使用多任务级联卷积网络的联合人脸检测和对准
作者:张凯鹏,张展鹏,李志峰,IEEE高级会员,余乔,IEEE高级会员
摘要
由于姿势、光照或遮挡等原因,在非强迫环境下的人脸识别和对齐是一项具有挑战性的问题。最近的研究显示,深度学习算法可以很好的解决上述的两个问题。在这篇文章中,我们利用检测和校准之间固有的相关性在深度级联的多任务框架下来提升它们的性能。尤其是,我们利用三层级联架构结合精心设计的卷神经网络算法,来对人脸进行检测和关键点的粗略定位。另外,我们建议使用一种新的在线采集样本策略来改善算法的性能。我们的方法与FDDB和WIDER FACE数据集上最先进的人脸检测算法进行对比,具有更高的精度。同时,与AFLW上人脸对齐算法比较,实时性能良好
关键词:人脸检测,人脸对齐,级联卷积神经网络
一、介绍
ACE检测和对齐对于许多人脸应用来说至关重要,例如人脸识别和面部表情分析。 但是,在实际应用中,脸部大幅度的视觉变化,例如遮挡、大幅度的姿态变化和极端照明条件等都会这些任务带来巨大的挑战。Viola和Jones提出的级联人脸检测器,利用Haar-Like特性和AdaBoost来训练级联分类器,在实时性方面获得了良好的性能。 然而,不少工作表明,即使具有更高级的特征和分类器,这种探测器在人类面部具有Viola和Jones提出的级联人脸检测器利用Haar-Like特性和AdaBoost来训练级联分类器,实现了实时效率的良好性能。 然而,不少作品表明,即使具有更高级的特征和分类器,这种检测器在人类面部具有较大程度的视觉变化下的实际应用中也会显著退化。 除了级联结构之外,还引入了用于人脸检测的可变形部件模型(DPM),并取得了显著的性能。 然而,它们在计算上是昂贵的,并且在训练阶段通常可能需要昂贵的注释。
最近,卷积神经网络(CNN)在诸如图像分类和人脸识别等各种计算机视觉任务中取得了显著的进步。 受深度学习方法在计算机视觉任务中取得显著成功的启发,一些研究学者利用深度CNN进行人脸检测。 杨等人训练用于面部属性识别的深度卷积神经网络,以在面部区域获得高响应,然后进一步产生候选的人脸窗口。 但是,由于其复杂的CNN结构,这种方法在实践中耗费大量时间。 Li等人使用级联的CNN进行人脸检测,但是它需要从面部检测中进行边界框校准并带来额外的计算开销,同时忽略了面部标志定位和边界框回归之间的固有相关性。
人脸对齐也吸引了广泛的研究兴趣,这方面的研究大致可以分为两类,即基于回归的方法和基于模板拟合的方法。最近,张等人提出使用面部属性识别作为辅助任务来增强使用深度卷积神经网络的人脸对准性能。然而,大多数以前的人脸检测和人脸对齐方法忽略了这两个任务之间的固有关联。 虽然现有的几部作品试图联合解决这些问题,但这些作品仍然存在局限性。 例如,Chen等人利用像素值差异特征共同进行随机森林的对齐和检测。 但是,仍然限制了其性能。 Zhang等人使用多任务CNN来提高多视角人脸检测的准确性,但检测回馈受到弱脸检测器产生的初始检测窗口的限制。另一方面,在训练中挖掘难样本对于增强检测器的能力至关重要。然而,传统的难样本采样通常采用离线方式进行,这显著增加了人工操作量。设计一种适用于当前训练状态的人脸检测的在线难样本挖掘方法是可取的。
