�ϴ����ӿ�ѹ������ǰһֱ�о�ʹ��jmeter������Ϊ��������ʹ���ˣ������������в����ӿ�ʱ������jmeter�ڵ����²���1000��ʱ��̨ʽ���Ե�����Դ��ͱ�ʹ���꣬����jmeter���������ģ��������ʹ��jmeter����ʧ�ܣ��Һ�֮ǰҲ��������һ��ѹ��С����Apache ab�����ʹ��ab��ǿ���������jmeterѹ��ӿ��о���ԶԶ���������������о��ɡ��º��ֻ���Python������Locust�����������������룬���Ǻ��ڲ��Ի�������ѹ���ǴεĽӿڡ�������Ŀ���ʵ�ּ�ǧ�IJ�������¼�·����Լ��´�ʹ�ã�
Locustѹ��ӿ�����2
Locust����ȫ����Python��http������ȫ�ǻ���requests�⡣Locust֧��http��httpsЭ�飬��֧�ֲ�������Э�飬websocket�ȣ�ֻҪ����Python���ö�Ӧ�Ŀ�Ϳ����ˡ�
http/https����requests��
websocket����websocket ��
�ȵȡ�
Locust��jmeter��lr�ŵ�Ա�3
���ܲ��Ժ����ڵ����ϻ�úܸߵIJ�������lr��jmeter����߲��ý��̺��߳���ѹ�⣬�������������ߡ���һ�㶼Ҫ�ü�̨������ѹ���������
Locust�������Ʊ����˽��̺��̣߳�����Э�̣�gevent�����ơ�Э�̱�����ϵͳ����Դ���ȣ����Դ����ߵ�������������
Locust��װʹ��3
centos6.7ʹ��Locust
Python��װLocust����GitHub��¡��������������Python setup.py install ���а�װ��
GitHub��ַ��https://github.com/locustio/locust
�ڰ�װ֮ǰ����Ȱ�װ������������
install_requires=[��gevent>=1.2.2��, ��flask>=0.10.1��, ��requests>=2.9.1��, ��msgpack-python>=0.4.2��, ��six>=1.10.0��, ��pyzmq==15.2.0��]
- 1.gevent����Python��ʵ��Э�̵ĵ������⡣Э���ֽ��߳�Corouine��ʹ��gevent���Ի�ȡ���ߵIJ���������
- 2.flask��Python��һ��web������ܣ���django�൱��
- 3.requests��֧��http/https���ʵĿ⣻
- 4.msgpack-python��һ�ֿ��١����յĶ��������л���ʽ��ʹ��������json�����ݣ�
- 5.six���ṩ��һЩ�Ĺ��߷�װPython2��Python3 ֮��IJ��죻
- 6.pyzmq����װ����������⣬����Locust�����ڶ�����̻����������ֲ�ʽִ�в�������
��centos 6.7��װ��Щ�⣨ע��汾����ʹ��pip��װ�Ϳ����ˣ�
�����������������Python setup.py install �����Ȼ������ϵ���������û�кϷ���װ�����װ�ɹ���
��֤��װ��
������� locust �Chelp
-
[root@localhost locust]
# locust --help
-
Usage: locust [options] [LocustClass [LocustClass2 ... ]]
-
-
Options:
-
-h, --help show this help message
and exit
-
-H HOST, --host=HOST Host to load test
in the following format:
-
http://
10.21
.32
.33
#�������еIJ��Ե�ַ��������ϵͳ��������IP��
-
--web-host=WEB_HOST Host to bind the web interface to. Defaults to
'' (all
-
interfaces)
-
-P PORT, --port=PORT, --web-port=PORT
-
Port on which to run web host
-
-f LOCUSTFILE, --locustfile=LOCUSTFILE
#ָ�����ܲ��Խű��ļ�
-
Python module file to
import, e.g.
'../other.py'.
-
Default: locustfile
-
--csv=CSVFILEBASE, --csv-base-name=CSVFILEBASE
-
Store current request stats to files
in CSV format.
-
--master Set locust to run
in distributed mode
with this
-
process
as master
-
--slave Set locust to run
in distributed mode
with this
-
process
as slave
-
--master-host=MASTER_HOST
-
Host
or IP address of locust master
for distributed
-
load testing. Only used when running
with --slave.
