经典 O(nlogn) 复杂度算法之快排
关注「码哥字节」并设置星标接收最新技术干货,后台回复「加群」获取更多成长
快速排序是由东尼・霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序原理
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n?),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,可是这是为什么呢,我也不知道。好在我的强迫症又犯了,查了 N 多资料终于在《算法艺术与信息学竞赛》上找到了满意的答案:
快速排序的最坏运行情况是 O(n?),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
遍历 p 到 r 之间的数据,将小于 pivot 的放在左边,大于 pivot 的放在右边,pivot 则在中间。数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
动图展示
静态原理图
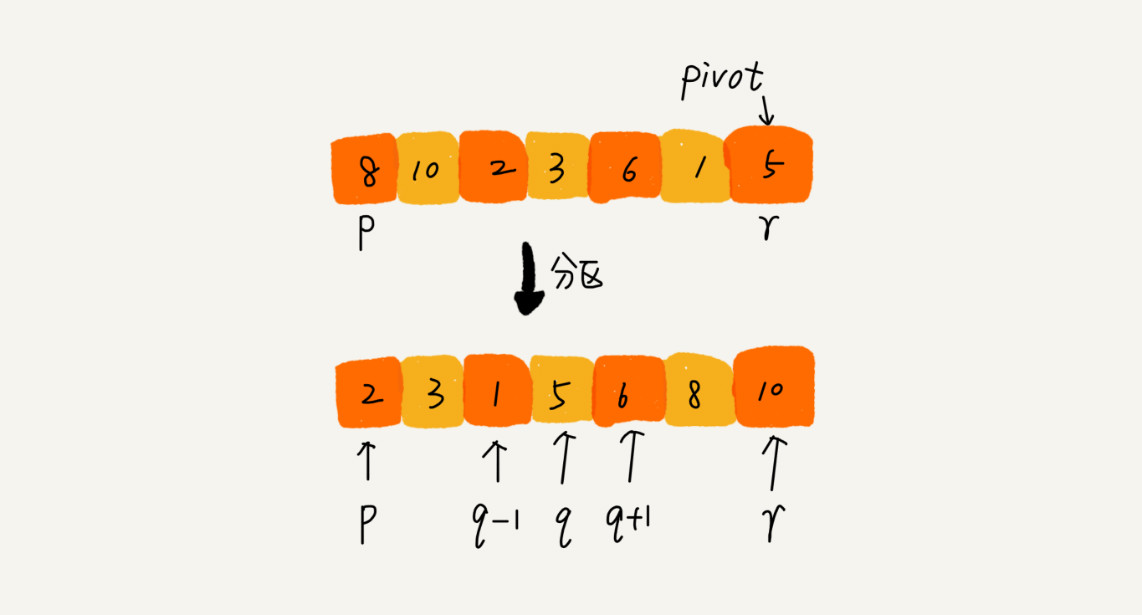
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
选择好基准元素以后,我们要做的就是把小于基准元素的交换到基准元素的左边,大于的交换到基准元素的右边。
从基准元素
递推公式与代码实现
公式如下所示:
递推公式:
quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1, r)终止条件:
p >= r转化成代码的大致思路如下伪代码,主要就是利用了递归技巧实现分区并对每个区排序,关键就是在于分区函数对数据的交换:
// 快速排序,A 是数组,n 表示数组的大小
quickSort(A, n) {quickSortC(A, 0, n-1)
}
// 快速排序递归函数,p,r 为下标
quickSortC(A, p, r) {if p >= r then returnq = partition(A, p, r) // 获取分区点quickSortC(A, p, q-1)quickSortC(A, q+1, r)
}归并排序中有一个 merge() 合并函数,我们这里有一个 partition() 分区函数。partition() 分区函数实际上我们前面已经讲过了,就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的第一个元素),然后对 A[p…r] 分区,函数返回 pivot 的下标。
因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是一个稳定的排序算法。
完整代码
package com.zero.algorithms.linear.sort;import java.util.Arrays;/*** 快速排序*/
public class QuickSort implements ComparisonSort {@Overridepublic int[] sort(int[] sourceArray) {// 对 arr 进行拷贝,不改变参数内容int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);quickSortInternal(arr, 0, arr.length - 1);return arr;}/*** 快速排序* @param arr 数据* @param p 开始下标* @param r 结束下标* @return*/private void quickSortInternal(int[] arr, int p, int r) {if (p >= r) {return;}// 获取分区点,也就是 pivot 下标int q = partition(arr, p, r);// 递归调用直到有序quickSortInternal(arr, p, q - 1);quickSortInternal(arr, q + 1, r);}/*** 分区函数:挖坑填洞,先把基准元素的坑挖出来,然后遍历坑后面的数组,比坑的位置小则交换数据* 。并标记最新的坑的位置* @param arr 待分区数据* @param p 开始下标* @param r 结束喜爱奥* @return*/private int partition(int[] arr, int p, int r) {// 设置基准值,选择第一个,也可以随机,int pivot = arr[p];//从基准元素的下一个位置开始遍历数组,记录当前坑的位置,最后把 pivot 值放到这个坑中int index = p;for (int i = p + 1; i <= r; i++) {// 比基准数据小if (arr[i] < pivot) {// 坑位移动index++;// 交换数据 i 位置的 与 index 位置数据交换int indexValue = arr[index];arr[index] = arr[i];arr[i] = indexValue;}}// 最后把 pivot位置与 与 最后的坑 index 交换arr[p] = arr[index];arr[index] = pivot;return index;}
}归并排序与快速排序对比
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢?
