Ъ§ОнПт
АВзАФЃПщ
pip install flask-sqlalchemy
pip install pymysql
АВзАmysql
ЕижЗ
НщЩм
ORMНщЩм
- ORM Object Relationship Mapping
- ФЃаЭгыБэжЎМфЕФгГЩф
SQLAlchemy
ВЩгУаДдЩњsqlЕФЗНЪНдкДњТыжаЛсГіЯжДѓСПЕФsqlгяОфЃЌЛсГіЯжвЛаЉЮЪЬт:
- sqlгяОфжиИДРћгУТЪВЛИпЃЌдНИДдгЕФsqlгяОфЬѕМўдНЖрЃЌДњТыдНГЄЁЃЛсГіЯжКмЖрЯрНќЕФsqlгяОф
- КмЖрsqlгяОфЪЧдквЕЮёТпМжаЦДГіРДЕФЃЌШчЙћгаЪ§ОнПташвЊИќИФЃЌОЭвЊШЅаоИФетаЉТпМЃЌетЛсКмШнвзТЉЕєЖдФГаЉsqlгяОфЕФаоИФЁЃ
- аДsqlЪБШнвзКіТдwebАВШЋЮЪЬтЃЌИјЮДРДдьГЩвўЛМ
ORM,ШЋГЦObject Relational MappingЃЌжаЮФНазіЖдЯѓЙиЯЕгГЩфЃЌЭЈЙ§ORMПЩвдЭЈЙ§РрЕФЗНЪНШЅВйзїЪ§ОнПтЃЌЖјВЛгУдйаДдЩњЕФsqlгяОфЁЃЭЈЙ§АбБэгГЩфГЩРрЃЌАбаазїЪЕР§ЃЌАбзжЖЮзїЮЊЪєадЃЌORMдкжДааЖдЯѓВйзїЕФЪБКђзюжеЛЙЪЧЛсАбЖдЯѓЕФВйзїзЊЛЛЮЊЪ§ОнПтдЩњгяОфЁЃЪЙгУORMгааэЖргаЕу:
- взгУадЃКЪЙгУORMзіЪ§ОнПтЕФПЊЗЂПЩвдгааЇЕФМѕЩйжиИДsqlгяОфЕФИХТЪЃЌаДГіРДЕФФЃаЭвВИќМгжБЙлЧхЮњЁЃ
- адФмЫ№КФаЁ:ORMзЊЛЛГЩЕзВуЪ§ОнПтВйзїжИСюШЗЪЕЛсгавЛаЉПЊЯњЁЃЕЋДгЪЕМЪЕФЧщПіРДПДЃЌетжжадФмЫ№КФКмЩйЃЌжЛвЊВЛЪЧЖдадФмгабЯИёЕФвЊЧѓЃЌзлКЯПМТЧПЊЗЂаЇТЪЃЌДњТыЕФдФЖСадЃЌДјРДЕФКУДІвЊдЖДѓгкадФмЫ№КФЃЌЖјЧвЯюФПдНДѓзїгУдНУїЯдЁЃ
- ЩшМЦСщЛю:ПЩвдЧсЫЩЕФаДГіИДдгЕФВщбЏ
- ПЩвЦжВад:SQLAlchemyЗтзАСЫЕзВуЕФЪ§ОнПтЪЕЯжЃЌжЇГжЖрИіЙиЯЕЪ§ОнПтв§ЧцЃЌАќРЈСїааЕФMySQLЁЂPostgreSQLКЭSQLiteЁЃПЩвдЗЧГЃЧсЫЩЕФЧаЛЛЪ§ОнПт
СЌНгЪ§ОнПт
- ДДНЈЪ§ОнПт
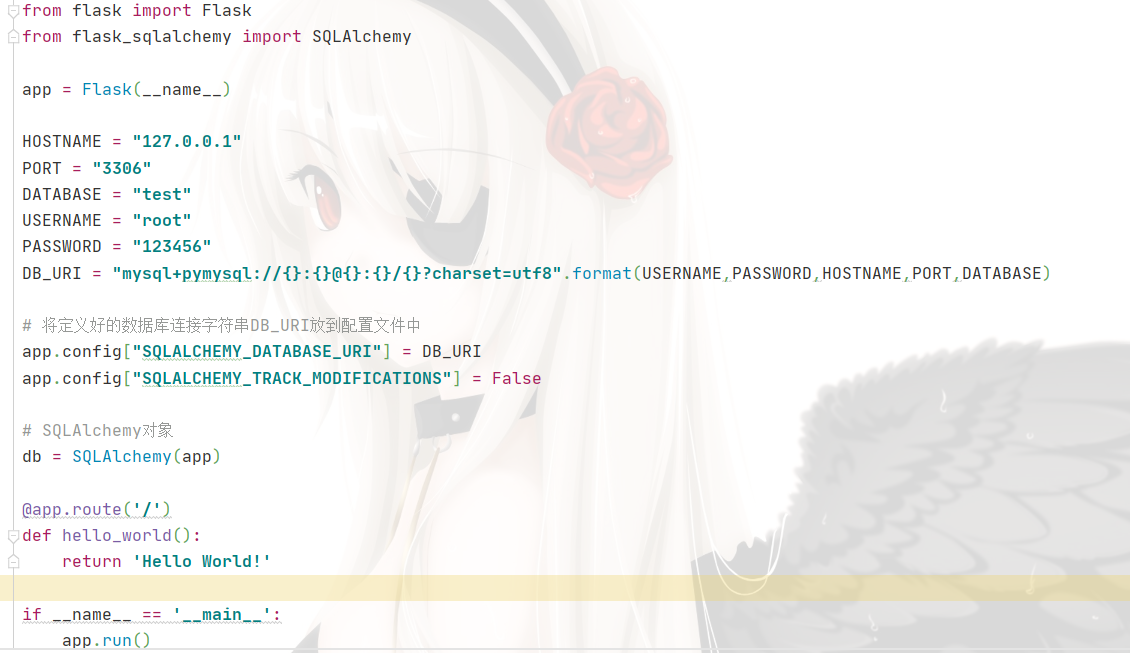
- ЖЈвхЪ§ОнПтСЌНгзжЗћДЎDB_URI
ИёЪН:dialect+dricer://username:password@host:port/database
ШчЯТЃК
HOSTNAME = "127.0.0.1"
PORT = "3306"
DATABASE = "test"
USERNAME = "root"
PASSWORD = "123456"
DB_URI = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)
- НЋЖЈвхКУЕФЪ§ОнПтСЌНгзжЗћДЎDB_URIЗХЕНХфжУЮФМўжа
app.config["SQLALCHEMY_DATABASE_URI"] = DB_URI
- ЖЈвхSQLAlchemyЖдЯѓ
db = SQLAlchemy(app)
дЫааКѓЃЌГіЯжШчЯТОЏИцЃК
SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.'SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and '
жЛашвЊЬэМгШчЯТМДПЩЃК
# ЦСБЮSQLalchemyЗЂЫЭЕФаХКХ
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
ДДНЈФЃаЭ
ЭЈЙ§ЪЙгУdb.ModelНјааДДНЈФЃаЭРрЁЃ
зюаЁгІгУ
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)HOSTNAME = "127.0.0.1"
PORT = "3306"
DATABASE = "test"
USERNAME = "root"
PASSWORD = "123456"
DB_URI = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)# НЋЖЈвхКУЕФЪ§ОнПтСЌНгзжЗћДЎDB_URIЗХЕНХфжУЮФМўжа
app.config["SQLALCHEMY_DATABASE_URI"] = DB_URI
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False# SQLAlchemyЖдЯѓ
db = SQLAlchemy(app)class UserModel(db.Model):id = db.Column(db.Integer,primary_key=True,autoincrement=True)name = db.Column(db.String(200))# ГѕЪМЛЏdef __init__(self, name):self.name = name# ДђгЁзжЗћДЎdef __repr__(self):return '<User %r>' % self.nameif __name__ == '__main__':app.run()
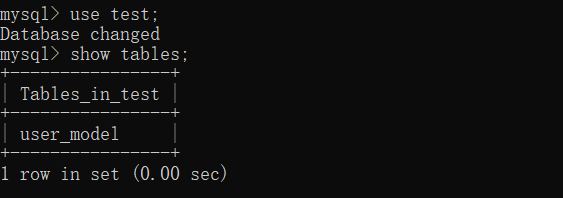
ЮЊСЫДДНЈГѕЪМЪ§ОнПтЃЌжЛашвЊДгНЛЛЅЪН Python shell жаЕМШы db ЖдЯѓВЂЧвЕїгУ SQLAlchemy.create_all()ЗНЗЈРДДДНЈБэКЭЪ§ОнПт:
>>> from yourapplication import db
>>> db.create_all()
ШчЯТЃК
>>> from app import db
>>> db.create_all()
етбљОЭЛсдкЪ§ОнПтЩњГЩБэ
ШчЙћЯывЊЩОГ§ЃЌОЭЪЧгУdb.drop_all()ЁЃ
ФПЧАЪ§ОнПтвбОЩњГЩЃЌЯждкНјааДДНЈвЛаЉгУЛЇ:
>>> from app import UserModel
>>> user = UserModel(name="test1")
ЕЋЪЧЫќУЧЛЙУЛгаеце§ЕиаДШыЕНЪ§ОнПтжаЃЌвђДЫЖЏЪжШЗБЃЫќУЧвбОаДШыЕНЪ§ОнПтжа:
>>> db.session.add(user)
>>> db.session.commit()
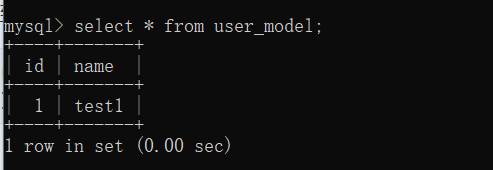
ЗУЮЪЪ§ОнПтжаЕФЪ§ОнвВЪЧЪЎЗжМђЕЅЕФ:
>>> users = UserModel.query.all()
>>> usersOut[10]: [<User 'test1'>]
ЗЕЛиНсЙћДѓаЁПижЦ
- all() ЗЕЛиЫљга
- first() ВщбЏВЂЗЕЛиЕквЛЬѕ,УЛгаЪ§ОнЮЊПе
- one() ВщбЏЫљгаВЂбЯИёЗЕЛивЛЬѕЪ§ОнЃЌШчЙћВщбЏЕНЖрЬѕЪ§ОнЛђУЛгаЪ§ОнЃЌЖМЛсБЈДэ
- one_or_none ЭЌ oneЃЌУЛгаЪ§ОнЛсЗЕЛиNoneЃЌВЛЛсБЈДэЃЌЦфЫћвЛбљЁЃ
- scalar ЭЌ oneЃЌЕЋЪЧжЛЗЕЛиФЧЬѕЪ§ОнЕФЕквЛИізжЖЮЁЃ
діЩОВщИФ
ЖЈвхФЃаЭ
class UserModel(db.Model):id = db.Column(db.Integer,primary_key=True,autoincrement=True)name = db.Column(db.String(200))# ГѕЪМЛЏdef __init__(self, name):self.name = name# ДђгЁзжЗћДЎdef __repr__(self):return '<User %r>' % self.name
ЬэМг
>>> db.drop_all()
>>> db.create_all()
- ЬэМгЕЅИіЪ§Он
>>> add1()
- вЛДЮадЬэМгЖрИіЪ§Он
>>> add2()
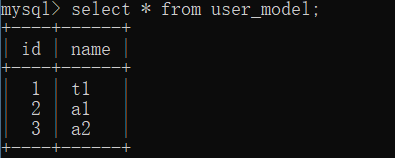
