������������Ķ�
���˼��
������
�廪����,�������ݴ�ѧ��˹͡��У˶ʿ��ʮ������»���������ƽ̨���ֲ�ʽ��������ݴ洢�Ŀ����ͼ��������������Ⱥ���ְ���ܲ���eBay �� Twitter �ܲ���
��һֱ���º�̨�ĺ����ֲ�ʽ�����ݴ洢ϵͳ����ơ��з�����ά�������������տ�ʼ��ʱ���� SQL Server������ת������ Online Service Division (OSD)��
�� OSD �з��ֲ�ʽ�� In-Memory ���ݿ⣬��Ҫ��֧�������������ֹ��ϵͳ�����ϵͳ��Ҫ��ܸߣ�5������Ӧʱ�䣬������ QPS Ҫ��ʮ�����ϡ�����ȥ�� Twitter����Ҫ��ʵ Twitter �ķֲ�ʽ Key-Value ���ݿ���з�����ά��
һ������ɫɫ�����ݿ�
Twitter ����洢�ܹ�����������ϵͳ��
1��NoSql����Ҫ�����û���Ϣ���Ƚ�С�����֣���ʱ��Լ�������ڵ㡣
2.�����ļ�ϵͳ����Ҫ�Ǵ洢ͼƬ��video �ȴ������ļ����� NoSql ͬ����Ҳ���������ڵ㡣
3.��Hadoop ϵͳ����Ҫ���ں�̨���ݴ���������������ʱ���о�ǧ���ڵ����ҡ�
4.��MySQL�����Ƚϸ��ӵĹ�ϵ�����ݲ�ѯ
�������ݿ�� CAP
˵�����ݿ⣬���ò�˵�ľ��� CAP��CAP ��ʲô�أ�C����һ���ԡ�A�ǿ����ԡ�P���Ƿ����ݴ��ԡ�
Eric Brewer ֤������ CAP ���������У���ֻ��������������Զ�����������������������ݿ���Ƶ�ʱ���Ҫ����Ӧ�ó�����ʲô�������Ǹ�������ȡ����һ���������ԡ�
��ʵ�����е����ݿ⣬�����������˵����ݿⶼ������ CAP ԭ���������ij��Ӧ�ó������Ż���û��һ�����ͳʲô�����õ�ϵͳ��
�����Dz�ͬ�������ݿ�� CAP �ľ���

��ϵ�����ݿ⣬��ҪӦ���ڽ���ϵͳ����������ϵͳ���������ǿһ���Եģ�������A��
NoSql �ĺô��������ĸ߲������ܹ�֧�źܸߵIJ�����������һ�����Բ������һ�µġ�

NewSQL, �� google �� spanner �ų��ܹ�ͬʱ���� CAP ������ʵ�����Dz�ȡ��һЩ��ʩ����ǿ������ȶ��ԣ���������� partition �Ŀ����Խ��ͺܵ͡����������ϻ��� ����ͻ�� CAP��
������;�����ݿ⣻����ʱ�������͵� OpenTSDB���ĵ��͵� mongoDB �Լ�ͼ���ݿ� Neo4j �ȡ�
����Manhattan ��ǰ������

Twitter �����õ��� Cassandra������ cassandra û������ڵ㵼�²��ܲ��ֵ����ݣ����ڵ� Cassandra �Ѿ������ˡ�
�ڶ������� Cassandra �õ��� gossip Э�顣��ʵ��Ӧ���У�����Ⱥ�����ϴ�ʱ����ﵽ���ٸ��ڵ㣬gossip Э�鲻�ܹ���Ч���÷ֲ�ʽϵͳ����һ���ԣ�����һ���̶Ȳ�һ�µ����⡣

����������������£�twitter �з����Լ��� NoSql Ҳ���� manhattan ϵͳ��manhattan ���ʵ����Ҫ��ע��Ҫ�����£�
�ɿ��ԣ�
�����ԣ�
�ɲ����ԣ�
����ʱ��
����
manhattan �ֲ�ʽʵʱ�������ݿ�Ŀǰ���������ڵ㣬ÿ���ڵ����֧������ QPS��P99��ʱΪ10���롣
����Manhattan ���֮�洢����
���ȣ���һ�� One Size Fit All ϵͳ�ǿ϶������ܵġ��������ǵ�ʱ��������ģ�黯��ƣ�����Ĵ洢���ʹ洢�����ǿ��ԽӲ�ģ����Ը��ݲ�ͬ����������������ϵͳ��
��ˣ����ǵĺ�̨���������ೣ�����������һЩר����;�����档

