������
ǰ��
Ĭ���Ѿ���װ��python
��;
| python�� | ˵�� |
|---|---|
| ����ģ�� | ����ģ���û�������ҳ��ȡ���� |
| requests | ����ģ������ |
| selenium | ģ���û����������ȡ���� |
| chromeDriver | selenium��chrome���� |
| GeckoDriver | selenium��firefox���� |
| PhantomJS | selenium��������������� |
| ����ģ�� | ���ڽ�����ҳ���� |
| Beautiful Soup | |
| pyquery | |
| ͼƬʶ�� | |
| tesserocr | ���ڽ�����֤��ͼƬ |
| ���ݿ� | �洢���� |
| MySQL | |
| MongoDB | |
| Redis | |
| ���湤�� | |
| memcached | |
| �洢ģ�� | �������ݿ��python�� |
| PyMySQL | ��������mysql |
| PyMongo | ��������MongoDB |
| redis-py | ��������redis |
| RedisDump | ͼ�λ�redis���� |
| Sqlalchemy | orm����Ϊ����IJ������ݿ� |
| ץ������/ģ������ | ����ץȡapp�Լ���ҳ���� |
| Charles | |
| Wireshark | |
| mitmproxy | |
| Appinum | |
| fillder | |
| postman | ����ģ������ |
| ������ | |
| pyspider | |
| Scrapy | |
| Scrapy-Splash | |
| ScrapyRedis | |
| ����ģ�� | |
| Docker | |
| Scrapyd | |
| ScrapyClient | |
| ScrapydAPI | |
| Scrapyrt | |
| Gerapy |
����
HTTP����ԭ��
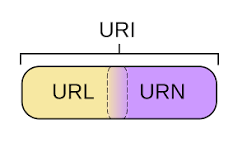
URI��URL
URI�ɱ���Ϊ��λ����URL�������ƣ�URN�������汸�� ͳһ��Դ��ʶ����URI�����ڱ�ʶijһ��������Դ����ͳһ��Դ��λ����URL����ʾ��Դ�ĵص㣨��������������λ�ã��� ����URL ��URI ���Ӽ���
���ı�
��ҳ��Դ�����ɳ�Ϊ���ı���
HTTP��HTTPS
HTTP ��ȫ���� Hyper Text Transfer Protocol���������������ı�����Э�飬HTTP Э�������ڴ����紫�䳬�ı����ݵ�����������Ĵ���Э�飬���ܱ�֤����Ч��ȷ�ش��ͳ��ı��ĵ���
HTTPS ��ȫ���� Hyper Text Transfer Protocol over Secure Socket Layer������ȫΪĿ��� HTTP ͨ�������� HTTP �İ�ȫ�棬�� HTTP �¼��� SSL �㣬���Ϊ HTTPS��
HTTPS �İ�ȫ������ SSL�����ͨ������������ݶ��Ǿ��� SSL ���ܵģ�������Ҫ���ÿ��Է�Ϊ���֣�
- �ǽ���һ����Ϣ��ȫͨ��������֤���ݴ���İ�ȫ��
- ȷ����վ����ʵ�ԣ�����ʹ���� https ����վ��������ͨ������������ַ������ͷ��־���鿴��վ��֤֮�����ʵ��Ϣ��Ҳ����ͨ�� CA �����䷢�İ�ȫǩ������ѯ��
��ijЩ��վ��Ȼʹ���� HTTPS Э�黹�ǻᱻ�������ʾ����ȫ����������֤����֤�Ͳ���ͨ������ʾ�����Ļ�������ʵ�����������ݴ�����Ȼ�Ǿ��� SSL ���ܵġ����Ҫ��ȡ������վ�����Ҫ���ú���֤���ѡ��������ʾ SSL ���Ӵ���
HTTP�������
�������������һ��url���س���ɿ�������ҳ�����ݣ�ʵ���Ϲ���������������վ�ķ���������һ��Request(����)����վ�ķ���������֮��Ȼ����֮��Ӧ��һ��Response(��Ӧ)��Ȼ�ظ��������response��Ӧ�а�����ҳ���Դ��������ݣ�������������㽫��ҳ�����ֳ���
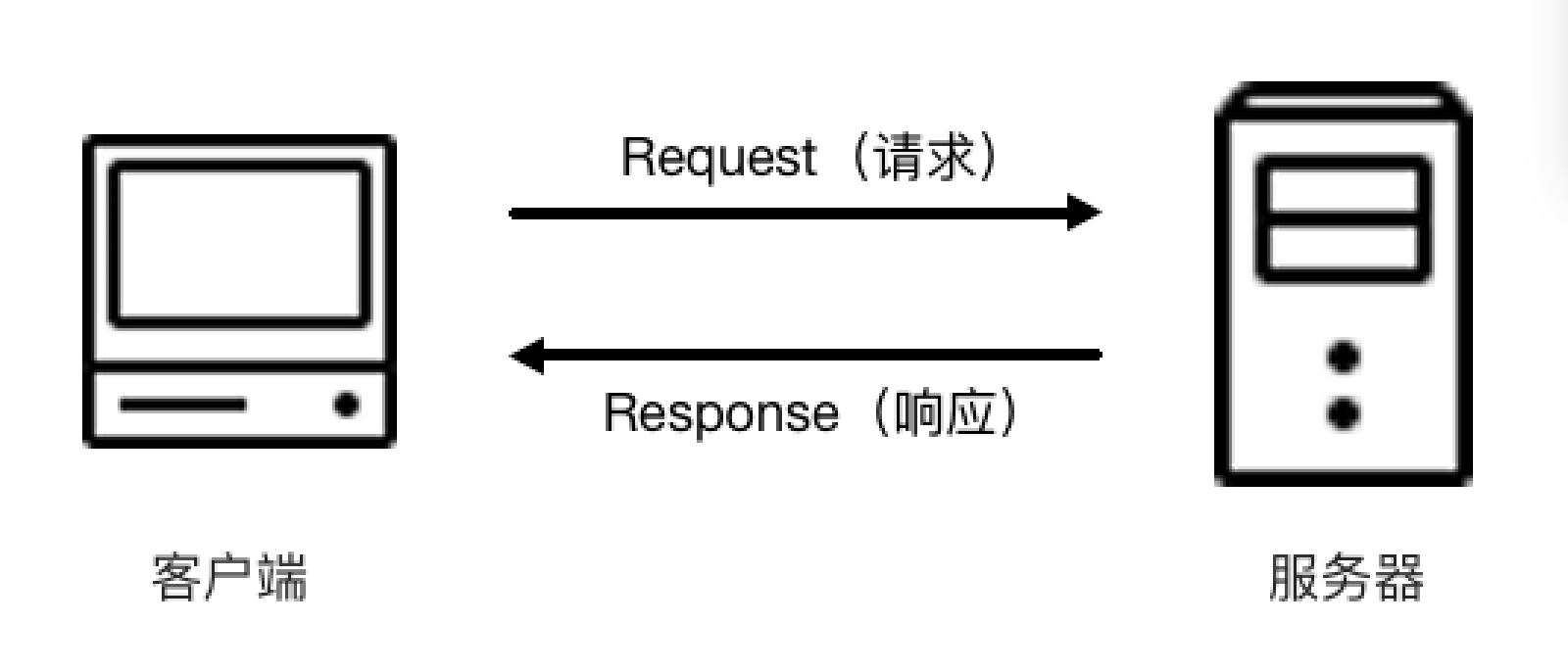

����F12��Ȼ����network��壬��ɿ���һ�η�������ͽ�����Ӧ֮��Ĺ��̡�
һ����Ŀ�����Ƽ����壺
Name���� Request �����ơ�Status���� Response ��״̬�롣ͨ��״̬������жϷ����� Request ֮���Ƿ�õ��������� Response��Type���� Request ������ĵ����͡�Initiator��������Դ��Size�����ӷ��������ص��ļ����������Դ��С��Time�������� Request ����ȡ�� Response ���õ���ʱ�䡣Timeline������������Ŀ��ӻ��ٲ�����
���ij��Ŀ���Կ�������ϸ����Ϣ
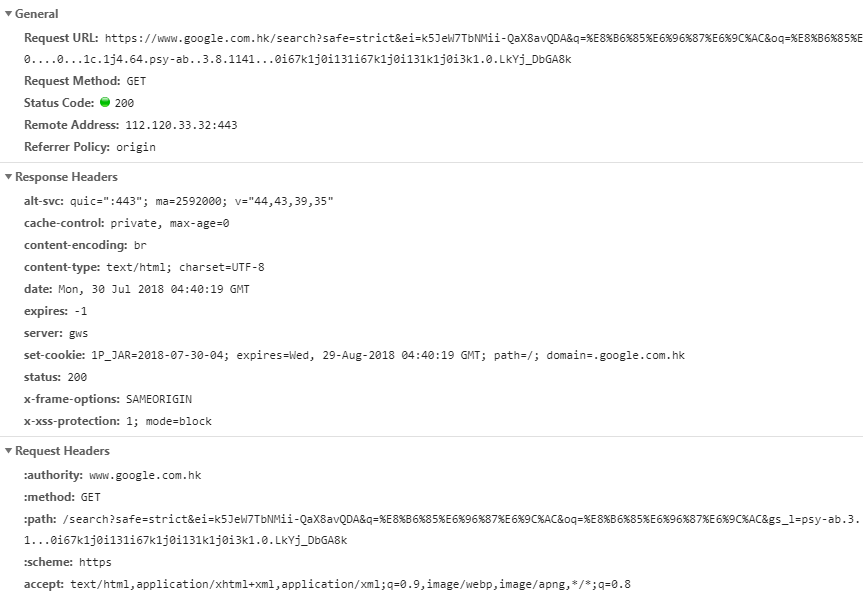
General���������Եĺ���:
- Request URL Ϊ Request �� URL
- Request Method Ϊ����ķ���
- Status Code Ϊ��Ӧ״̬��
- Remote Address ΪԶ�̷������ĵ�ַ�Ͷ˿�
- Referrer Policy Ϊ Referrer �б����
Response Headers ��һ�� Request Headers����ֱ������Ӧͷ������ͷ������ͷ�����������������Ϣ�������������ʶ��Cookies��Host ����Ϣ������ Request ��һ���֣����������������ͷ�ڵ���Ϣ�ж������Ƿ�Ϸ�������������Ӧ����Ӧ������ Response����ô��ͼ�п����� Response Headers ���� Response ��һ���֣��������а����˷����������͡��ĵ����͡����ڵ���Ϣ����������ܵ� Response �������Ӧ���ݣ�����������ҳ���ݡ�
����
Request
Request���������ɿͻ��������˷�����
Request ���IJ������ݣ�
- Request Method(����ʽ)
- Request URL(��������)
- Request Headers(����ͷ)
- Request Body(������)
- Request Method
����ʽ�������ֳ���������:GET��POST
*GET:*��ָ������Դ�������ݡ������ڹȸ���ֱ������������㷢����һ��get��������IJ�����ֱ�Ӱ�����url�У���:https://www.google.com.hk/search?q=��&oq=��&aqs=chrome..69i57j69i60l4.5466j0j7&sourceid=chrome&ie=UTF-8��url�а���������IJ�����Ϣ������IJ���q���������Ĺؼ���
*POST:*��ָ������Դ�ύҪ�����������ݡ�POST ������Ϊ�����ύ������һ����¼�����������û������룬�����¼��ť����ͨ���ᷢ��һ�� POST ����������ͨ���� Form Data ����������ʽ���䣬���������� URL �С�
GET �� POST ��������������
- GET ��ʽ�����в����ǰ����� URL ����ģ����ݿ����� URL �п������� POST ����� URL ���������Щ���ݣ����ݶ���ͨ����������ʽ���䣬������� Request Body �С�
- GET ��ʽ�����ύ���������ֻ�� 1024 �ֽڣ��� POST ��ʽû�����ơ�
����ʽ�Լ�����
����
| ���� | |
|---|---|
| GET | ����ָ����ҳ����Ϣ��������ʵ�����塣 |
| HEAD | ������ GET ����ֻ�������ص���Ӧ��û�о�������ݣ����ڻ�ȡ��ͷ�� |
| POST | ��ָ����Դ�ύ���ݽ��д����������ݱ��������������С� |
| PUT | �ӿͻ�������������͵�����ȡ��ָ�����ĵ������ݡ� |
| DELETE | ���������ɾ��ָ����ҳ�档 |
| CONNECT | HTTP/1.1 Э����Ԥ�����ܹ������Ӹ�Ϊ�ܵ���ʽ�Ĵ����������� |
| OPTIONS | �����ͻ��˲鿴�����������ܡ� |
| TRACE | ���Է������յ���������Ҫ���ڲ��Ի���ϡ� |
�������http://www.runoob.com/http/http-methods.html
- Request URL
�������ַ����ͳһ��Դ��λ������ URL ����Ψһȷ�����������Դ��
- Request Headers
����ͷ������˵��������Ҫʹ�õĸ�����Ϣ���Ƚ���Ҫ����Ϣ�� Cookie��Referer��User-Agent �ȣ����潫һЩ���õ�ͷ��Ϣ˵�����£�
- Accept������ͷ������ָ���ͻ��˿ɽ�����Щ���͵���Ϣ��
- Accept-Language��ָ���ͻ��˿ɽ��ܵ��������͡�
- Accept-Encoding��ָ���ͻ��˿ɽ��ܵ����ݱ��롣
- Host������ָ��������Դ������ IP �Ͷ˿ںţ�������Ϊ���� URL ��ԭʼ�����������ص�λ�á��� HTTP 1.1 �汾��ʼ��Request ������������ݡ�
- Cookie��Ҳ���ø�����ʽ Cookies������վΪ�˱���û����� Session ���ٶ��������û����ص����ݡ�Cookies ����Ҫ���ܾ���ά�ֵ�ǰ���ʻỰ��
- Referer��������������ʶ��������Ǵ��ĸ�ҳ�淢�����ģ������������õ���һ��Ϣ������Ӧ�Ĵ�����������Դͳ�ơ��������������ȡ�
- User-Agent����� UA������һ�������ַ���ͷ��ʹ�÷������ܹ�ʶ��ͻ�ʹ�õIJ���ϵͳ���汾����������汾����Ϣ����������ʱ���ϴ���Ϣ����αװΪ�������������Ӻܿ��ܻᱻʶ���Ϊ���档
- Content-Type���� Internet Media Type��������ý�����ͣ�Ҳ���� MIME ���ͣ��� HTTP Э����Ϣͷ�У�ʹ��������ʾ���������е�ý��������Ϣ������ text/html ���� HTML ��ʽ��image/gif ���� GIF ͼƬ��application/json ���� Json ���ͣ������Ӧ��ϵ���Բ鿴�˶��ձ���http://tool.oschina.net/commons��
Request Headers �� Request ����Ҫ��ɲ��֣���д�����ʱ����������Ҫ�趨 Request Headers��
- Request Body