ВщбЏ
ЯъЯИВщбЏЗНЗЈЃЌМћКѓај
- ЪЙгУfilter_byРДзіЬѕМўВщбЏ
>>> user = UserModel.query.filter(UserModel.name.contains("t")).all()
>>> print(user)
[<User 't1'>]
- ЪЙгУfilterРДзіЬѕМўВщбЏ
>>> user = UserModel.query.filter_by(name="t1").all()
>>> user
[<User 't1'>]
- ЪЙгУgetЗНЗЈВщевЪ§ОнЃЌgetЗНЗЈЪЧИљОнidРДВщбЏЕФЃЌжЛЛсЗЕЛивЛЬѕЪ§ОнЛђепNone
>>> user = UserModel.query.get(1)
>>> user
Out[7]: <User 't1'>
- ЪЙгУfirstЗНЗЈЛёШЁНсЙћМЏжаЕФЕквЛЬѕЪ§Он
>>> user = UserModel.query.first()
>>> user
Out[7]: <User 't1'>
аоИФ
аоИФЖдЯѓЃЌЪзЯШдкЪ§ОнПтВщевЪ§ОнЃЌШЛКѓНЋЪ§ОнНјаааоИФЃЌзюКѓзіcommitВйзї
>>> user = UserModel.query.first()
>>> user.name = "ttt"
>>> db.session.commit()
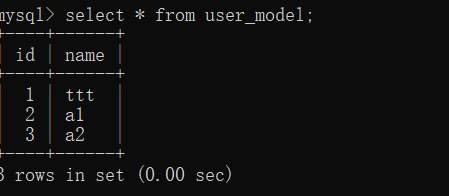
ЩОГ§
ЩОГ§ЖдЯѓЃЌЪзЯШдкЪ§ОнПтВщевЪ§ОнЃЌШЛКѓНЋВщевЕНЕФЪ§ОнНјааЩОГ§ЃЌзюКѓжДааcommitВйзї
>>> user = UserModel.query.first()
>>> db.session.delete(user)
>>> db.session.commit()
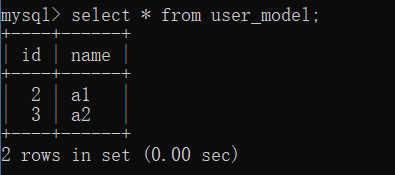
БэУћгыСаУћЩшжУ
- БэУћЭЈЙ§
__tablename__НјааЩшжУБэУћГЦЃЌЗёдђЛсвдРрУћНјааУќУћЁЃР§ШчUserModelЕФБэУћЮЊuser_model
class Article(db.Model):__tablename__ = "article"
- СаУћЃЌЭЈЙ§
db.ColumnжаЕФnameВЮЪ§НјааУќУћ
db.Column(name="xxx")
ГЃгУЪ§ОнРраЭЯъНт
- Integer:ећаЭ
- Float:ИЁЕуРраЭ
- Boolean:ДЋЕнTrue/FalseНјШЅ
- DECIMAL:ЖЈЕуРраЭЃЌЪЧзЈУХЮЊСЫНтОіИЁЕуОЋЖШЖЊЪЇЕФЮЪЬтЕФЃЌдкДцДЂЯрЙиЕФзжЖЮЕФЪБКђНЈвщЖМЪЧвЊетИіЪ§ОнзжЖЮЃЌВЂЧветИіРраЭЪЙгУЕФЪБКђашвЊДЋЕнСНИіВЮЪ§ЃЌЕквЛИіВЮЪ§ЪЙгУРДБъМЧзжЖЮФмЙЛДцДЂЖрЩйИіЪ§зжЃЌЕкЖўИіВЮЪ§ЪЧБэЪОаЁЪ§ЕуЕФзюДѓЮЛЪ§
- enum:УЖОйРраЭЁЃжИЖЈФГИізжЖЮжЛФмЪЧУЖОйжажИЖЈЕФМИИіжЕЃЌВЛФмЮЊЦфЫћжЕЃЌдкORMФЃаЭжаЃЌЪЙгУEnumРДзїЮЊУЖОйЃЌЪОР§ДњТыШчЯТ:
import enum
class TagEnum(enum.Enum):python = "python"flask = "flask"django = "django"class Article(Base):__tablename__ = "article"id = Column(Integer,primary_key=True,autoincrement=True)# tag = Column(Enum('python','django','flask'))tag = Column(Enum(TagEnum))# article = Article(tag='1')
# article = Article(tag='python')
article = Article(tag=TagEnum.python)
- Date:ДЋЕнdatetime.date()НјШЅЁЃДцДЂЪБМфЃЌжЛФмДцДЂФъдТШеЁЃгГЩфЕНЪ§ОнПтжаЪЧdateРраЭЁЃдкpythonжаЃЌПЩвдЪЙгУdatetime.dateРДжИЖЈ
class Article(Base):__tablename__ = "article"id = Column(Integer,primary_key=True,autoincrement=True)create_time = Column(Date)from datetime import date
article = Article(create_time=date(year=2017,month=10,day=8))
- DateTime:ДЋЕнdatetime.datetime()НјШЅЁЃДцДЂЪБМфЃЌПЩвдДцДЂФъдТШеЪБЗжУыКСУыЕШЁЃгГЩфЕНЪ§ОнПтжавВЪЧdatetimeРраЭЁЃдкpythonДњТыжаЃЌПЩвдЪЙгУ"datetime.datetime"РДжИЖЈЃЌЪОР§ЃК
class Article(Base):__tablename__ = "article"id = Column(Integer,primary_key=True,autoincrement=True)create_time = Column(DateTime)from datetime import datetime
article = Article(create_time=datetime(year=2017,month=11,day=11,hour=11,minute=11,second=11,microsecond=11))
- Time:ДЋЕнdatetime.time()НјШЅЁЃДцДЂЪБМфЃЌПЩвдДцДЂЪБЗжУыЃЌгГЩфЕНЪ§ОнПтжавВЪЧtimeРраЭЁЃдкpythonДњТыжаЃЌПЩвдЪЙгУ"datetime.time"РДжИЖЈЃЌЪОР§ЃК
class Article(Base):__tablename__ = "article"id = Column(Integer,primary_key=True,autoincrement=True)create_time = Column(Time)from datetime import time
article = Article(create_time=time(hour=11,minute=11,second=11,microsecond=11))
# article = Article(create_time=datetime.now())
- String:зжЗћРраЭЃЌЪЙгУЪБашвЊжИЖЈГЄЖШЃЌЧјБ№гкTextРраЭ
- Text:ЮФБОРраЭ.ДцДЂГЄзжЗћДЎЃЌвЛАуПЩвдДцДЂ6wЖрИізжЗћЁЃШчЙћГЌГіСЫетИіЗЖЮЇЃЌПЩвдЪЙгУLONGTEXTРраЭЃЌгГЩфЕНЪ§ОнПтжаОЭЪЧtextРраЭ
- LONGTEXT:ГЄЮФБОРраЭ
ColumnГЃгУВЮЪ§
- default:ЩшжУФГИізжЖЮЕФФЌШЯжЕЁЃФЌШЯжЕПЩвдЮЊвЛИіБэДяЪНЛђепБфСПЃЌКЏЪ§
- nullable:ЩшжУФГИізжЖЮЪЧЗёПЩПеЃЌФЌШЯжЕЮЊTrue
- primary_key:ЩшжУФГИізжЖЮЮЊжїМќ
- unique:ЩшжУФГИізжЖЮЮЊЮЈвЛЕФзжЖЮЃЌВЛдЪаэгажиИДжЕЃЌФЌШЯжЕЮЊTrue
- autoincrement:ЩшжУетИізжЖЮЮЊздЖЏдіГЄЕФ
- name:жИЖЈormФЃаЭжаФГИіЪєадгГЩфЕНБэжаЕФзжЖЮУћЃЌШчЙћВЛжИЖЈЃЌФЧУДЛсЪЙгУетИіЪєадЕФУћзжзїЮЊзжЖЮУћЁЃШчЙћжИЖЈСЫЃЌОЭЛсЪЙгУжИЖЈЕФетИіжЕзїЮЊВЮЪ§ЃЌетИіВЮЪ§вВПЩвдЕБзіЮЛжУВЮЪ§ЃЌдкЕк1ИіВЮЪ§РДжИЖЈЁЃ
class ArticleModel(db.Model):id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),name="БъЬт",nullable=False)phone = db.Column(db.String(11),unique=True)update_time = db.Column(db.DateTime, onupdate=datetime.now, default=datetime.now)# ГѕЪМЛЏdef __init__(self, title,phone):self.phone = phoneself.title = title