在本文中,我么们提出新的级联架构来整合多任务卷积神经网络学习的问题。该算法有三个阶段组成:第一阶段,浅层的CNN快速产生候选窗体;第二阶段,通过更复杂的CNN精炼候选窗体,丢弃大量的重叠窗体;第三阶段,使用更加强大的CNN,实现候选窗体去留,同时显示五个面部关键点定位。
通过这个多任务学习框架,算法的性能可以显著提高。本文的主要贡献总结如下:
(1)我们提出了一种新的级联CNNs框架,用于联合人脸检测和对齐,并仔细设计了轻量级CNN架构以实现实时性能。(2)提出一种有效的在线难样本挖掘方法来提高性能。
(3)对具有挑战性的基准进行了大量的实验,与在面部检测和面部对准任务中最先进的技术相比,该方法显示出显著的性能改进。
二、方法
在本节中,我们将描述我们的联合人脸检测和对齐方法。
2.1 总体框架
我们的方法的总体流程如图1所示:
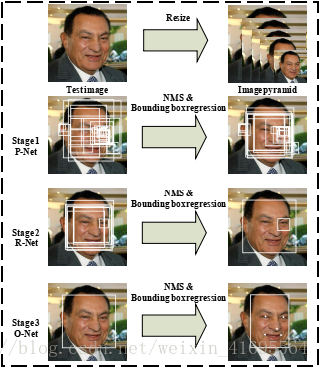
图1. 包含三阶段多任务深度卷积网络的级联框架的流水线。 首先,通过快速提取网络(P-Net)生成候选窗口。 之后,我们通过更精细的网络(R-Net)在下一阶段完善这些候选窗口。 在第三阶段,输出网络(O-Net)产生最终的边界框和面部标记位置。
给定一幅图像,我们首先调整它的大小以建立一个图像金字塔,这是以下三级级联框架的输入:
阶段1:我们利用完全卷积网络(称为建议网络(P-Net))获得候选面部窗口及其边界框回归向量。 然后基于估计的边界框回归向量校准候选窗口。 之后,我们采用非最大抑制(NMS)来合并高度重叠的候选窗口。
阶段2:所有候选窗口都被送到另一个叫做Refine Network(R-Net)的CNN,它进一步拒绝了大量错误的候选窗口,用边界框回归进行校准,并进行非最大抑制(NMS)。
阶段3:这个阶段与第二阶段相似,但在这个阶段我们的目标是通过更多的监督来识别人脸区域。 特别是,该网络将输出五个面部目标的位置。
2.2 CNN网络结构
其中,多个CNN被设计用于人脸检测。但是,我们注意到它的性能可能受到以下事实的限制:
(1)卷积层中的一些滤波器缺少可能限制其区分能力的多样性。
(2)与其他多类目标检测和分类任务相比,人脸检测是一项具有挑战性的二值分类任务,因此每层滤波器的数量可能会减少。为此,我们减少滤波器数量并将5×5滤波器更改为3×3滤波器,以减少计算量,同时增加深度以获得更好的性能。
通过这些改进,与之前的架构相比,我们可以在更少的运行时间内获得更好的性能(训练阶段的结果如表1所示。为了公平比较,我们在每个组中使用相同的训练和验证数据)。我们的CNN网络结构如图2所示。我们将PReLU应用于卷积和完全连接层(输出层除外)之后作为非线性激活函数。
表一 我们的CNNS和以前的CNNS在速度与验证准确性上面的比较
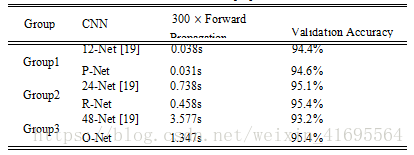
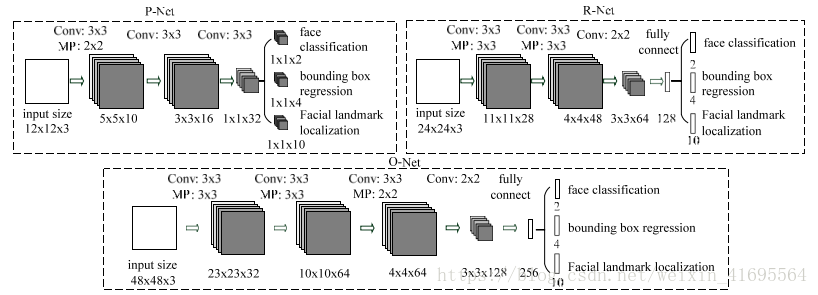