�������壬һ����ص������� POST �����е� Form Data�����������ݣ������� GET ���� Request Body ��Ϊ�ա�
�����г��� Content-Type �� POST �ύ���ݷ�ʽ�Ĺ�ϵ��
| Content-Type | �ύ���ݷ�ʽ |
|---|---|
| application/x-www-form-urlencoded | Form �����ύ |
| multipart/form-data | �����ļ��ϴ��ύ |
| application/json | ���л� Json �����ύ |
| text/xml | XML �����ύ |
�����������Ҫ���� POST ������Ҫע���⼸�� Content-Type���˽���������ĸ�����������ʱʹ�õ������� Content-Type����Ȼ���ܻᵼ�� POST �ύ��ò��������� Response��
��Ӧ
Response������Ӧ���ɷ���˷��ظ��ͻ��ˡ�Response ���Ի���Ϊ�����֣�Response Status Code��Response Headers��Response Body��
Response Status Code
��Ӧ״̬�룬��״̬���ʾ�˷���������Ӧ״̬���� 200 �����������������Ӧ��404 �����ҳ��δ�ҵ���500 ������������ڲ����������������У����Ը���״̬�����жϷ�������Ӧ״̬�����ж�״̬��Ϊ 200����֤���ɹ��������ݣ��ٽ��н�һ���Ĵ���������ֱ�Ӻ��ԡ�
�����ñ����г��˳����Ĵ�����뼰����ԭ��
| ״̬�� | ˵�� | ���� |
|---|---|---|
| 100 | ���� | ������Ӧ��������������������յ������һ���֣����ڵȴ����ಿ�֡� |
| 101 | �л�Э�� | ��������Ҫ��������л�Э�飬��������ȷ�ϲ����л��� |
| 200 | �ɹ� | �������ѳɹ����������� |
| 201 | �Ѵ��� | ����ɹ����ҷ������������µ���Դ�� |
| 202 | �ѽ��� | �������ѽ���������δ������ |
| 203 | ����Ȩ��Ϣ | �������ѳɹ��������������ص���Ϣ����������һ��Դ�� |
| 204 | ������ | �������ɹ�����������û�з����κ����ݡ� |
| 205 | �������� | �������ɹ��������������ݱ����á� |
| 206 | �������� | �������ɹ������˲������� |
| 300 | ����ѡ�� | �������������ִ�ж��ֲ����� |
| 301 | �����ƶ� | �������ҳ�������ƶ�����λ�ã��������ض��� |
| 302 | ��ʱ�ƶ� | �������ҳ��ʱ��ת������ҳ�棬����ʱ�ض��� |
| 303 | �鿴����λ�� | ���ԭ���������� POST���ض���Ŀ���ĵ�Ӧ��ͨ�� GET ��ȡ�� |
| 304 | δ�� | �˴����ص���ҳδ�ģ�����ʹ���ϴε���Դ�� |
| 305 | ʹ�ô��� | ������Ӧ��ʹ�ô������ʸ���ҳ�� |
| 307 | ��ʱ�ض��� | �������Դ��ʱ������λ����Ӧ�� |
| 400 | �������� | ������������������ |
| 401 | δ��Ȩ | ����û�н���������֤����֤δͨ���� |
| 403 | ��ֹ���� | �������ܾ������� |
| 404 | δ�ҵ� | �������Ҳ����������ҳ�� |
| 405 | �������� | ������������������ָ���ķ����� |
| 406 | ������ | ��ʹ�������������Ӧ�������ҳ�� |
| 407 | ��Ҫ������Ȩ | ��������Ҫʹ�ô�����Ȩ�� |
| 408 | ����ʱ | ����������ʱ�� |
| 409 | ��ͻ | ���������������ʱ������ͻ�� |
| 410 | ��ɾ�� | �������Դ������ɾ���� |
| 411 | ��Ҫ��Ч���� | �����������ܲ�����Ч���ݳ��ȱ�ͷ�ֶε����� |
| 412 | δ����ǰ������ | ������δ���������������������õ�����һ��ǰ�������� |
| 413 | ����ʵ����� | ����ʵ��������������Ĵ��������� |
| 414 | ���� URI ���� | ������ַ�������������������� |
| 415 | ��֧������ | ����ĸ�ʽ��������ҳ���֧�֡� |
| 416 | ����Χ���� | ҳ�����ṩ����ķ�Χ�� |
| 417 | δ��������ֵ | ������δ�������������ͷ�ֶε�Ҫ�� |
| 500 | �������ڲ����� | ����������������������� |
| 501 | δʵ�� | ���������߱��������Ĺ��ܡ� |
| 502 | �������� | ��������Ϊ���ػ�����������η������յ���Ч��Ӧ�� |
| 503 | ������ | ������Ŀǰ��ʹ�á� |
| 504 | ���س�ʱ | ��������Ϊ���ػ����������û�м�ʱ�����η������յ����� |
| 505 | HTTP �汾��֧�� | ��������֧�����������õ� HTTP Э��汾�� |
