Foreword
Flink SQL之所以简洁易用而功能强大,其中一个重要因素就是其拥有丰富的Connector(连接器)组件。Connector是Flink与外部系统交互的载体,并分为负责读取的Source和负责写入的Sink两大类。不过,Flink SQL内置的Connector有可能无法cover实际业务中的种种需求,需要我们自行定制。好在社区已经提供了一套标准化、易于扩展的体系,用户只要按照规范面向接口编程,就能轻松打造自己的Connector。本文就在现有Bahir Flink项目的基础上逐步实现一个SQL化的Redis Connector。
Introducing DynamicTableSource/Sink
当前(Flink 1.11+)Flink SQL Connector的架构简图如下所示,设计文档可参见FLIP-95。
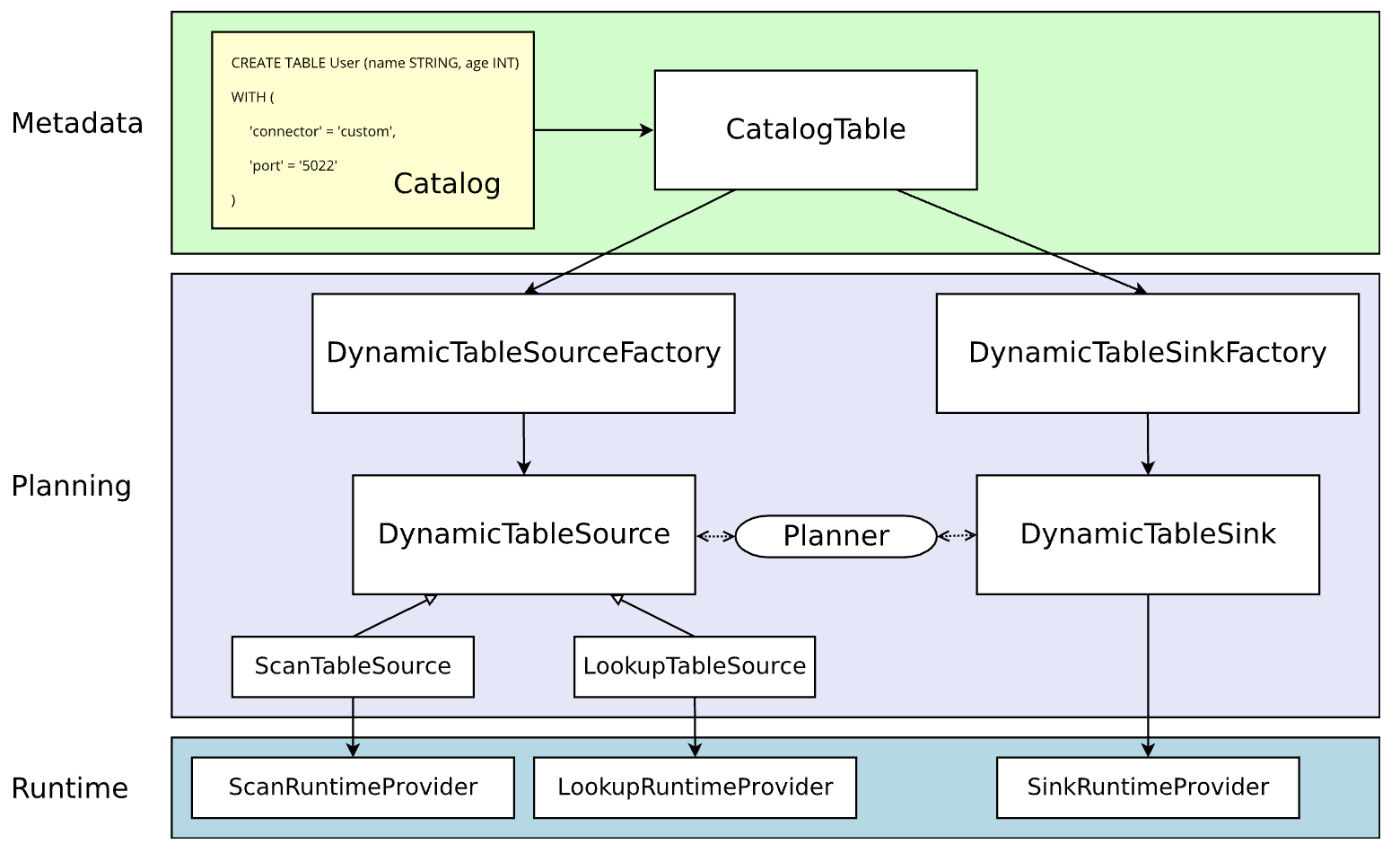
动态表(dynamic table)一直都是Flink SQL流批一体化的重要概念,也是上述架构中Planning阶段的核心。而自定义Connector的主要工作就是实现基于动态表的Source/Sink,还包括上游产生它的工厂,以及下游在Runtime阶段实际执行Source/Sink逻辑的RuntimeProvider。Metadata阶段的表元数据则由Catalog维护。
前方海量代码预警。
Implementing RedisDynamicTableFactory
DynamicTableFactory需要具备以下功能:
- 定义与校验建表时传入的各项参数;
- 获取表的元数据;
- 定义读写数据时的编码/解码格式(非必需);
- 创建可用的DynamicTable[Source/Sink]实例。
实现了DynamicTable[Source/Sink]Factory接口的工厂类骨架如下所示。
public class RedisDynamicTableFactory implements DynamicTableSourceFactory, DynamicTableSinkFactory {@Overridepublic DynamicTableSource createDynamicTableSource(Context context) { }@Overridepublic DynamicTableSink createDynamicTableSink(Context context) { }@Overridepublic String factoryIdentifier() { }@Overridepublic Set<ConfigOption<?>> requiredOptions() { }@Overridepublic Set<ConfigOption<?>> optionalOptions() { }
}首先来定义Redis Connector需要的各项参数,利用内置的ConfigOption/ConfigOptions类即可。它们的含义都很简单,不再赘述。
public static final ConfigOption<String> MODE = ConfigOptions.key("mode").stringType().defaultValue("single");public static final ConfigOption<String> SINGLE_HOST = ConfigOptions.key("single.host").stringType().defaultValue(Protocol.DEFAULT_HOST);public static final ConfigOption<Integer> SINGLE_PORT = ConfigOptions.key("single.port").intType().defaultValue(Protocol.DEFAULT_PORT);public static final ConfigOption<String> CLUSTER_NODES = ConfigOptions.key("cluster.nodes").stringType().noDefaultValue();public static final ConfigOption<String> SENTINEL_NODES = ConfigOptions.key("sentinel.nodes").stringType().noDefaultValue();public static final ConfigOption<String> SENTINEL_MASTER = ConfigOptions.key("sentinel.master").stringType().noDefaultValue();public static final ConfigOption<String> PASSWORD = ConfigOptions.key("password").stringType().noDefaultValue();public static final ConfigOption<String> COMMAND = ConfigOptions.key("command").stringType().noDefaultValue();public static final ConfigOption<Integer> DB_NUM = ConfigOptions.key("db-num").intType().defaultValue(Protocol.DEFAULT_DATABASE);public