ДгНЛЛЅЪН Python shell жаНјааДДНЈЃК
>>> from app import db
>>> from app import ArticleModel
>>> db.drop_all()
>>> db.create_all()
>>> article = ArticleModel(title="123",phone="1234567890")
>>> db.session.add(article)
>>> db.session.commit()
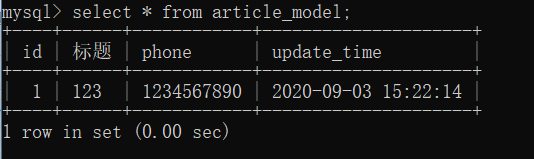
- onupdate:дкЪ§ОнИќаТЕФЪБКђЛсЕїгУетИіВЮЪ§жИЖЈЕФжЕЛђКЏЪ§ЃЌдкЕквЛДЮВхШыетЬѕЪ§ОнЕФЪБКђЃЌВЛЛсгУonupdateЕФжЕЃЌжЛЛсЪЙгУdefaultЕФжЕЃЌГЃгУЕФОЭЪЧ"update_time"ЃЈУПДЮИќаТЪ§ОнЕФЪБКђЖМвЊИќаТЕФжЕЃЉ
ЖдartitleЕФtitleНјаааоИФЃЌНјааЙлВь
>>> article = ArticleModel.query.first()
>>> article.title = "456"
>>> db.session.commit()
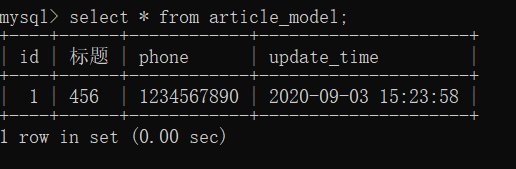
ЯждкПЩвдПДЕНupdate_timeвбОИќаТСЫЁЃ
queryКЏЪ§
-
ФЃаЭЖдЯѓЁЃжИЖЈВщеветИіФЃаЭжаЫљгаЕФЖдЯѓ
-
ФЃаЭжаЕФЪєадЁЃПЩвджИЖЈжЛВщевФГИіФЃаЭЕФЦфжаМИИіЪєад
-
ОлКЯКЏЪ§ ЃК
- db.func.count:ЭГМЦааЕФЪ§СП
- db.func.avg:ЧѓЦНОљжЕ
- db.func.max:ЧѓзюДѓжЕ
- db.func.min:ЧѓзюаЁжЕ
- db.func.sum:ЧѓКЭ
-
'db.func'ЩЯЃЌЦфЪЕУЛгаШЮКЮОлКЯКЏЪ§ЃЌЕЋЪЧвђЮЊЕзВузіСЫвЛаЉФЇЪѕЃЌжЛвЊmysqlжагаОлКЯКЏЪ§ЃЌЖМПЩвдЭЈЙ§db.funcЕїгУ
ДДНЈФЃаЭ
class ArticleModel(db.Model):id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),name="БъЬт",nullable=False)update_time = db.Column(db.DateTime, onupdate=datetime.now, default=datetime.now)price = db.Column(db.Float,nullable=False)# ГѕЪМЛЏdef __init__(self, title,price):self.price = priceself.title = title
ЬэМгЪ§Он
def add():for x in range(6):article = ArticleModel(title='title{}'.format(x),price=random.randint(50,100))db.session.add(article)db.session.commit()
ЭЈЙ§НЛЛЅЪН Python shell ДДНЈБэКЭЪ§ОнПт:
>>> from app import *
>>> add()
ЕїгУfunc
# ОлКЯКЏЪ§
count = db.session.query(db.func.count(Article.id)).first()
print(count)avg = db.session.query(db.func.avg(Article.price)).first()
print(avg)max = db.session.query(db.func.max(Article.price)).first()
print(max)min = db.session.query(db.func.min(Article.price)).first()
print(min)sum = db.session.query(db.func.sum(Article.price)).first()
print(sum)print(db.func.sum(Article.title))
>>> from app import *
>>> func()

filterЗНЗЈГЃгУЙ§ТЫЬѕМў
Й§ТЫЪЧЪ§ОнПтЕФвЛИіКмживЊЕФЙІФмЃЌвдЯТЖдвЛаЉГЃгУЕФЙ§ТЫЬѕМўНјааНтЪЭЃЌВЂЧветаЉЙ§ТЫЬѕМўЖМЪЧжЛФмЭЈЙ§filterЗНЗЈЪЕЯжЕФЁЃ
ШчЙћЯыПДЕзВуsqlдЩњгяОфЃЌдкгяОфФЉЮВВЛМгall()ЃЌОЭПЩвдДђгЁГідЩњsqlгяОфЁЃ
ЖЈвхвЛИіФЃаЭ
class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)price = db.Column(db.Float,nullable=False)content = db.Column(db.Text)def __repr__(self):return "<Article(title:%s)>" % self.title
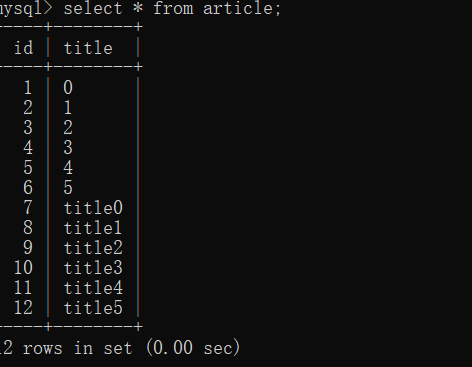
НЛЛЅshellЩњГЩВтЪдЪ§ОнЃК
>>> for x in range(6):...: article = Article(title='{}'.format(x))...: db.session.add(article)...: db.session.commit()...: ...: for x in range(6):...: article = Article(title='title{}'.format(x))...: db.session.add(article)...: db.session.commit()
- equalsЃЈЕШгкЃЉ
>>> article = Article.query.filter(Article.id == 1).first()
>>> article
<Article(title:0)>
- not equalsЃЈВЛЕШгкЃЉ
>>> article = Article.query.filter(Article.title != 'title0').all()
>>> article.__str__()
[<Article(title:0)>,<Article(title:1)>,<Article(title:2)>,<Article(title:3)>,<Article(title:4)>,<Article(title:5)>,<Article(title:title1)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]
- like & ilike(ВЛЧјЗжДѓаЁаД)
>>> articles = Article.query.filter(Article.title.like('%title%')).all()
# ВЛЗжЧјДѓаЁаД
>>> articles
[<Article(title:title0)>,<Article(title:title1)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]>>> articles = Article.query.filter(Article.title.ilike('%title%')).all()
>>> articles
[<Article(title:title0)>,<Article(title:title1)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]
- inЃЈКЌгаЃЉ
>>> articles = Article.query.filter(Article.title.in_(['title1','title2'])).all()
>>> articles
[<Article(title:title1)>, <Article(title:title2)>]
- not inЃЈВЛКЌгаЃЉ
>>> articles = Article.query.filter(~Article.title.in_(['title1'])).all()
