Foreword
截至当前,Flink作业的状态后端仍然只有Memory、FileSystem和RocksDB三种可选,且RocksDB是状态数据量较大(GB到TB级别)时的唯一选择。RocksDB的性能发挥非常仰赖调优,如果全部采用默认配置,读写性能有可能会很差。但是,RocksDB的配置也是极为复杂的,可调整的参数多达百个,没有放之四海而皆准的优化方案。如果仅考虑Flink状态存储这一方面,我们仍然可以总结出一些相对普适的优化思路。本文先介绍一些基础知识,再列举方法。
Note:本文的内容是基于我们在线上运行的Flink 1.9版本实践得出的。在1.10版本及以后,由于TaskManager内存模型重构(传送门),RocksDB内存默认成为了堆外托管内存的一部分,可以免去一些手动调整的麻烦。如果性能仍然不佳,需要干预,则必须将
state.backend.rocksdb.memory.managed参数设为false来禁用RocksDB内存托管。
State R/W on RocksDB
RocksDB作为Flink状态后端时的读写逻辑与一般情况略有不同,如下图所示。
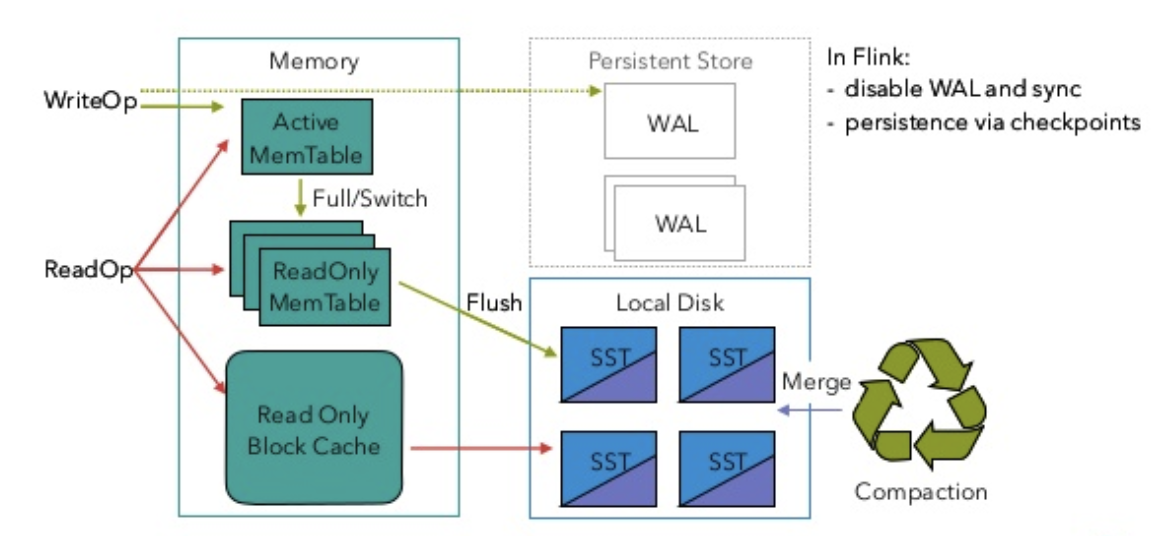
Flink作业中的每一个注册的状态都对应一个列族(column family),即包含自己独立的memtable和sstable集合。写操作会先将数据写入活动memtable,写满之后则会转换为不可变memtable,并flush到磁盘中形成sstable。读操作则会依次在活动memtable、不可变memtable、block cache和sstable中寻找目标数据。另外,sstable也需要通过compaction策略进行合并,最终形成分层的LSM Tree存储结构,老生常谈了。
特别地,由于Flink在每个检查点周期都会将RocksDB的数据快照持久化到文件系统,所以自然也就不需要再写预写日志(WAL)了,可以安全地关闭WAL与fsync。
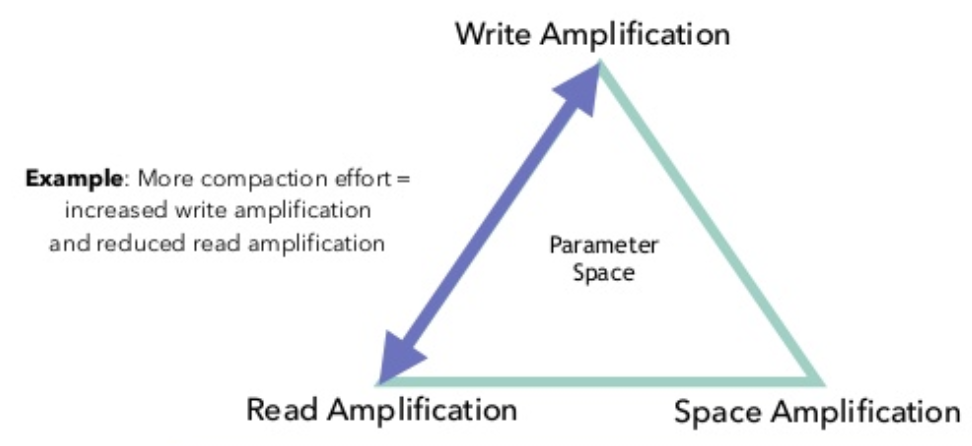
之前笔者已经详细讲解过RocksDB的compaction策略(传送门),并且提到了读放大、写放大和空间放大的概念,对RocksDB的调优本质上就是在这三个因子之间取得平衡。而在Flink作业这种注重实时性的场合,则要重点考虑读放大和写放大。
Tuning MemTable
memtable作为LSM Tree体系里的读写缓存,对写性能有较大的影响。以下是一些值得注意的参数。为方便对比,下文都会将RocksDB的原始参数名与Flink配置中的参数名一并列出,用竖线分割。
write_buffer_size|state.backend.rocksdb.writebuffer.size
单个memtable的大小,默认是64MB。当memtable大小达到此阈值时,就会被标记为不可变。一般来讲,适当增大这个参数可以减小写放大带来的影响,但同时会增大flush后L0、L1层的压力,所以还需要配合修改compaction参数,后面再提。max_write_buffer_number|state.backend.rocksdb.writebuffer.count
memtable的最大数量(包含活跃的和不可变的),默认是2。当全部memtable都写满但是flush速度较慢时,就会造成写停顿,所以如果内存充足或者使用的是机械硬盘,建议适当调大这个参数,如4。min_write_buffer_number_to_merge|state.backend.rocksdb.writebuffer.number-to-merge
在flush发生之前被合并的memtable最小数量,默认是1。举个例子,如果此参数设为2,那么当有至少两个不可变memtable时,才有可能触发flush(亦即如果只有一个不可变memtable,就会等待)。调大这个值的好处是可以使更多的更改在flush前就被合并,降低写放大,但同时又可能增加读放大,因为读取数据时要检查的memtable变多了。经测试,该参数设为2或3相对较好。
Tuning Block/Block Cache
block是sstable的基本存储单位。block cache则扮演读缓存的角色,采用LRU算法存储最近使用的block,对读性能有较大的影响。
