0 ����
Tensorflow�ٷ�Ŀ���������SSD��Faster rcnn��Ԥѵ��ģ�ͣ���û�и�yolov3��Ԥѵ��ģ�ͣ��������ĵ����Ѿ�ʵ���˻���tensorflow������yolov3���㷨�����ĶԸô����ѵ������������һ���ܡ�
������Դ��YunYang1994��tensorflow-yolov3���������ƵĴ��붼�ǻ��������е��ġ����ǽ�����ܵ�Byronnarʵ�ֵ�tensorflow-serving-yolov3����һ�ָĽ�����ظĽ������������ܣ����ľ��ǻ��ں�ߵĴ������ʵ�֡�
��Ҫ��ԭtensorflow-yolov3�汾��������ϸ���ϵĸĽ�,ѵ����Visdrone2019���ݼ���ȷ����87%����, ������ú��üǵ�starһ��Ŷ��лл�� ����ʮ����ϸ���ر��ʺ���������serving�˲�����ʲô���������issues,�����ǸĽ�ϸ��:
1 ��������ṹ��֧����tensorflow-serving����,�Լ�ѵ�������ݼ�Ҳ�������߲���,�������� docker+yolov3-api���Խű�
2 ����ulits�ļ����Ż���demoչʾ,����֧������չʾ,����������
3 ��ϸ������ע��,���������,���������������Դ���,һ���̶ȱ���index�Ĵ���
4 ����ѵ�����룬֧���������ݼ�ʹ��Ԥѵ��ģ���ˣ�ģ�������С����֮һ(�������ָ��ƽ�������Լ�С��200��Mһ��ģ�ͣ���С����֮������ͼƬ��Ƶdemoչʾ �궼֧�ֱ��浽����,ʮ�����ײ���
5 �����Ƶ����ԭ��,����������ͼƬ���Խű�,�ٶ��ر��(��������Ƶÿһ֡һ�����ٶ�)
6 ��������ʹ�õ�Anchors���ɽű��Լ��������������IJ�������
1 demo����
1.1 ���ؼ���װ
$ git clone https://github.com/byronnar/tensorflow-serving-yolov3.git
$ cd tensorflow-serving-yolov3
$ pip install -r requirements.txt
��requirement�ļ��п��Կ��������ǻ���tensorflow-gpu 1.11.0�������İ汾�����ߵIJ�һ�£����ܻ�������⣬��ȷ������������
1.2 ����Ԥѵ��ģ��
�ٶ���������: https://pan.baidu.com/s/1Il1ASJq0MN59GRXlgJGAIw ���룺vw9x
�ȸ���������: https://drive.google.com/open?id=1aVnosAJmZYn1QPGL0iJ7Dnd4PTAukSU4
$ cd checkpoint
$ tar -xvf yolov3_coco.tar.gz
$ cd ..
$ python convert_weight.py
$ python freeze_graph.py
1.3 ����demo
$ python image_demo_Chinese.py # ������ʾ
$ python image_demo.py # Ӣ����ʾ
$ python video_demo.py # if use camera, set video_path = 0
���гɹ������ʾ���ͼƬ

1.4 ������
# ת���ɿɲ���� saved model��ʽ
$ python save_model.py# ��������saved model�ļ�������� yolov3 �ļ��и��Ƶ� tmp �ļ������棬������
$ docker run -p 8501:8501 --mount type=bind,source=/tmp/yolov3/,target=/models/yolov3 -e MODEL_NAME=yolov3 -t tensorflow/serving &$ cd serving-yolov3$ python yolov3_api.py
���óɹ�����ʾ���»���
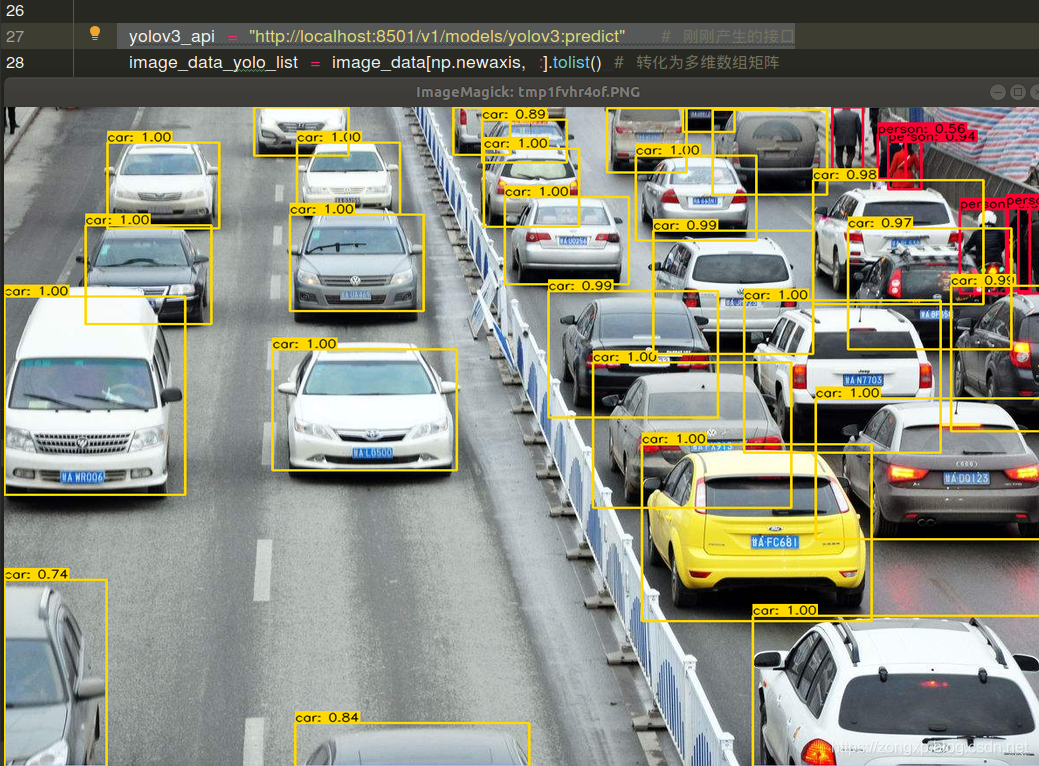
2 ѵ���Լ�������
�������ϲ��裬���ǰѻ��������ú��ˣ���������ʼѵ���Լ�������
2.1 ���ݼ���
��Ҫ��VOC��ʽ�����ݼ���VOC2007��Ŀ¼�ṹ����
VOC2007