-
Defaults to
127.0
.0
.1.
-
--master-port=MASTER_PORT
-
The port to connect to that
is used by the locust
-
master
for distributed load testing. Only used when
-
running
with --slave. Defaults to
5557. Note that
-
slaves will also connect to the master node on this
-
port +
1.
-
--master-bind-host=MASTER_BIND_HOST
-
Interfaces (hostname, ip) that locust master should
-
bind to. Only used when running
with --master.
-
Defaults to * (all available interfaces).
-
--master-bind-port=MASTER_BIND_PORT
-
Port that locust master should bind to. Only used when
-
running
with --master. Defaults to
5557. Note that
-
Locust will also use this port +
1, so by default the
-
master node will bind to
5557
and
5558.
-
--expect-slaves=EXPECT_SLAVES
-
How many slaves master should expect to connect before
-
starting the test (only when --no-web used).
-
--no-web Disable the web interface,
and instead start running
-
the test immediately. Requires -c
and -r to be
-
specified.
#��ʾ��ʹ��web�������в��ԣ��ӿ�ѹ������һ��ʹ�ø�Щ����
-
-c NUM_CLIENTS, --clients=NUM_CLIENTS
-
Number of concurrent clients. Only used together
with
-
--no-web
#���������û���
-
-r HATCH_RATE, --hatch-rate=HATCH_RATE
#����ÿ�������������û���
-
The rate per second
in which clients are spawned. Only
-
used together
with --no-web
-
-n NUM_REQUESTS, --num-request=NUM_REQUESTS
#�����������
-
Number of requests to perform. Only used together
with
-
--no-web
-
-L LOGLEVEL, --loglevel=LOGLEVEL
-
Choose between DEBUG/INFO/WARNING/ERROR/CRITICAL.
-
Default
is INFO.
-
--logfile=LOGFILE Path to log file. If
not set, log will go to
-
stdout/stderr
-
--
print-stats Print stats
in the console
-
--only-summary Only
print the summary stats
-
--no-reset-stats Do