static final ConfigOption<Integer> TTL_SEC = ConfigOptions.key("ttl-sec").intType().noDefaultValue();public static final ConfigOption<Integer> CONNECTION_TIMEOUT_MS = ConfigOptions.key("connection.timeout-ms").intType().defaultValue(Protocol.DEFAULT_TIMEOUT);public static final ConfigOption<Integer> CONNECTION_MAX_TOTAL = ConfigOptions.key("connection.max-total").intType().defaultValue(GenericObjectPoolConfig.DEFAULT_MAX_TOTAL);public static final ConfigOption<Integer> CONNECTION_MAX_IDLE = ConfigOptions.key("connection.max-idle").intType().defaultValue(GenericObjectPoolConfig.DEFAULT_MAX_IDLE);public static final ConfigOption<Boolean> CONNECTION_TEST_ON_BORROW = ConfigOptions.key("connection.test-on-borrow").booleanType().defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_ON_BORROW);public static final ConfigOption<Boolean> CONNECTION_TEST_ON_RETURN = ConfigOptions.key("connection.test-on-return").booleanType().defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_ON_RETURN);public static final ConfigOption<Boolean> CONNECTION_TEST_WHILE_IDLE = ConfigOptions.key("connection.test-while-idle").booleanType().defaultValue(GenericObjectPoolConfig.DEFAULT_TEST_WHILE_IDLE);public static final ConfigOption<String> LOOKUP_ADDITIONAL_KEY = ConfigOptions.key("lookup.additional-key").stringType().noDefaultValue();public static final ConfigOption<Integer> LOOKUP_CACHE_MAX_ROWS = ConfigOptions.key("lookup.cache.max-rows").intType().defaultValue(-1);public static final ConfigOption<Integer> LOOKUP_CACHE_TTL_SEC = ConfigOptions.key("lookup.cache.ttl-sec").intType().defaultValue(-1);接下来分别覆写requiredOptions()和optionalOptions()方法,它们分别返回Connector的必需参数集合和可选参数集合。
@Overridepublic Set<ConfigOption<?>> requiredOptions() {Set<ConfigOption<?>> requiredOptions = new HashSet<>();requiredOptions.add(MODE);requiredOptions.add(COMMAND);return requiredOptions;}@Overridepublic Set<ConfigOption<?>> optionalOptions() {Set<ConfigOption<?>> optionalOptions = new HashSet<>();optionalOptions.add(SINGLE_HOST);optionalOptions.add(SINGLE_PORT);// 其他14个参数略去......optionalOptions.add(LOOKUP_CACHE_TTL_SEC);return optionalOptions;}然后分别覆写createDynamicTableSource()与createDynamicTableSink()方法,创建DynamicTableSource和DynamicTableSink实例。在创建之前,我们可以利用内置的TableFactoryHelper工具类来校验传入的参数,当然也可以自己编写校验逻辑。另外,通过关联的上下文对象还能获取到表的元数据。代码如下,稍后会编写具体的Source/Sink类。
