最近在看这篇论文,NIPS2017的best paper。翻译了一下,有些地方自己稍微总结了下。
Abstract(摘要)
在不完全信息博弈中,子博弈中的最优策略可能取决于其他未达到的子博弈中的策略。因此,与完美信息博弈不同,子博弈不能孤立地解决,而必须考虑整个博弈的整体策略。然而,可以先对整个博弈进行近似求解,然后在单个子博弈中对其进行改进。这被称为子博弈求解。我们介绍了在理论和实践上都优于之前的方法的子博弈求解技术。我们还展示了如何调整它们以及过去的子博弈求解技术,以响应原始动作抽象之外的对手动作。这明显优于现有的最先进的方法,即action translation(动作翻译)。最后,我们展示了,随着博弈沿着博弈树向下进行,子博弈求解可以重复使用,这导致很低的exploitability(可利用度)。这些技术是Libratus的关键组成部分,Libratus是第一个在单挑无限注德州扑克中击败顶级人类的AI。
1 Introduction(介绍)
在完全信息博弈中,在决策点确定最优策略只需要知道博弈树的当前节点和该节点之外的剩余博弈树(根植于该节点的子博弈)。几乎每一个人工智能都利用这一事实进行完全的信息博弈,包括在国际象棋和围棋中击败顶级人类的人工智能。在跳棋博弈中,甚至可以使用将博弈分解成更小的独立子博弈的能力来解决整个博弈。然而,在不完全信息博弈中,仅仅利用子博弈的知识来确定子博弈的最优策略是不可能的,因为博弈树的确切节点通常是未知的。相反,最优策略可能取决于对手在其他一些未实现的子博弈中可能收到的值。尽管这是违反直觉的,但我们在第2节中提供了一个演示。
过去不完全信息博弈的方法通常是预先解决整个博弈,而不是依靠子博弈分解。例如,heads up limit Texas hold'em,一种具有1013个决策点的相对简单的扑克形式,基本上是在不分解的情况下求解的。然而,这种方法不能扩展到更大的博弈,例如heads up no limit Texas hold'em,这是不完全信息博弈解决的主要基准,有10161个决策点。
在这种大型博弈中,计算策略的标准方法是首先生成一个对博弈的抽象,这是一个较小版本的博弈,尽可能保留原始博弈的战略特征。例如,可以离散化连续动作空间。该抽象博弈求解后,它的解将在完整博弈中的状态映射到抽象博弈中的状态时使用。我们将抽象的解决方案(或者更一般地说,是博弈的任何近似解决方案)称为蓝图策略。
在高度抽象的博弈中,蓝图策略可能远不是真正的解决方案。子博弈解决方法试图通过实时为遇到的子博弈解决更细粒度的抽象,同时将其解决方案与总体蓝图策略相匹配,从而改进蓝图策略。
2 Coin Toss(抛硬币)
在这一部分中,我们提供了一种直觉,解释为什么不完全信息的子博弈不能被孤立地解决。我们在一个“掷硬币”的简单博弈中演示了这一点,如图1a所示,它将作为贯穿本文的一个运行示例。
掷硬币博弈在玩家p1和p2之间进行。图中只显示了p1的奖励;p2总是收到p1奖励的否定。硬币被翻转,以相等的概率落在Heads或Tails上,但只有p1能看到结果。然后,p1在动作“出售”(sell)和“玩”(play)之间进行选择。出售动作将带来一个子博弈,其细节并不重要,但选择出售动作的预期价值(ev)将很重要。(为了简单起见,我们可以在本节中等效地假设,出售会立即获得最终奖励,其价值取决于硬币是正面还是反面)。如果硬币Heads,它被认为是幸运的,此时p1如果选择出售,则会收到0.50美元的EV。另一方面,如果硬币落在Tails,就被认为是不吉利的,而此时p1选择出售,则得到的EV为-0.50美元。(也就是说,P1必须平均支付0.50美元才能摆脱硬币)。如果p1选择了play,那么p2可以猜测硬币是如何落下的。如果p2猜对了,p1将得到-$1的奖励。如果p2猜错了,那么p1会收到$1。p2也可能会弃权,这不应该被选择,这会在后面的章节中提到。我们希望在子游戏S中确定在p1选择play后出现的p2的最佳策略,如图1a所示。

?Figure 1: (a) 掷硬币游戏的例子。“c”表示机会节点。S是一个Player2(p2)子游戏。两个p2节点之间的虚线表示p2无法区分它们。
(b) 掷硬币的公众游戏树。硬币翻转的两个结果只能由p1观察到。
总结一下这个游戏就是:
p1和p2玩抛硬币。抛一个硬币之后,落在heads和tails的概率都是0.5。这个硬币是落在heads还是tails,只有p1能看到,p2看不到。
p1有两个选择,可选择“sell”或者“play”。
如果p1选sell,卖掉硬币:如果硬币落在heads,p1卖掉后得到 $0.5;如果是tails,p1卖掉后得到 -$0.5。
如果p1选play,则游戏继续,接下来由p2来猜硬币是落在heads还是tails:
p2猜对了,p1收益为 -$1(因为是二人零和博弈,p1的收益正好是p2收益的负值,p2得到$1,说明p1失去了$1);
p2猜错了,p1收益为 $1;
p2还有一个选择是forfeit(弃权),这个动作不应该被选择,后面会提到。
我们所要做的事情是:在P1选择了Play之后,在Play所产生的这个子博弈S中,确定P2的最优策略(也就是P2怎么来猜抛硬币的结果能使得自己收益最大)。
接下来列举了三种P2的策略:
(1)如果P2 总猜 Heads
当硬币落在Heads, P1 选 Sell, 得 $0.5
当硬币落在Tails, P1 选 Play, 得 $1
此时,P1 平均得: 0.5 x 0.5 + 0.5 x 1 = $0.75(意味着P2如果采取这个策略,那么P2将平均损失$0.75)
(2)如果P2 总猜 Tails
当硬币落在Tails, P1 选 Sell, 得 -$0.5
当硬币落在Heads, P1 选 Play, 得 $1
此时,P1 平均得: 0.5 x -0.5 + 0.5 x 1 = $0.25(P2平均损失$0.25)
(3)然而,通过猜测25%概率的Heads和75%概率的Tails,p2的收益会更好。
P2 猜 0.25 的 Heads 与 0.75 的 Tails.
硬币落在Heads时: P1选Play,得0.25 x -1 + 0.75 x 1 = $0.5; 选Sell, 得 $0.5
硬币落在Tails时: P1选Play,得-$0.5; 选Sell, 得 -$0.5
此时,P1平均:$0(说明P2在这种策略下,平均损失为0,这种情况对P2来说是最优的)
现在假设当硬币落在Heads上时,预期的回报是 -$0.50,落在Tails上时,预期的回报是 $0.50。很容易看出,P2的“Play”子博弈的最佳策略现在是猜测概率为 75% 的Heads和概率为 25% 的Tails。由此可见,一个玩家在子博弈中的最优策略可以依赖于博弈其他部分的策略和结果。因此,不能只用子博弈的信息来解决子博弈。这是不完全信息博弈相对于完全信息博弈的核心挑战。
(据我个人理解,这一部分列举这3个策略,一是为了让我们熟知不同策略会导致P2的收益不同,所以P2该如何选取策略能使自己的收益最高;二是在本文较为靠前的这一部分就告诉你P2的最优策略是什么,之后的部分所提出的那些方法,都是为了告诉我们,如何进行子博弈求解能够得到上述的最优策略,即“P2猜测25%概率的Heads和75%概率的Tails”这个最优策略你是怎么算出来的。)
3 Notation and Background(符号和背景)
这一部分主要是符号介绍。
在一个两人零和扩展形式的博弈中,有两个玩家,P = {1,2}。H是所有可能节点的集合。
A(h):在一个节点处可选择的action集合,P(h)∈P ∪ c 是在节点h进行动作选择的player们,这里c代表chance。Chance节点会以固定的概率来采取动作a ∈A(h)。
如果在节点h处采取动作a后会走向节点h',那我们写作 h ・ a = h'。
如果在节点h处采取一系列动作之后才会到达h',则写作 。
节点集合 Z ? H 是终止节点。
对于每个player i ∈ P,存在一个payoff函数 :Z → R, 其中u1 = -u2。
非完全信息由information sets(infosets)信息集来表示。对于一个信息集Ii,节点h,h' ∈ 对玩家 i 来说是不可区分的。
(比如在图1(a)中,子博弈S中的两个节点对于P2来说就是不可区分的。因为P2只知道P1采取了“Play”这个动作,但是具体是硬币落在了Heads后,P1选择了play;还是硬币落在了Tails后,P1选择了play,P2是无法得知的。)
一个策略 是对这个信息集的动作集
的一个概率向量(即为这个信息集的每个动作分配一个概率)。然后,采取信息集
