前言
为了解决Flink作业使用RocksDB状态后端时的内存超用问题,Flink早在1.10版本就实现了RocksDB的托管内存(managed memory)机制。用户只需启用state.backend.rocksdb.memory.managed参数(默认即为true),再设定合适的TaskManager托管内存比例taskmanager.memory.managed.fraction,即可满足多数情况的需要。
关于RocksDB使用托管内存,Flink官方文档给出了一段简短的解释:
Flink does not directly manage RocksDB’s native memory allocations, but configures RocksDB in a certain way to ensure it uses exactly as much memory as Flink has for its managed memory budget. This is done on a per-slot level (managed memory is accounted per slot).
To set the total memory usage of RocksDB instance(s), Flink leverages a shared cache and write buffer manager among all instances in a single slot. The shared cache will place an upper limit on the three components that use the majority of memory in RocksDB: block cache, index and bloom filters, and MemTables.
本文先简单介绍一下RocksDB(版本5.17.2)内部的Cache和Write Buffer Manager这两个组件,然后看一眼Flink是如何借助它们来实现RocksDB内存托管的。
[LRU]Cache
Cache组件负责管理Block Cache,在RocksDB中的实现有两种,分别对应两种常用的缓存置换算法:LRUCache和ClockCache。由于ClockCache目前仍有bug,所以在生产环境总是使用默认的LRUCache。注意Cache有压缩的和非压缩的两种,这里只考虑默认的非压缩Cache。
LRUCache最核心的四个参数列举如下:
-
capacity:缓存的总大小。 -
num_shard_bits:按2num_shard_bits的规则确定整个缓存区域的分片(CacheShard)总数,也就是分片编号的比特数。每个CacheShard均分缓存容量,读写时,会根据key哈希值的高num_shard_bits位来确定路由。 -
strict_capacity_limit:是否严格控制单个缓存分片的容量限制,默认为false。RocksDB的Iterator在遍历数据时,会将它要读取的一部分块暂时固定在Cache内,称为Iterator-pinned blocks。如果Iterator-pinned blocks的大小超过了分片容量,再插入数据就有造成OOM的风险。开启这个参数后,超额的缓存写入就会直接失败。 -
high_pri_pool_ratio:高优先级缓存区域占整个Cache的比例。所谓高优先级缓存一般是指SST文件索引和布隆过滤器对应的块,通过cache_index_and_filter_blocks和cache_index_and_filter_blocks_with_high_priority参数控制。
笔者之前讲过实现LRU缓存的经典数据结构,即哈希表+双链表(参见《手撕一个LRU Cache》)。RocksDB的LRUCache也是以这种思路为基础实现,简单的示意图如下。

每个缓存分片LRUCacheShard都有一套哈希表+循环双链表的结构。哈希表称为LRUHandleTable,是RocksDB自己实现的链地址法分桶,且每个分片上都有互斥锁,整体与JDK中的旧版ConcurrentHashMap非常相似。哈希桶的扩容和缩容也是按照2的幂次,并且会尽量保证扁平(即每个桶中尽量只有1个元素)。
一个低优先级指针(图中Low-Pri)用于指示低优先级区域与高优先级区域的边界。如果高优先级LRUHandle的量超过了high_pri_pool_ratio比例规定的量,就会将溢出的高优先级LRUHandle降格成低优先级。当然,淘汰LRUHandle时也是从低优先级区域开始淘汰。
LRUHandle是LRUCache的最小单元,其key是SST文件的ID加上块在SST内的偏移量,value则是缓存的块数据(代码中为void*类型),另外还有数据大小、指针域和引用计数域等。
为什么要有引用计数呢?因为RocksDB的实现方法与传统结构略有不同,链表中保存的并不是全部LRUHandle,而是可以被淘汰的那些LRUHandle,“可以被淘汰”的标准就是LRUHandle的引用计数为1——只有哈希表中存在,而没有外部引用者。也就是说,如果LRUHandle在链表中,那么一定在哈希表中,反之则不成立。
Write Buffer Manager(WBM)
顾名思义,Write Buffer Manager(以下简称WBM)是用来管理写缓存的组件。除了负责MemTable分配、Flush等细节,我们所关注的另一个作用则是追踪和控制MemTable的内存用量,它可以以两种形式生效:
- 传入一个设定的阈值,WBM将多个列族或RocksDB实例的MemTable总大小限制在阈值内;
- 将WBM传给Cache,可以使两者共同控制RocksDB总内存占用量的上限。
Flink也正是利用了上述特性来实现RocksDB托管内存的。那么WBM与Cache如何协同工作?如下图所示。
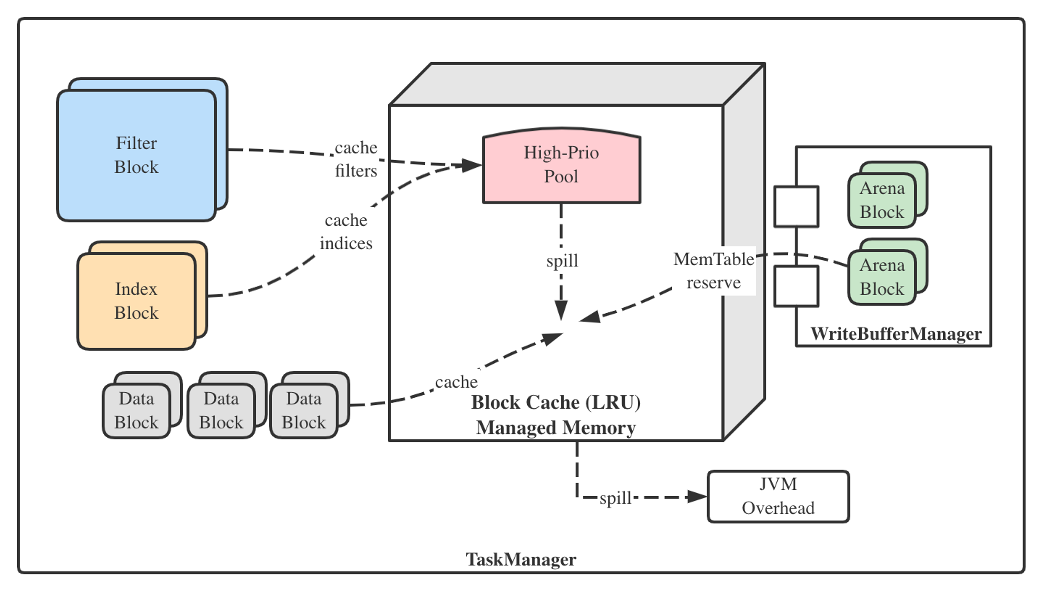
RocksDB Wiki中用了一句不符合英语语法的话来描述,即"Cost memory used in memtable to block cache",此时Block Cache的内存配额就是RocksDB全部的内存配额。
MemTable的分配单元称为Arena Block,默认大小为8MB。每分配一个Arena Block,WBM就会将它的内存消耗向LRUCache记账——所谓“记账”就是向Cache的低优先级区域内写入Dummy LRUHandle。这些LRUHandle没有value,只有key,但携带有Arena Block的内存消耗,且每个Dummy LRUHandle代表1MB的空间。也就是说它们仅占用了逻辑配额,并未占用物理空间,并且同样受Cache的LRU规则的控制。由于MemTable本身既是读缓存也是写缓存,所以把它和Block Cache统一起来倒也合理。
WBM控制下的MemTable Flush策略也变得更加激进了一些:
- 当可变MemTable的大小超过WBM可用内存配额的7 / 8时,会触发Flush;
- 当所有MemTable的大小超过内存配额,且可变MemTable的大小超过配额的一半时,也会触发Flush。
下面来简单看看Flink是如何利用WBM和Cache的。
To RocksDB Backend
直接上源码,即org.apache.flink.contrib.streaming.state.RocksDBMemoryControllerUtils类。
public class RocksDBMemoryControllerUtils {public static RocksDBSharedResources allocateRocksDBSharedResources(long totalMemorySize, double writeBufferRatio, double highPriorityPoolRatio) {long calculatedCacheCapacity =RocksDBMemoryControllerUtils.calculateActualCacheCapacity(totalMemorySize, writeBufferRatio);final Cache cache =RocksDBMemoryControllerUtils.createCache(calculatedCacheCapacity, highPriorityPoolRatio);long writeBufferManagerCapacity =RocksDBMemoryControllerUtils.calculateWriteBufferManagerCapacity(totalMemorySize, writeBufferRatio);final WriteBufferManager wbm =RocksDBMemoryControllerUtils.createWriteBufferManager(writeBufferManagerCapacity, cache);return new RocksDBSharedResources(cache, wbm, writeBufferManagerCapacity);}@VisibleForTestingstatic long calculateActualCacheCapacity(long totalMemorySize, double writeBufferRatio) {return (long) ((3 - writeBufferRatio) * totalMemorySize / 3);}@VisibleForTestingstatic long calculateWriteBufferManagerCapacity(long totalMemorySize, double writeBufferRatio) {return (long) (2 * totalMemorySize * writeBufferRatio / 3);}@VisibleForTestingstatic Cache createCache(long cacheCapacity, double highPriorityPoolRatio) {// TODO use strict capacity limit until FLINK-15532 resolvedreturn new LRUCache(cacheCapacity, -1, false, highPriorityPoolRatio);}@VisibleForTestingstatic WriteBufferManager createWriteBufferManager(long writeBufferManagerCapacity, Cache cache) {return new WriteBufferManager(writeBufferManagerCapacity, cache);}static long calculateRocksDBDefaultArenaBlockSize(long writeBufferSize) {long arenaBlockSize = writeBufferSize / 8;// Align up to 4kfinal long align = 4 * 1024;return ((arenaBlockSize + align - 1) / align) * align;}static long calculateRocksDBMutableLimit(long bufferSize) {return bufferSize * 7 / 8;}@VisibleForTestingstatic boolean validateArenaBlockSize(long arenaBlockSize, long mutableLimit) {return arenaBlockSize <= mutableLimit;}
}其中的writeBufferRatio就是state.backend.rocksdb.write-buffer-ratio参数,表示MemTable占托管内存(即Block Cache)的比例,默认0.5。同理,highPriorityPoolRatio就是state.backend.memory.high-prio-pool-ratio参数,表示高优先级内存占托管内存的比例,默认0.1。
托管内存在TaskManager的Slot之间平均分配,每个Slot都会有一组Cache和WBM。需要特别注意,实际的Cache和WBM配额是:
cache_capacity = (3 - write_buffer_ratio) * total_memory_size / 3
write_buffer_manager_capacity = 2 * total_memory_size * write_buffer_ratio / 3也就是说,如果TM总的托管内存的大小是3GB,默认比例下的Block Cache大小其实是2.5GB,MemTable配额其实是1GB,都略偏小一些。这是因为FLINK-15532尚未解决,strict_capacity_limit在Flink的场景下暂时不能生效,所以要留出一部分缓冲。推算的依据就是上一节提到的MemTable Flush策略,具体的关系如下:
write_buffer_manager_memory = 1.5 * write_buffer_manager_capacity
write_buffer_manager_memory = total_memory_size * write_buffer_ratio
write_buffer_manager_memory + other_part = total_memory_size
write_buffer_manager_capacity + other_part = cache_capacityThe End
写的很潦草,就这样吧。
下班跑路,民那晚安。