not reset statistics once hatching has been
-
completed
-
-l, --list Show list of possible locust classes
and exit
-
--show-task-ratio
print table of the locust classes
' task execution
-
ratio
-
--show-task-ratio-json
-
print json data of the locust classes' task execution
-
ratio
-
-V, --version show program
's version number and exit
Locust�ű�ʹ��˵��3
ע�⣺���Ӵ��ļ����Ƶ����������
��ÿһ��HTTP���ӵĻ����ϴ�һ�����ļ��������ļ���������������ϵͳ��������һ�����Դ��ļ���������������ޡ��������С��ģ���û����������ڲ���ʱ���ᷢ�����ϡ����Ӳ���ϵͳ��Ĭ������������ļ����Ƶ�һ�����ָ���ģ���û��������������ܴﵽ����Ҫ�IJ��ԣ���centos������������ִ��ulimit 655336�������ļ������������в��ᱨopen too many file �Ĵ���
��������url�����ӣ�
-
from locust
import HttpLocust,TaskSet,task
-
-
# �����û���Ϊ���̳�TaskSet�࣬���������û���Ϊ
-
# (���������Ÿ������������ǻ���requests�ģ�ÿ�����������requests��࣬�����������������Ӧ�����requestsһ����ʹ�ã�url����д����·��)
-
# client.get===>requests.get
-
# client.post===>requests.post
-
class test_126(TaskSet):
-
# taskװ�θ÷���Ϊһ�������IJ�������ָ������Ϊ��ִ��Ȩ�ء�����Խ��ÿ�α������û�ִ�и���Խ�ߣ�������Ĭ����1��
-
@task()
-
def test_baidu(self):
-
# ����requests������ͷ
-
header = {
"User-Agent":
"Mozilla/5.0 "
-
"(Windows NT 6.1; Win64; x64) AppleWebKit/537.36 "
-
"(KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36"}
-
# r�ǰ���������Ӧ���ݵ�һ������
-
r = self.client.get(
"/",timeout=
30,headers=header)
-
# �������ʹ��assert���������Ƿ���ȷ��Ҳ����ʹ��if�ж�
-
assert r.status_code ==
200
-
-
# ����������������ܲ��ԣ��̳�HttpLocust
-
class websitUser(HttpLocust):
-
# ָ��һ�����涨����û���Ϊ��
-
task_set = test_126
-
#ִ������֮���û��ȴ�ʱ����½磬��λ���룬�൱��lr�е�think time
-
min_wait =
3000
-
max_wait =
6000
-
[root @ localhost locust_baidu]