@Overridepublic DynamicTableSource createDynamicTableSource(Context context) {FactoryUtil.TableFactoryHelper helper = createTableFactoryHelper(this, context);helper.validate();ReadableConfig options = helper.getOptions();validateOptions(options);TableSchema schema = context.getCatalogTable().getSchema();return new RedisDynamicTableSource(options, schema);}@Overridepublic DynamicTableSink createDynamicTableSink(Context context) {FactoryUtil.TableFactoryHelper helper = createTableFactoryHelper(this, context);helper.validate();ReadableConfig options = helper.getOptions();validateOptions(options);TableSchema schema = context.getCatalogTable().getSchema();return new RedisDynamicTableSink(options, schema);}private void validateOptions(ReadableConfig options) {switch (options.get(MODE)) {case "single":if (StringUtils.isEmpty(options.get(SINGLE_HOST))) {throw new IllegalArgumentException("Parameter single.host must be provided in single mode");}break;case "cluster":if (StringUtils.isEmpty(options.get(CLUSTER_NODES))) {throw new IllegalArgumentException("Parameter cluster.nodes must be provided in cluster mode");}break;case "sentinel":if (StringUtils.isEmpty(options.get(SENTINEL_NODES)) || StringUtils.isEmpty(options.get(SENTINEL_MASTER))) {throw new IllegalArgumentException("Parameters sentinel.nodes and sentinel.master must be provided in sentinel mode");}break;default:throw new IllegalArgumentException("Invalid Redis mode. Must be single/cluster/sentinel");}}在factoryIdentifier()方法内指定工厂类的标识符,该标识符就是建表时必须填写的connector参数的值。
@Overridepublic String factoryIdentifier() {return "redis";}笔者在之前的文章中介绍过,Flink SQL采用Java SPI机制来发现与加载表工厂类。所以最后不要忘了classpath的META-INF/services目录下创建一个名为org.apache.flink.table.factories.Factory的文件,并写入我们自定义的工厂类的全限定名,如:org.apache.flink.streaming.connectors.redis.dynamic.RedisDynamicTableFactory。
Implementing RedisDynamicTableSink
Bahir Flink项目已经提供了基于DataStream API的RedisSink,我们可以利用它来直接构建RedisDynamicTableSink,减少重复工作。实现了DynamicTableSink接口的类骨架如下。
public class RedisDynamicTableSink implements DynamicTableSink {private final ReadableConfig options;private final TableSchema schema;public RedisDynamicTableSink(ReadableConfig options, TableSchema schema) {this.options = options;this.schema = schema;}@Overridepublic ChangelogMode getChangelogMode(ChangelogMode changelogMode) { }@Overridepublic SinkRuntimeProvider getSinkRuntimeProvider(Context context) { }@Overridepublic DynamicTableSink copy() { }@Overridepublic String asSummaryString() { }
