大纲:Tips for Training Deep Network
- Training Strategy: Batch Normalization
- Activation Function: SELU
- Network Structure: Highway Network
Batch Normalization算法自从15年提出,到现在已经成为深度学习中经常使用的技术,可以说是十分powerful。
Feature Scaling 特征缩放
我们先从Feature Scaling或者Feature Normalization说起,不管你是不是做深度学习的方法,其实你都会想要做Feature Scaling。原因是:
在没有进行Feature Scaling之前,如果两个输入数据 的distribution很不均匀的话,导致
的distribution很不均匀的话,导致 对计算结果的影响比较大(图左),所以训练的时候,横纵方向上需要给与一个不同的training rate,在
对计算结果的影响比较大(图左),所以训练的时候,横纵方向上需要给与一个不同的training rate,在 方向需要一个更大的learning rate,
方向需要一个更大的learning rate, 方向给与一个较小的learning rate,不过这样做的办法却不见得很简单。所以对不同Feature做了normalization之后,使得error surface看起来比较接近正圆的话(图右),就可以使训练容易得多。
方向给与一个较小的learning rate,不过这样做的办法却不见得很简单。所以对不同Feature做了normalization之后,使得error surface看起来比较接近正圆的话(图右),就可以使训练容易得多。

那变成椭圆形或变成正圆形有什么样的不同呢?
如果你今天你的 error surface上面, 你的gradient的变化是非常大,gradient在横的方向上和纵的方向上变化非常大, 这会让你的training变得比较不容易,因为不同的方向上你要给他非常不一样的学习率,你要在横的方向上给比较大的学习率,纵的方向上给比较小的学习率, 你要给不同的参数不同的学习率,因为这件事情当然是有办法的,但不见得那么好做。 如果你今天可以把不同的feature做Normalization,让你的error surface看起来比较接近正圆的话,是会让你的training容易得多。
经典的Feature Scaling
不管你是不是deep learning的方法,你都会用到Feature Scaling技术。通常经典的Feature Scaling的方法是怎么做的?
现在给你一大堆的数据,你的训练数据总共有大 笔data。而接下来你就对每一个dimension去计算dimension的mean跟dimension的standard deviation,假设你这个input是39维,所以就算出39个mean跟39个standard deviation;然后对每一维中的数值,假设你取第
笔data。而接下来你就对每一个dimension去计算dimension的mean跟dimension的standard deviation,假设你这个input是39维,所以就算出39个mean跟39个standard deviation;然后对每一维中的数值,假设你取第 维中的数值出来,你就把它减掉第
维中的数值出来,你就把它减掉第 维的mean,除以第
维的mean,除以第 维的standard deviation,作为一个Normalization,你就会让第
维的standard deviation,作为一个Normalization,你就会让第 维的feature的分布mean=0,variance=1,一般来说,如果你今天做了Feature Scaling这件事情往往会让你的training变得比较快速。
维的feature的分布mean=0,variance=1,一般来说,如果你今天做了Feature Scaling这件事情往往会让你的training变得比较快速。

进入 deep learning 部分
刚才都是还没有讲到deep learning了,现在我们进入deep learning的部分,我们知道说在deep learning里面它的卖点就是有很多个layer,你有个 进来通过一个layer得到
进来通过一个layer得到 ,把
,把 放入layer 2得到输出
放入layer 2得到输出 ,我们当然会对network输入的
,我们当然会对network输入的 做Feature Scaling。但是你仔细想想从layer 2的角度来看,其实它的input的feature是
做Feature Scaling。但是你仔细想想从layer 2的角度来看,其实它的input的feature是 ,我们可以把network前几个layer想成是一个feature的提取,我们知道说network的前几个layer的工作其实就是在抽比较好的feature,后面几个layer当做classify可以做得更好,所以对layer 2来说,他吃到的feature就是layer 1的output
,我们可以把network前几个layer想成是一个feature的提取,我们知道说network的前几个layer的工作其实就是在抽比较好的feature,后面几个layer当做classify可以做得更好,所以对layer 2来说,他吃到的feature就是layer 1的output  ,如果我们觉得说Feature Scaling是有帮助的,我们也应该对layer 2 的feature,也就是layer 1的output
,如果我们觉得说Feature Scaling是有帮助的,我们也应该对layer 2 的feature,也就是layer 1的output  做Feature Scaling,同理layer 2的输出
做Feature Scaling,同理layer 2的输出 他是下一个Layer 3的输入,它是下一个layer的feature,我们应该要做一下Normalization,这样接下来layer可以learn的更好。
他是下一个Layer 3的输入,它是下一个layer的feature,我们应该要做一下Normalization,这样接下来layer可以learn的更好。

其实对每一个layer做Normalization这件事情,在deep learning上面是很有帮助的,因为它解决了一个叫做Internal Covariate Shift的这个问题,可以令这个问题比较轻微一点。
Internal Covariate Shift这个问题是什么意思?
