ЧАбд
HDFS SecondaryNameNodeЪЧИЩЪВУДЕФЃП
етЪЧЕРОЕфЕФЛљДЁУцЪдЬтЃЌБЪепЮЪЙ§УцЪдепКмЖрДЮЃЈЕБШЛвВБЛУцЪдЙйЮЪЙ§КмЖрДЮЃЉЁЃДггЁЯѓПДЃЌДѓдМгавЛАыЕФБЛУцЪдепЮоЗЈе§ШЗзїД№ЃЌИјГіЕФД№АИЩѕжСгаЁАВЛОЭЪЧNameNodeЕФШШБИТяЁБЁЃБОЮФРДМђЕЅСФСФЯрЙиЕФжЊЪЖЃЌЮЊНкЪЁЦЊЗљЃЌНЋSecondaryNameNodeМђГЦSNNЃЌNameNodeМђГЦNNЁЃ
NNгыfsimageЁЂedit logЮФМў
NNИКд№ЙмРэHDFSжаЫљгаЕФдЊЪ§ОнЃЌАќРЈЕЋВЛЯогкЮФМў/ФПТМНсЙЙЁЂЮФМўШЈЯоЁЂПщID/ДѓаЁ/Ъ§СПЁЂИББОВпТдЕШЕШЁЃПЭЛЇЖЫжДааЖСаДВйзїЧАЃЌЯШДгNNЛёЕУдЊЪ§ОнЁЃЕБNNдкдЫааЪБЃЌдЊЪ§ОнЖМЪЧБЃДцдкФкДцжаЃЌвдБЃжЄЯьгІЪБМфЁЃ
ЯдШЛЃЌдЊЪ§ОнжЛБЃСєдкФкДцжаЪЧЗЧГЃВЛПЩППЕФЃЌЫљвдвВашвЊГжОУЛЏЕНДХХЬЁЃNNФкВПгаСНРрЮФМўгУгкГжОУЛЏдЊЪ§ОнЃК
- fsimageЮФМўЃЌвд
fsimage_ЮЊЧАзКЃЌЪЧађСаЛЏДцДЂЕФдЊЪ§ОнЕФећЬхПьееЃЛ - edit logЮФМўЃЌвд
edits_ЮЊЧАзКЃЌЪЧЫГађДцДЂЕФдЊЪ§ОнЕФдіСПаоИФЃЈМДПЭЛЇЖЫаДШыЪТЮёЃЉШежОЁЃ
етСНРрЮФМўОљДцДЂдк${dfs.namenode.name.dir}/current/ТЗОЖЯТЃЌВщПДЦфжаЕФФкШнЃК
[root@bigdata-test-hadoop10 current]# ll
змгУСП 412944
-rw-r--r-- 1 hdfs hdfs 46134049 6дТ 29 16:57 edits_0000000001876931538-0000000001877134881
-rw-r--r-- 1 hdfs hdfs 29205984 6дТ 29 17:57 edits_0000000001877134882-0000000001877229652
-rw-r--r-- 1 hdfs hdfs 28306206 6дТ 29 18:57 edits_0000000001877229653-0000000001877318515
-rw-r--r-- 1 hdfs hdfs 49660366 6дТ 29 19:57 edits_0000000001877318516-0000000001877544080
-rw-r--r-- 1 hdfs hdfs 50708454 6дТ 29 20:57 edits_0000000001877544081-0000000001877776582