}getChangelogMode()方法需要返回该Sink可以接受的change log行的类别。由于向Redis写入的数据可以是只追加的,也可以是带有回撤语义的(如各种聚合数据),因此支持INSERT、UPDATE_BEFORE和UPDATE_AFTER类别。
@Overridepublic ChangelogMode getChangelogMode(ChangelogMode changelogMode) {return ChangelogMode.newBuilder().addContainedKind(RowKind.INSERT).addContainedKind(RowKind.UPDATE_BEFORE).addContainedKind(RowKind.UPDATE_AFTER).build();}接下来需要实现SinkRuntimeProvider,即编写SinkFunction供底层运行时调用。由于RedisSink已经是现成的SinkFunction了,我们只需要写好通用的RedisMapper,顺便做一些前置的校验工作(如检查表的列数以及数据类型)即可。getSinkRuntimeProvider()方法与RedisMapper的代码如下,很容易理解。
@Overridepublic SinkRuntimeProvider getSinkRuntimeProvider(Context context) {Preconditions.checkNotNull(options, "No options supplied");FlinkJedisConfigBase jedisConfig = Util.getFlinkJedisConfig(options);Preconditions.checkNotNull(jedisConfig, "No Jedis config supplied");RedisCommand command = RedisCommand.valueOf(options.get(COMMAND).toUpperCase());int fieldCount = schema.getFieldCount();if (fieldCount != (needAdditionalKey(command) ? 3 : 2)) {throw new ValidationException("Redis sink only supports 2 or 3 columns");}DataType[] dataTypes = schema.getFieldDataTypes();for (int i = 0; i < fieldCount; i++) {if (!dataTypes[i].getLogicalType().getTypeRoot().equals(LogicalTypeRoot.VARCHAR)) {throw new ValidationException("Redis connector only supports STRING type");}}RedisMapper<RowData> mapper = new RedisRowDataMapper(options, command);RedisSink<RowData> redisSink = new RedisSink<>(jedisConfig, mapper);return SinkFunctionProvider.of(redisSink);}private static boolean needAdditionalKey(RedisCommand command) {return command.getRedisDataType() == RedisDataType.HASH || command.getRedisDataType() == RedisDataType.SORTED_SET;}public static final class RedisRowDataMapper implements RedisMapper<RowData> {private static final long serialVersionUID = 1L;private final ReadableConfig options;private final RedisCommand command;public RedisRowDataMapper(ReadableConfig options, RedisCommand command) {this.options = options;this.command = command;}@Overridepublic RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(command, "default-additional-key");}@Overridepublic String getKeyFromData(RowData data) {return data.getString(needAdditionalKey(command) ? 1 : 0).toString();}@Overridepublic String getValueFromData(RowData data) {return data.getString(needAdditionalKey(command) ? 2 : 1).toString();}@Overridepublic Optional<String> getAdditionalKey(RowData data) {return needAdditionalKey(command) ? Optional.of(data.getString(0).toString()) : Optional.empty();}@Overridepublic Optional<Integer> getAdditionalTTL(RowData data) {return options.getOptional(TTL_SEC);}}剩下的copy()和asSummaryString()方法就很简单了。