>>> articles
[<Article(title:0)>,<Article(title:1)>,<Article(title:2)>,<Article(title:3)>,<Article(title:4)>,<Article(title:5)>,<Article(title:title0)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]
>>> articles = Article.query.filter(Article.title.notin_(['title1'])).all()
>>> articles
[<Article(title:0)>,<Article(title:1)>,<Article(title:2)>,<Article(title:3)>,<Article(title:4)>,<Article(title:5)>,<Article(title:title0)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]
- is null
>>> Article.query.filter(Article.title == None).all()
[]
- is not null
>>> Article.query.filter(Article.title != None).all()
[<Article(title:0)>,<Article(title:1)>,<Article(title:2)>,<Article(title:3)>,<Article(title:4)>,<Article(title:5)>,<Article(title:title0)>,<Article(title:title1)>,<Article(title:title2)>,<Article(title:title3)>,<Article(title:title4)>,<Article(title:title5)>]
- or
>>> articles = Article.query.filter(db.or_(Article.title=='title0',Article.id=='1')).all()
>>> articles
Out[34]: [<Article(title:0)>, <Article(title:title0)>]
- and
>>> from sqlalchemy import or_,and_
>>> articles = Article.query.filter(Article.title=='0' and Article.id == 'id').all()
>>> articles
[<Article(title:0)>]>>> articles = Article.query.filter(and_(Article.title=='0',Article.id == '1')).all()
>>> articles
[<Article(title:0)>]
зЂвтдкЪЙгУorКЭandЕФЪБКђЃЌашвЊЬэМг
from sqlalchemy import or_,and_ЛђепЪЙгУdb.or_ЁЂdb.and_
filter_byЗНЗЈГЃгУЙ§ТЫЬѕМў
filter_byгыfilterЧјБ№ЃЌfilterашвЊЪЙгУРрУћ.СаУћЃЌfilter_byжЛашвЊЪЙгУСаУћМДПЩ
ЭтМќМАЦфЫФжждМЪјНВНт
дкMySQLжаЃЌЭтМќПЩвдШУБэжЎМфЕФЙиЯЕИќМгНєУмЃЌЖјSQLAlchemyЭЌбљжЇГжЭтМќЁЃЭЈЙ§FpreignKeyРрРДЪЕЯжЃЌВЂЧвПЩвджИЖЈБэЕФЭтМќдМЪјЁЃ
ЭтМќдМЪјгавдЯТМИЯю:
- RESTRICT(restrict):ИИБэЪ§ОнБЛЩОГ§ЃЌЛсзшжЙЩОГ§
- NO ACTION:дкMySQLжаЃЌЭЌRESTRICT
- CASCADE:МЖСЊЩОГ§
- SET NULL:ИИРрЪ§ОнБЛЩОГ§ЃЌзгБэЪ§ОнЩшжУЮЊNULL
ЯрЙиЪОР§ДњТыШчЯТ:
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50))class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)content = db.Column(db.Text,nullable=False)# ЭтМќЃЌУЛгажИЖЈЃЌОЭФЌШЯЮЊRESTRICT# RESTRICT:зшжЙЩОГ§Ъ§Он# uid = Column(Integer,ForeignKey("user.id",ondelete="RESTRICT"))# МЖСЊЩОГ§# uid = Column(Integer, ForeignKey("user.id", ondelete="CASCADE"))# жЛгаИИБэБЛЩОГ§ЃЌзгБэаоИФЮЊNULLuid = db.Column(db.Integer, db.ForeignKey("user.id", ondelete="SET NULL"))
ORMВуЭтМќ
mysqlМЖБ№ЕФЭтМќЃЌЛЙВЛЙЛORMЃЌБиаыФУЕНвЛИіБэжаЕФЭтМќЃЌШЛКѓдйШЅЭЈЙ§етИіЭтМќдйШЅСэЭтвЛеХБэВщевЁЃПЩетбљЬЋТщЗГСЫЁЃSQLAlchemyЬсЙЉСЫвЛИі"relationship"ЃЌетИіРрПЩвдЖЈвхЪєадЃЌвдКѓдйЗУЮЪЯрЙиСЊЕФБэЕФЪБКђОЭПЩвджБНгЭЈЙ§ЪєадЗУЮЪЕФЗНЪНОЭПЩвдЗУЮЪЕУЕНСЫЁЃ
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50))articles = db.relationship('Article')class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)content = db.Column(db.Text,nullable=False)uid = db.Column(db.Integer, db.ForeignKey("user.id", ondelete="SET NULL"))# гГЩфЕНUserФЃаЭauthor = db.relationship("User")def __repr__(self):return "<Article(title:%s),content:%s>" % (self.title,self.content)
вЛЖдвЛЙиЯЕ
ЯывЊвЛЖдвЛЙиЯЕЃЌПЩвдАб uselist=False ДЋИј relationship() ЁЃ
ШчЯТ:
class User(db.Model):....articles = db.relationship('Article',uselist=False)class Article(db.Model):....author = db.relationship("User",uselist=False)....
СэЭтЃЌПЩвдЭЈЙ§backrefРДжИЖЈЗДЯђЗУЮЪЕФЪєадУћГЦЁЃ
ШчЯТЃК
class User(db.Model):....articles = db.relationship('Article',backref=db.backref("author",uselist=False))ЬэМгЪ§Он
def add():user = User(username="demo1")db.session.add(user)db.session.commit()user = User.query.first()article = Article(title="title1",content="123",uid=user.id)db.session.add(article)db.session.commit()db.drop_all()
db.create_all()
# ДДНЈЪ§Он
add()
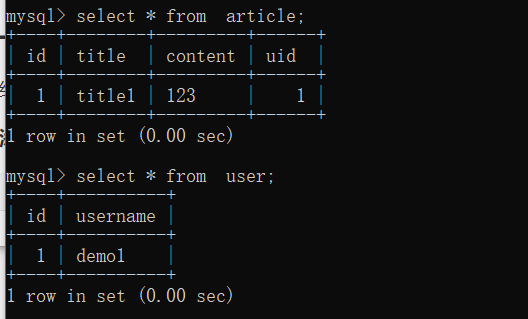
вЛЖдЖрЙиЯЕ
МЬајВЩгУгУЛЇ(user)гыЮФеТ(article)ЃЌЙиЯЕЮЊвЛИігУЛЇгЕгаЖрЦЊЮФеТЁЃШчЯТЃК
ЭЈЙ§backrefРДжИЖЈЗДЯђЗУЮЪЕФЪєадУћГЦЁЃ
class User(db.Model):....articles = db.relationship('Article',backref=db.backref("author"))class Article(db.Model):....
