作者:Nikita Zhiltsov
翻译:王威力
校对:李海明
本文约5000字,建议阅读15分钟。
本文为你概述处理不同NLP问题时的具有卓越性能的方法、技术和框架等。
计算语言:人类语言技术学会北美分会2019年年会(North American Chapter of the Association for Computational Linguistics: Human Language Technologies/NAACL- HLT)于6月2至7日美国明尼阿波利斯举办。NAACL- HLT是A级同行评审会议,是继计算语言学协会(ACL)会议之后,计算语言学界的又一重要事件,即自然语言处理(NLP)。受今年NAACL- HLT启发,本系列文章对学术研究和工程应用中在处理不同NLP问题时所实现的具有卓越性能的方法、技术和框架进行了概述。这些文章主要面向NLP领域入门级软件工程师、机器学习工程师、数据科学家、研究类科学家,若在现代神经网络方面具备一定基础则更佳。本系列不对NLP领域所做工作进行全面覆盖,而是只关注与Orb智能最相关的一些话题,如language representation learning(语言特征学习),transfer learning(迁移学习),multi-language support (Part I)(多语言支持),text similarity(文本相似性),text classification(文本分类),language generation(语言生成), sequence labeling (Part II)(序列标注), frameworks(框架)以及miscellaneous techniques (Part III)(其他技术)。同时,读者可能会发现一些非常通用的想法在NLP领域之外也同样适用。
介绍
或许现代NLP领域最大的转变,是将每个特征视作表独立正交维数(即one-hot表示,该表示经常与TF-IDF一同使用)进行表示,转变为密集向量表示(见图1)。也就是把原始特征压缩嵌入到一个低维空间中(便于工程应用),并用这个空间中的向量对特征进行表示。密集表示的最大好处是,特征间不再是独立的,捕获的相似性或其他的相关关系,并可以更好地进行特征归纳(见分布式语义假设)。另一个好处是,词嵌入可向神经网络那样进行训练,从而对主目标函数进行优化(在此之前,潜在语义分析,布朗聚类和潜在狄利克雷分配都在广泛使用)。
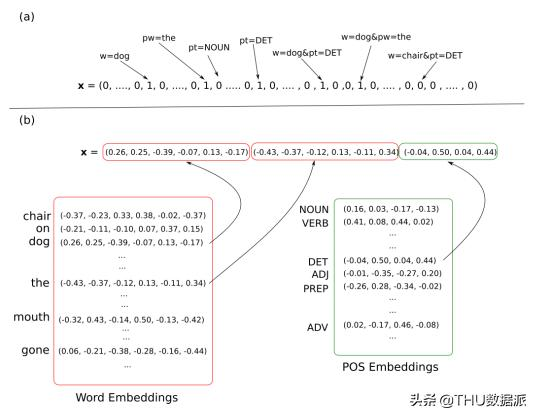
图 1 one-hot编码和词向量(word embeddings)
同时,分布语义假设有其固有的限制:
- 常识是隐蔽的,通常不会直接写下来
- 词嵌入易产生偏见(比如道德的、社会的、职业的)
- 除文本外,没有其他形式的形态
最后一点很有意思,因为这是人工神经语言学习者(作为慢的和数据依赖的学习者)和人类学习者(特别是儿童)之间的主要区别,人类能够在很少的例子下更快地学习一门语言。我们倾向于认为,多模态学习的工作,即在学习过程中结合各种输入(文本、音频、图像、视频),似乎是人工智能的下一个潜在突破(见第三部分中的第一步示例)。
回到第一部分,我们涵盖了现代语言特诊学习技术的一些基本方面。
迁移学习
在NAACL上,S. Ruder, T. Wolf, S. Swayamdipta, and M. Peters提供了一个很棒的教程,“Transfer learning in NLP”(http://tiny.cc/NAACLTransfer)。NLP中的迁移学习被认为是一个自动学习表示的问题,它使用基于神经网络的自然语言处理方法跨任务、域和语言进行迁移学习(参见图2)。
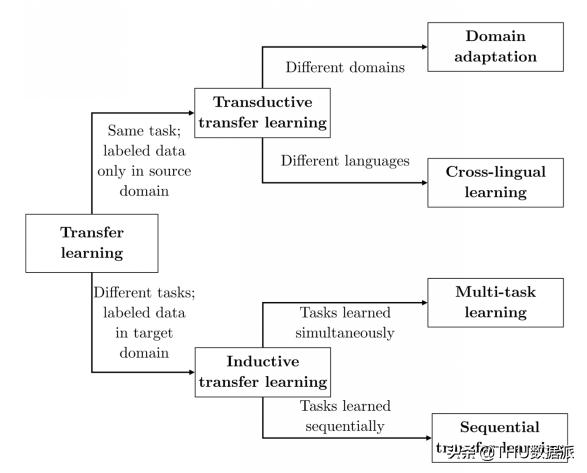
图 2 迁移学习任务的分类