# locust -f locustfile.py --host=http://www.126.com
-
-
[
2017 -
06 -
08
12:
33:
42,
662] localhost.localdomain / INFO / locust.main: Starting web monitor at
: 8089
-
[
2017 -
06 -
08
12:
33:
42,
663] localhost.localdomain / INFO / locust.main: Starting Locust
0.8 a3
2.�Chost ָ��������url��������ַ��IP��ַ��
ͨ����������ʣ�http://192.168.0.107:8089/��Ĭ�϶˿���8089��
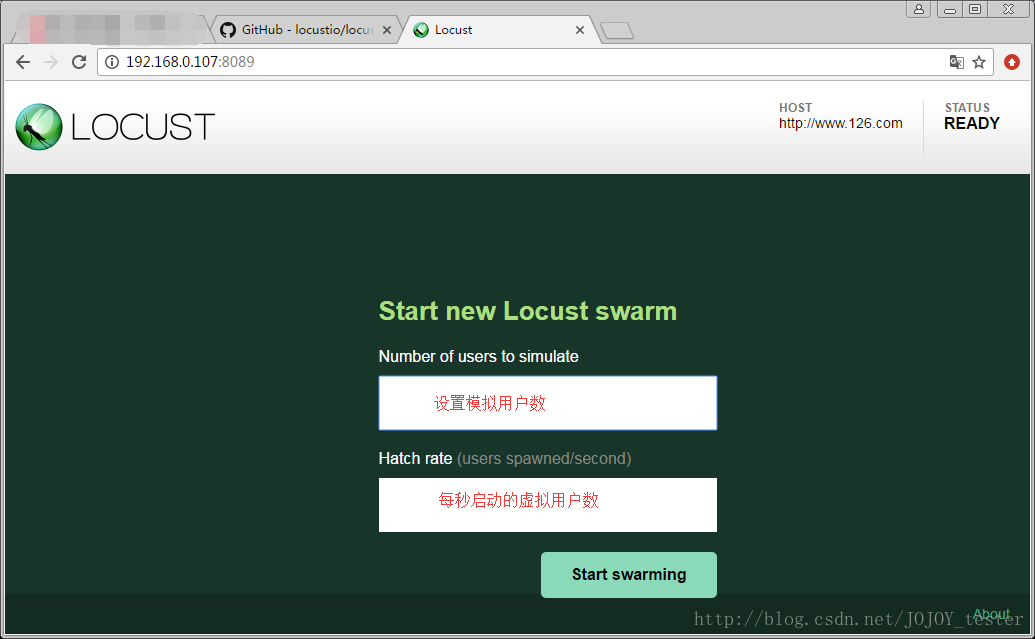
���start swarming���в��ԣ�

- 1.Type���������ͣ�
- 2.Name������·����
- 3.requests����ǰ�����������
- 4.fails����ǰ����ʧ�ܵ�������
- 5.Median���м�ֵ����λ���룬һ���������Ӧʱ����ڸ�ֵ������һ����ڸ�ֵ��
- 6.Average�����������ƽ����Ӧʱ�䣬���룻
- 7.Min���������С�ķ�������Ӧʱ�䣬���룻
- 8.Max�����������������Ӧʱ�䣬���룻
- 9.Content Size����������Ĵ�С����λ�ֽڣ�
- 10.reqs/sec��ÿ��������ĸ�����
ͼ����ʾ��
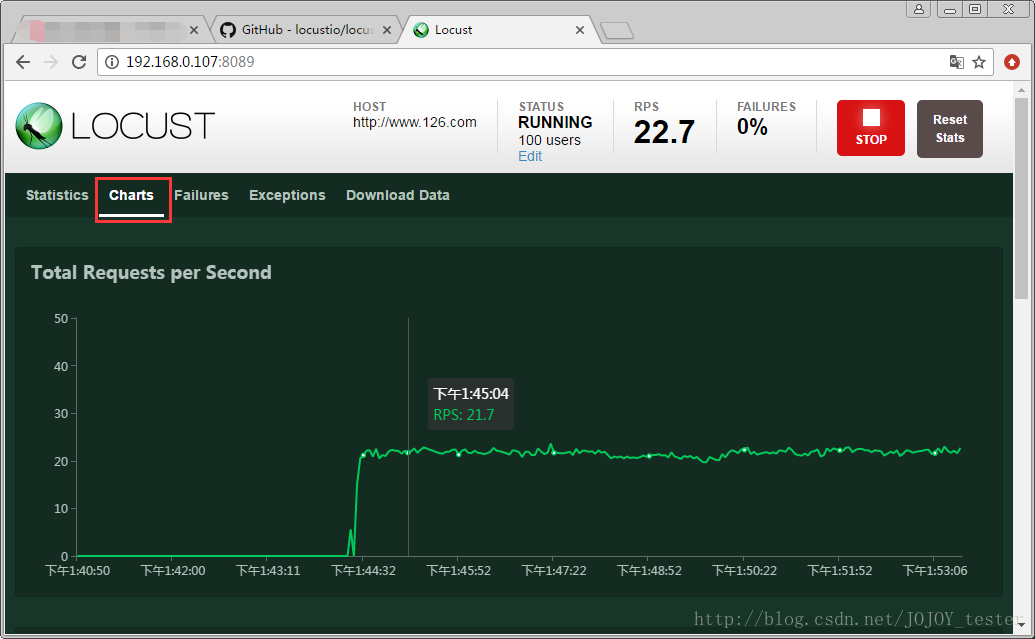
���ϵ��£�
- 1.������/ÿ����Ӧ��������rps��ʵʱͳ��
- 2.ƽ����Ӧʱ��/ƽ��������ʵʱͳ��
- 3.�����û�������
���⣬��������ͳ�Ʊ���ʧ�������쳣������ʧ�ܽ����ʾ����������ز��Խ����
�����ͨ����������Ե���ʽ������ͨ�����Գ�����Ƶ�ʱ�䳤�����У�ѹ������ʱ�䣨һ�㶼��5�������ϰɣ��㹻����Ҫ�ֶ����stop��ť������ѹ�����ԡ�
���ϣ����������ά����һ�������������ʹ�èCno-web��ʽ��
��shell��ֱ�����룺
-
[root@localhost locust_baidu]
# locust -f locustfile.py --host=http://www.126.com --no-web -c 10 -r 10 -n 30
-
[
2017
-06
-08
13:
13:
31,
385] localhost.localdomain/INFO/locust.main: Starting Locust
0.8a3
-
[
2017
-06
-08
13:
13:
31,
385] localhost.localdomain/INFO/locust.runners: Hatching
and swarming
10 clients at the rate
10 clients/s...
-
Name
-
# ���Թ��̵�ʵʱ����
-
������������
-
#���Խ���
-
[
2017
-06
-08
13:
13:
52,
588] localhost.localdomain/INFO/locust.runners: All locusts dead
-
#����ͳ��
-
[
2017
-06
-08
13:
13:
52,
588] localhost.localdomain/INFO/locust.main: Shutting down (exit code
0), bye.