的动作a的概率表示为
。对于这个信息集中的每个节点h,有
=
(就是这个信息集中每个节点h的动作概率分布都是一样的)。
一个 full-game 策略 是每个玩家 i 信息集的策略。
一个strategy profile(策略组合) 是一个策略元组,每个player都有一个
(这个元组表示了你的策略
与你的对手们的策略
,例如player 1的对手的策略写作
,在这个例子中因为只有两个玩家,所以
其实也就是playe 2 的策略
)。
player i 的期望回报(expected payoff):如果所有的players都按照策略组合 来play,那么i的期望回报值就是
。其中
代表除了i之外的所有其他玩家(也就是i的对手们)的策略。
![]()
代表所有players都依照策略来进行博弈时,到达节点h的概率(这个公式看起来很长,其实就是路径上所有概率相乘)。
:代表 player i 对这个概率的贡献。(也就是说,如果chance节点以及除了i之外的所有玩家们都选择了能导致最终走到h的那个动作,那么此时到达h的概率是多少)。
:已到达h节点的前提下,到达节点h'的概率。若从h无法到达h',则该值为0。
一个Nash equilibrium(纳什均衡)是一个strategy profile :在这个策略组中,没有任何一个玩家能够通过改变自己的策略而得到提升(也就是说此时如果你要改变策略,那么你得到的收益肯定不会比现在更高)。
![]()
对一个玩家 i 来说,他在纳什均衡下的期望回报值 u 是当他的对手 -i 采取最优策略 时,他所能得到的最大的 u 值。此时,能使玩家 i 得到这个最大 u 值的策略就是
。
而 就是对于任何一个玩家 i 来说,都满足上述条件。
A best response :玩家 i 针对对手策略
而做出的最优策略。
(下面是维基百科关于 best response 的解释:在博弈论中,best response指的是一种策略,这种策略能够根据给定的其他参与者的策略为参与者产生最有利的结果。best response的概念是约翰纳什最著名的贡献,纳什均衡的核心,在这个点上,游戏中的每个玩家都选择了相对其他玩家策略的最佳反应(或最佳反应之一)。)

在二人零和博弈中,exploitability(可利用度)exp() 是指:当对手采取best response时,你所采取的策略
与纳什均衡策略相比还差多少。正式来讲,策略
的exploitability是
![]() 。
。
节点h的expected value(期望值):![]() (节点h处的期望值 = 从 h 到 所有终止节点 z 的概率乘上节点 z 处的收益,然后加和)。
(节点h处的期望值 = 从 h 到 所有终止节点 z 的概率乘上节点 z 处的收益,然后加和)。
一个信息集的value是这个信息集中每个节点值的加权平均。

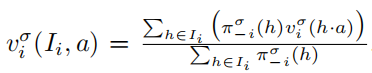
counterfactual best response CBR() 是在未到达的信息集中也最大化其value的best response。更详细一点来说,一个CBR策略是一个有额外条件的best response
,条件是:如果
,那么
。
我们进一步定义counterfactual best response value 为:player i 根据策略 CBR(
)进行play得到的已到达的信息集
的期望值。

一个不完全信息子博弈,我们在本文中简单地称之为子博弈,在大多数情况下(但不是全部),可以描述为包括所有共享先前公共行为的节点(也就是说,两个参与者都可以看到的行为)。例如,在扑克中,一个子游戏是由一系列赌注和公共牌局卡唯一定义的。
图 1b 展示了Coin Toss的公共博弈树。正式地,一个非完全信息子博弈是一个节点集合 ,使得对于所有
,如果
,那么
。并且对于所有
和所有
,如果
,那么
。
定义为S中最早到达的节点集合。也就是说,
![]() (如果节点h在S中,那么它之前的节点都不会属于S)。
(如果节点h在S中,那么它之前的节点都不会属于S)。
4 Prior Approaches to Subgame Solving (子博弈求解的过去方法)
本节回顾了我们建立在不完全信息博弈中的子博弈求解方法。在本节中,我们参考图1a所示的掷币游戏。