原则上,越来越多的经验表明,迁移学习优于监督学习,除非没有相关信息可用或者已有足够的可用的训练样本。
预训练
预训练是迁移学习的第一个基本步骤。预训练的核心思想是,用已训练的内部表示对主要的自监督NLP任务(如无标记数据)进行求解,对其他任务也同样使用。比如在上下文中简单的单词预测或word2vec的词向量学习,已经成为最先进的NLP模型的基本构建模块。更困难的语言建模任务,如句子预测、上下文单词预测和掩蔽单词预测将在下面的博客文章中予以概述。这还包括神经机器翻译(例如,CoVE)和自动编码导出。根据目前关于预训练的共识,教程作者观察到:
- 一般来说,预训练任务和目标任务的选择是耦合的,即预训练越接近目标任务,效果越好
- 经验上,语言建模(LM)任务比自动编码任务效果更好:
这已经够难了,LM模型必须压缩任何可能的上下文(语法、语义、事实知识)来概括可能的完成;
可用于预训练的数据更多参数更多,训练效果越好,得到更好的词向量
- 预训练提高了样本效率,也就是说,为了达到相同的质量和更快的收敛速度,通常需要较少的最终任务注释数据。
适应
若一个预训练模型需要适配到目标任务上,这会产生三个基本问题:
1、 对预训练好的模型架构做多少改变以适应目标问题(模型架构调整)
2、 适应过程中需要训练哪些权重,遵循何种训练计划(优化方案)
3、 如何为目标任务获取更多的监督信号(弱监督、多任务和集成学习)。
首先对于模型架构调整,有两个方式:
1(a)保持预先训练的模型内部不变。如果对目标任务没有用处,请删除一个预训练任务head。在预训练模型的首层/最底层添加迁移任务特定层(随机初始化参数)。
1(b)修改内部结构。这包括适应结构不同的目标任务。例如,对具有多个输入序列(翻译、语言生成)的任务使用单个输入序列进行预训练,即,可以使用预训练的权重初始化目标模型的多个层(LM用于初始化MT中的编码器和解码器)。另一个方向是特定于任务的修改,例如添加跳过/剩余连接和注意层。最后,在预先训练的模型层之间添加适配器或瓶颈模块。适配器减少了用于调整的参数数量,允许其他“heavy”层在传输期间保持冻结状态。它们可能包含不同的操作(卷积,自关注),并且通常与剩余连接连接到现有层。
例如,参见最近的文章(https://arxiv.org/pdf/1902.00751.pdf),在适配器中多头关注和前馈层之后引入适配器模块。
对于第二个调优的问题:
2(a)除非我们改变预先训练好的权重,否则我们最终会得到诸如特征提取和适配器之类的选项。如果预先训练的权重发生变化,则采用微调。在这种情况下,预先训练好的权值用于结束任务模型的参数初始化。一般来说,如果源任务和目标任务不同(即源任务不包含对目标任务非常有利的关系),则特征提取在实践中更为可取(详见本文)。Transformers(如BERT)通常比LSTMs(如ELMo)更容易微调。
2(b)学习时间表。这是一个关于更新哪些权重、更新顺序和更新速率的方案。我们的动机是防止覆盖有用的预先训练的知识(灾难性遗忘),并保留转移的好处。好的技术包括:自上而下的更新(通常顶层是特定于任务的,底层传递更多的一般性知识,如形态学和语法),不同学习阶段之间的不同学习速率,以及添加正则化以防止参数偏离预训练区域。
第三个是关于获得更多监督训练:
3(a)在单个适应任务上对模型进行微调。例如,对于文本分类任务,从模型中提取一个固定长度的向量(最后一个隐藏状态或它们的池)。使用额外的分类器投影到分类空间,扩展顶层。以分类目标训练。
3(b)相关数据集。在这里我们:
- 顺序适应:对相关数据集和任务进行中间微调;
- 多任务与相关任务的微调:采用损失函数的组合,然后对每一优化步骤分别抽取一个任务和一批进行训练,最后只对目标任务进行微调; 数据集切片:使用只对数据的特定子集进行训练的辅助头,并检测自动挑战的子集,模型在其上执行不足(https://hazyresearch.github.io/snorkel/);