ЬэМгЪ§Он
def add():user = User(username="demo1")db.session.add(user)db.session.commit()user = User.query.first()for i in range(6):article = Article(title="title{}".format(i),content="{}".format(i),uid=user.id)db.session.add(article)db.session.commit()
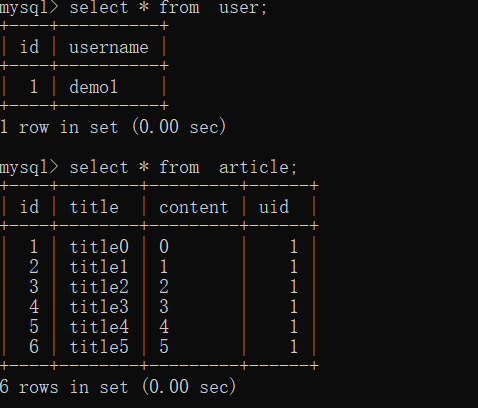
ВщбЏ
>>> user = User.query.first()
>>> user.articles
[<Article(title:title0),content:0>,<Article(title:title1),content:1>,<Article(title:title2),content:2>,<Article(title:title3),content:3>,<Article(title:title4),content:4>,<Article(title:title5),content:5>]>>> article = Article.query.first()
>>> article.author
<User 1>>>> article.author.articles[<Article(title:title0),content:0>,<Article(title:title1),content:1>,<Article(title:title2),content:2>,<Article(title:title3),content:3>,<Article(title:title4),content:4>,<Article(title:title5),content:5>]ЭЈЙ§user.articlesетбљНјааЕїгУЪєадЃЌОЭФмЙЛЗНБуЕФЛёШЁЯрЙиБэЕФЪ§ОнЁЃ
ЖрЖдЖрЙиЯЕ
ЯывЊгУЖрЖдЖрЙиЯЕЃЌашвЊЖЈвхвЛИігУгкЙиЯЕЕФИЈжњБэЁЃЖдгкетИіИЈжњБэЃЌ ЧПСвНЈвщВЛЪЙгУФЃаЭЃЌЖјЪЧВЩгУвЛИіЪЕМЪЕФБэ:
? ШчЯТЮЪЬтЃЌМЬајВЩгУгУЛЇ(user)гыЮФеТ(article)ЃЌЙиЯЕЮЊвЛИігУЛЇгЕгаЖрЦЊЮФеТЃЌвЛЦЊЮФеТгавЛИівдЩЯгУЛЇЁЃМДЃК
user_article = db.Table('user_article',db.Column('user_id', db.Integer, db.ForeignKey('user.id')),db.Column('article_id', db.Integer, db.ForeignKey('article.id'))
)class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50))articles = db.relationship('Article',secondary=user_article,backref=db.backref("authors"))class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)content = db.Column(db.Text,nullable=False)def __repr__(self):return "<Article(title:%s),content:%s>" % (self.title,self.content)
дкrelationshipКЏЪ§жаЬэМгsecondary=user_articleЃЌМДПЩЁЃЦфжаuser_articleЮЊжаМфБэЁЃ
ВЛашвЊЩшжУЭтМќСЫ
ЬэМгЪ§Он
>>> from app import *
>>> db.drop_all()
>>> db.create_all()>>> user1 = User(username="user1")
>>> user2 = User(username="user2")
>>>
>>> article1 = Article(title="title{}".format(1),content="{}".format(1))
>>> article2 = Article(title="title{}".format(2),content="{}".format(2))
>>> article3 = Article(title="title{}".format(3),content="{}".format(3))
>>>
>>> article1.authors.append(user1) # article1ЖдгІuser1,user2СНИігУЛЇ
>>> article1.authors.append(user2)
>>>
>>> article2.authors.append(user1) # article2ЖдгІuser1вЛИігУЛЇ
>>>
>>> user2.articles.append(article3) # article3ЖдгІuser2вЛИігУЛЇ
>>>
>>> db.session.add_all([user1,user2,article1, article2,article3])
>>> db.session.commit()
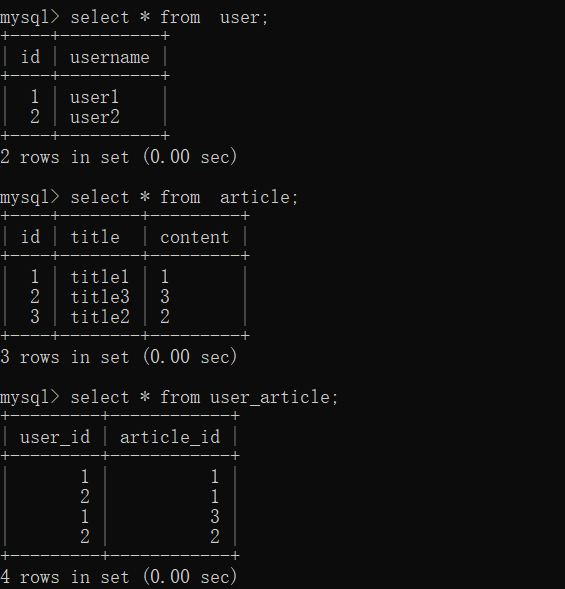
ВщбЏ
>>> user1.articles
[<Article(title:title1),content:1>, <Article(title:title2),content:2>]>>> article1.authors
[<User 1>, <User 2>]
ORMВуУцЩОГ§Ъ§ОнзЂвтЪТЯю
ORMВуУцЩОГ§Ъ§ОнЃЌЛсЮоЪгmysqlМЖБ№ЕФЭтМќдМЪјЃЌжБНгЛсЖдНЋЖдгІЕФЪ§ОнЩОГ§ЃЌШЛКѓНЋДгБэжаЕФФЧИіЭтМќЩшжУЮЊNULL,ШчЙћЯывЊБмУтетжжааЮЊЃЌгІИУНЋДгБэжаЕФЭтМќЕФ"nullable=False"ЁЃ
relationshipЗНЗЈжаЕФcascadeВЮЪ§ЯъНт
ШчЙћНЋЪ§ОнПтЕУЕНЭтМќЩшжУЮЊRESTRICTЃЌФЧУДдкORMВуУцЃЌЩОГ§СЫИИБэжаЕФЪ§ОнЃЌФЧУДДгБэжаЕФЪ§ОнНЋЛсNULLЁЃШчЙћВЛЯывЊетжжЧщПіЗЂЩњЃЌФЧУДгІИУНЋетИіжЕЕФnullable=FalseЁЃ
дкSQLAlchemyЃЌжЛвЊНЋвЛИіЪ§ОнЬэМгЕНsessionжаЃЌКЭЫќЯрЙиСЊЕФЪ§ОнЖМПЩвдвЛЦ№ДцШыЕНЪ§ОнПтжаСЫЁЃетаЉЪЧдѕУДЩшжУЕФФи?ЦфЪЕЪЧЭЈЙ§relationshipЕФЪБКђ ЃЌгавЛИіЙиМќзжВЮЪ§cascadeПЩвдЩшжУетаЉЪєад:
- save-update:ФЌШЯбЁЯюЁЃдкЬэМгвЛЬѕЪ§ОнЕФЪБКђЃЌЛсАбЦфЫћКЭЫќЯрЙиСЊЕФЪ§ОнЖМЬэМгЕНЪ§ОнПтжаЁЃетжжааЮЊОЭЪЧsave-updateЪєадгАЯьЕФЁЃ
- delete:БэЪОЕБЩОГ§ФГвЛИіФЃаЭжаЕФЪ§ОнЕФЪБКђЃЌЪЧЗёвВЩОГ§ЕєЪЙгУrelationshipКЭЫќЙиСЊЕФЪ§ОнЁЃ
- delete-orphan:БэЪОЕБЖдвЛИіORMЖдЯѓНтГ§СЫИИБэжаЕФЙиСЊЖдЯѓЕФЪБКђЃЌздМКБуЛсБЛЩОГ§ЕєЁЃЕБШЛШчЙћБэжаЕФЪ§ОнБЛЩОГ§ЃЌздМКвВЛсБЛЩОГ§ЁЃетИібЁЯюжЛФмгУдквЛЖдЖрЩЯЃЌВЛФмгУдкЖрЖдЖрвдМАЖрЖдвЛЩЯЁЃВЂЧвЛЙашвЊдкзгФЃаЭжаЕФrelationshipжаЃЌдіМгвЛИіsingle_parent=TrueЕФВЮЪ§ЁЃ
- merge:ФЌШЯбЁЯюЁЃЕБдкЪЙгУsession.mergeЃЌКЯВЂвЛИіЖдЯѓЕФЪБКђЃЌЛсНЋЪЙгУСЫrelationshipЯрЙиСЊЕФЖдЯѓвВНјааmergeВйзї
- expunge:вЦГ§ВйзїЕФЪБКђЃЌЛсНЋЯрЙиСЊЕФЖдЯѓвВНјаавЦГ§ЁЃетИіВйзїжЛЪЧДгsessionжавЦГ§ЃЌВЂВЛЛсеце§ЕФДгЪ§ОнПтжаЩОГ§ЁЃ
- all:ЪЧЖдsave-updateЃЌmergeЃЌrefresh-expireЃЌexpungeЃЌdeleteМИжжЕФЬюаД
Р§ШчЃК
1. author = db.relationship("User", backref="articles", cascade="save-update,delete")2. author = db.relationship("User", backref=db.backref("articles",cascade="save-update,delete"),cascade="save-update,delete")
Ш§жжХХађЗНЪНЯъНт
ДДНЈФЃаЭРр