������������
SeaDB ��ֻ���Ż�����Ϊ�����кܶ��û��������ǹ��ͻ��������Ƕ���������������ݵġ����ʱ����ʺ����������£�����ǰ����ֻ���ġ�
SSTable ���д�Ż��Ĵ洢���档�� google �� bigtable ���������Ƶģ�����д�Ƿdz���Ч�ġ�
RMDBS ��ͳ�Ĺ�ϵ���ݿ�ϵͳ���кܶ��û���ͬʱ��д�ģ�ͬʱ�Զ��Ǻ�����ġ���ʱ RMDBS �ǿ��Խ��� index �ֿ���ʵʱ�� update��
ר����;��������Ҫ�Ǵ�����������������Ż��Ĵ�ʩ��
ǿһ���ԣ�
ʱ�����з���
����������
�ġ�Manhattan ���֮�ܹ�
Manhattan ����ܹ���Ϊ�IJ��֣��ֱ��ǵ��ȡ�����д�Լ�һ����Э����
Cordinator ����ģ�飬������Ҫ�����Ƕ���������Ȼ����ݲ�ͬ key �����ɢ����ͬ�ĺ�̨�ڵ��ϣ����ս��ڵ����Ӧ������װ���ظ�����
��Щ������ Coordinator ����ģ�����棬���ں�˴洢ģ�����档bloom filter ���Կ����ų��ֲ�ʽ�ı����治����ij��ֵ���Ӷ��������߲�ѯЧ�ʡ�
�������� SSTable ���ּܹ��Ĵ洢�����Ĵ���ʱ�dz��ߵġ���Ϊ��Ҫ���ܶ�ܶ� SSTable��
��Ȼ�����кܶ��ʩ���Զ�������Ż�����һ���Ƕ��ڽ�С�ĺϲ��ɴ�� SSTable���ڶ�����������������һ��פ�ڴ棬����һ���ڴ����У�������ʹ�� Bloom filter�������ܱ�֤���ǵļ��١�
д����ʵ������ֱ��д���ڴ���ģ�commitlog �Ƿdz���ģ�����д��Ч�ʺܸߣ������Ͽ��Կ�����д���ڴ���ġ�
Reconciliation �������հ�����д������ݸ��ƣ�ͨ������ job �������д�����֤����ͬ�������ݡ�
ͬʱ��reconciliation �и����ڵĹ�������ɨ���е��ļ���Ȼ����ļ��IJ�һ�½������ϴﵽ����һ���ԡ�
�塢����ϵͳ��Ч��άʵս

Twitter �������dz���Ҷ�֪������������н����Ŵ����Եġ�����ǰ��Ҫ����һ������˿����м��ٸ����á��������ļ�Ⱥÿ��������ǧ������������ʮ���������ļ�Ⱥ��������ά������ϵͳ�dz�ʹ�ࡣ
�����и��ܼ��˵����ӣ���һ�� SRE ����һ��ʱ��尾������ͻȻ�ڰ칫�һ赹��������������ά�������˳ɹ��ظĽ������� DevOps��DevOps ʵ����ָ���Ƿֱ����֯�ܹ������̡������������������ϵͳ��Ӫ��Ч��
������ά-��֯�ܹ�

��ҿ���֪����������������з�д�� code�������ά�������ˡ�����Ҳ��֪����ʲô�ģ���ҹ������������������Ҫ����Ȼ�����з����з�˵�������������������ά�����������͵�ì�ܾ����������ˡ�
���Կ����Dz��еģ�����Ч������֯�ܹ�������������е��������ж��⡣Ϊʲô��ô˵���з�������ά����άȫ�����һ�顣��ʱ����д���ô��룬���ҹ��������������������д��һ������Ҫ�ı��������ͬ�±����������ڶ�����Ҫ������һ�ٵġ�
����Ŀ���������У���ά����Ŀ����һ��Ҫ�����з���ơ��з�������DZ���Ҫ������ά signoff����ά�� signoff���з�����Ʋ�������ɡ�
�з������֮���������Ƚϵ���Ҫ�� work items ����Ҫ�С���һ������άָ�ꡣ
�ڶ������Ǹ澯����Щ���� Ҫͨ��������۵ġ��������߽�����ά֮ǰ����ά�����ֲ��DZ���Ҫ��ɵģ�һ��Ҫ�з�����߹���ģ��������IJ����ֲᡣ
���������֮ǰ�и�Ԥ���ߵĻ��飬�������з��ߡ���ά�ߵĸ������Ű�����ȫ��Ҫ�˽��Ʒ�������ߵķ������沢 sign off��
���ߺ��з���Ŀ������Լ���ά�Լ��Ĺ���ģ��һ���¡�ͨ��һ���µIJ�Ʒĥ�ϣ�����ٽ�����ѵ�ͽ������Ҫ�����������ʱ����Ҫ��һ�����������з�����ά����ѵ���̡�
������ά-����

�����˶���Ҫ�ϸ���ά��������Ҫһ���ܺõ����̡�������ѵ�����������Ժ����˿�һ�����εĽ��������ܲ�Ʒ��������ά���顣
Ȼ�������ν�� Shadow Others����������ά�ڴ�������ʱ�������Ա߿��ţ���¼���ظ������������в������
��һ������ Shadow by Others��������Σ��������������е����⣬���������άͬ������������Щ��ͨ���ˣ���Ϳ��Զ����ϸ��ˡ�
������ά-����
�߱�����ȷ����֯�ܹ�����Ч�����̺�Devops �ĵ�����֧���Ƿ������õ���ά���ߡ���Щ������ά�ƶ�����ά���з���ͬʵ�ֵĹ��ߡ������м������߰������Ǽ���Ľ�������ά�ijɱ���

Self Service����ǰ��ά�ķ���80%���ڲ��Ŷӵģ��кܶ��ڲ��������ǻ��˺ܳ�ʱ�������档�������������һ�� Self Service UI������Ľ����˹�ͨ�ɱ���
ֻ��10%������ķ�����ߺ���Ҫ�ķ������ǻ�����ǹ�ͨ�������������и�����Ҫ�Ĺ����ǵ��Թ��ߡ���Ϊ��ҷ��������ˣ����˵��Թ��ߵ� UI �ͷdz������ˣ�������ע��дһ�� Key-Value �dz����㡣

������Ҫ���ֲ�ͬ�Ļ��������Ի��������������ȡ��������ݷ�����˵����Ҫע�� canary �����ڵ㲻����һ�� replication set �ϡ�
����Ļع������ر���Ҫ�����Dz��漰���κ����ݸ�ʽ�仯�ı䶯һ����˵��û��ʲô�����⡣���ǣ�һ���漰���������������ݵĸ�ʽ�ĸĶ���Ҫ�dz�С�ģ����ݸ�ʽ�䶯���û�а취�ع��ˡ�
���Բ���һ���Ƿ������ġ���һ�����Ȱ��µĴ��벿����ȥ���µĸ�ʽ��Ҫ�䣻�µĴ����ܹ�ͬʱ�����¾����ݸ�ʽ���ڶ���������һ�£��µ����ݸ�ʽ�ͽ����ˣ������Ͳ����ˡ�

Topology Transition������Ҫ���ߵ����ݻ��żӽڵ��ʱ��������Ҫ�и���ν��״̬��������֤���ݵ�һ���Ժ�ͳһ�Բ���Ӱ�졣
��ʱ�ϵķ���ʹ����������һ�� all or none �Ĺ��̣�һ��Ǩ�ƹ������ʧ���ˣ���ʹ�Ѿ������90%��Ҳ���DZ���������������� SRE ��˵�Ƿdz�ʹ��ġ�
���Ǻ��������һ������ʽ��Ǩ�Ʒ������ܹ���ס��ǰ״̬������������ʱ�ӵ�ǰ��״̬���»ָ���
������ά����ս�����
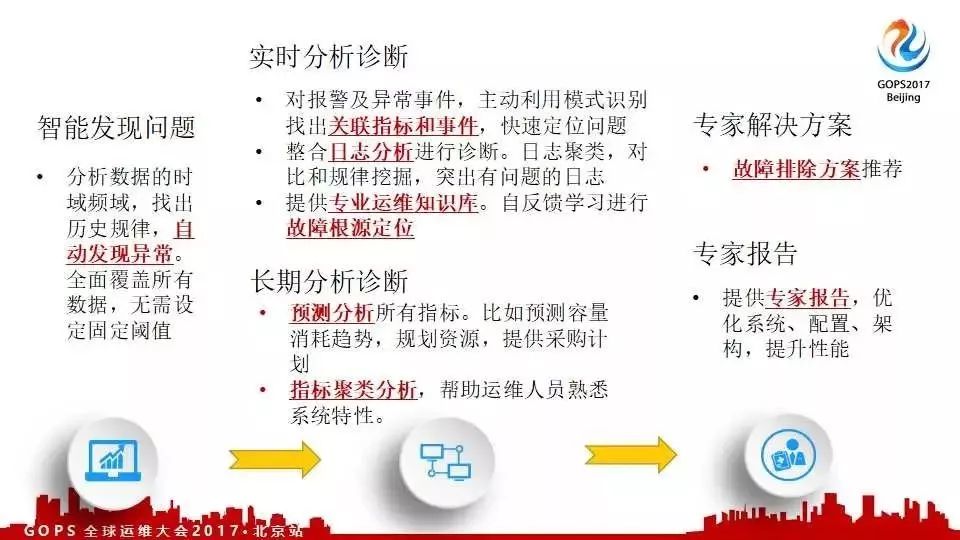
���� Twitter ����ά�������˺ܶ�������ǻ����кܶ��������Ҫ�Ľ��ĵط������磬�����ų��߶��ֹ�����
��Ϊ twitter ���еķ����ָ������������ܹ�����10�ڡ�һ�������⣬�Ų���������һ����ʹ������顣
������ô��ָ�꣬��Щ�����⡢��Щû���⣻���Ǻ����жϵġ����ǻ�������ͨ���Ա���ʷ���ݲ������ǿ��������쳣�Զ����ֵġ�
��ҿ����о��飬ǰ�˳��������������ں�˵��µġ���ô��ǰ��˹��������������������ȫ���Կ�����ɵģ�����һ���Ϳ��Խ�ʡ�ܶ��˹���ʱ�䡣
�ܶ�ʱ��֪��������ָ�겻�������ܻ���������ʱ��Ҫ�鿴��־���鿴��־�Ѷȴ���־��Ϣ�࣬�������ҵ���Ҫ����Ϣ�����ף����һ���Ҫ����ʱ�䣻Ϊ������������־���������ϵ�ϵͳ����ͼ����־�����ϡ�����ԱȵĽ����
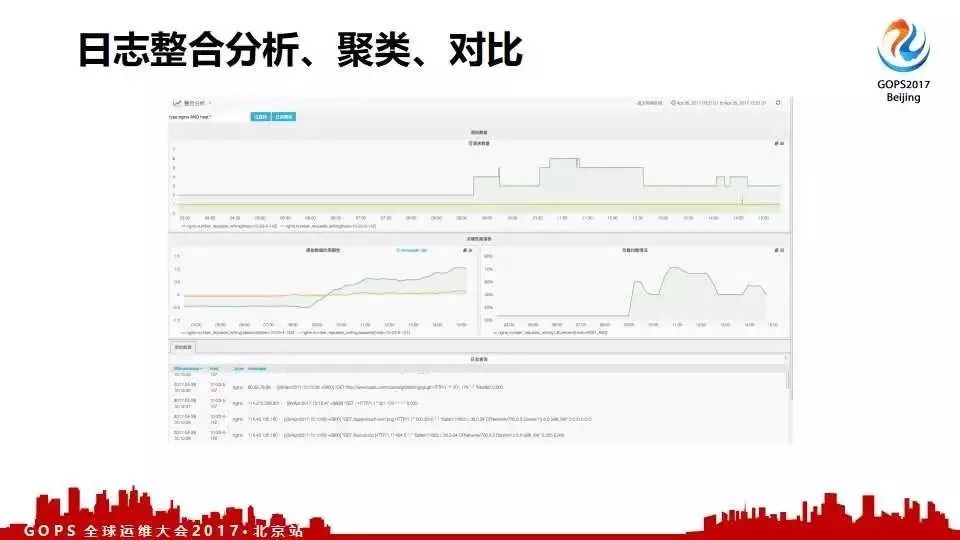
��������������
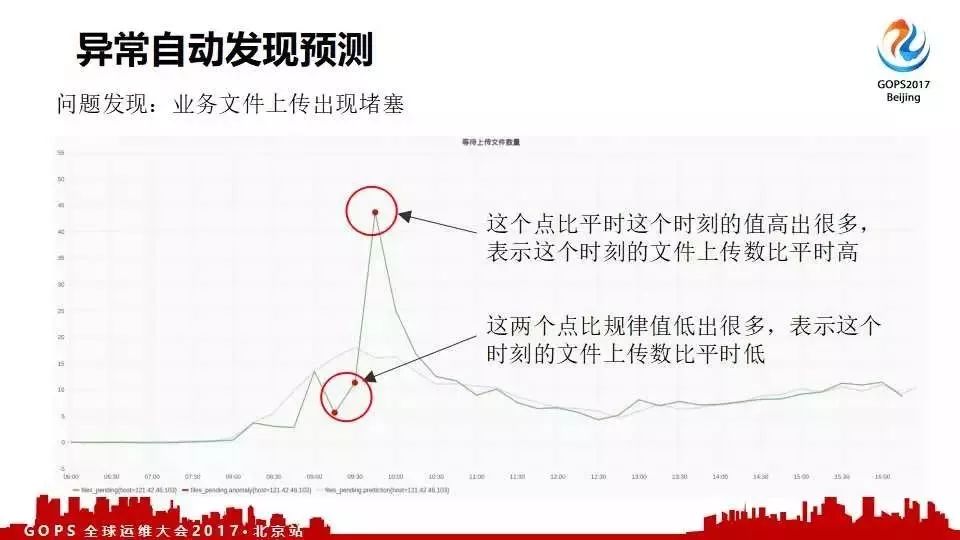
����һ�������ͻ�������ҵ���ϴ���������������������ǻ����Զ���ʶ�����ġ�ͨ��������ʶ���Խ��������ı�������
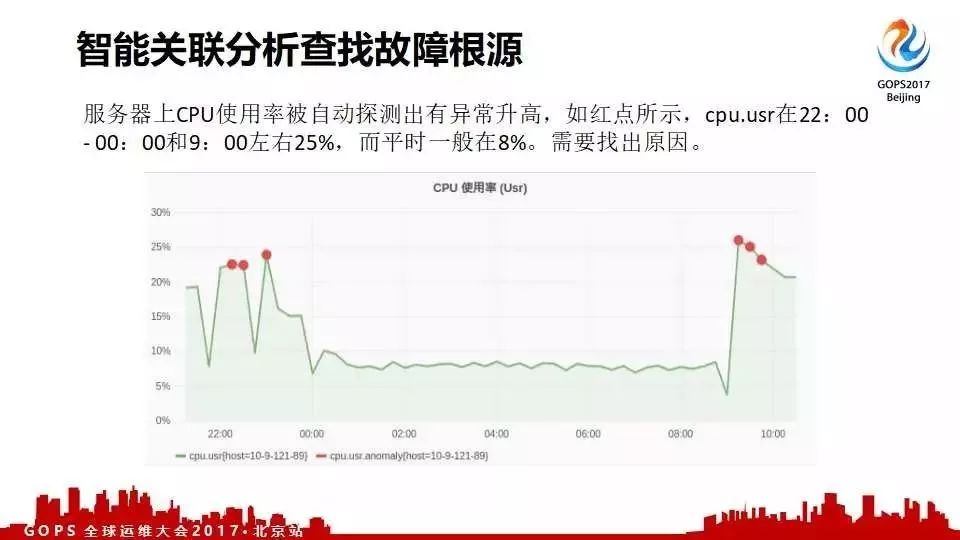
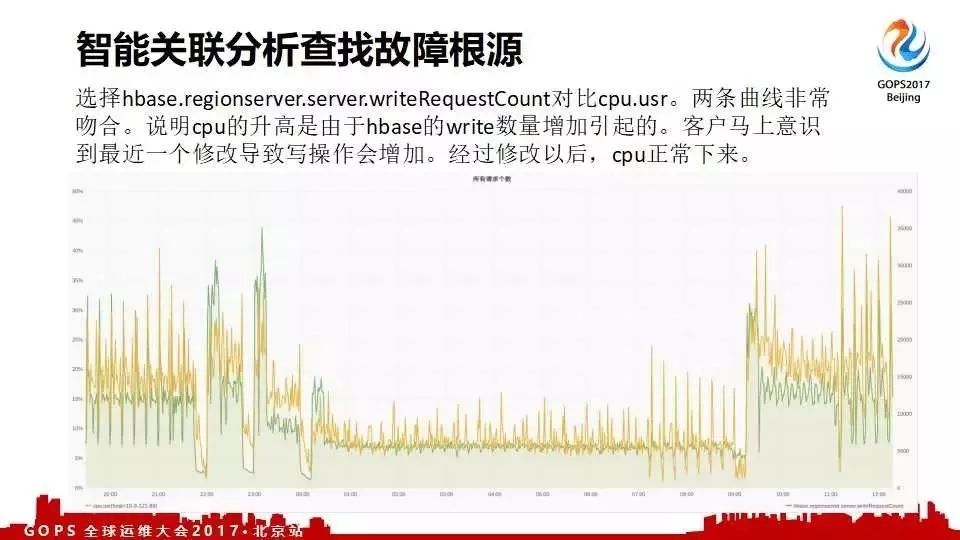