- 半监督学习:最小化对原始输入的预测与其倾斜版本之间的距离,使其与未标记数据更加一致。
3(c)集成。这意味着通过组合它们的预测对独立的微调模型进行集成。为了在集成中获得不相关的预测器,模型可以在不同的任务、数据集分割、参数设置和预训练模型的变体上进行训练。这个方向还包括知识提炼(详见第三部分)。
示例
对于这些原则的一个好的展现是NAACL上的一篇文章,“An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models” 介绍了SiATL(代码链接https://github.com/alexandra-chron/siatl),是一个简单且有效的用于文本分类任务的迁移学习。SiATL(图3)是一个标准的基于预训练模型,并把它的权重迁移到一个分类器并增加了一个任务特定层。
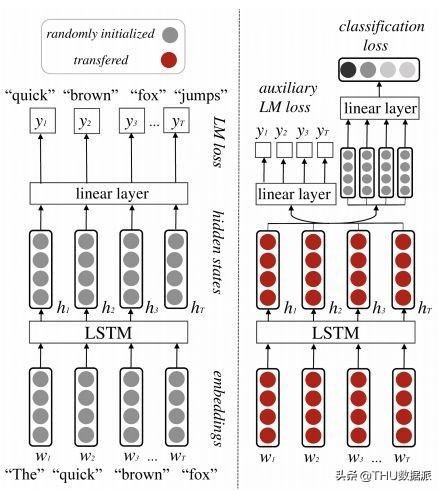
图 3
为了防止语言分布的灾难性遗忘,该模型将辅助LM损失与分类损失结合在一起。此外,辅助LM损失的贡献通过训练迭代次数的指数下降来控制,逐渐将焦点从LM目标转移到分类任务。类似于ULMFiT(见下面的详细信息),SiATL从层的顺序解冻中获益:微调附加参数,在没有嵌入层的情况下微调预训练参数,并训练所有层直到收敛。作者还仔细选择了优化器:小学习率的随机梯度下降(SGD)用于微调,Adam用于随机初始化的LSTM和分类层,用于更快的训练。虽然没有超过最先进的(SOTA),SiATL优于更复杂的迁移学习方法,特别是在小数据集上。
最后,我们将提到一些可用于迁移学习的预先训练模型的来源:
- TensorFlow Hub(https://www.tensorflow.org/hub)
- PyTorch Hub(https://pytorch.org/hub)
- AllenNLP(https://allennlp.org/)
- Fast.ai(http://fast.ai/)
- HuggingFace.(https://huggingface.co/)
不同粒度
特征学习的一个重要因素是模型运行在的基础单元。“One Size Does Not Fit All: Comparing NMT Representations of Different Granularities”的作者把特征单元分为四种:单词、字节对编码(byte-pair encoding)单元、形态单元(Morfessor)(https://github.com/aalto-speech/morfessor)
和字母。BPE把单词分为symbols(symbols是一串字母),然后迭代地用一个新的symbol序列替换最频繁的symbol序列。BPE分割在神经机器翻译(NMT)中非常流行。Morfessor分裂成形态单位,如词根和后缀。
作者评估了NMT派生的嵌入质量,这些嵌入源于不同粒度的单元,用于建模形态学、语法和语义(而不是像情感分析和问答这样的最终任务)。他们的方法从训练的基于LSTM的NMT模型的编码器中提取特征表示,然后训练Logistic回归分类器对辅助任务进行预测。
作者得出以下结论:
- 特征单位表现的好坏与目标任务相关
- 从子词单元派生的表示形式更适合于建模语法(即,长期依赖关系);
- 基于字符的表示显然更适合于形态学建模;
- 基于字符的表示对拼写错误非常健壮;
- 使用不同表示的组合通常效果最好。
拼写错误容忍字嵌入
标准的word2vec方法通常不能很好地表示格式错误的单词及其正确的对应词(我们通常喜欢为它们提供类似的嵌入),这是实际应用中的一个严重缺陷。虽然FastText包含了用于学习单词嵌入的字符n-grams,但通过设计,它倾向于捕获语素,而不是拼写错误。在“Misspelling Oblivious Word Embeddings”一文中,Facebook人工智能研究人员介绍了MOE,这是一种学习单词嵌入的简单方法,它可以抵抗拼写错误。他们用拼写更正目标扩展了FastText目标。