class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)content = db.Column(db.Text,nullable=False)def __repr__(self):return "<Article(title:%s),content:%s>" % (self.title,self.content)
ЬэМгЪ§Он
>>> article1 = Article(title="title{}".format(1),content="{}".format(1))
>>> article2 = Article(title="title{}".format(2),content="{}".format(2))
>>> article3 = Article(title="title{}".format(3),content="{}".format(3))>>>
>>> db.session.add_all([article1, article2,article3])
>>> db.session.commit()
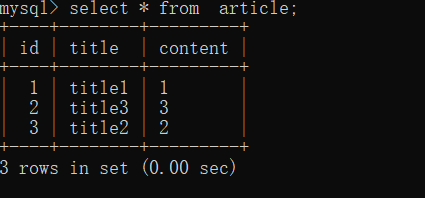
ЕїгУorder_by
- order_byЃКПЩвджИЖЈИљОнетИіБэжаЕФФГИізжЖЮНјааХХађЃЌШчЙћдкКѓУцЬэМгdesc()ЃЌОЭФмЙЛЕїгУdesc()ЗНЗЈНјааНЕађЁЃЖјЩ§ађЃЌsqlalchemyЪЧФЌШЯЮЊЩ§ађЕФЃЌЛђепЕїгУasc()ЗНЗЈЁЃ
>>> Article.query.order_by(Article.title.desc()).all()
[<Article(title:title3),content:3>,<Article(title:title2),content:2>,<Article(title:title1),content:1>]
ФЃаЭЖЈвхЪБжИЖЈФЌШЯХХађ
дкФЃаЭЖЈвхЕФЪБКђжИЖЈФЌШЯХХађ:гааЉЪБКђЃЌВЛЯыУПДЮдкВщбЏЕФЪБКђЖМжИЖЈХХађЕФЗНЪНЃЌПЩвддкЖЈвхФЃаЭЕФЪБКђОЭжИЖЈХХађЕФЗНЪНЁЃ
гавдЯТСНжжЗНЪН:
- relationshipЕФorder_byВЮЪ§:дкжИЖЈrelationshipЕФЪБКђЃЌДЋЕнorder_byВЮЪ§РДжИЖЈХХађЕФзжЖЮ
class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)content = db.Column(db.Text,nullable=False)# ХХађauthor = db.relationship("User",backref=db.backref("articles",order_by=create_time.desc()))
-
дкФЃаЭЖЈвхжаЃЌЬэМгвдЯТДњТы:
__mapper_args__ = { 'order_by':title, }
class Article(db.Model):....__mapper_args__ = {"order_by":create_time.desc(),}
МДПЩШУЮФеТгУБъЬтРДНјааХХађ
limitЁЂoffsetвдМАЧаЦЌВйзї
ЬэМгЪ§Он
>>> db.drop_all()
>>> db.create_all()
>>> for i in range(1000):article = Article(title="title{}".format(i))db.session.add(article)
>>> db.session.commit()
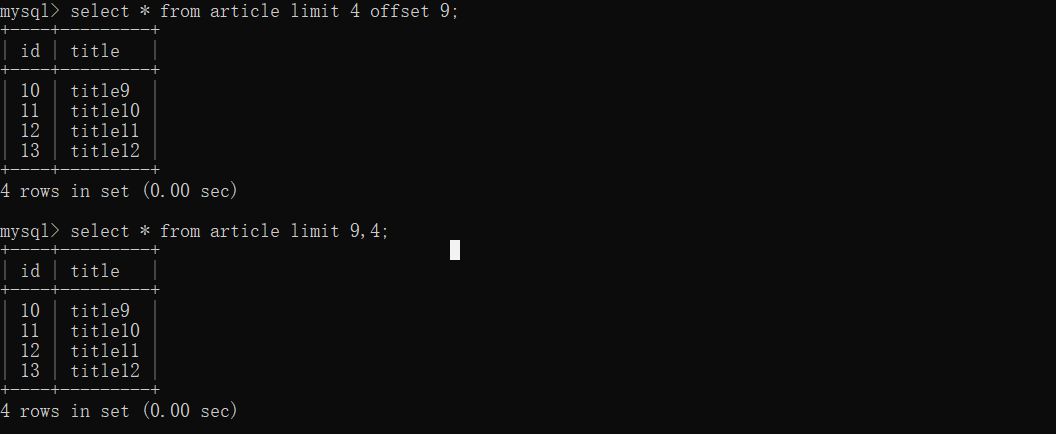
select * from article limit 4 offset 9
or
select * from article limit 9,4
КЌвхЮЊЗЕЛиДгЕк9ааЦ№ЃЌКѓУц4ааЪ§ОнЃЌАќРЈЕк9ааЁЃ
-
limit:ПЩвдЯожЦУПДЮВщбЏЕФЪБКђжЛВщбЏМИЬѕЪ§ОнЁЃ
-
offset:ПЩвдЯожЦВщевЪ§ОнЕФЪБКђЙ§РДЧАУцЖрЩйЬѕЁЃ
>>> articles = Article.query.offset(9).limit(4).all()
>>> for article in articles:
>>> print(article.title)title9
title10
title11
title12
- ЧаЦЌ:ПЩвдQueryЖдЯѓЪЙгУЧаЦЌВйзїЃЌРДЛёШЁЯывЊЕФЪ§Он
>>> articles = Article.query.all()[9:9+4]
>>> for article in articles:
>>> print(article.title) title9
title10
title11
title12
Ъ§ОнВщбЏМгдиММЪѕ
lazy ОіЖЈСЫ SQLAlchemy ЪВУДЪБКђДгЪ§ОнПтжаМгдиЪ§ОнЁЃ
'select'(ФЌШЯжЕ) ОЭЪЧЫЕ SQLAlchemy ЛсЪЙгУвЛИіБъзМЕФ select гяОфБивЊЪБвЛДЮМгдиЪ§ОнЁЃ'joined'ИцЫп SQLAlchemy ЪЙгУJOINгяОфзїЮЊИИМЖдкЭЌвЛВщбЏжаРДМгдиЙиЯЕЁЃ'subquery'РрЫЦ'joined'ЃЌЕЋЪЧ SQLAlchemy ЛсЪЙгУзгВщбЏЁЃ'dynamic'дкгаЖрЬѕЪ§ОнЕФЪБКђЪЧЬиБ№гагУЕФЁЃВЛЪЧжБНгМгдиетаЉЪ§ОнЃЌSQLAlchemy ЛсЗЕЛивЛИіВщбЏЖдЯѓЃЌдкМгдиЪ§ОнЧАФњПЩвдЙ§ТЫЃЈЬсШЁЃЉЫќУЧЁЃ
ШчЯТЃК
author = db.relationship("User",backref=db.backref('articles',lazy="dynamic"))
group_byКЭhavingзгОф
ДДНЈФЃаЭ
class User(db.Model):__tablename__ = "user"id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50),nullable=False)age = db.Column(db.Integer,default=0)gender = db.Column(db.Enum("male","female","secret"))
ЬэМгЪ§Он
user1 = User(username="angle",age=17,gender="male")
user2 = User(username="miku",age=18,gender="male")
user3 = User(username="xue",age=18,gender="female")
user4 = User(username="yue",age=19,gender="female")
user5 = User(username="mi",age=20,gender="female")db.session.add_all([user1,user2,user3,user4,user5])
db.session.commit()
- group_by
ИљОнФГИізжЖЮНјааЗжзщ
ЪОР§
ЭГМЦУПИіФъСфЖЮЕФШЫЪ§ЃЌsqlгяОфЮЊЃК
select count(*) from user group by age;
ЪЕЯжЃК
>>> result = db.session.query(User.age,db.func.count(User.id)).group_by(User.age).all()
>>> result
[(17, 1), (18, 2), (19, 1), (20, 1)]- having
havingЪЧЖдВщевНсЙћНјвЛВНЙ§ТЫЃЌдкЗжзщЕФЛљДЁЩЯдкНјааЩИбЁЙ§ТЫ
ЪОР§
ЭГМЦУПИіФъСфЖЮЕФШЫЪ§ЃЌВЂЩИбЁГіФъСфаЁгк18ЕФЃЌsqlгяОфЮЊЃК
select count(*) from user group by age where age < 18;
ЪЕЯжЃК
>>> result = db.session.query(User.age,db.func.count(User.id)).group_by(User.age).having(User.age < 18).all()
>>> result
[(17, 1)]
ИДдгВщбЏ
ДДНЈФЃаЭРр
class User(db.Model):__tablename__ = "user"id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50),nullable=False)def __repr__(self):return "<User(id:%s,username:%s)>" % (self.id,self.username)class Article(db.Model):__tablename__ = 'article'id = db.Column(db.Integer,primary_key=True,autoincrement=True)title = db.Column(db.String(50),nullable=False)create_time = db.Column(db.DateTime,nullable=False,default=datetime.now)uid = db.Column(db.Integer,db.ForeignKey("user.id"))author = db.relationship("User",backref=db.backref("articles"))def __repr__(self):return "<Article(title:%s)>" % self.title