如上图所示:你就想成说现在每一个人代表1个layer,然后他们中间是用话筒连在一起,而今天当一个人手上的两边的话筒被接在一起的时候,整个network的传输才会顺利,才会得到好的performance。
现在我们看一下中间那个小人,他左手边的话筒比较高,他的右手边的话筒比较低。在训练的时候为了将两个话筒拉到同一个水平高度,它会将左手边的话筒放低一点,同时右手的话筒放高一点,因为是同时两边都变,所以就可能出现了下面的图,最后还是没对上。
在过去的解决方法是调小learning rate,因为没对上就是因为学习率太大导致的,虽然体调小learning rate可以很好地解决这个问题,但是又会导致训练速度变得很慢。
你不想要学习率设小一点,所以怎么办?
Batch Normalization
所以今天我们要讲batch Normalization,也就是对每一个layer做Feature Scaling这件事情,就可以来处理Internal Covariate Shift问题。
为什么?因为如果我们今天把每一个layer的feature都做Normalization,我们把每一个layer的feature的output都做Normalization,让他们永远都是比如说 ,对下一个layer来看,前个layer的statistics就会是固定的,他的training可能就会更容易一点。
,对下一个layer来看,前个layer的statistics就会是固定的,他的training可能就会更容易一点。
首先我们把刚才的话筒转化为deep learning中就是说,训练过程参数在调整的时候前一个层是后一个层的输入,当前一个层的参数改变之后也会改变后一层的参数。当后面的参数按照前面的参数学好了之后前面的layer就变了,因为前面的layer也是不断在变的。其实输入数据很好normalization,因为输入数据是固定下来的,但是后面层的参数在不断变化根本就不能那么容易算出mean和variance,所以需要一个新的技术叫Batch normalization。
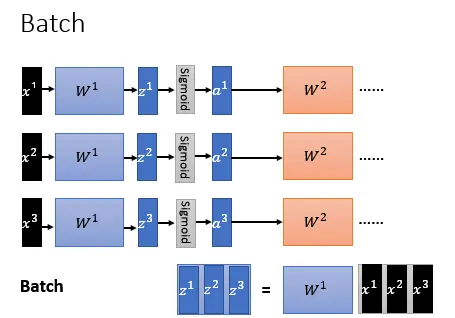
补充:GPU加速batch计算的原理
Batch的数据其实是平行计算的,如下图。实际上gpu在运作的时候,它会把 拼在一起,排在一起变成一个matrix,把这个matrix乘上
拼在一起,排在一起变成一个matrix,把这个matrix乘上 得到
得到 ,因为今天是matrix对matrix,你如果把matrix对matrix作平行运算,可以比matrix对三个data分开来进行运算速度还要快,这个就是gpu加速batch运算的原理。
,因为今天是matrix对matrix,你如果把matrix对matrix作平行运算,可以比matrix对三个data分开来进行运算速度还要快,这个就是gpu加速batch运算的原理。
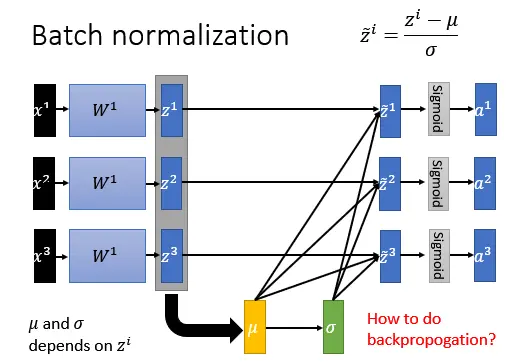
接下来我们要做Batch Normalization。怎么做?我们现在想要做的事情是对第一个隐藏层的output, ,做Normalization。
,做Normalization。
我们可以先做Normalization,再通过激活函数,或者先通过激活函数再做Normalization。我们偏向于先做Normalization,再通过激活函数,这样做有什么好处呢?