他们扩展了FastText目标,带一个拼写正确目标L? 。(w?, w?) ∈ M,其中w?是正确拼写,w?是它的错误品系。N是negative samples。l(x) = log (1 + e??) 是逻辑损失函数。评分函数如下定义:
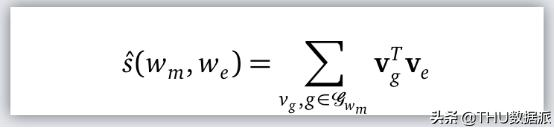
继续:
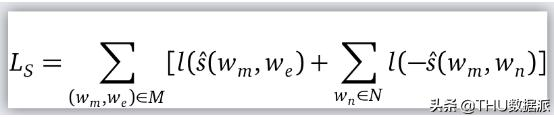
其中第一部分是基于w?的w?的可能性。由标准SGD和常规的FastText丢失函数联合训练,通过加权和将两者结合起来。单词相似度和单词类比任务的实验表明,虽然FastText确实能够捕获较低编辑距离的拼写错误,但MOE更擅长捕获较远的示例。这篇论文还附带了一个很好的奖励——从Facebook的搜索查询日志中收集的超过2000万条修正数据集。实验是在英语数据集上进行的。多种语言的支持留给以后的工作。
语境词嵌入
与传统的上下文无关的单词嵌入相比,上下文单词嵌入通过动态地将单词链接到不同的上下文,提供了更丰富的语义和句法表示。构建和重用上下文单词嵌入有两种有效的方法:基于特征(例如ELMo)和微调(ULMFiT、OpenAI的GPT和Google AI的BERT),而在微调时使用基于特征的模式更有效。
ELMo(https://arxiv.org/pdf/1802.05365.pdf)预先训练了一个基于LSTM的双向字符级语言模型,并提取上下文单词向量作为隐藏状态的学习组合(参见图4)。对于下游任务,这些单词嵌入被用作输入,而不做任何更改(因此,它们就像功能一样)。自2018年出版以来,ELMo在6项不同的NLP任务中展示了最新的(SOTA)结果。
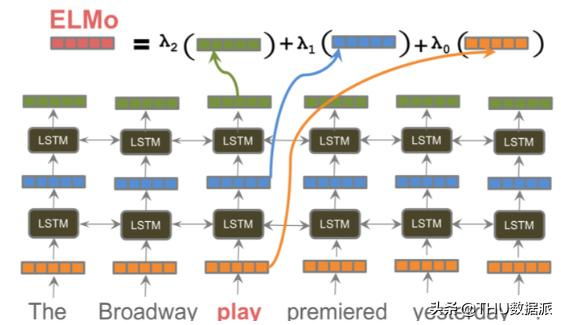
图 4
因此,我们简要介绍了预训练的最佳微调方法。与基于特征的方法不同,微调提供了将语言模型与特定领域的语料库甚至下游任务相匹配的能力,保留了来自初始大型语料库的一般知识。例如,ULMFiT [code(https://github.com/fastai/fastai),tutorial(https://github.com/fastai/fastai/blob/master/examples/ULMFit.ipynb)] 预先训练Salesforce的AWD-LSTM(https://github.com/salesforce/awd-lstm-lm)单词级语言模型(参见图5),并使用不同的适应技术(逐步解冻层和倾斜三角形学习率的区分微调)分两个阶段对训练的语言模型进行微调。ULMFiT在6个分类数据集上显示了SOTA。
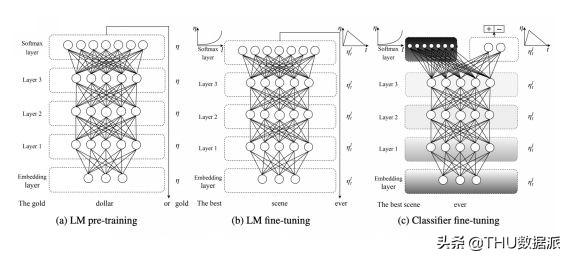
图 5
Generative Pretrained Transformer (GPT)( https://github.com/openai/gpt-2)预先训练大型12层左右变换器(见图6)和句子、句子对和多项选择题的微调。下游任务的灵活性是通过将任务的结构线性化为一系列令牌来实现的。GPT在9个不同的NLP任务中达到了SOTA,其更大的模型GPT-2以其令人震惊的良好文本生成应用获得了广泛的关注。
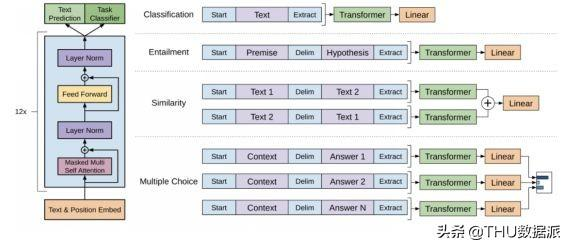
图 6
“BERT: Pre-training of Deep Bidirectional