@Overridepublic DynamicTableSink copy() {return new RedisDynamicTableSink(options, schema);}@Overridepublic String asSummaryString() {return "Redis Dynamic Table Sink";}Implementing RedisDynamicTableSource
与DynamicTableSink不同,DynamicTableSource又根据其特性分为两类,即ScanTableSource和LookupTableSource。顾名思义,前者能够扫描外部系统中的所有或部分数据,并且支持谓词下推、分区下推之类的特性;而后者不会感知到外部系统中数据的全貌,而是根据一个或者多个key去执行点查询并返回结果。
考虑到在数仓体系中Redis一般作为维度库使用,因此我们需要实现的是LookupTableSource接口。实现该接口的RedisDynamicTableSource类如下所示,大体结构与Sink类似。
public class RedisDynamicTableSource implements LookupTableSource {private final ReadableConfig options;private final TableSchema schema;public RedisDynamicTableSource(ReadableConfig options, TableSchema schema) {this.options = options;this.schema = schema;}@Overridepublic LookupRuntimeProvider getLookupRuntimeProvider(LookupContext context) {Preconditions.checkArgument(context.getKeys().length == 1 && context.getKeys()[0].length == 1, "Redis source only supports lookup by single key");int fieldCount = schema.getFieldCount();if (fieldCount != 2) {throw new ValidationException("Redis source only supports 2 columns");}DataType[] dataTypes = schema.getFieldDataTypes();for (int i = 0; i < fieldCount; i++) {if (!dataTypes[i].getLogicalType().getTypeRoot().equals(LogicalTypeRoot.VARCHAR)) {throw new ValidationException("Redis connector only supports STRING type");}}return TableFunctionProvider.of(new RedisRowDataLookupFunction(options));}@Overridepublic DynamicTableSource copy() {return new RedisDynamicTableSource(options, schema);}@Overridepublic String asSummaryString() {return "Redis Dynamic Table Source";}
}根据Flink框架本身的要求,用于执行点查询的LookupRuntimeProvider必须是TableFunction(同步)或者AsyncTableFunction(异步)。由于Bahir Flink项目采用的Jedis是同步客户端,故本文只给出同步版本的实现,异步版本可以换用其他客户端(如Redisson或Vert.x Redis Client)。RedisRowDataLookupFunction的代码如下。