因为你的激活函数,如果你用tanh或者是sigmoid,函数图像的两端,相对于 的变化,
的变化, 的变化都很小。也就是说,容易出现梯度衰减的问题。因此你比较喜欢你的input是落在变化比较大的地方,也就是你的前后零的附近,如果先做Normalization你就能够确保说在进入激活函数之前,你的值是落在你的附近。
的变化都很小。也就是说,容易出现梯度衰减的问题。因此你比较喜欢你的input是落在变化比较大的地方,也就是你的前后零的附近,如果先做Normalization你就能够确保说在进入激活函数之前,你的值是落在你的附近。

我们现在来做Normalization:你想要先算出一个 ,
, ,先算出这些
,先算出这些 的均值。接下来算一下
的均值。接下来算一下 ,
, 。好,接下来这边有件事情要跟大家强调一下,就是
。好,接下来这边有件事情要跟大家强调一下,就是 是是由
是是由 决定的。
决定的。 是由
是由 和
和 决定的。等一下会用上。
决定的。等一下会用上。
这边有一件事情要注意:在做Normalization的话,在选的 跟
跟 的时候我们其实希望它代表的是整个training set全体的statistics。但是因为实做上统计整个training set全体的statistics是非常耗费时间的,而且不要忘了
的时候我们其实希望它代表的是整个training set全体的statistics。但是因为实做上统计整个training set全体的statistics是非常耗费时间的,而且不要忘了 的数值是不断的在改变的,你不能说我把整个training set的data导出来算个
的数值是不断的在改变的,你不能说我把整个training set的data导出来算个 ,然后
,然后 的数值改变以后,再把整个导出来的再算一次
的数值改变以后,再把整个导出来的再算一次 ,这个是不切实际的做法;
,这个是不切实际的做法;
所以现在我们在算 跟
跟 的时候,只会在batch里面算,这意味着什么?这意味着说你的batch size一定要够大,如果太小的话Batch Normalization的性能就会很差,因为你没有办法从一个batch里面估测整个data的
的时候,只会在batch里面算,这意味着什么?这意味着说你的batch size一定要够大,如果太小的话Batch Normalization的性能就会很差,因为你没有办法从一个batch里面估测整个data的 跟
跟 ,举例来说,你可以想象极端case,如果今天batch size=1,你根本不能够apply这套想法。
,举例来说,你可以想象极端case,如果今天batch size=1,你根本不能够apply这套想法。
接下来,有了 跟
跟 以后,我们可以算出:
以后,我们可以算出: ,这里面的除法代表element wise的除法。好,我们做完Normalization以后就得到了
,这里面的除法代表element wise的除法。好,我们做完Normalization以后就得到了 ,经过Normalization以后 的
,经过Normalization以后 的 每一个dimension它的
每一个dimension它的 ,你高兴的话就把它通过sigmoid得到A,然后再丢到下一个layer,Batch Normalization通常会每一个layer都做好,所以每一个layer的
,你高兴的话就把它通过sigmoid得到A,然后再丢到下一个layer,Batch Normalization通常会每一个layer都做好,所以每一个layer的 ,在进入每一个激活函数之前,你都会做这一件事情。
,在进入每一个激活函数之前,你都会做这一件事情。
它这边有一个其实大家可能比较不知道的事情是:有batch Normalization的时候怎么作training?很多同学想法也许是跟原来没有做背Normalization没有什么不同。其实不是这样,真正在train这个batch Normalization的时候,会把整个batch里面所有的data一起考虑。我不知道大家听不听得懂我的意思,你train这个batch Normalization的时候,你要想成你有一个非常巨大的network,然后它的input就是 ,然后得到
,然后得到 ,中间它还会算两个东西
,中间它还会算两个东西 跟
跟 ,它会产生 ,
,它会产生 , ,你一路backout回来的时候,他是会通过
,你一路backout回来的时候,他是会通过 ,通过
,通过 ,然后去update z的。
,然后去update z的。
为什么这样?因为假设你不这么做,你把 跟
跟 视为是一个常数。当你实际在train你的network的时候,你Backpropagation的时候,你改的这个
视为是一个常数。当你实际在train你的network的时候,你Backpropagation的时候,你改的这个 的值,你会改动这个
的值,你会改动这个 的值,改动这个
的值,改动这个 的值,其实你就等同于改动了
的值,其实你就等同于改动了 跟
跟 的值。但是如果你在training的时候没有把这件事情考虑进去会是有问题的。所以其实在做batch Normalization的时候,
的值。但是如果你在training的时候没有把这件事情考虑进去会是有问题的。所以其实在做batch Normalization的时候, 对
对 的影响是会被在training的时候考虑进去的。所以今天你要想成是你有一个非常巨大的network,input就是一整个batch,在Backpropagation的时候,它error signal也会从这个path(上图粗箭头的反向路径)回来,所以