-rw-r--r-- 1 hdfs hdfs 51308280 6дТ 29 21:57 edits_0000000001877776583-0000000001878012751
-rw-r--r-- 1 hdfs hdfs 28408745 6дТ 29 22:57 edits_0000000001878012752-0000000001878101834
-rw-r--r-- 1 hdfs hdfs 1048576 6дТ 29 22:58 edits_inprogress_0000000001878101835
-rw-r--r-- 1 hdfs hdfs 68590654 6дТ 29 21:57 fsimage_0000000001878012751
-rw-r--r-- 1 hdfs hdfs 62 6дТ 29 21:57 fsimage_0000000001878012751.md5
-rw-r--r-- 1 hdfs hdfs 69451619 6дТ 29 22:57 fsimage_0000000001878101834
-rw-r--r-- 1 hdfs hdfs 62 6дТ 29 22:57 fsimage_0000000001878101834.md5
-rw-r--r-- 1 hdfs hdfs 11 6дТ 29 22:57 seen_txid
-rw-r--r-- 1 hdfs hdfs 175 8дТ 27 2019 VERSION
[root@bigdata-test-hadoop10 current]# cat seen_txid
1878101835
ПЩМћЃЌfsimageКЭedit logЮФМўЖМЛсАДееЪТЮёIDРДЗжЖЮЁЃЕБЧАе§дкаДШыЕФedit logЮФМўУћЛсДјга"inprogress"БъЪЖЃЌЖјseen_txidЮФМўБЃДцЕФОЭЪЧЕБЧАе§дкаДШыЕФedit logЮФМўЕФЦ№ЪМЪТЮёIDЁЃ
дкШЮвтЪБПЬЃЌзюНќЕФfsimageКЭedit logЮФМўЕФФкШнМгЦ№РДОЭЪЧШЋСПдЊЪ§ОнЁЃNNдкЦєЖЏЪБЃЌОЭЛсНЋзюНќЕФfsimageЮФМўМгдиЕНФкДцЃЌВЂжиЗХЫќжЎКѓМЧТМЕФedit logЮФМўЃЌЛжИДдЊЪ§ОнЕФЯжГЁЁЃ
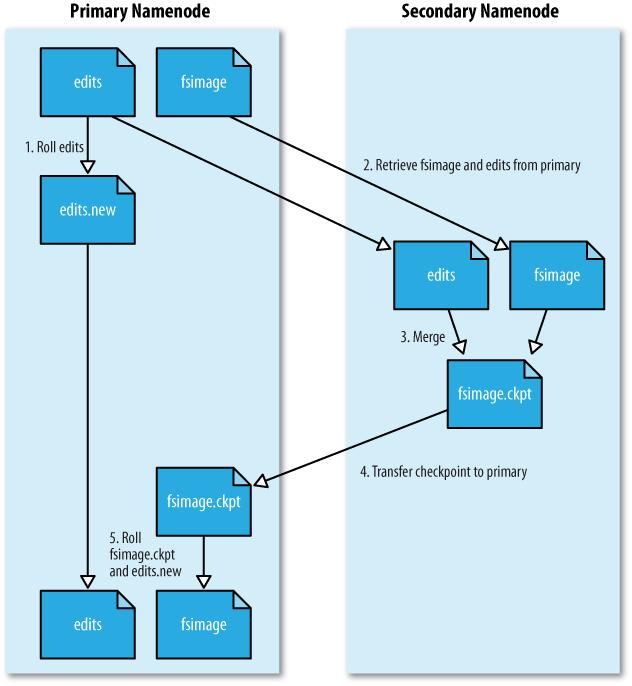
SNNгыcheckpointЙ§ГЬ
ЮЊСЫБмУтedit logЮФМўЙ§ДѓЃЌвдМАЫѕЖЬNNЦєЖЏЪБЛжИДдЊЪ§ОнЕФЪБМфЃЌЮвУЧашвЊЖЈЦкЕиНЋedit logЮФМўКЯВЂЕНfsimageЮФМўЃЌИУКЯВЂЙ§ГЬНазіcheckpointЃЈетИіДЪЪЧеце§БЛгУРУСЫЙўЃЉЁЃ