block_size|state.backend.rocksdb.block.blocksize
block的大小,默认值为4KB。在生产环境中总是会适当调大一些,一般32KB比较合适,对于机械硬盘可以再增大到128~256KB,充分利用其顺序读取能力。但是需要注意,如果block大小增大而block cache大小不变,那么缓存的block数量会减少,无形中会增加读放大。block_cache_size|state.backend.rocksdb.block.cache-size
block cache的大小,默认为8MB。由上文所述的读写流程可知,较大的block cache可以有效避免热数据的读请求落到sstable上,所以若内存余量充足,建议设置到128MB甚至256MB,读性能会有非常明显的提升。
Tuning Compaction
compaction在所有基于LSM Tree的存储引擎中都是开销最大的操作,弄不好的话会非常容易阻塞读写。建议看官先读读前面那篇关于RocksDB的compaction策略的文章,获取一些背景知识,这里不再赘述。
compaction_style|state.backend.rocksdb.compaction.style
compaction算法,使用默认的LEVEL(即leveled compaction)即可,下面的参数也是基于此。target_file_size_base|state.backend.rocksdb.compaction.level.target-file-size-base
L1层单个sstable文件的大小阈值,默认值为64MB。每向上提升一级,阈值会乘以因子target_file_size_multiplier(但默认为1,即每级sstable最大都是相同的)。显然,增大此值可以降低compaction的频率,减少写放大,但是也会造成旧数据无法及时清理,从而增加读放大。此参数不太容易调整,一般不建议设为256MB以上。max_bytes_for_level_base|state.backend.rocksdb.compaction.level.max-size-level-base
L1层的数据总大小阈值,默认值为256MB。每向上提升一级,阈值会乘以因子max_bytes_for_level_multiplier(默认值为10)。由于上层的大小阈值都是以它为基础推算出来的,所以要小心调整。建议设为target_file_size_base的倍数,且不能太小,例如5~10倍。level_compaction_dynamic_level_bytes|state.backend.rocksdb.compaction.level.use-dynamic-size
这个参数之前讲过。当开启之后,上述阈值的乘法因子会变成除法因子,能够动态调整每层的数据量阈值,使得较多的数据可以落在最高一层,能够减少空间放大,整个LSM Tree的结构也会更稳定。对于机械硬盘的环境,强烈建议开启。
Generic Parameters
max_open_files|state.backend.rocksdb.files.open
顾名思义,是RocksDB实例能够打开的最大文件数,默认为-1,表示不限制。由于sstable的索引和布隆过滤器默认都会驻留内存,并占用文件描述符,所以如果此值太小,索引和布隆过滤器无法正常加载,就会严重拖累读取性能。max_background_compactions/max_background_flushes|state.backend.rocksdb.thread.num
后台负责flush和compaction的最大并发线程数,默认为1。注意Flink将这两个参数合二为一处理(对应DBOptions.setIncreaseParallelism()方法),鉴于flush和compaction都是相对重的操作,如果CPU余量比较充足,建议调大,在我们的实践中一般设为4。
The End
除了上述设置参数的方法之外,用户还可以通过实现ConfigurableRocksDBOptionsFactory接口,创建DBOptions和ColumnFamilyOptions实例来传入自定义参数,更加灵活一些。看官可参考Flink预先定义好的几个RocksDB参数集(位于PredefinedOptions枚举中)获取更多信息。
写得有点乱了,民那晚安晚安。