图2 P-Net,R-Net和O-Net的结构,其中“MP”表示最大池化层,“Conv”表示卷积层。 卷积和池化操作的步长分别为1和2。
2.3 训练
我们利用三项任务来训练我们的CNN检测器:面部/非面部分类,边界框回归和面部标志定位。
1)脸部分类:学习目标表述为一个两级分类问题。 对于每个样本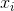 ,我们使用交叉熵损失:
,我们使用交叉熵损失:
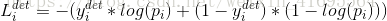
其中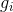 是由网络产生的表示样本
是由网络产生的表示样本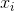 是人脸的概率。 符号
是人脸的概率。 符号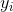 ∈{0,1}表示样本对应的真实标签。
∈{0,1}表示样本对应的真实标签。
2)边界框回归:对于每个候选窗口,我们预测它与最近的真实标签值之间的偏移(即边界框的左边,顶边,高度和宽度)。 学习目标被形容成为一个回归问题,我们使用每个样本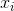 的欧几里德损失:
的欧几里德损失:
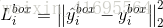
其中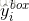 是从卷积神经网络中获得的回归目标,
是从卷积神经网络中获得的回归目标,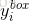 是样本对应的真实坐标。 该真实坐标有四个坐标值,包括左上角坐标值、高度以及宽度值,因此
是样本对应的真实坐标。 该真实坐标有四个坐标值,包括左上角坐标值、高度以及宽度值,因此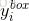 ∈?4。
∈?4。
3)面部关键点定位:与边界框回归任务类似,将面部标志检测表示为回归问题,我们将欧几里得损失最小化:
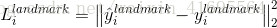
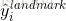 是从卷积神经网络中获得的面部标志的坐标,
是从卷积神经网络中获得的面部标志的坐标,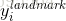 是第
是第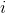 个样本对应的真实面部关键点坐标。该真实面部关键点坐标包括左眼、右眼、鼻子、左嘴角和右嘴角等坐标,因此
个样本对应的真实面部关键点坐标。该真实面部关键点坐标包括左眼、右眼、鼻子、左嘴角和右嘴角等坐标,因此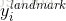 ∈?10。
∈?10。