гЩгкNNЕФИКЕЃвбОБШНЯжиЃЌдйШУЫќРДНјааI/OУмМЏаЭЕФЮФМўКЯВЂВйзїОЭВЛЬЋПЦбЇСЫЃЌЫљвдHadoopв§ШыСЫSNNИКд№етМўЪТЁЃвВОЭЪЧЫЕЃЌSNNЪЧИЈжњNNНјааcheckpointВйзїЕФНЧЩЋЁЃ
checkpointЕФДЅЗЂгЩhdfs-site.xmlжаЕФСНИіВЮЪ§РДПижЦЁЃ
-
dfs.namenode.checkpoint.periodЃКДЅЗЂcheckpointЕФжмЦкГЄЖШЃЌФЌШЯЮЊ1аЁЪБЁЃ -
dfs.namenode.checkpoint.txnsЃКСНДЮcheckpointжЎМфзюДѓдЪаэНјааЕФЪТЮёЪ§ЃЈМДedit logЕФдіСПЬѕЪ§ЃЉЃЌФЌШЯЮЊ100ЭђЁЃ
жЛвЊТњзуЩЯЪіСНИіВЮЪ§ЕФЬѕМўжЎвЛЃЌОЭЛсДЅЗЂcheckpointЙ§ГЬЃЌа№ЪіШчЯТЃК
- NNЩњГЩаТЕФedits_inprogressЮФМўЃЌКѓајЕФЪТЮёШежОНЋаДШыИУЮФМўжаЃЌжЎЧАе§дкаДЕФedit logЮФМўМДЮЊД§КЯВЂзДЬЌЁЃ
- НЋД§КЯВЂЕФedit logЮФМўКЭfsimageЮФМўвЛЦ№ИДжЦЕНSNNБОЕиЁЃ
- SNNЯёNNЦєЖЏЪБвЛбљЃЌНЋfsimageЮФМўМгдиЕНФкДцЃЌВЂжиЗХedit logЮФМўНјааКЯВЂЁЃЩњГЩКЯВЂНсЙћЮЊfsimage.chkpointЮФМўЁЃ
- SNNНЋfsimage.chkpointИДжЦЛиNNЃЌВЂжиУќУћЮЊе§ЪНЕФfsimageЮФМўУћЁЃ
HadoopЙйЗНИјГіЕФЭМЪОШчЯТЁЃЫфШЛЮФМўУћГЦВЛЭЌЃЌЕЋЫМЯыЪЧвЛбљЕФЁЃ
СэЭтЃЌЮЊСЫБмУтfsimageЮФМўеМгУЬЋЖрДХХЬПеМфЃЌЭЈЙ§dfs.namenode.num.checkpoints.retainedВЮЪ§ПЩвджИЖЈБЃСєЖрЩйИіfsimageЮФМўЃЌФЌШЯжЕЮЊ2ЁЃ
ШчЙћПЊЦєСЫNNИпПЩгУФиЃП
ЩЯУцЫЕЕФЖМЪЧМЏШКжЛгавЛИіNNЕФЧщПіЁЃШчЙћгаСНИіNNВЂЧвПЊЦєСЫHAЕФЛАЃЌSNNОЭУЛгУСЫЁЊЁЊcheckpointЙ§ГЬЛсжБНгНЛИјStandby NNРДИКд№ЁЃActive NNЛсНЋedit logЮФМўЭЌЪБаДЕНБОЕигыЙВЯэДцДЂЃЈQJMЗНАИОЭЪЧJournalNodeМЏШКЃЉЩЯШЅЃЌStandby NNДгJournalNodeМЏШКРШЁedit logЮФМўНјааКЯВЂЃЌВЂБЃГжfsimageЮФМўгыActive NNЕФЭЌВНЁЃ
NNИпПЩгУЕФЪЕЯждРэгжЪЧвЛИіживЊЕФЛАЬтЃЌПЩвдЫЕКмЖрЃЌдёШеСэЭтаДЮФеТЬжТлАЩЁЃ
УёФЧЭэАВЭэАВЁЃ