前言
假期马上就要过去了,还是写点什么找找状态比较好。翻看之前的文章,发现自己说过不少ZooKeeper的应用,但还没有真正涉及到它的原理,那么本文就找个切入点来聊聊吧。
Leader选举
众所周知,ZK是典型的Leader-Follower架构的分布式框架,通过ZooKeeper原子广播(ZooKeeper Atomic Broadcast, ZAB)协议来保证最终一致性。只有Leader能处理写请求,而Leader和Follower都能处理读请求。
一个ZK集群的示意图如下。注意图中没有Observer节点(即无投票权的Follower节点),无伤大雅。
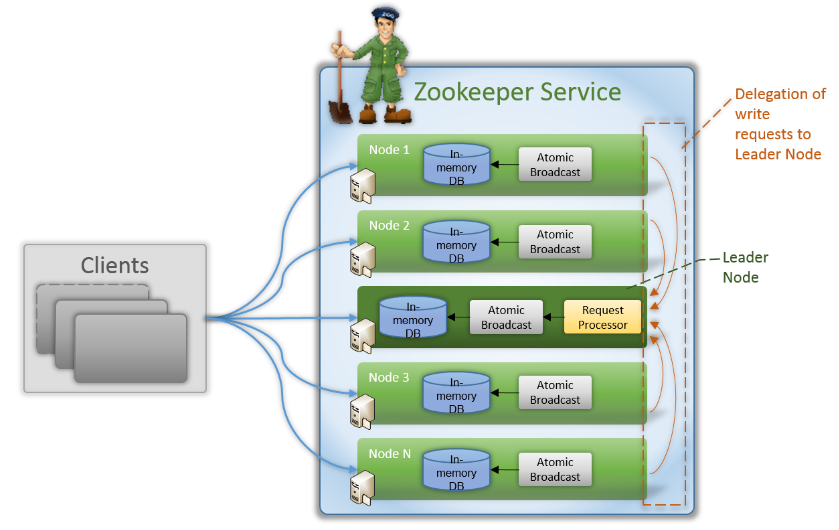
既然Leader在整个ZK集群中处于中心地位,那么在ZK集群启动时,需要由所有节点共同选举出Leader节点,才能正常提供服务。同理,如果当前Leader失败,也需要尽快推举出新的Leader节点,避免处于“群龙无首”的状态。ZAB协议的第0个阶段就是Leader选举,而具体到ZK的实现上,称为快速领导选举(Fast Leader Election)机制,如下图所示。

ZAB协议的恢复和广播阶段今后再提,本文重点分析Fast Leader Election的相关内容。作为预备,先介绍ZK节点状态及与选举相关的信息。
ZK节点状态
一个ZK节点可能处于以下4种状态之一,在源码中以QuorumPeer#ServerState枚举来定义。
- LOOKING:不确定Leader的“寻找”状态,即当前节点认为集群中没有Leader,进而发起选举;
- LEADING:“领导”状态,即当前节点就是Leader,并维护与Follower和Observer的通信;
- FOLLOWING:“跟随”状态,即当前节点是Follower,且正在保持与Leader的通信;
- OBSERVING:“观察”状态,即当前节点是Observer,且正在保持与Leader的通信,但是不参与Leader选举。
与选举相关的信息
这些信息体现在FastLeaderElection#Notification、FastLeaderElection#ToSend和Vote等数据结构中,看官可自行参考源码。
- electionEpoch:“选民”的选举轮次,在每个节点中以逻辑时钟logicalclock的形式存储。每发起一轮新的选举,该值会加1。若节点重启,此值会归零。
- sid:“选民”自己的服务器ID,是一个正整数,由各个ZK实例中的$dataDir/myid指定。
- state:“选民”的状态。
- votedLeaderSid:这一票推选的“候选人”的服务器ID。在代码中直接命名为leader,为了防止混淆,这里稍作更改。
- votedLeaderZxid:这一票推选的“候选人”的事务ID。所谓事务ID即写操作的proposal ID,其高32位是Leader纪元值,低32位是当前Leader纪元下的操作序号,亦即zxid肯定是单调递增的。在代码中直接命名为zxid,为了防止混淆,这里稍作更改。
- recvset:“选民”的票箱,其中存储有自己的和其他节点的选票。注意,每张选票都包含上述的electionEpoch、sid、state、leader和zxid信息,并且票箱中都只会记录每个“选民”的最近一次投票信息。
选举流程
Fas tLeader Election算法的主体位于FastLeaderElection#lookForLeader方法中,代码比较长,因此不贴出来了,只用文字叙述流程。
