state backend ���������ͣ�FsStateBackend������״̬���ճ־û����ֲ�ʽ�ļ�ϵͳ��MemoryStateBackend����ʹ�� JobManager �Ķѱ���״̬���ա�
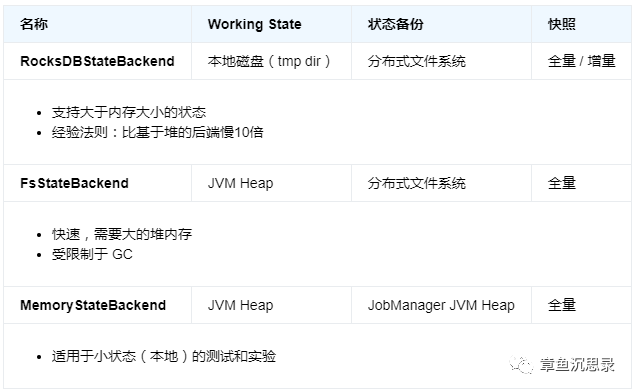
��ʹ�û��ڶѵ� state backend ����״̬ʱ�����ʺ����漰�ڶ��϶�д�����Ƕ��ڱ����� RocksDBStateBackend �еĶ����ʺ����漰���л��ͷ����л������Ի��и���Ŀ������� RocksDB ��״̬�����ܱ��ش��̴�С�����ơ���Ҫע�⣬ֻ�� RocksDBStateBackend �ܹ������������գ�����ھ��д����仯����״̬��Ӧ�ó�����˵�Ǵ�������ġ�
������Щ state backends ���ܹ��첽ִ�п��գ�����ζ�����ǿ����ڲ��������ڽ��е��������������ִ�п��ա�
���ǵ�����һ����õ���RocksDB��Ϊ״̬��ˣ�checkpoint dir����hdfs�ļ�ϵͳ����ʵ�Ҹ��˾������Ӧ�ø�����ҵ�����Խ���ѡ�����Ҹ��˵ľ����Լ�֪ʶ������ѡ�����Ҫ��������ҵ��state��С���Դ����������ܵ�Ҫ��
-
RocksDBStateBackend����ͻ���ڴ�����ƣ�rocksDB���������ṹ��redis���ƣ��������ݵ������洢�ṹ�ֺ�hbase���ƣ��̳���levelDB��LSM��˼�룬ȱ��������̫��
-
��FsStateBackend������snapshot��ʱ��Ž��ڴ��state�־û���Զ�ˣ��ٶȽӽ����ڴ�״̬
-
MemoryStateBackend�Ǵ��ڴ�ģ�һ��ֻ�������ԡ�
�������������״̬��ҵ���ٶ�ʵ��̫���������������
������ʱ����FsStateBackend�������ô��ڴ棬�Ұ�managed memory����0��ͬʱ��ck���������õĺܴ����ϲ���ck���Ϻ�savepoint���ٰ�״̬��˻���RocksDB�����Ҵ�FSSatebackend��savepoint���ָ������Ƿ���1.13��֧��savepoint�л�statebackend���͡�
ֻʣ�µ���RocksDBһ��·�ˡ�����֮ǰ��HBase��LSMԭ�������⣬����֪ʶǨ�ƣ����϶�RocksDB����һ������ʶ����HBase�е���Ч������������
blockcache�����桢memStoreд���桢���Ӳ�¡������������compactЧ��
�������˼·���ٲ�����һ��RocksDB���Ϻ����ȶ����²������е��ţ�
-
state.backend.rocksdb.block.cache-size
-
state.backend.rocksdb.block.blocksize
Block ���� RocksDB �����ڴ����е� SST �ļ��Ļ�����λ����������һϵ��������� Key �� Value ���ϣ��������ù̶��Ĵ�С��
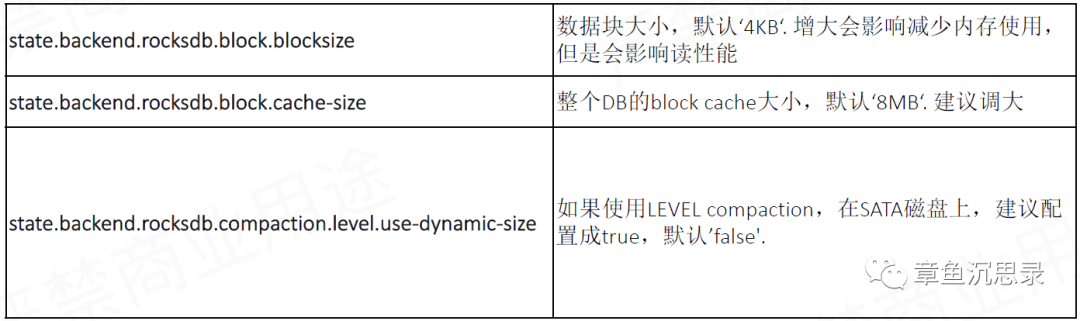
���ǣ�ͨ������ Block Size�����������Ӷ��Ŵ�Read Amplification��ЧӦ�����ȡ����ʱ���������½���ԭ���� Block Size�����Ժ���� Block Cache �Ĵ�Сû�б䣬�ͻ�?����� Cache �пɴ�ŵ� Block ������� Cache �л��洦����������?�����ݣ���ô�ɷ��õ����ݿ���Ŀ�ͻ���٣�������Ҫ����Ĵ��� IO �������ҵ����ݾ�?���ˣ���ʱ��ȡ���ܻ����½�����֮�������СBlockSize�����ö���������?������������д���ܻ��½���?���Ҷ� SSD ����Ҳ��?��
����ҵĵ��ž����ǣ������Ҫ���� Block Size �Ĵ�С��������д���ܣ������һ������ Block Cache Size �Ĵ�С�������ſ���ȡ�ñȽϺõĶ�д���ܡ�Block Cache����������㷨?�õ��� LRU��Least Recently Used����
��֤
���ԶԱȺ��֣�ԭ������������ɵ���ҵֻ��Ҫһ������Сʱ���������ݣ�
����
���ܵ��ž���ͬ�����β����ؼ����ڶ�֢��ҩ��
ǰ�ڣ�Ҫ������ǰ������������Լ���ܵ�ƿ�����ڣ����ڣ���֢�ᴦ��Ч�������Եķ�ʽ����֢�ᡣ