-
Name
# reqs # fails Avg Min Max | Median req/s
-
--------------------------------------------------------------------------------------------------------------------------------------------
-
GET /
39
0(
0.00%)
305
28
5155 |
40
2.00
-
--------------------------------------------------------------------------------------------------------------------------------------------
-
Total
39
0(
0.00%)
2.00
-
-
Percentage of the requests completed within given times
-
Name
# reqs 50% 66% 75% 80% 90% 95% 98% 99% 100%
-
--------------------------------------------------------------------------------------------------------------------------------------------
-
GET /
39
40
41
44
47
52
5100
5200
5200
5155
-
--------------------------------------------------------------------------------------------------------------------------------------------
- 1.�Cno-web����ʾ��ʹ��web�������в��ԣ�
- 2.-c�����������û�������
- 3.-r������ÿ�����������û�����
- 4.-n�����������ܸ�����
���Ի���ѹ��ӿڽű���
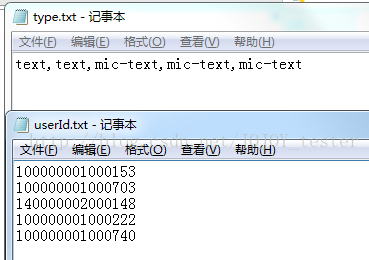
���������ݣ�
readData.py
-
# ˼·����userId.txt��type.txt�ļ�����д����Դ�������ļ�������һһ��Ӧ�ģ�ͨ��readlines()��ȡ������Ϊһ���б���
-
# ͨ��list��������ȡ���ݣ�����ʹ�������
-
import random
-
class Readdata():
-
# ���������init�����У���ֻ֤��ȡһ�����������Ϊ��ֻʵ����һ��
-
def init(self):
-
with open(
"./userId.txt")
as f:
-
userId = f.readlines()
-
# �������Χ0--�����鳤��-1��Ϊ�˺�list�±�һ������0��ʼ
-
self.ran = random.randint(
0,len(userId)
-1)
-
-
def readUserid(self):
-
with open(
"./userId.txt")
as f:
-
userId = f.readlines()
-
userIds = []
-
# readlines��ȡÿһ�����ݱ���Ϊlist��ÿһ��������һ��Ԫ�أ��ַ�����ʽ��
-
# ����Ҫ����תΪint����ȥ�����з�����appendһ�������顣
-
for i
in userId:
-
data = int(i)
-
userIds.append(data)
-
# �����ȡһ����
-
userId = userIds[self.ran]
-
return userId
-
def readType(self):
-
with open(
"./type.txt")
as f1:
-
type_ = f1.readlines()
-
# ȥ��list�еĻ��з���\n
-
type1 =
''.join(type_).strip(
'\n')
-
# �ָ��ַ���������Ϊlist��
-
type2 = type1.split(
',')
-
type3 = type2[self.ran]
-
# print(type(type2))
-
return type3
-
if
name ==
"main":
-
rd = Readdata()
-
print(rd.readType())
-
print(rd.readUserid())
����
common.py
-
import sys,time,random,hashlib
-
sys.path.append(
'../db_set')
-
# from db_set.mysql_db import DB
-
def setUp_():
-
tim = time.time()
-
tim = tim
1000
-
tim = str(tim)
-
# tsʱ���
-
ts = tim.split(
'.')[
0]
-
ran = random.randint(
100,
999)
-
ran = str(ran)
-
# reqIdʱ���ƴ�������
-
reqId =ts + ran
-
# �ܳ�
-
secret =
'xxxxxxxxxxx'
-
#����ͷ
-
header = {
"User-Agent":
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36"}
-
#���ݿ�
-
# db = DB()
-
#����userId
-
userId =
"100000001000153"
-
#����liveId
-
liveId =
"140000002000038"
-
#���Ե�ַ
-
host =
"http://ixxxxxxxhat.com/"
-
return (ts,reqId,secret,header,userId,liveId,host)
-
def md5(reqSign_):
-
md5 = hashlib.md5()
-
str_bytes_utf8 = reqSign_.encode(encoding=
"utf-8")
-
md5.update(str_bytes_utf8)
-
sign = md5.hexdigest()
-
return sign