ЬэМгЪ§Он
db.drop_all()
db.create_all()user1 = User(username="angle")
user2 = User(username="miku")for i in range(1):article = Article(title="title1 %s" % i)article.author = user1db.session.add(article)
db.session.commit()for i in range(1,3):article = Article(title="title1 %s" % i)article.author = user2db.session.add(article)
db.session.commit()
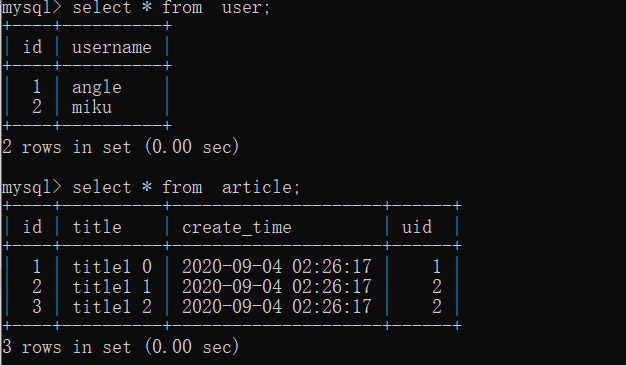
joinЪЕЯжИДдгВщбЏ
joinВщбЏЗжЮЊСНжжЃЌ
- inner join
- left join
- right join
- outer joinЁЃ
ШчЙћЯывЊВщбЏUserМАЦфЖдгІЕФAddressЃЌдђПЩвдЭЈЙ§вдЯТЗНЪНРДЪЕЯж:
for u,a in db.session.query(User,Address).filter(User.id == Address.user.id).all()print(u)print(a)
tips:joinЗНЗЈХфКЯfilterЙ§ТЫЗНЗЈвЛЦ№ЪЙгУ
- left join
sqlгяОфЃК
select user.id,user.username from user
inner join article on user.id = article.uid
group by user.id
order by count(article.id) desc;
ЪЕЯжЃК
>>> result = db.session.query(User).join(Article).group_by(User.id).order_by(db.func.count(Article.id).desc()).all()
>>> result
[<User(id:2,username:miku)>, <User(id:1,username:angle)>]
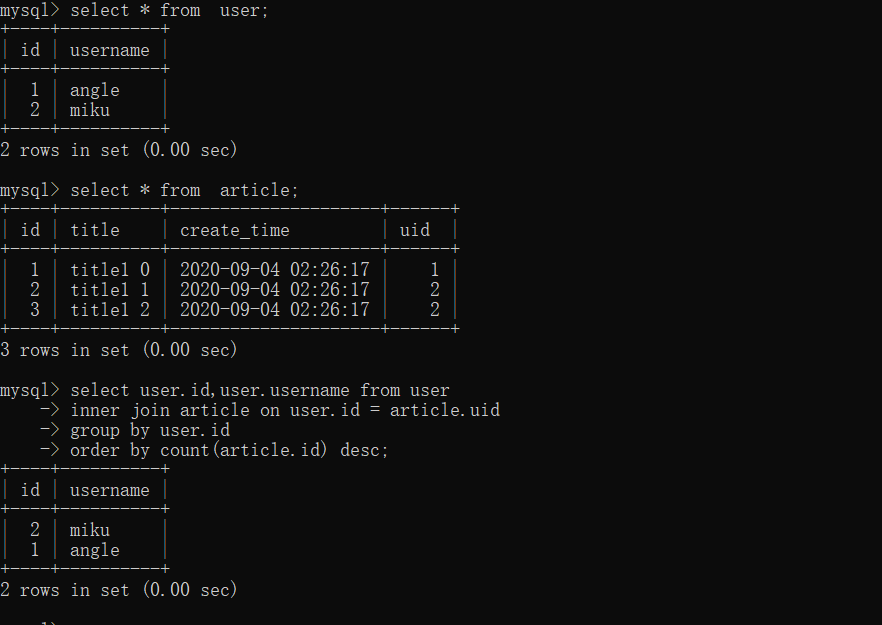
- right join
sqlгяОфЃК
select article.id,article.title,article.create_time,article.uid from article
inner join user on user.id = article.uid
group by user.id
order by count(article.id) desc;
ЪЕЯжЃК
>>> result = db.session.query(Article).join(User).group_by(User.id).order_by(db.func.count(Article.id).desc()).all()
>>> result
[<Article(title:title1 1)>, <Article(title:title1 0)>]
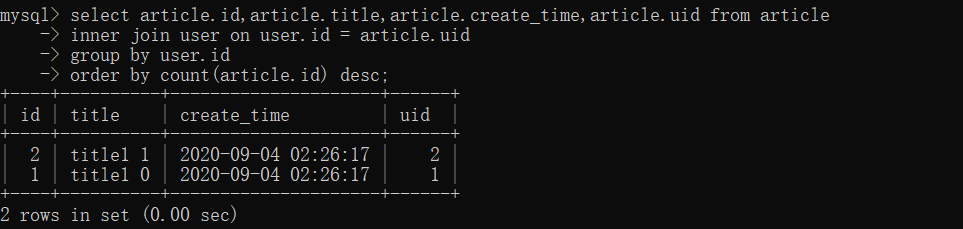
- outer join
sqlгяОфЃК
select article.id ,article.title,article.create_time,article.uid from article
left outer join user on user.id = article.uid
group by user.id
order by count(article.id) desc;
ЪЕЯжЃК
>>> result = db.session.query(Article).outerjoin(User).group_by(User.id).order_by(db.func.count(Article.id).desc()).all()
>>> result
[<Article(title:title1 1)>, <Article(title:title1 0)>]
subqueryЪЕЯжИДдгВщбЏ
ФЃаЭРр
class User(db.Model):__tablename__ = "user"id = db.Column(db.Integer,primary_key=True,autoincrement=True)username = db.Column(db.String(50),nullable=False)city = db.Column(db.String(50),nullable=False)age = db.Column(db.Integer,default=0)def __repr__(self):return "<User(username:%s)>" % self.username
ЬэМгЪ§Он
>>> user1 = User(username="A",city="MГЧ",age=15)
>>> user2 = User(username="B",city="GГЧ",age=21)
>>> user3 = User(username="C",city="HГЧ",age=12)
>>> user4 = User(username="D",city="JГЧ",age=20)>>> db.session.add_all([user1,user2,user3,user4])
>>> db.session.commit()
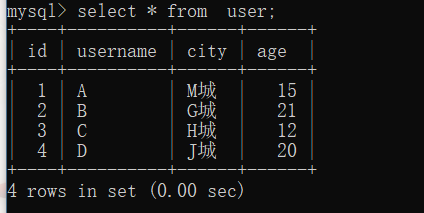
згВщбЏПЩвдШУЖрИіВщбЏБфГЩвЛИіВщбЏЃЌжЛвЊВщеввЛДЮЪ§ОнПтЃЌадФмЯрЖдРДНВИќМгИпаЇвЛЕуЃЌВЛгУаДЖрИіsqlгяОфОЭПЩвдвЛаЉИДдгЕФВщбЏСЫЃЌФЧУДдкsqlalchemyжаЃЌвЊЪЕЯжвЛИізгВщбЏЃЌгІИУЪЙгУвдЯТМИИіВНжш:
1.НЋзгВщбЏАДееДЋЭГЕФЗНЪНаДКУВщбЏДњТыЃЌШЛКѓдк"query"ЖдЯѓКѓУцжДаа"subquery"ЗНЗЈЃЌНЋетИіВщбЏБфГЩвЛИізгВщбЏЁЃ
user = db.session.query(db.func.max(User.age).label("age")).subquery()
2.дкзгВщбЏжаЃЌНЋвдКѓашвЊгУЕНЕФзжЖЮЭЈЙ§"label"ЗНЗЈЃЌШЁИіБ№Ућ
db.session.query(db.func.max(User.age).label("age"))
3.дкИИВщбЏжаЃЌШчЙћЯывЊЪЙгУзгВщбЏЕФзжЖЮЃЌФЧУДПЩвдЭЈЙ§згВщбЏЕФБфСПЩЯЕФ"c"ЪєадФУЕН
db.session.query(User).filter(User.age == user.c.age).all()
ЪЙгУБ№УћЃЈaliasedЃЉ
SQLAlchemy ЪЙгУ aliased() ЗНЗЈБэЪОБ№УћЃЌЕБашвЊАбЭЌвЛеХБэСЌНгЖрДЮЕФЪБКђЃЌГЃГЃашвЊгУЕНБ№УћЁЃ
# Аб Address БэЗжБ№ЩшжУБ№Ућ
Article1 = aliased(Article)
Article2 = aliased(Article)
text - жБНгаДsql
- дкtextРяаДsqlгяОфЃЌВЂдк
filterКЭorder_byжаЪЙгУ
>>> db.session.query(User).filter(db.text("age<16"))\.order_by(db.text("age")).all()
[<User(username:C)>, <User(username:A)>]
- textРяПЩвдгУ
:nameДЋЖЏЬЌВЮЪ§ЃЌВЂparamsДЋжЕ
>>> db.session.query(User).filter(db.text("age<:value and username=:name")). \...: params(value=16, name='A').order_by(User.id).one()
<User(username:A)>
- textРявВПЩвдИјЭъећЕФsqlгяОф,ШЛКѓДЋИј
from_statement
>>> db.session.query(User).from_statement(db.text("select * from user where username=:name and age<:age")).params(name='A',age=16).all()