如第1部分所述,处理大型不完全信息博弈的标准方法是解决博弈的抽象。抽象的解是整个博弈中的(可能是次优的)strategy profile。我们将这个full-game strategy profile称为blueprint(蓝图策略)。子博弈求解的目的是通过只在子博弈中改变策略来改进蓝图策略。

图2:我们在掷硬币游戏中提到的蓝图策略。Sell动作导致的子博弈没有显示。所有动作的概率都已显示出来。虚线表示两个P2节点共享一个信息集。还显示了每个P1动作的EV。
假设这里有一个Coin Toss的已经计算出来的蓝图策略。
(这里并没有具体说这个蓝图策略是怎么计算出来的,但是这篇论文的作者后来在《Science》上发了一篇论文《Libratus: The Superhuman AI for No-Limit Poker 》,这篇论文里有提到,可以使用MCCFR来计算出一个蓝图策略。)
这个蓝图策略具体是这样:当硬币为Heads时,P1选择Play的概率是0.75;当硬币为Tails时,P1选择Play的概率是0.5.当P1选择Play后,P2猜Heads的概率为0.5,猜Tails的概率为0.25,弃权的概率为0.25。
蓝图策略中Sell子博弈的细节在本节中不相关,但选择Sell动作的EV是相关的。
假设如果P1选择了Sell操作并在之后进行最优博弈,那么当硬币为Heads时,P1将获得$0.5的期望收益,当硬币为Tails时,P1将获得 -$0.5的收益。
我们将尝试去提升当P1选择Play之后P2在子博弈S中的策略。
4.1 Unsafe Subgame Solving (不安全的子博弈求解)
我们首先回顾了最直观的子博弈求解形式,我们称之为不安全的子博弈求解。这种子博弈求解形式假定两个玩家在到达子博弈之前都按照蓝图策略进行博弈。它定义了子博弈S根节点上的概率分布,表示真实博弈状态与该节点匹配的概率。假设此分布是正确的,然后计算子博弈的策略。
在所有子博弈求解算法中,都要求解包含S和几个附加节点的增广子博弈,以确定S的策略。在Coin Toss的蓝图策略中应用不安全的子博弈求解(在p1选择play之后)意味着求解图3a所示的增广子博弈。
具体来说,增广子博弈只包含一个初始机会节点和S。初始机会节点到 的概率为:
![]() 。增强子博弈求解后,它的策略将用于S而不是用蓝图策略。
。增强子博弈求解后,它的策略将用于S而不是用蓝图策略。
(总结:在进行子博弈求解时,先构建一个增强子博弈,然后去求解。不同的求解算法,增强子博弈构建方法不同。在这个unsafe方法中,去掉P1节点,只保留C与子博弈S,然后以原来的蓝图策略的概率为基础,重新计算初始机会节点C与子博弈S之间的概率,这样来构建一个新的增强子博弈。然后接下来再对这个增强子博弈进行求解。)

比如在图3a中,C与P2之间的概率就是根据公式![]() 计算的,其中分子部分是在蓝图策略中到达h的概率,分母部分是蓝图策略中到达S中所有节点h'概率的和。(这里人家只是告诉咱这个unsafe方法是怎么计算的,具体的细节没说,可以自己找论文看一下原理啥的。)
计算的,其中分子部分是在蓝图策略中到达h的概率,分母部分是蓝图策略中到达S中所有节点h'概率的和。(这里人家只是告诉咱这个unsafe方法是怎么计算的,具体的细节没说,可以自己找论文看一下原理啥的。)
不安全的子博弈解决缺乏理论上的求解质量保证,而且在许多情况下,它的性能非常差。事实上,如果把它应用到Coin Toss的蓝图策略中,那么p2总是会选择Heads――而p1可以通过在硬币为Tails时选择Play来进行严重的利用。尽管缺乏理论保证和潜在的不良性能,不安全的子博弈解决是简单的,有时可以产生低可利用性策略,我们之后会讲到。
我们现在开始讨论safe的子博弈求解技术,即确保策略的可利用性不高于蓝图策略的可利用性。(exploitability越低越好,越低说明被对手利用的程度越低,所以本节提到的unsafe方法之所以不安全,就是因为它无法确保它得到的策略的exploitability一定比蓝图策略的低。)
4.2 Subgame Resolving