locust�ļ���
-
from locust
import HttpLocust,TaskSet,task
-
from common
import setUp_,md5
-
from readData
import Readdata
# �������������
-
-
# �����û���Ϊ
-
class SpeakAdd(TaskSet):
-
# �������ʵ������
-
ts = setUp_()[
0]
-
reqId = setUp_()[
1]
-
secret = setUp_()[
2]
-
header = setUp_()[
3]
-
# db = setUp_()[4]
-
# userId = setUp_()[4]
-
# liveId = setUp_()[5]
-
# ��ȡ����������
-
rd = Readdata()
-
# ��������type����Ϊ��ͬ�û�����Dz�ͬ��
-
type = rd.readType()
-
# ��ȡ������id������ͷ������Ͷ�Ӧ���������˴���
-
userId = rd.readUserid()
-
#����
-
reqSign = reqId +
':' + secret +
':' + ts
-
sign = md5(reqSign)
-
# �������
-
data = {
"id": reqId,
-
"timestamp": ts,
-
"sign": sign,
-
"data": {
"commentId":
"",
-
"topicId":
"100000046000082",
-
"type": type,
-
"liveId":
"140000002000038",
-
"content":
"�����ڷ��ԣ�" + ts,
-
"isReplay":
"N",
-
"page": {
"size":
"20",
"page":
"1"},
-
"userId": userId}}
-
@task(1)
-
def testSpeakadd(self):
-
# ��requests����һ��д
-
r = self.client.post(
"/h5/speak/add",json=self.data,headers=self.header,timeout=
30)
-
result = r.json()
# �����ֵ�
-
# ����
-
assert r.status_code ==
200
-
assert result[
'state'][
'code'] ==
0
-
-
-
# �������ܲ���
-
class WebsiteUser(HttpLocust):
-
task_set = SpeakAdd
-
# �ӿڲ���think time ����Ϊ0
-
min_wait =
0
-
max_wait =
0
-
-
# �������ͨ��ֱ������Python locustfile1.py c r n ���в��ԣ����ַ�ʽ�ʺ� --no-web����
-
if
name ==
"main":
-
import os,sys
-
# sys.argv��һ��list��Ԫ�����û��Զ���ģ�ԭ����str���ͣ���Ҫת��Ϊint
-
c = int(sys.argv[
1])
-
r = int(sys.argv[
2])
-
t = int(sys.argv[
3])
-
for i
in range(
2):
-
# os.system(����)����������shell��Windows����
-
os.system(
"locust -f locustfile1.py --host=http://xxxxxt2.qlchat.com --no-web -c %d -r %d -n %d" %(c,r,t))
���Է���һ��
�����ӿ�ѹ�����ԣ�
locust -f locustfile.py �Chost=http://inner.test2.qlchat.com
�������
http://192.168.0.107:8089/
���ݳ�������ѹ�����ԣ�
����1������5���ӣ��û���1000��ÿ������100����¼���Խ�����ݣ�����������ָ�ꣻ
����2������5���ӣ��û���1000��ÿ������200����¼���Խ�����ݣ�����������ָ�ꣻ
����3������5���ӣ��û���1000��ÿ������500����¼���Խ�����ݣ�����������ָ�ꣻ
������ָ�꣺CPU���ڴ��
���ܲ��Է�����
������������
���Է�������
ʹ������һ�ֲ��Է�ʽ���Cno-web��-c��-r��-n��
��������ִ�в��ԣ�ÿ�ֳ�����¼���Խ�����ݣ�����������ָ�ꣻ
����һ��locust -f locustfile.py �Chost=http://inner.test2.qlchat.com �Cno-web -c 1000 -r 100 -n 30000
��������locust -f locustfile.py �Chost=http://inner.test2.qlchat.com �Cno-web -c 1000 -r 500 -n 30000
��������locust -f locustfile.py �Chost=http://inner.test2.qlchat.com �Cno-web -c 1000 -r 1000 -n 30000
�ܽ
����֮����������id��Ҫ������ͬһ����Ҳ����ͬ�ķ����ˣ���������ʹ�������ӽӽ��û�ʹ�ó��������Dz���ʱ����ͬһ���û� ==�����ġ������и��ֿ����鷳ָ���¡�����
���urlѹ������Ҳ����ҵ�����ܲ���3��
��������
������
����
��
˼·��
��һ��������ҵ���У����û���¼���˳�ϵͳ���������һ��ҳ�浽��һ��ҳ�棬ÿ��ҳ�涼����url����ģ�������д�����¼�ķ�������д��һ��ҳ�����������������������������������һ��������ҵ���ˡ�Ȼ������¼�������û������������������û���ÿ�����������û���������Ƴ���ȥ������