Response Headers
��Ӧͷ�����а����˷������������Ӧ����Ϣ���� Content-Type��Server��Set-Cookie �ȣ����潫һЩ���õ�ͷ��Ϣ˵�����£�
- Date����ʶ Response ������ʱ�䡣
- Last-Modified��ָ����Դ�������ʱ�䡣
- Content-Encoding��ָ�� Response ���ݵı��롣
- Server�������˷���������Ϣ�����ƣ��汾�ŵȡ�
- Content-Type���ĵ����ͣ�ָ���˷��ص�����������ʲô����text/html ��������� HTML �ĵ���application/x-javascript ��������� JavaScript �ļ���image/jpeg �����������ͼƬ��
- Set-Cookie������Cookie��Response Headers �е� Set-Cookie�������������Ҫ�������ݷ��� Cookies �У��´�����Я�� Cookies ����
- Expires��ָ�� Response �Ĺ���ʱ�䣬ʹ�������Կ��ƴ���������������������ݸ��µ������У�����ٴη���ʱ��ֱ�Ӵӻ����м��أ����ͷ��������أ����̼���ʱ�䡣
Resposne Body
����Ӧ�壬����Ҫ�ĵ�����Ӧ�������ˣ���Ӧ���������ݶ�������Ӧ���У�������һ����ҳ��������Ӧ�������ҳ�� HTML ���룬����һ��ͼƬ��������Ӧ�����ͼƬ�Ķ��������ݡ���������Ҫ�����ݶ���������Ӧ�����ˣ�������������ҳ��Ҫ���������ݾ��ǽ�����Ӧ��

������������߹����е�� Preview���Ϳ��Կ�����ҳ��Դ���룬��Ҳ������Ӧ�����ݣ��ǽ�����Ŀ�ꡣ
��������ʱ��Ҫ���������ݾ��� Resposne Body��ͨ�� Resposne Body ���Եõ���ҳ��Դ���롢Json ���ݵȵȣ�Ȼ���������Ӧ���ݵ���ȡ��
��ҳ����
�˽���ҳ�Ļ�����ɡ��ṹ���ڵ�����ݡ�
��ҳ�����
HTML
HTML ������������ҳ��һ�����ԣ���ȫ�ƽ��� Hyper Text Markup Language�������ı�������ԡ���ҳ�������֡���ť��ͼƬ����Ƶ�ȸ��ָ��ӵ�Ԫ�أ�������ܹ����� HTML����ͬ���͵�����ͨ����ͬ���͵ı�ǩ����ʾ����ͼƬ�� img ��ǩ��ʾ����Ƶ�� video ��ǩ����ʾ�������� p ��ǩ����ʾ������֮��IJ����ֳ�ͨ�����ֱ�ǩ div Ƕ����϶��ɣ����ֱ�ǩͨ����ͬ�����к�Ƕ�ײ��γ�����ҳ�Ŀ�ܡ�
CSS
CSS��ȫ�ƽ��� Cascading Style Sheets���������ʽ�������������ָ���� HTML ��������������ʽ�ļ���������ʽ������ͻʱ������������ݲ��˳����������ʽ��ָ��ҳ�����ִ�С����ɫ��Ԫ�ؼ�ࡢ���еȸ�ʽ��
JavaScript
JavaScript�����Ϊ JS����һ�ֽű����ԣ�HTML �� CSS ���ʹ�ã��ṩ���û���ֻ��һ�־�̬����Ϣ��ȱ�ٽ����ԡ�����ҳ����ܻῴ��һЩ�����Ͷ���Ч���������ؽ���������ʾ���ֲ�ͼ�ȣ���ͨ������ JavaScript �Ĺ��͡����ij���ʹ���û�����Ϣ֮�䲻ֻ��һ���������ʾ�Ĺ�ϵ������ʵ����һ��ʵʱ����̬��������ҳ�湦�ܡ�
��ҳ�Ľṹ
��ҳ��һ��ṹ������ html ��ǩ��Ƕ�� head �� body ��ǩ��head �ڶ�����ҳ�����ú����ã�body �ڶ�����ҳ�����ġ�
<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>This is a test</title></head><body><div id="header">header</div> <div id="container"><div class="wrapper"><h2 class="title">Hello World</h2><p class="text">Hello, this is a paragraph.</p></div></div><div id="footer">footer</div></body>
</html>
�ڵ������ڵ��Ĺ�ϵ
�� HTML DOM �У��������ﶼ�ǽڵ㡣DOM �DZ���Ϊ�ڵ����� HTML��
DOM �ڵ�
���� W3C �� HTML DOM ����HTML �ĵ��е��������ݶ��ǽڵ㣺
- �����ĵ���һ���ĵ��ڵ�
- ÿ�� HTML Ԫ����Ԫ�ؽڵ�
- HTML Ԫ���ڵ��ı����ı��ڵ�
- ÿ�� HTML ���������Խڵ�
- ע����ע�ͽڵ�
HTML DOM �ڵ���
HTML DOM �� HTML �ĵ��������ṹ�����ֽṹ����Ϊ�ڵ�����
HTML DOM Tree ʵ��
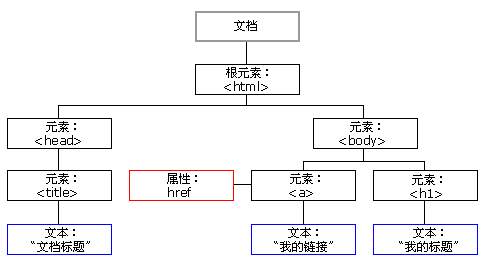
ͨ�� HTML DOM�����е����нڵ����ͨ�� JavaScript ���з��ʡ����� HTML Ԫ�أ��ڵ㣩���ɱ��ģ�Ҳ���Դ�����ɾ���ڵ㡣
�ڵ㸸���Ӻ�ͬ��
�ڵ����еĽڵ�˴�ӵ�в㼶��ϵ��
����parent�����ӣ�child����ͬ����sibling������������������Щ��ϵ�����ڵ�ӵ���ӽڵ㡣ͬ�����ӽڵ㱻��Ϊͬ�����ֵܻ���ã���
- �ڽڵ����У����˽ڵ㱻��Ϊ����root��
- ÿ���ڵ㶼�и��ڵ㡢���˸�����û�и��ڵ㣩
- һ���ڵ��ӵ��������������
- ͬ����ӵ����ͬ���ڵ�Ľڵ�
�����ͼƬչʾ�˽ڵ�����һ���֣��Լ��ڵ�֮��Ĺ�ϵ��
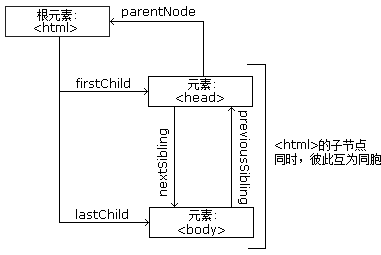
���βο�:http://www.w3school.com.cn/htmldom/dom_nodes.asp
ѡ����
CSS ѡ�����������
| ѡ���� | ���� | �������� |
|---|---|---|
| .class | .intro | ѡ�� class="intro" �����нڵ㡣 |
| #id | #firstname | ѡ�� id="firstname" �����нڵ㡣 |
| * | * | ѡ�����нڵ㡣 |
| element | p | ѡ������ p �ڵ㡣 |
| element,element | div,p | ѡ������ div �ڵ������ p �ڵ㡣 |
| element element | div p | ѡ�� div �ڵ��ڲ������� p �ڵ㡣 |
| element>element | div>p | ѡ�ڵ�Ϊ div �ڵ������ p �ڵ㡣 |
| element+element | div+p | ѡ������� div �ڵ�֮������� p �ڵ㡣 |
| [attribute] | [target] | ѡ����� target �������нڵ㡣 |
| [attribute=value] | [target=blank] | ѡ�� target="blank" �����нڵ㡣 |
| [attribute~=value] | [title~=flower] | ѡ�� title ���������� "flower" �����нڵ㡣 |
| :link | a:link | ѡ������δ�����ʵ����ӡ� |
| :visited | a:visited | ѡ�������ѱ����ʵ����ӡ� |
| :active | a:active | ѡ�����ӡ� |
| :hover | a:hover | ѡ�����ָ��λ�����ϵ����ӡ� |
| :focus | input:focus | ѡ���ý���� input �ڵ㡣 |
| :first-letter | p:first-letter | ѡ��ÿ�� p �ڵ������ĸ�� |
| :first-line | p:first-line | ѡ��ÿ�� p �ڵ�����С� |
| :first-child | p:first-child | ѡ�����ڸ��ڵ�ĵ�һ���ӽڵ��ÿ�� p �ڵ㡣 |
| :before | p:before | ��ÿ�� p �ڵ������֮ǰ�������ݡ� |
| :after | p:after | ��ÿ�� p �ڵ������֮��������ݡ� |
| :lang(language) | p:lang | ѡ������� "it" ��ͷ�� lang ����ֵ��ÿ�� p �ڵ㡣 |
| element1~element2 | p~ul | ѡ��ǰ���� p �ڵ��ÿ�� ul �ڵ㡣 |
| [attribute^=value] | a[src^="https"] | ѡ���� src ����ֵ�� "https" ��ͷ��ÿ�� a �ڵ㡣 |
| [attribute$=value] | a[src$=".pdf"] | ѡ���� src ������ ".pdf" ��β������ a �ڵ㡣 |
| [attribute*=value] | a[src*="abc"] | ѡ���� src �����а��� "abc" �Ӵ���ÿ�� a �ڵ㡣 |
| :first-of-type | p:first-of-type | ѡ�������丸�ڵ���� p �ڵ��ÿ�� p �ڵ㡣 |
| :last-of-type | p:last-of-type | ѡ�������丸�ڵ����� p �ڵ��ÿ�� p �ڵ㡣 |
| :only-of-type | p:only-of-type | ѡ�������丸�ڵ�Ψһ�� p �ڵ��ÿ�� p �ڵ㡣 |
| :only-child | p:only-child | ѡ�������丸�ڵ��Ψһ�ӽڵ��ÿ�� p �ڵ㡣 |
| :nth-child(n) | p:nth-child | ѡ�������丸�ڵ�ĵڶ����ӽڵ��ÿ�� p �ڵ㡣 |
| :nth-last-child(n) | p:nth-last-child | ͬ�ϣ������һ���ӽڵ㿪ʼ������ |
| :nth-of-type(n) | p:nth-of-type | ѡ�������丸�ڵ�ڶ��� p �ڵ��ÿ�� p �ڵ㡣 |
| :nth-last-of-type(n) | p:nth-last-of-type | ͬ�ϣ����Ǵ����һ���ӽڵ㿪ʼ������ |
| :last-child | p:last-child | ѡ�������丸�ڵ����һ���ӽڵ�ÿ�� p �ڵ㡣 |
| :root | :root | ѡ���ĵ��ĸ��ڵ㡣 |
| :empty | p:empty | ѡ��û���ӽڵ��ÿ�� p �ڵ㣨�����ı��ڵ㣩�� |
| :target | #news:target | ѡ��ǰ��� #news �ڵ㡣 |
| :enabled | input:enabled | ѡ��ÿ�����õ� input �ڵ㡣 |
| :disabled | input:disabled | ѡ��ÿ�����õ� input �ڵ� |
| :checked | input:checked | ѡ��ÿ����ѡ�е� input �ڵ㡣 |
| :not(selector) | p:not | ѡ��� p �ڵ��ÿ���ڵ㡣 |
| ::selection | ::selection | ѡ���û�ѡȡ�Ľڵ㲿�֡� |
����Ļ���ԭ��
ʲô������?