在Subgame Resolving中,通过求解图3b中所示的增广子博弈,计算出子博弈中p2的安全策略,生成均衡策略。这种增广子博弈不同于unsafe子博弈求解,它在进入S的地方给了P1一个操作“选择退出”,以此来替代P1在对抗P2在S中的蓝图策略时,通过最优博弈得到的EV。(也就是说在这个增强子博弈中,把P1的Sell变成一个“Alternative”,含义是如果P1不选择Play,那么他不再是简单地获得$0.5或者-$0.5,而是用另一个值来替代,具体选哪个值下面讲。)
具体来说,Resolving方法的增广子博弈与不安全子博弈求解的区别如下:
对于每个节点 ,我们在初始chance节点与
之间插入一个新的P1节点
,这个节点只存在于增强子博弈中。这些节点
的集合为
。初始机会节点与每个节点
连接的概率 与 玩家P1到达
的概率成比例。(在图3b中,两个Enter操作的概率与c节点左右两侧的Heads与Tails的概率成比例,具体如何去算,这里没说。)
对于每个节点 ,P1有两个可能的动作。动作 a'S 通往
,动作 a'T 带来一个终止的payoff,这个值为对抗P2的蓝图策略时,P1进行最优博弈所获得的value值,即
。
在Coin Toss的蓝图策略中,当coin落在Heads时,P1选择Play的结果为EV = 0,当coin为Tails时,EV = 0.5。因此,a'T 导致的terminal payoff分别为:硬币落在Heads时为0,落在Tails时为0.5。在增强子博弈中计算完均衡策略 后,P2在子博弈S中将根据计算得到的子博弈策略
来进行博弈,而不是根据蓝图策略。P1的策略
未被使用。
很明显,P1不会比总是选择动作a'T而做得更糟(这个选择获得的EV是P1对抗P2的蓝图策略时所能获得的最高EV)。但是P1也不会比总是选择动作a'T做得更好,因为P2可以简单地根据S的蓝图策略来进行博弈,这意味着动作a'S将会给P1带来和动作a'T一样的EV(因为a'T的EV值就是蓝图策略中的a'S带来的EV值)(如果P1在S中博弈最优)。这样一来,S中的P2策略就不会比蓝图策略更差。在Coin Toss中,如果P2总是选择Heads,那么P1将总是在硬币Heads时选择a'T,在硬币Tails时选择a'S。
Resolving保证了p2的可利用性不会高于蓝图(而且可能会更好)。但是,它可能会错过改进提升策略的机会(也就是说,它可能一直保持蓝图策略不变,那么就不会提升策略,这就会变得毫无意义)。例如,如果我们在Coin Toss游戏中将Resolving应用于示例的蓝图策略中,则增强子博弈的一个解决方案是蓝图本身,因此P2可能会有25%的概率选择“弃权”,即使猜硬币为Heads或Tails比这个动作更优。事实上,Resolving的最初目的并不是为了改进子博弈中的蓝图策略,而是通过将EV保留在子博弈的根节点,然后在需要时实时重建策略,而不是存储整个子博弈策略。
附录A中提到的Maxmargin subgame solving(最大差额子博弈求解),可以通过为每个 定义一个margin(差额):
![]() 并且最大化
并且最大化 。Resolving只是是的所有margins非负。然而,当使用附录C中讨论的均衡值的估计值时,MaxMargin在实践中表现得更差。
5 Reach Subgame Solving
在Section 4中描述的子博弈求解技术仅仅独立考虑了目标子博弈,这有可能导致次优策略。例如,Maxmargin求解应用到Coin Toss的S上,求得的策略是:P2在子博弈S中以5/8的概率选择Heads,以3/8的概率选择Tails。结果是硬币在Heads时,P1选择Play得到EV = -1/4,在Tails时得到EV = 1/4。然而,P1可以简单地在Heads状态下总是选择Sell,在Tails状态下选择Play,P1会得到EV = 3/8 在整个博弈中。在本节中,我们介绍Reach subgame solving,是对过去子博弈求解技术的改进,考虑到对手会从其他子博弈中选择什么。
例如,对于P2来说一个更好的策略是以0.75的概率选择Heads,0.25的概率选择Tails。那么P1在任何情况下选择Sell与Play是一样的,总体的期望收益为0。