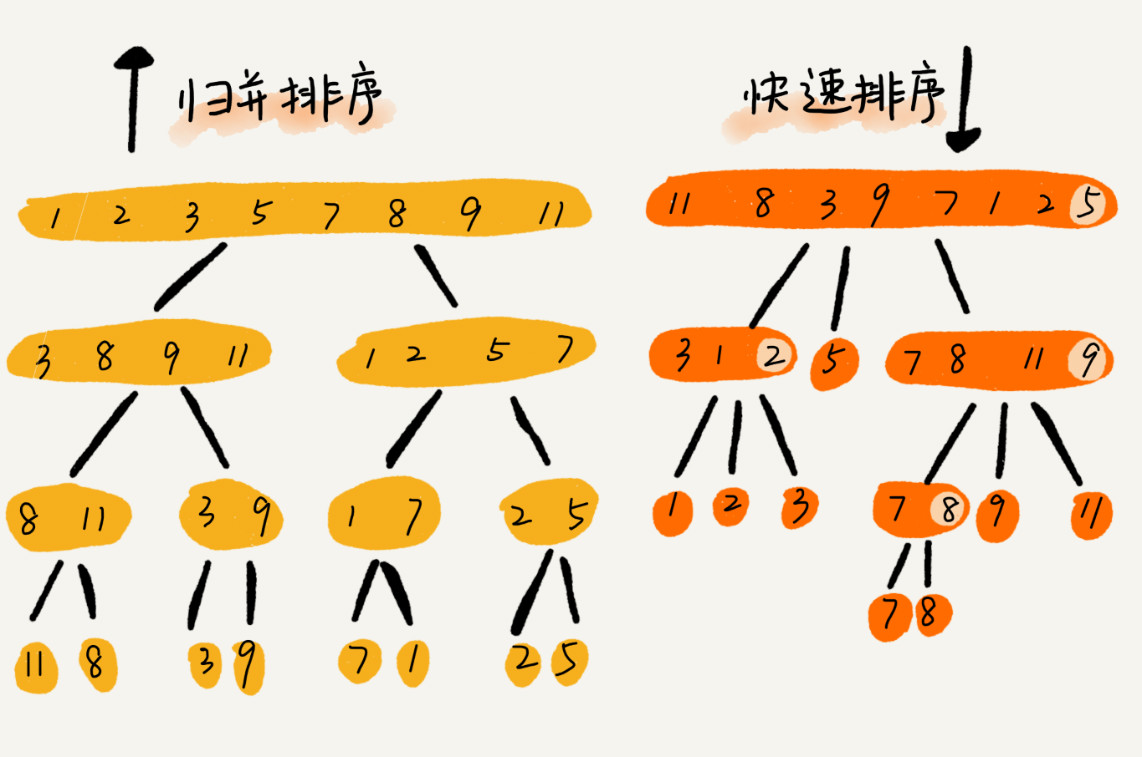
可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
总结
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和 merge() 合并函数。同理,理解快排的重点也是理解递推公式,还有 partition() 分区函数。
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
快速排序算法虽然最坏情况下的时间复杂度是 O(n2),但是平均情况下时间复杂度都是 O(nlogn)。不仅如此,快速排序算法时间复杂度退化到 O(n2) 的概率非常小,我们可以通过合理地选择 pivot 来避免这种情况。
详细代码我提交在 GitHub,戳此即可查看。
关注 码哥字节,设置星标第一时间接收技术干货,素质三连(转发、点赞、收藏)是我们持续写好文章的动力。