4)多源训练:由于我们在每个CNN中完成不同的任务,所以在学习过程中存在不同类型的训练图像,如人脸,非人脸和部分对齐人脸。 在这种情况下,上面列出的三个损失函数将不会使用。 例如,对于背景区域的样本,我们只计算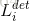 ,另外两个损失设置为0,这可以直接使用样本类型指标来实现。
,另外两个损失设置为0,这可以直接使用样本类型指标来实现。
5)在线难样本挖掘:与原始分类器训练完成后进行传统难样本挖掘不同,我们在适应训练过程的人脸/非人脸分类任务中进行在线难样本挖掘。特别是,在每个小样本批次中,我们对从所有样本向前传播中计算出的损失进行排序,并选择最高的70%作为难样本。 然后我们只计算这些反向传播中难样本的梯度。 这意味着我们忽略了在训练期间加强检测器的帮助不大的简单样本。 实验表明,这种策略在没有手动样本选择的情况下获得更好的性能,第三部分证明了它的有效性。
三、实验
在本节中,我们首先评估所提出的难样本挖掘策略的有效性。 然后,我们将我们的人脸检测器与人脸检测数据集FDDB、WIDER FACE和AFLW上的最新方法进行比较。 FDDB数据集包含一组2,845个图像中的5,171个面的注释。 WIDER FACE数据集包含32203张图像中的393703个带标签的边界框,其中50%用于测试(根据图像的难度分为三个子集),40%用于训练,其余用于验证。 AFLW包含24386个面的面部标志注释,我们使用与之相同的测试子集。 最后,我们评估我们的人脸检测器的计算效率。
3.1 训练数据
由于我们共同执行人脸检测和对齐,因此我们在训练过程中使用四种不同类型的数据注释:
(i)非人脸负样本:交并比(IoU)比率小于0.3的区域(在目标检测的评价体系中,有一个参数叫做IoU,简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。具体我们可以简单的理解为检测结果(DetectionResult)与 Ground Truth的交集比上它们的并集,即为检测的准确率 IoU);
(ii)人脸正样本:高于0.65的IoU;(iii)部分脸:在0.4至0.65之间的IoU;
(iv)人脸关键点:标记为左眼、右眼、鼻子、左嘴角和右嘴角等五个关键点的面孔。 部分脸和非人脸负样本之间的差距不明确,不同脸部标注之间存在差异。
所以我们选择0.3到0.4之间的IoU差距。 非人脸负样本和人脸正样本用于人脸分类任务,人脸正样本和部分人脸用于边界框回归,而人脸关键点用于人脸关键点定位。 总训练数据由3:1:1:2(非人脸负样本/人脸正样本/部分面/人脸关键点)数据组成。 每个网络的训练数据收集描述如下:
1)P-Net:我们随机地从WIDER FACE中裁剪出几个图片来收集正面,负面和部分脸部。 然后,我们将CelebA的脸部作为面部标记。
2)R-Net:我们使用我们框架的第一阶段检测WIDER FACE中的脸部来收集正面,负面和部分脸部,并检测CelebA中的面部标记。
3)O-Net:类似于R-Net收集数据,但我们使用框架的前两个阶段来检测人脸并收集数据。