public static class RedisRowDataLookupFunction extends TableFunction<RowData> {private static final long serialVersionUID = 1L;private final ReadableConfig options;private final String command;private final String additionalKey;private final int cacheMaxRows;private final int cacheTtlSec;private RedisCommandsContainer commandsContainer;private transient Cache<RowData, RowData> cache;public RedisRowDataLookupFunction(ReadableConfig options) {Preconditions.checkNotNull(options, "No options supplied");this.options = options;command = options.get(COMMAND).toUpperCase();Preconditions.checkArgument(command.equals("GET") || command.equals("HGET"), "Redis table source only supports GET and HGET commands");additionalKey = options.get(LOOKUP_ADDITIONAL_KEY);cacheMaxRows = options.get(LOOKUP_CACHE_MAX_ROWS);cacheTtlSec = options.get(LOOKUP_CACHE_TTL_SEC);}@Overridepublic void open(FunctionContext context) throws Exception {super.open(context);FlinkJedisConfigBase jedisConfig = Util.getFlinkJedisConfig(options);commandsContainer = RedisCommandsContainerBuilder.build(jedisConfig);commandsContainer.open();if (cacheMaxRows > 0 && cacheTtlSec > 0) {cache = CacheBuilder.newBuilder().expireAfterWrite(cacheTtlSec, TimeUnit.SECONDS).maximumSize(cacheMaxRows).build();}}@Overridepublic void close() throws Exception {if (cache != null) {cache.invalidateAll();}if (commandsContainer != null) {commandsContainer.close();}super.close();}public void eval(Object obj) {RowData lookupKey = GenericRowData.of(obj);if (cache != null) {RowData cachedRow = cache.getIfPresent(lookupKey);if (cachedRow != null) {collect(cachedRow);return;}}StringData key = lookupKey.getString(0);String value = command.equals("GET") ? commandsContainer.get(key.toString()) : commandsContainer.hget(additionalKey, key.toString());RowData result = GenericRowData.of(key, StringData.fromString(value));cache.put(lookupKey, result);collect(result);}}有三点需要注意:
- Redis维度数据一般用String或Hash类型存储,因此命令支持GET与HGET。如果使用Hash类型,需要在参数中额外传入它的key,不能像Sink一样动态指定;
- 为了避免每来一条数据都请求Redis,需要设计缓存,上面利用的是Guava Cache。在Redis中查不到的数据也要缓存,防止穿透;
- TableFunction必须有一个签名为
eval(Object)或eval(Object...)的方法。在本例中实际输出的数据类型为ROW<STRING, STRING>,在Flink Table的类型体系中应表示为RowData(StringData, StringData)。
Using Redis SQL Connector
来实际应用一下吧。先创建一张表示Hash结构的Redis Sink表。
CREATE TABLE rtdw_dws.redis_test_order_stat_dashboard (hashKey STRING,cityId STRING,data STRING,PRIMARY KEY (hashKey) NOT ENFORCED
) WITH ('connector' = 'redis','mode' = 'single','single.host' = '172.16.200.124','single.port' = '6379','db-num' = '10','command' = 'HSET','ttl-sec' = '86400','connection.max-total' = '5','connection.timeout-ms' = '5000','connection.test-while-idle' = 'true'
)然后读取Kafka中的订单流,统计一些简单的数据,并写入Redis。