首先,自增本地的逻辑时钟logicalclock。
接下来给自己投一票(即该票中包含自己的sid、zxid等信息),并将该选票广播给其他节点。
投出这一票后,只要当前服务器处于LOOKING状态,就会循环执行收取其他选票、更新并广播自己的选票、计算投票结果的操作,直到可以确定Leader为止。具体叙述如下。
-
如果对方的状态也是LOOKING,说明两方都处于选举流程中(可能是集群刚刚启动,或者Leader掉线)——
- 若对方选票中的electionEpoch等于当前的logicalclock,说明当前节点与对方处于同一选举轮次,需要将对方的选票与自己刚才投出的票进行对比,看哪个候选Leader更优。规则是先比较事务ID(votedLeaderZxid),再比较服务器ID(votedLeaderSid),值较大的候选Leader更优。然后投更优的候选Leader一票,并广播出去。
- 若对方选票中的electionEpoch大于当前的logicalclock,说明当前节点的选举轮次已经滞后。此时将logicalclock更新为该选票的electionEpoch,并清空recvset(因为上一轮的选票已经没用了)。然后按照上一条的规则对比选票,并投出自己的新选票。
- 若对方选票中的electionEpoch小于当前的logicalclock,说明是对方滞后,忽略这一票。
- 将自己的选票和其他人的选票放入recvset中,并进行计票。如果收到了所有节点的选票,则直接认为选举结束,根据票数修改自己的状态为LEADING或FOLLOWING;如果没有收到所有选票,但已经过半(即满足Quorum原则),那么就等待一个较短的时期(默认200ms),如果选举的结果没有改变,则仍然认为选举已经结束,修改状态。这里我们只考虑数量,不考虑节点权重的问题。
-
如果对方的状态是LEADING/FOLLOWING,说明对方不处于选举流程中(可能是当前节点因故重启)——
- 若对方选票中的electionEpoch等于当前的logicalclock,说明选举结果已经出来了,将它们放入recvset。特别地,如果收到了对方称自己处于LEADING状态的票,则进行计票并检查该节点是否得到了过半数的支持。如是,说明Leader有效,修改自身状态为FOLLOWING并退出选举。
- 若对方选票中的electionEpoch不等于当前的logicalclock,说明在另一场选举中已经有了结果,只需听从该结果即可。这时需要将logicalclock直接设为对方的electionEpoch值,并将其他节点的选票放入一个旁路的outofelection集合并进行计票(顾名思义,这个集合只用来表征选举结果,不用于实际的选举流程),根据得出的结果修改自身状态,再结束选举。
可见,Fast Leader Election流程的本质就是每个节点通过不断做出最优的选择并进行广播,最终使所有节点对Leader和Follower角色的认知收敛到一致。
下面通过画图来演示上文所述的选举流程。
选举流程示例
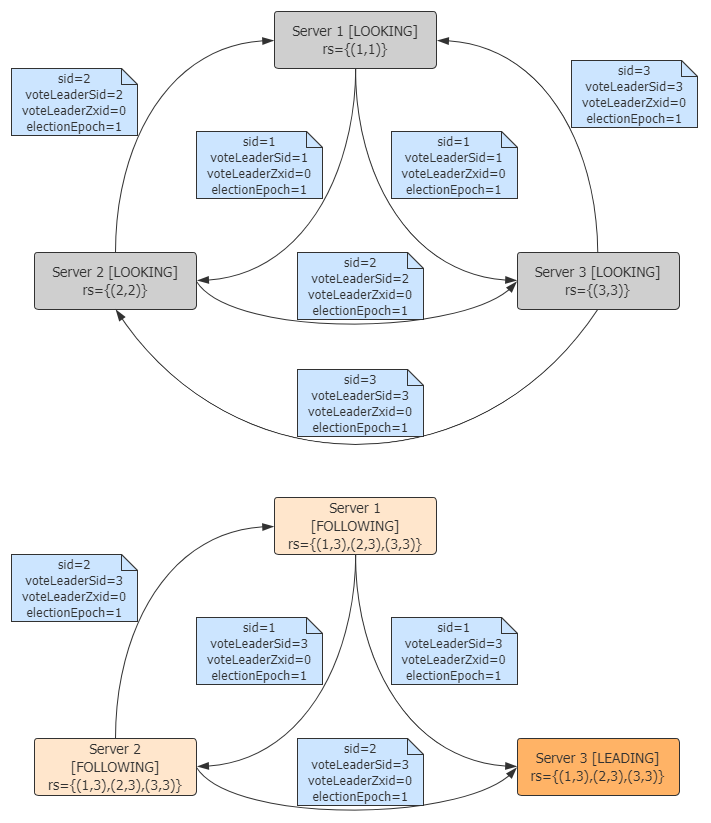
- 集群启动时
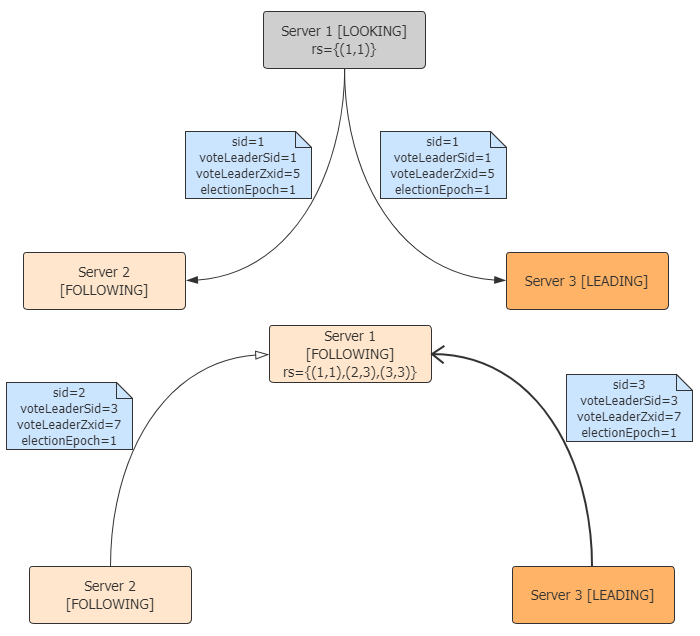
- Follower失败重启时
- Leader失败重启时的情况,就留给看官自行思考吧(因为笔者要去洗衣服了hhhhhhhhhh