������ Annotations
������ ImageSets
�� ������ Main
������ JPEGImages
�����DZ�ע��xml�ļ��ŵ�Annotations�ļ����£�ͼƬ�ŵ�JPEGImages�ļ����£�Ȼ����VOC2007�ļ������½�һ���ű�����������ImageSets�ļ����µ����ݼ��ṹ��������ʾ
import os
import randomtrainval_percent = 0.1
train_percent = 0.9xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'# ����"Annotations"�ļ���Ȼ���б�
total_xml = os.listdir(xmlfilepath)# ��ȡ�б�������
num = len(total_xml)
list = range(num)tv = int(num * trainval_percent)
tr = int(tv * train_percent)trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')for i in list:# ʹ����Ƭ������ȡ�ļ���(ȥ����".xml")name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
���гɹ�����Main�ļ���������test\train\trainval\val�ĸ��ļ����������ݼ������
2.2 �������
��data/classesĿ¼�±�����������ļ���������vis.names�����ݣ����Լ������д�뱣��
�������ط����õ�coco.names�ļ�������Ϊ�˷�ֹ���������ǽ�����ļ�����ÿ��names�ļ�����Ϊ�Լ������ʡȥ�����ط���
2.3 ��anchors
ͨ�������㷨�������������ݼ���anchors��ֱ������anchors_generate.py�ļ��������9������ֵ������
$ python anchors_generate.py
anchors are:
45,45, 96,70, 80,112, 157,108, 118,172, 230,154, 169,246, 330,241, 279,358
the average iou is:
0.7574684115499671
��anchorsֵд��data/anchors/basline_anchors�ļ���
2.4 ����ѵ���ļ�
����split.py�ļ���������2007_test.txt 2007_train.txt 2007_val.txt�����ļ���ʵ��ѵ��ʱ���������ļ��ж�ȡ���ݣ��ı��е����ݸ�ʽ����
image_path x_min, y_min, x_max, y_max, class_id x_min, y_min ,..., class_id x_min, y_min # ����
xxx/xxx.jpg 18.19,6.32,424.13,421.83,20 323.86,2.65,640.0,421.94,20
xxx/xxx.jpg 48,240,195,371,11 8,12,352,498,14
2.5 �������ļ�
��core/config.py�ļ�����Ҫ�����Լ��Դ��������BATCH_SIZEֵ�����鲻Ҫ̫��������ᱨ�ڴ����
2.6 ��ʼѵ��
�����������裬����������ݺ������ļ��������������Ϳ��Կ�ʼѵ���ˣ�ֱ������train.py�ļ�����
$ python train.py
2019-11-26 15:36:24.311910: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-11-26 15:36:24.981981: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1411] Found device 0 with properties:
name: TITAN V major: 7 minor: 0 memoryClockRate(GHz): 1.455
pciBusID: 0000:04:00.0
totalMemory: 11.78GiB freeMemory: 10.81GiB
2019-11-26 15:36:24.982042: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1490] Adding visible gpu devices: 0