����һ���ͻ� CPU ͻȻ쭸ߣ���֪��ʲôԭ��ͨ�����ܹ����Ų���ϸ�Դ���߷��������һ�� hbase дҲ�����ˡ�����Щ���õ���Ϣ�Ƽ����ͻ����ͻ��ܿ�֪����������һ����������ɵ����⡣
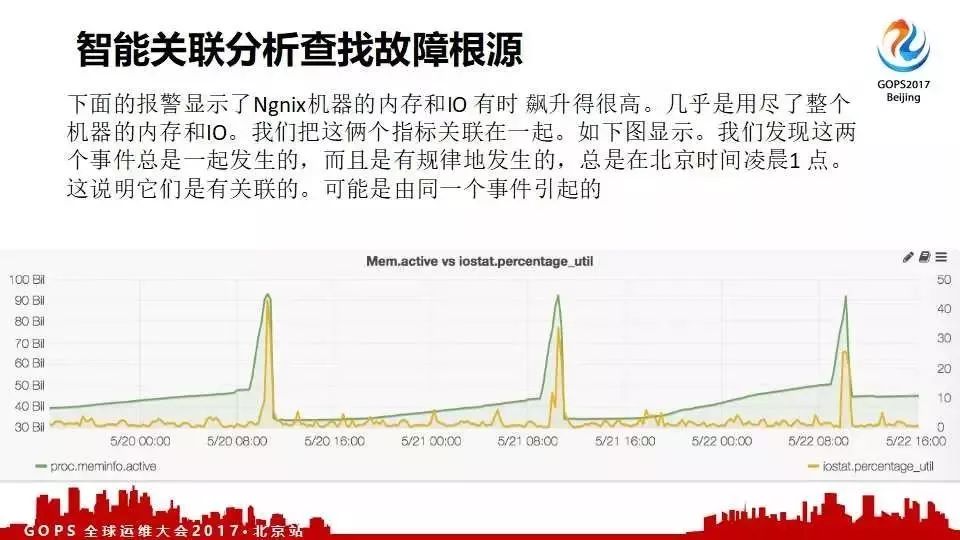

��������һ���ͻ����dz���Ҫ���Ż���������������쭸ߣ���ȴһֱ��֪��ʲôԭ����ͨ�����ǵĹ����Զ��ҳ������⣻�����ҵ���������̺��꾡��Ϣ���꾡��������ʲô����д�ġ�
�������������ǵ� SRE д��һ���ű�������û�����ˣ��������Ƕ����ˣ����ÿ�춼���ܣ��˷Ѽ�����Դ���������Ƿ�����Ӱ�졣

�������������Թ�������зdz���İ�������Ҳ�����ǽ���������ܹ�������һվʽ���������ԭ��
���һ������֪ʶ���ǰѴ�ҵ���ά֪ʶ���ϻ��۷������棻ͬʱ�����ܹ��Զ�ѧϰ������һ��һ���������ԣ���ʱ���Բ�ѯ���൱��һ����ά��֪����