[<User(username:A)>]
- ШчЙћгУfrom_statementжаВЛЪЧИјЕФЫљгазжЖЮЃЌФЧПЩгУ columns НЋжЕИГИјзжЖЮ
>>> stmt = db.text("select id,username FROM user where username=:name")
>>> stmt = stmt.columns(User.username, User.id)
>>> db.session.query(User).from_statement(stmt).params(name='A').all()
[<User(username:A)>]
Flask-Script
Flask-ScriptЕФзїгУЪЧПЩвдЭЈЙ§УќСюааЕФаЮЪНРДВйзїFlaskЁЃ
АВзА
pip install flask-script
Ш§жжДДНЈУќСю:ЪЙгУ@commandаоЪЮЗћЁЂЪЙгУ@optionаоЪЮЗћЁЂДДНЈcommandзгРр
@commandаоЪЮЗћ
from flask_script import Manager
from app import app,db# ЪЙгУManagerДДНЈвЛИіЖдЯѓ
manager = Manager(app)@manager.command
def greet():print("ФуКУ")if __name__ == '__main__':manager.run()
дЫааЃК
python manage.py greet

@optionаоЪЮЗћ
ЬэМгВЮЪ§
from flask_script import Manager
from myapp import app,BackendUser,db
from db_script import db_manager# ЪЙгУManagerДДНЈвЛИіЖдЯѓ
manager = Manager(app)@manager.option("-u","--username",dest="username")
@manager.option("-a","--age",dest="age")
def add_user1(username,age):print("гУЛЇУћ:{},ФъСф:{}".format(username,age))@manager.option("-u","--username",dest="username")
@manager.option("-e","--email",dest="email")
def add_user2(username,email):user = BackendUser(username=username,email=email)db.session.add(user)db.session.commit()if __name__ == '__main__':manager.run()
дЫааЃК
python manage.py add_user1 -u angle -a 18
python manage.py add_user2 -u angle -e 18@qq.com

commandзгРр
from flask_script import Manager ЃЌServer
from flask_script import Command
from debug import app manager = Manager(app) class Hello(Command):def run(self):print('ВтЪд')#здЖЈвхУќСювЛ/НЋРрHello()гГЩфЮЊhello
manager.add_command('hello', Hello())#здЖЈвхУќСюЖў/ЦєЖЏУќСю
manager.add_command("runserver", Server()) #УќСюЪЧrunserver
if __name__ == '__main__':manager.run()
дЫааЃК
python manage.py hello

згРр
db_script.py
from flask_script import Managerdb_manager = Manager()@db_manager.command
def init():print('ЧЈвЦВжПтДДНЈЭъБЯ')@db_manager.command
def revision():print("ЧЈвЦНХБОЩњГЩГЩЙІ")@db_manager.command
def upgrade():print("НХБОгГЩфЕНЪ§ОнПтГЩЙІ")
manage.py
from flask_script import Manager
from app import app
from db_script import db_manager# ЪЙгУManagerДДНЈвЛИіЖдЯѓ
manager = Manager(app)# ЬэМгзгУќСю
# python manage.py db init
manager.add_command("db",db_manager)if __name__ == '__main__':manager.run()
дЫааЃК
python manage.py db init

tips:жДааdb_script.pyЯТЕФinitКЏЪ§
add_command()ЬэМгзгРрЃЌНЋdb_managerгГЩфЮЊdb
ЯюФПНсЙЙжиЙЙ
ЮЊЪВУДНјааЯюФПжиЙЙЃП
вђЮЊflaskЯюФПжаЃЌгааЉБфСПЛђепЖдЯѓЛсБЛЕїгУдкЖрИіЮФМўжаЃЌПЩФмдкЕїгУЪБаЮГЩвЛИіЫРбЛЗЁЃвђДЫЃЌзЈУХНЋвЛаЉОГЃЪЙгУЕФЖдЯѓЃЌЗХдквЛИіЮФМўжаЃЌвдБуЕїгУЁЃ
exts.py
from flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()
НЋвЛаЉХфжУаХЯЂзЈУХЗХдквЛИіХфжУЮФМўжаЁЃ
config.py
HOSTNAME = "127.0.0.1"
PORT = "3306"
DATABASE = "test"
USERNAME = "root"
PASSWORD = "123456"
DB_URI = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)SQLALCHEMY_DATABASE_URI = DB_URI
SQLALCHEMY_TRACK_MODIFICATIONS = False
app.py
from flask import Flask
from exts import db
import configapp = Flask(__name__)# ДгХфжУЮФМўЛёШЁХфжУВЮЪ§
app.config.from_object(config)# РСМгдиНјааГѕЪМЛЏapp
db.init_app(app)
Flask-Migrate
Flask-MigrateЪЧвЛИіЮЊFlaskгІгУДІРэSQLAlchemyЪ§ОнПтЧЈвЦЕФРЉеЙЃЌЪЙЕУПЩвдЭЈЙ§FlaskЕФУќСюааНгПкЛђепFlask-ScriptsЖдЪ§ОнПтНјааВйзїЁЃ
АВзАУќСю
pip install flask-migrate
ХфжУflask-migrate
manage.py
from flask_script import Manager
from app import app
from flask_migrate import Migrate,MigrateCommand
from exts import dbmanager = Manager(app)# гУРДАѓЖЈappКЭflask_migrateЕФ
Migrate(app,db)# ЬэМгMigrateЕФЫљгазгУќСюЕНdbЯТ
manager.add_command("db",MigrateCommand)if __name__ == '__main__':manager.run()
ЪЙгУinitУќСюДДНЈЧЈвЦВжПт
python manage.py db init
ЪЙгУmigrateУќСюНЋФЃаЭгГЩфЕНЮФМўжа
python manage.py db migrate
# python manage.py db migrate -m "initial migratetion"
ЪЙгУupgradeУќСюНЋЮФМўЪ§ОнгГЩфЕНЪ§ОнПтжа
python manage.py db upgrade
ЪЙгУdowngradeУќСюЛиЙіЧЈвЦжаЕФЪ§ОнПтИФЖЏ
python manage.py db downgrade version(ЩЯвЛИіАцБОЕФАцБОКХ)
ИќЖрУќСю
python manage.py db --help
змВНжш
python manage.py db init
python manage.py db migrate
python manage.py db upgrade# ИФБфзжЖЮКѓжиИД2~3ВНжш# ЛиЙіВйзї
python manage.py db downgrade version
# python manage.py db downgrade 289402d590c2