2019-11-26 15:36:25.509204: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-11-26 15:36:25.509273: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] 0
2019-11-26 15:36:25.509286: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0: N
2019-11-26 15:36:25.509692: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1103] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10435 MB memory) -> physical GPU (device: 0, name: TITAN V, pci bus id: 0000:04:00.0, compute capability: 7.0)
=> Restoring weights from: ./checkpoint/yolov3_coco_demo.ckpt ...
train loss: 67.78: 100%|����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 1427/1427 [05:24<00:00, 4.40it/s]
=> Epoch: 1 Time: 2019-11-26 15:43:56 Train loss: 786.53 Test loss: 93.00 Saving ./checkpoint/yolov3_train_loss=786.5312.ckpt ...
train loss: 20.86: 100%|����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 1427/1427 [04:58<00:00, 4.79it/s]
=> Epoch: 2 Time: 2019-11-26 15:49:39 Train loss: 39.11 Test loss: 22.08 Saving ./checkpoint/yolov3_train_loss=39.1093.ckpt ...
train loss: 20.92: 100%|����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 1427/1427 [04:55<00:00, 4.83it/s]
=> Epoch: 3 Time: 2019-11-26 15:55:22 Train loss: 16.35 Test loss: 14.92 Saving ./checkpoint/yolov3_train_loss=16.3459.ckpt ...
train loss: 16.56: 100%|����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 1427/1427 [04:52<00:00, 4.88it/s]
=> Epoch: 4 Time: 2019-11-26 16:01:02 Train loss: 13.07 Test loss: 13.02 Saving ./checkpoint/yolov3_train_loss=13.0722.ckpt ...
train loss: 6.54: 100%|������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 1427/1427 [04:52<00:00, 4.89it/s]
=> Epoch: 5 Time: 2019-11-26 16:06:40 Train loss: 11.71 Test loss: 11.79 Saving ./checkpoint/yolov3_train_loss=11.7074.ckpt ...
����ʱ�ᱣ��ÿ��Epoch��Ȩ���ļ�
3 ģ����֤
�����ϱߵ�ѵ��������checkpoint�ļ���������ѵ���ļ������ǿ��Զ�ÿ��ģ�ͽ�����֤����mAPֵ���Ӷ��������ģ��
������confi.py�ļ���TEST���֣���Ҫ�ǽ�__C.TEST.WEIGHT_FILE��ֵ��Ϊcheckpoint��ģ���ļ����ɣ�Ȼ���������½ű�
$ python evaluate.py
$ cd mAP
$ python main.py -na
������ʾ��ÿ������APֵ���Ӷ�����ܵ�mAP������mAPѡ��һ������ģ�;ͺ���
���������ģ�͵�ѵ�������Թ��̡