3.2 在线难样本挖掘的有效性
为了评估所提出的在线难样本挖掘策略的贡献,我们训练两个P-Nets(有和没有在线难样本挖掘)并比较它们在FDDB上的表现。 图3(a)显示了在FDDB上两个不同P-Nets的结果。 很明显,在线难样本挖掘有利于提高性能,在FDDB可以使整体性能提高1.5%。
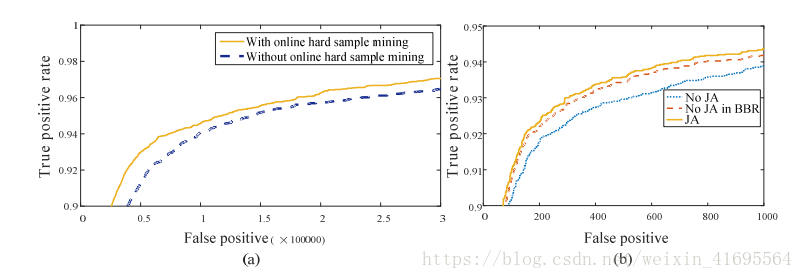
图3.(a)有和没有在线难样本挖掘的P-Net的检测性能。 (b)“JA”表示O-Net中的联合脸部对齐学习,而“No JA”表示不联合它。 “BBR中没有JA”表示使用“无JA”O-Net进行边界框回归。
3.3 联合人脸检测和对齐联合检测的有效性
为了评估联合检测和对齐的贡献,我们评估了的两个不同的O-Nets(联合面部标志回归学习并且不联合它)在FDDB(具有相同的P-Net和R-Net)上的性能。 我们还比较了这两个O-Nets中边界框回归的性能。 图3(b)表明,联合地标本地化任务学习有助于增强人脸分类和边界框回归任务。
3.4 人脸检测评估
为了评估我们的人脸检测方法的性能,我们将我们的方法与FDDB中的最新方法以及WIDER FACE中的最新方法进行了比较。 图4(a) - (d)表明,我们的方法在两个基准测试中始终优于所有比较方法。
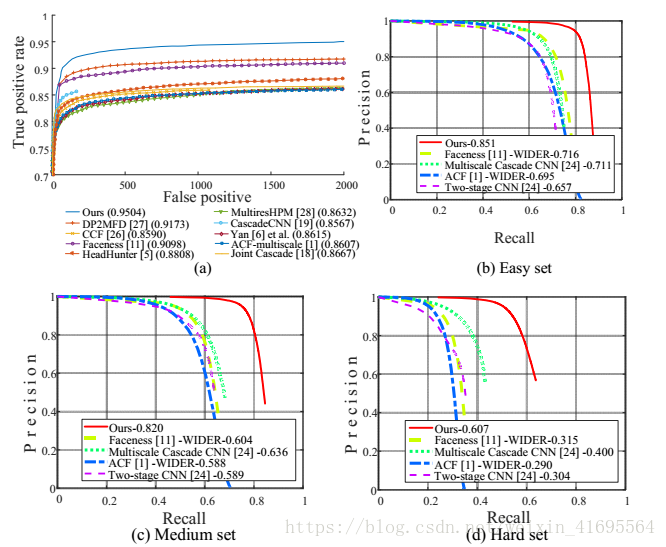
图4.(a)表示在FDDB上的评估。 (b-d)对WIDER FACE的三个子集进行评估。方法后面的数字表示平均准确度。
3.5 评估脸部对齐
在这一部分中,我们将我们的方法的人脸对齐性能与以下方法的性能进行比较:RCPR,TSPM,Luxand face SDK,ESR,CDM,SDM,和TCDCN。 平均误差通过估计值与真实值之间的距离来测量,并且相对于眼间距离进行归一化。 图5显示我们的方法优于所有具有余量的最先进的方法。 这也表明我们的方法在嘴角定位方面显示出较小的优势。 这可能是由于在我们的训练数据中,对嘴角位置有显著影响的表情变化很小。
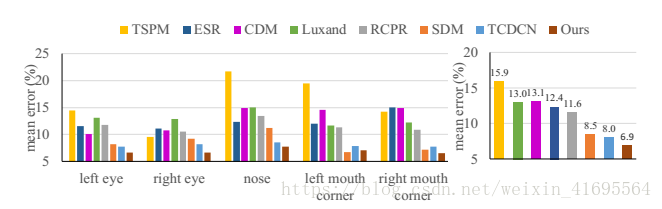
图5. 脸部对齐在AFLW上的评估
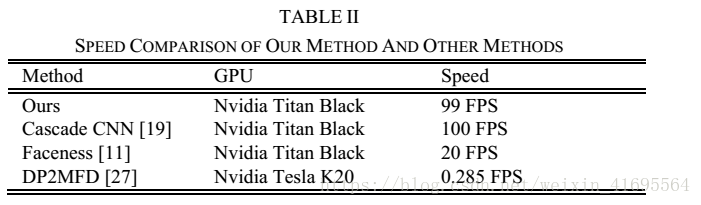
3.6 实时性能
鉴于级联结构,我们的方法可以在联合人脸检测和对齐方面实现高速。 我们将我们的方法与GPU上的最新技术进行比较,结果如表2所示。 注意到我们目前的实现是基于未经优化的MATLAB代码。
四、结论
在本文中,我们提出了一种基于CNNs的多任务级联联合人脸检测和对齐的框架。 实验结果表明,我们的方法始终在多个挑战性数据集(包括用于人脸检测的FDDB、WIDER FACE以及用于面部对齐的AFLW数据集)上面优于最先进的方法,同时对最小面部尺寸为20x20的640x480的VGA图像实现了实时性能 。性能改进的三个主要贡献是仔细设计级联CNN架构,在线难样本挖掘策略和联合人脸对齐学习。
论文下载地址: 点击打开链接