的影响是会被在training的时候考虑进去的。所以今天你要想成是你有一个非常巨大的network,input就是一整个batch,在Backpropagation的时候,它error signal也会从这个path(上图粗箭头的反向路径)回来,所以 对
对 跟
跟 的影响是会在training的时候被考虑进去的,这样讲大家有问题吗? 如果有问题,就忽略吧……
的影响是会在training的时候被考虑进去的,这样讲大家有问题吗? 如果有问题,就忽略吧……
接下来继续,我们已经把 Normalize
Normalize  ;
;
但是有时候你会遇到的状况是,你可能不希望你的激活函数的input是 ,也许有些特别的激活函数,但我一下想不到是什么,他的mean和variance是别的值,performance更好。你可以再加上
,也许有些特别的激活函数,但我一下想不到是什么,他的mean和variance是别的值,performance更好。你可以再加上 跟
跟 ,把你现在的distribution的mean和variance再做一下改动,你可以把你的
,把你现在的distribution的mean和variance再做一下改动,你可以把你的  乘上这个
乘上这个 ,然后再加上
,然后再加上 得到
得到  ,然后再把
,然后再把 通过sigmoid函数,当做下一个layer的input,这个
通过sigmoid函数,当做下一个layer的input,这个 跟
跟 你就把它当做是network的参数,它也是可以跟着network一起被learn出来的。
你就把它当做是network的参数,它也是可以跟着network一起被learn出来的。

这边有人可能会有问题是如果我今天的 正好等于
正好等于 ,
, 正好等于
正好等于 ,Normalization不就是有做跟没做一样吗?就是把
,Normalization不就是有做跟没做一样吗?就是把 Normalize成
Normalize成  ,再把
,再把  Normalize成
Normalize成 ,但是如果今天
,但是如果今天 正好等于
正好等于 ,
, 正好等于
正好等于 的话就等于没有做事,确实是如此。但是加
的话就等于没有做事,确实是如此。但是加 和
和 跟
跟 和
和 还是有不一样的地方,因为
还是有不一样的地方,因为 和
和 它是受到data所影响。但是今天你的
它是受到data所影响。但是今天你的 和
和 是独立的,他是跟input的data是没有关系的,它是network自己加上去的,他是不会受到input的feature所影响的,所以它们还是有一些不一样的地方。
是独立的,他是跟input的data是没有关系的,它是network自己加上去的,他是不会受到input的feature所影响的,所以它们还是有一些不一样的地方。
testing
好,我们看一下在testing的时候怎么做,假设我们知道training什么时候怎么做,我们就train出一个network,其实它在train的时候它是考虑整个batch的,所以他其实要吃一整个batch才work。好,他得到一个 ,他会用
,他会用 减掉
减掉 除以
除以 ,
, 跟
跟 是从一整个batch的data来的,然后他会得到
是从一整个batch的data来的,然后他会得到 ,它会乘上
,它会乘上 ,再加上
,再加上 ,
, 和
和 是network参数一部分,得到的
是network参数一部分,得到的 。training的时候没有问题,testing的时候你就有问题了,因为你不知道怎么算
。training的时候没有问题,testing的时候你就有问题了,因为你不知道怎么算 跟
跟 , 对不对?因为training的时候,你input一整个batch,算出一整个batch的
, 对不对?因为training的时候,你input一整个batch,算出一整个batch的 跟
跟 。但是testing的时候你就有点问题,因为你只有一笔data进来,所以你估不出
。但是testing的时候你就有点问题,因为你只有一笔data进来,所以你估不出 跟
跟 。
。

有一个ideal的solution是说:既然 跟
跟 代表的是整个data set的feature的均值和标准差,而且现在的training的process已经结束了,所以整个network的参数已经固定下来了,我们train好network以后再把它apply到整个training set上面,然后你就可以估测现在
代表的是整个data set的feature的均值和标准差,而且现在的training的process已经结束了,所以整个network的参数已经固定下来了,我们train好network以后再把它apply到整个training set上面,然后你就可以估测现在 的
的 跟
跟 ,之前没有办法直接一次估出来,是因为我们network参数不断的在变,在你的training结束以后,把training里的参数已经确定好,你就可以算
,之前没有办法直接一次估出来,是因为我们network参数不断的在变,在你的training结束以后,把training里的参数已经确定好,你就可以算 的distribution,就可以估出
的distribution,就可以估出 的
的 跟
跟 。
。
这是一个理想的做法,在实做上有时候你没有办法这么做,一个理由是有时候你的training set太大,可能你把整个training set的data都倒出来再重新算一次 跟