/*
tableEnvConfig.setBoolean("table.dynamic-table-options.enabled", true)
tableEnvConfig.setBoolean("table.exec.emit.early-fire.enabled", true)
tableEnvConfig.setString("table.exec.emit.early-fire.delay", "5s")
tableEnv.createTemporarySystemFunction("MapToJsonString", classOf[MapToJsonString])
*/
INSERT INTO rtdw_dws.redis_test_order_stat_dashboard
SELECTCONCAT('dashboard:city_stat:', p.orderDay) AS hashKey,CAST(p.cityId AS STRING) AS cityId,MapToJsonString(MAP['subOrderNum', CAST(p.subOrderNum AS STRING),'buyerNum', CAST(p.buyerNum AS STRING),'gmv', CAST(p.gmv AS STRING)]) AS data
FROM (SELECTcityId,SUBSTR(tss, 0, 10) AS orderDay,COUNT(1) AS subOrderNum,COUNT(DISTINCT userId) AS buyerNum,SUM(quantity * merchandisePrice) AS gmvFROM rtdw_dwd.kafka_order_done_log /*+ OPTIONS('scan.startup.mode'='latest-offset','properties.group.id'='fsql_redis_test_order_stat_dashboard') */GROUP BY TUMBLE(procTime, INTERVAL '1' DAY), cityId, SUBSTR(tss, 0, 10)
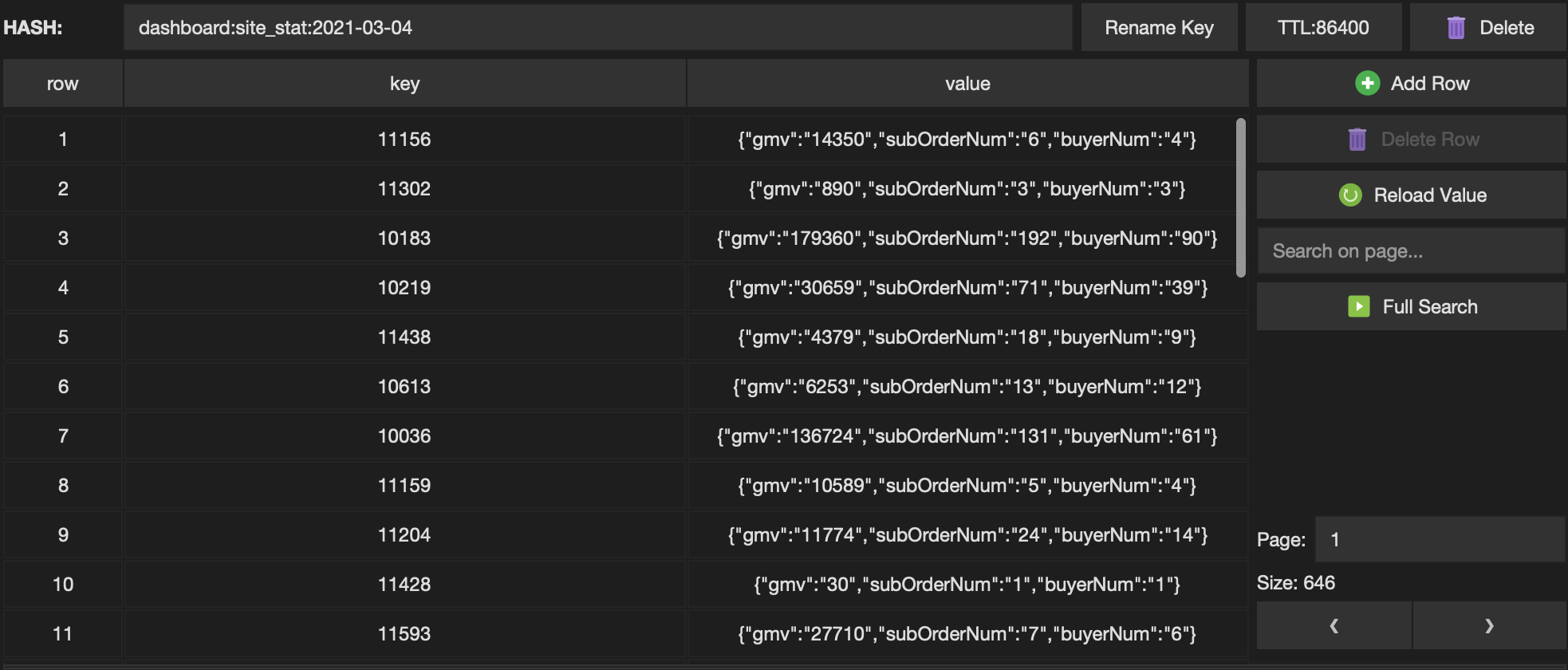
) p观察结果~
再看一下Redis作为维度表的使用,仍然以Hash结构为例。
CREATE TABLE rtdw_dim.redis_test_city_info (cityId STRING,cityName STRING
) WITH ('connector' = 'redis','mode' = 'single','single.host' = '172.16.200.124','single.port' = '6379','db-num' = '9','command' = 'HGET','connection.timeout-ms' = '5000','connection.test-while-idle' = 'true','lookup.additional-key' = 'rtdw_dim:test_city_info','lookup.cache.max-rows' = '1000','lookup.cache.ttl-sec' = '600'
)为了方便观察结果,创建一张Print Sink表输出数据,然后将Kafka流表与Redis维表做Temporal Join,SQL语句如下。
CREATE TABLE test.print_redis_test_dim_join (tss STRING,cityId BIGINT,cityName STRING
) WITH ('connector' = 'print'
)INSERT INTO test.print_redis_test_dim_join
SELECT a.tss, a.cityId, b.cityName
FROM rtdw_dwd.kafka_order_done_log /*+ OPTIONS('scan.startup.mode'='latest-offset','properties.group.id'='fsql_redis_source_test') */ AS a
LEFT JOIN rtdw_dim.redis_test_city_info FOR SYSTEM_TIME AS OF a.procTime AS b ON CAST(a.cityId AS STRING) = b.cityId
WHERE a.orderType = 12查看输出~
4> +I(2021-03-04 20:44:48,10264,漳州市)
3> +I(2021-03-04 20:45:26,10030,常德市)
4> +I(2021-03-04 20:45:23,10332,桂林市)
7> +I(2021-03-04 20:45:26,10031,九江市)
9> +I(2021-03-04 20:45:23,10387,惠州市)
4> +I(2021-03-04 20:45:19,10607,芜湖市)
3> +I(2021-03-04 20:45:25,10364,无锡市)The End
通过上面的示例,相信看官已经能够根据自己的需求灵活地定制Flink SQL Connector了。本文未详述的ScanTableSource、异步LookupTableSource和Encoding/Decoding Format也会在之后的文章中择机讲解。
最近春寒料峭,民那注意增减衣物。
晚安晚安。