Transformers for Language Understanding”(https://www.aclweb.org/anthology/N19-1423)描述了作为GPT发展的以下的方法(图7):使用maskedLM和next sentence prediction预训练句子和语境词特征。masking提供了在单词预测期间同时包含左上下文和右上下文的能力。BERT模型有令人印象深刻的340M参数和24层。BERT是目前最有用的预训练机制(然而,最近的XLNet[https://arxiv.org/abs/1906.08237],声称BERT在20个NLP任务上的性能优于BERT,值得一看)。
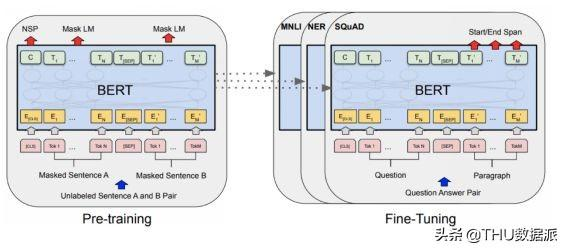
图 7
跨语言词向量
多语言嵌入已经被证明是在许多NLP任务中实现跨语言传输的一种很有前途的方法。实现这一目标主要有两种正交方法。第一种是跨语言多语言预训练:通过在多种语言中训练一个模型,跨语言共享词汇和表示。虽然它易于实现,但它常常导致低资源语言的表示不足。这种方法的显著例子包括Facebook Research的LASER(https://github.com/facebookresearch/LASER)和Google AI的多语言BERT(https://github.com/google-research/bert/blob/master/multilingual.md)。
其次,为每种感兴趣的语言独立地训练单词嵌入,然后将这些单语单词嵌入对齐。例如,Facebook Research的MUSE(https://github.com/facebookresearch/MUSE)为FastText令牌级嵌入实现了这种方法。“Cross-Lingual Alignment of Contextual Word Embeddings, with Applications to Zero-shot Dependency Parsing” 提出了一种基于ELMo的上下文词嵌入对齐方法。有趣的是,来自不同单词的点云在实践中被很好地分离,因此作者引入了一个嵌入锚e?作为单词i的点云的质心。空间结构的另一个有趣的特性是同音点云的多模态(见图8)。
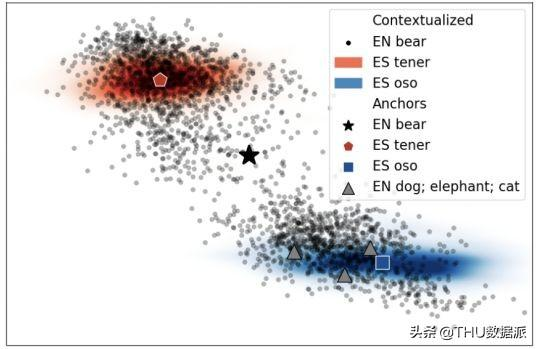
图 8 对英文单词bear的语境词和它的可能的两种西班牙语翻译(``oso’’蓝色表示,``tener’’红色表示)
也就是说,当一个单词i有多个不同的意义时,人们可能会期望i的嵌入通过将其分成多个不同的云来反映这一点,每个云对应一个意思。该方法采用了两种著名的上下文无关对齐方法(Mikolov等人(2013)和MUSE),用嵌入锚替换词向量。
- 有监督设置:通过给定的单词词典在源语言和目标语言之间进行监督。然后,将问题归结为求矩阵之间的最佳线性变换(即几何缩放、旋转、反射等)的正交Procrustes问题:
接近的表示为,W^s→t = UV?,其中U和V列是源和目标的专制的嵌入矩阵的乘法的左、右奇异向量;
- 无监督设置:当词典由MUSE中实现的对抗性框架自动生成时,采用第一种方法。
作者已经证明,这些对齐的嵌入提供了良好的单词翻译(包括低资源语言,如哈萨克语),并在最新的zero-shot 和few-shot跨语言依赖性分析模型上显著改进。
感谢Grigory Sapunov 和Mikhail Obukhov帮助的反馈。
原文标题:
NAACL ’19 Notes: Practical Insights for Natural Language Processing Applications
原文链接:
https://medium.com/orb-engineering/naacl-19-notes-practical-insights-for-natural-language-processing-applications-part-i-5f981c92af80
编辑:于腾凯
译者简介

王威力,养老医疗行业BI从业者。保持学习。
— 完 —