跟 ,也许你都不太想做,而另外一个可能是你的training的data是一笔一笔进来的,你并没有把data省下来,你data一个batch进来,你要备参数以后,那个batch就丢掉,你的训练资料量非常大,所以要训练是不省下来的,你每次只进来一个batch,所以也许你的training set根本就没有留下来,所以你也没有办法估测training set的
,也许你都不太想做,而另外一个可能是你的training的data是一笔一笔进来的,你并没有把data省下来,你data一个batch进来,你要备参数以后,那个batch就丢掉,你的训练资料量非常大,所以要训练是不省下来的,你每次只进来一个batch,所以也许你的training set根本就没有留下来,所以你也没有办法估测training set的 跟
跟 ;
;
所以可行的solution是怎么做呢?这个critical 的solution是说把过去在update的过程中的 跟
跟 都算出来,随着这个training的过程正确率会缓缓地上升,如上图红色框中图示:假设第一次取一个batch算出来是
都算出来,随着这个training的过程正确率会缓缓地上升,如上图红色框中图示:假设第一次取一个batch算出来是 ,第100次取一个batch算出来是
,第100次取一个batch算出来是 ……你可以说我把过去所有的
……你可以说我把过去所有的 连起来当作是整个data的statistic,我这样做也不见得太好,为什么?因为今天在训练过程中参数是不断的变化,所以第一次地方算出来的
连起来当作是整个data的statistic,我这样做也不见得太好,为什么?因为今天在训练过程中参数是不断的变化,所以第一次地方算出来的 跟第100次算出来的
跟第100次算出来的 显然是差很多的,对不对?因为真正最后训练完的参数会比较接近100次得到的参数,第一次得到参数跟你训练时候得到参数差很多,所以这个地方的
显然是差很多的,对不对?因为真正最后训练完的参数会比较接近100次得到的参数,第一次得到参数跟你训练时候得到参数差很多,所以这个地方的 跟你实际上你训练好的network以后,他会算出来的
跟你实际上你训练好的network以后,他会算出来的 的
的 是差很多的,所以在实做上你会给靠近training结束的这些
是差很多的,所以在实做上你会给靠近training结束的这些 比较大的weight,然后给前面这些比较少的weight。
比较大的weight,然后给前面这些比较少的weight。
Batch Normalization的好处
解决了Internal Covariate Shift的问题:Internal Covariate Shift让我们的学习率能够设很小,既然Batch Normalization以后你的学习率可以设大一点,所以你的training就快一点。
对防止gradient vanish这件事情是有帮助的:我们之前有讲说,如果你用sigmoid函数,你很容易遇到gradient vanish的问题。因为如果你接的input是落在靠近值很大或者很小的地方,你就很容易gradient vanish。但是今天如果你有加Batch Normalization,你就可以确保说激活函数的input都在零附近,都是斜率比较大的地方,就不会有gradient,就是gradient比较大的地方就不会有gradient vanish的问题,所以他特别对sigmoid,tanh这种特别有帮助。
对参数的定义的initialization影响是比较小的:很多方法对参数的initialization非常sensitive,但是当你加了Batch Normalization以后,参数的initialization的影响就会比较小
怎么说?假设我现在把 都乘
都乘 倍,
倍, 当然也就乘上
当然也就乘上 ,今天做Normalization的时候,他的
,今天做Normalization的时候,他的 当然也是乘上
当然也是乘上 ,我算了一下它的
,我算了一下它的 当然也是乘上
当然也是乘上 倍。
倍。
今天分子乘 倍,分母乘
倍,分母乘 ,做完Normalization以后就是什么事都没发生。所以如果你今天在initialize的时候,你的
,做完Normalization以后就是什么事都没发生。所以如果你今天在initialize的时候,你的 的参数乘上
的参数乘上 倍,对它的output的结果是没有影响。所以这就是batch Normalization另外一个好处,它对你的参数的initialization比较不sensitive。
倍,对它的output的结果是没有影响。所以这就是batch Normalization另外一个好处,它对你的参数的initialization比较不sensitive。据说能够对抗overfitting:在batch Normalization的时候你等同于是做了regularization这一件事情,这个也是很直观,因为你现在如果把所有的feature都Normalize 到固定的mean,一样的variance,如果你今天在test的时候有一个??进来,导致你的mean有一个shift,shift没关系,反正你会做Normalization,,所以batch Normalization有一些对抗overfitting的效果,所以我们刚才一开始都讲说你看到一个方法的时候,要想清楚它到底是在training的performance不好的时候做有用,还是在testing的performance不好的时候有用,那些batch Normalization应该是两training都有用,不过它主要的作用还是在training不好的时候帮助比较大;如果你今天是training已经很好,testing不好,你可能也有很多其他的方法可以快,不见得要batch Normalization。