���棬���������棬���ѻ������ͱ���һ�Ŵ�����������������������е�֩�룬�������Ľڵ����һ������ҳ��������������൱�ڷ����˸�ҳ���ȡ������Ϣ���ڵ������߿��Ա�����ҳ����ҳ֮������ӹ�ϵ������֩��ͨ��һ���ڵ�����˳�Žڵ����������е�����һ���ڵ㣬��ͨ��һ����ҳ������ȡ��������ҳ�������������Ľڵ����Ա�֩��ȫ�����е���������վ�����ݾͿ��Ա�ץȡ�����ˡ�
�����������
������ǻ�ȡ��ҳ����ȡ�ͱ�����Ϣ���Զ�������IJ�������:
��ȡ��ҳ
��������Ҫ���Ĺ������ǻ�ȡ��ҳ���������ȡ��ҳ����ȡ��ҳ��Դ���룬Դ���������Ȼ��������ҳ�IJ������õ���Ϣ������ֻҪ��Դ�����ȡ�����ˣ��Ϳ��Դ�����ȡ��Ҫ����Ϣ�ˡ�
��ȡ��Ϣ
�ڵ�һ����ȡ����ҳԴ����֮�������Ĺ������Ƿ�����ҳԴ���룬������ȡ��Ҫ�����ݡ�
��������
��ȡ��Ϣ֮��һ��Ὣ��ȡ�������ݱ��浽ij���Ա�������ݴ���ʹ�á�������ʽ�ж��ֶ���������Լ���Ϊ TXT �ı��� Json �ı���Ҳ���Ա��浽���ݿ⣬�� MySQL��MongoDB �ȣ�Ҳ�ɱ�����Զ�̷������������ Sftp ���в����ȡ�
��ץ����������
����ҳ���ܿ������ָ�������Ϣ������ı��dz�����ҳ���䶼��Ӧ�� HTML ���룬�������ץȡ����ץȡ HTML Դ���롣
���������Щ��ҳ���صIJ��� HTML ���룬���Ƿ���һ�� Json �ַ�����API �ӿڴ�������������ʽ���������ݵĴ���ͽ�������������ͬ������ץȡ������������ȡ���ӷ��㡣
������Կ������ֶ��������ݣ���ͼƬ����Ƶ����Ƶ�ȵȣ������������潫���ǵĶ���������ץȡ������Ȼ��ɶ�Ӧ���ļ������ɡ�
������Կ���������չ�����ļ����� CSS��JavaScript�������ļ��ȵȣ���Щ��ʵҲ������ͨ���ļ���ֻҪ�������������ʵ����Ϳ��Խ���ץȡ������
���ϵ�������ʵ����Ӧ�Ÿ��Ե�URL���ǻ��� HTTP �� HTTPS Э��ģ�ֻҪ�������������涼���Խ���ץȡ��
�Զ�������
˵���Զ���������˼����˵������Դ������������Щ�����������ֹ���Ȼ�ǿ�����ȡ��Щ��Ϣ�ģ����ǵ����ر���������ٻ�ȡ�������ݵĻ����϶����ǽ����ڳ�������������Ǵ�������������ȡ���ݵĹ������Զ���������������ץȡ�����н��и����쳣�������������ԵȲ�����ȷ����ȡ������Ч�����С�
javascript��Ⱦ��ҳ��
��ʱ������ Urllib �� Requests ץȡ��ҳʱ���õ���Դ����ʵ�ʺ�������п������Dz�һ���ġ�
���������һ���dz����������⣬������ҳԽ��Խ��ز��� Ajax��ǰ��ģ�黯������������ҳ��������ҳ���ܶ����� JavaScript ��Ⱦ�����ģ���˼����˵ԭʼ�� HTML �������һ���տǣ����磺
<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>This is a Demo</title></head><body><div id="container"></div></body><script src="app.js"></script>
</html>
body �ڵ�����ֻ��һ�� id Ϊ container �Ľڵ㣬����ע��� body �ڵ��������һ�� app.js������㸺����������վ����Ⱦ��
������������ҳ��ʱ�����Ȼ������� HTML ���ݣ�����������ᷢ����������������һ�� app.js �ļ���Ȼ�������������ȥ��������ļ�����ȡ�����ļ�֮����ִ�����е� JavaScript ���룬�� JavaScript ���ı� HTML �еĽڵ㣬�����������ݣ����õ�������ҳ�档
�������� Urllib �� Requests �ȿ�������ǰҳ��ʱ���õ���ֻ����� HTML ���룬���������ȥ����������� JavaScript �ļ�������Ҳ�Ϳ�����������п����������ˡ�
��Ҳ������Ϊʲô��ʱ�õ���Դ�����������п������Dz�һ���ġ�
����ʹ�û��� HTTP �����õ��Ľ��Դ������ܸ�������е�ҳ��Դ���벻̫һ����������������������Է������̨ Ajax �ӿڣ�Ҳ��ʹ�� Selenium��Splash �����Ŀ���ʵ��ģ�� JavaScript ��Ⱦ�������������ȡ JavaScript ��Ⱦ����ҳ�������ˡ�
�Ự��cookies
����
Session��Cookie�ĵ���
cookie���ԣ�
- Name������ Cookie �����ơ�
- Value������ Cookie ��ֵ�����ֵΪ Unicode �ַ�����ҪΪ�ַ����롣���ֵΪ���������ݣ�����Ҫʹ�� BASE64 ���롣
- Max Age������ Cookie ʧЧ��ʱ�䣬��λ�룬Ҳ���� Expires һ��ʹ�ã�ͨ�������Լ��������Чʱ�䡣Max Age ���Ϊ���������Cookie �� Max Age ��֮��ʧЧ�����Ϊ��������ر������ʱCookie ��ʧЧ�������Ҳ�������κ���ʽ����� Cookie��
- Path������ Cookie ��ʹ��·�����������Ϊ /path/����ֻ��·��Ϊ /path/ ��ҳ����Է��ʸ� Cookie���������Ϊ /���������µ�����ҳ�涼���Է��ʸ� Cookie��
- Domain�������Է��ʸ� Cookie �������������������Ϊ .zhihu.com���������� zhihu.com����β�����������Է��ʸ�Cookie��
- Size�ֶΣ����� Cookie �Ĵ�С��
- Http�ֶΣ��� Cookie �� httponly ���ԡ���������Ϊ true����ֻ���� HTTP Headers �л���д� Cookie ����Ϣ��������ͨ�� document.cookie �����ʴ� Cookie��
- Secure������ Cookie �Ƿ����ʹ�ð�ȫЭ�鴫�䡣��ȫЭ�顣��ȫЭ���� HTTPS��SSL �ȣ��������ϴ�������֮ǰ�Ƚ����ݼ��ܡ�Ĭ��Ϊ false��
��̬��ҳ�Ͷ�̬��ҳ
��̬��ҳ������ڶ�̬��ҳ���ԣ���ָû�к�̨���ݿ⡢��������Ͳ��ɽ�������ҳ����̬��ҳ��Ը��������Ƚ��鷳��������һ����½��ٵ�չʾ����վ�����������Ǿ�̬ҳ�涼��htm����ҳ�棬ʵ���Ͼ�̬Ҳ������ȫ��̬��Ҳ���Գ��ָ��ֶ�̬��Ч������GIF��ʽ�Ķ�����FLASH��������Ļ�ȡ�
��״̬HTTP
HTTP ����״̬��ָ HTTP Э�����������û�м��������ģ�Ҳ����˵��������֪���ͻ�����ʲô״̬���������������һ�� Requset ������������ Request��Ȼ�ض�Ӧ�� Response���������������������̣����������������ȫ�����ģ������������¼ǰ��״̬�ı仯��Ҳ����ȱ��״̬��¼������ζ�����������Ҫ������Ҫǰ�����Ϣ����������Ҫ�ش�����Ҳ��������Ҫ�����һЩǰ����ظ� Request ���ܻ�ȡ���� Response��Ȼ������Ч����Ȼ������Ҫ�ġ�Ϊ�˱���ǰ��״̬���϶����ܽ�ǰ�������ȫ���ش�һ�Σ���̫�˷���Դ�ˣ�����������Ҫ�û���¼��ҳ����˵�����Ǽ��֡�
���ڱ��� HTTP ����״̬�ļ��������Ƿֱ��� Session �� Cookies��Session �ڷ���ˣ�Ҳ������վ�ķ����������������û��ĻỰ��Ϣ��Cookies �ڿͻ��ˣ����ڱ����¼��һЩƾ֤��Ϣ��
��������
��̸�� Session ���Ƶ�ʱ������������һ����⡰ֻҪ�ر��������Session ����ʧ�ˡ������������Ǵ���ģ���������һ�»�Ա�������ӣ����ǹ˿������Ե����������������Ҿ��Բ�������ɾ���˿͵����ϡ��� Session ��˵Ҳ��һ���ģ����dz���֪ͨ������ɾ��һ�� Session�������������һֱ�������������һ�㶼������ע��������ʱ���ȥɾ�� Session��
���ǵ��ر������ʱ����������������ڹر�֮ǰ֪ͨ����������Ҫ�رգ����Է��������������л���֪��������Ѿ��رգ�֮���Ի������ִ������Ǵ� Session ���ƶ�ʹ�ûỰ Cookie ������ Session ID ��Ϣ�����ر�������� Cookies ����ʧ�ˣ��ٴ����ӷ�����ʱҲ�����ҵ�ԭ���� Session��������������õ� Cookies �����浽Ӳ���ϣ�����ʹ��ij���ֶθ�д����������� HTTP ����ͷ����ԭ���� Cookies ���������������ٴδ��������Ȼ�ܹ��ҵ�ԭ���� Session ID�����ɻ��ǿ��Ա��ֵ�¼״̬�ġ�
����ǡǡ�����ڹر���������ᵼ�� Session ��ɾ���������Ҫ������Ϊ Seesion ����һ��ʧЧʱ�䣬������ͻ�����һ��ʹ�� Session ��ʱ�䳬�����ʧЧʱ��ʱ���������Ϳ�����Ϊ�ͻ����Ѿ�ֹͣ�˻���Ż�� Session ɾ���Խ�ʡ�洢�ռ䡣
�����
- Session�ͼ���״̬���ַ�������
����
����
��������Ĺ����о����������������������������������У�����ץȡ���ݣ�һ�п�����������ô�����ã�Ȼ��һ����Ĺ�����ܾͻ���ִ����� 403 Forbidden����ʱ�����ҳһ�������ܻῴ����IP ����Ƶ��̫�ߡ���������ʾ�����������������ԭ������վ��ȡ��һЩ������Ĵ�ʩ���������������ij�� IP �ڵ�λʱ���ڵ������������������������ֵ����ô��ֱ�Ӿܾ�������һЩ������Ϣ������������Գ�֮Ϊ�� IP�����Ǻ��ͳɹ�������������ˡ�
��Ȼ������������ij�� IP ��λʱ��������������ô����ij�ַ�ʽ��αװ�� IP���÷�����ʶ�����ɱ�������������Ϳ��Գɹ���ֹ�� IP ����
��ô������һ����Ч�ķ�ʽ����ʹ�ô�����ʹ�������Գɹ�αװ IP�����Ȿ�� IP ������������
����ԭ��
������������Ӣ�Ľ��� Proxy Server�����Ĺ����Ǵ��������û�ȥȡ��������Ϣ�������˵������������Ϣ����תվ������������һ����վʱ���Ƿ����� Request �� Web ��������Web �������� Response ����������������˴�����������ʵ���Ͼ����ڱ����ͷ�����֮����һ���ţ���ʱ��������ֱ���� Web ����������������������������������� Request �ᷢ��������������Ȼ���ɴ����������ٷ��� Web ��������Ȼ���ɴ����������ٰ� Web ���������ص� Response ת��������������ͬ����������������ҳ����������� Web ������ʶ�������ʵ�� IP �Ͳ����DZ����� IP �ˣ��ͳɹ�ʵ���� IP αװ������Ǵ����Ļ���ԭ����
��������;
- ����һЩ��λ�������ڲ���Դ
- ��߷����ٶ�
- ������ʵ IP
- ͻ������ IP �������ƣ�����һЩƽʱ���ܷ��ʵ�վ��
�������
����������˵������������ȡ�ٶȹ��죬����ȡ�����п�������ͬһ�� IP ���ʹ���Ƶ�������⣬��վ�ͻ���������֤����¼����ֱ�ӷ��� IP�����������ȡ��������IJ��㡣
����ʹ�ô���������ʵ�� IP���÷���������Ϊ�Ǵ����������������Լ�����������ȡ������ͨ�����ϸ����������Ͳ��ᱻ���������Դﵽ�ܺõ���ȡЧ����
���������
���
���ݴ�����Э�����֣��������Է�Ϊ�������
- FTP ��������������Ҫ���ڷ��� FTP ��������һ�����ϴ��������Լ����湦�ܣ��˿�һ��Ϊ 21��2121 �ȡ�
- HTTP ��������������Ҫ���ڷ�����ҳ��һ�������ݹ��˺ͻ��湦�ܣ��˿�һ��Ϊ 80��8080��3128 �ȡ�
- SSL/TLS ��������Ҫ���ڷ��ʼ�����վ��һ���� SSL �� TLS ���ܹ��ܣ����֧�� 128 λ����ǿ�ȣ����˿�һ��Ϊ 443��
- RTSP ��������Ҫ���� Realplayer ���� Real ��ý���������һ���л��湦�ܣ��˿�һ��Ϊ 554��
- Telnet��������Ҫ���� telnet Զ�̿��ƣ��ڿ����ּ����ʱ�������������ݣ����˿�һ��Ϊ23��
- POP3/SMTP ��������Ҫ���� POP3/SMTP ��ʽ�շ��ʼ���һ���л��湦�ܣ��˿�һ��Ϊ 110/25��
- SOCKS������ֻ�ǵ����������ݰ��������ľ���Э����÷��������ٶȿ�ܶ࣬һ���л��湦�ܣ��˿�һ��Ϊ1080��SOCKS ����Э���ַ�Ϊ SOCKS4 �� SOCKS5��SOCKS4 Э��ֻ֧�� TCP���� SOCKS5 Э��֧�� TCP �� UDP����֧�ָ���������֤���ơ������������������ȡ�����˵��SOCK4��������SOCKS5��������������SOCKS5��������SOCK4��һ����������
���������̶�����
���ݴ����������̶Ȼ��֣��������Է�Ϊ�������
- �߶������������߶����������Ὣ���ݰ�ԭ�ⲻ����ת�����ڷ���˿����ͺ��������һ����ͨ�ͻ����ڷ��ʣ�����¼�� IP �Ǵ����������� IP��
- ��ͨ������������ͨ���������������ݰ�����һЩ�Ķ�����������п��ܷ������Ǹ�������������Ҳ��һ�������鵽�ͻ��˵���ʵ IP������������ͨ�������� HTTP ͷ�� HTTP_VIA �� HTTP_X_FORWARDED_FOR��
- �������������������Ķ������ݰ���������߷������ͻ��˵���ʵ IP�����ִ����������û��漼���������ٶȣ��������ݹ�����߰�ȫ��֮�⣬���������������ã�����������������е�Ӳ������ǽ��
- ����������������ָ��֯����˴����ģ����ڼ�¼�û���������ݣ�Ȼ������о�����ص�Ŀ�Ĵ�����������
�����Ĵ�������
- ʹ�����ϵ���Ѵ��������ʹ�ø��������ʹ��ǰץȡ����ɸѡһ�¿��ô�����Ҳ���Խ�һ��ά��һ�������ء�
- ʹ�ø��Ѵ������������ϴ�����������̣����Ը���ʹ�ã���������Ѵ����úܶࡣ
- ADSL���ţ���һ�κŻ�һ�� IP���ȶ��Ըߣ�Ҳ��һ�ֱȽ���Ч�Ľ��������
���Թ���
postman
postman���ڽ���ģ������Ĺ��ߡ�
��������
XPATH
��װ
pip install lxml
�÷�
| ����ʽ | ���� |
|---|---|
| nodename | ѡȡ�˽ڵ�������ӽڵ� |
| / | �ӵ�ǰ�ڵ�ѡȡֱ���ӽڵ� |
| // | �ӵ�ǰ�ڵ�ѡȡ����ڵ� |
| . | ѡȡ��ǰ�ڵ� |
| .. | ѡȡ��ǰ�ڵ�ĸ��ڵ� |
| @ | ѡȡ���� |
| * | ͨ�����ѡ������Ԫ�ؽڵ���Ԫ���� |
| @* | ѡȡ�������� |
| [@attrib] | ѡȡ���и������Ե�����Ԫ�� |
| [@attrib='value] | ѡȡ�������Ծ��и���ֵ������Ԫ�� |
| [tag] | ѡȡ���о���ָ��Ԫ�ص�ֱ���ӽڵ� |
| [tag="text"] | ѡȡ���о���ָ��Ԫ�ز����ı�������text�ڵ� |