然而,只有当P1实际在Heads状态下选择Sell得到EV = 0.5和在Tails状态下选择Sell得到EV = -0.5时,该策略才是最佳的。如果P2按照Sell子博弈(未显示)中的蓝图策略进行博弈,就会出现这种情况;但实际上,如果采取了Sell操作,我们会将子博弈求解应用于Sell子博弈,这将改变P2的策略,从而改变P1的EV。对博弈中遇到的任何子博弈应用subgame solving方法等同于独立地将其应用于所有子博弈;最终,在这两种情况下都会使用相同的策略。因此,我们必须考虑来自其他子博弈的EV可能与蓝图策略所说的不同,因为子游戏求解也将适用于它们。

图4:左:一个修改后的Coin Toss博弈,有两个子博弈。节点C1和C2是公共机会节点,其结果可由P1和P2看到。右图:根据Reach Subgame Solving得到的其中一个子博弈的增强子博弈。如果只有一个子博弈被解决,那么Heads的alternative payoff最多可以是1。但是,如果两个问题都独立解决,那么gife必须在子博弈中分配,并且总和必须至多为1。例如,两个子博弈的alternative payoff可以是0.5。
作为这个问题的一个例子,考虑图四所示的博弈,这个博弈包含了两个相同的子博弈S1和S2(S1中左侧P2与S2中左侧P2都是由C1分出来的,是相同的;同理S1与S2中右侧P2也相同),其蓝图策略为P2分别以50%的概率选择Heads与Tails。对于Heads state,Sell操作带来EV = 0.5,此时Play带来的EV = 0。如果我们仅仅求解S1,那么P2 可承担的是在S1中总是选择Tails,这将导致P1从Heads到达子博弈会得到EV = 1,因为由于chance节点C1,抵达S1的概率为50%。因此P1从Heads选择Play得到的EV = 0.5,从Tails选择Play得到的EV = -0.5,这是最优的。我们能够通过求解一个在Heads时alternative payoff为1的增强子博弈来得到这个S1的策略。在那个增强子博弈中,P2总是选择Tails将是solution(即使不是唯一解)。
然而,如果相同的推理也独立地应用于S2,那么P2可能总是在两个子博弈中选择Tails,P1从Heads状态下选择Play的EV将是1,此时选择Sell的EV将只有0.5。相反,我们可以允许P1从Heads抵达每个子博弈所得到的EV = 0.5(通过为Heads设置alternative payoff为0.5)。在这种情况下,P1选择Play的总体EV只能增长为0.5,即使S1与S2都是独立求解的。
考虑对于每个 ,所有信息集与动作
,P1将沿着这条path走到
。如果,在某些 P1采取动作的
处,有一个不同的动作
能产生更高的EV,如果P1抵达了
,那么说明P1采取的是次优动作。a*与a'的差值定义为gift。我们可以让
的P1的value增长至超过蓝图策略的value(并且在此过程中在
的其他信息集中降低P1的value),只要
的value增加的足够小,那么选择导致
的动作对P1来说仍是次优的。重要的是,我们必须确保,即使所有子博弈的潜在增长加在一起,value的增长也足够小,如图四所示。
(在这篇论文与我们的实验中,我们允许任何从gift下降的信息集按gift的size来增加(例:图四中,来自Heads处的gift为0.5,所以我们允许S1和S2中Heads的P1的值增加0.5)。但是,只要所有子博弈的潜在增长(乘以P1到达该子博弈的概率)不超过原始gift,子博弈之间的任何gift分配都是可以接受的。例如,在图4中,如果我们只对S1应用Reach subgame solving,那么我们可以允许Heads状态在S1中增加1而不是增加0.5。在实践中,一些分配可能比其他的分配更好。我们在这篇文章中使用的划分(为所有子博弈均等分配gift)在实践中做得很好。)
一个复杂的因素是我们假定的gift实际上可能不存在。例如,在Coin Toss中,在Sell子博弈中应用子博弈求解,P1在Heads状态下选择Sell后得到的value会从0.5降到0.25。如果我们独立地求解Play子博弈,我们将无法得知,P1选择Sell后所得的value比蓝图策略提供的更低。因此,为了保证exploitability的理论结果尽可能的强,我们在我们的理论与实验中使用一个lower bound(下界),即什么样的gifts可以在子博弈求解之后应用到其他所有的子博弈上。
形式上,定义为P2的蓝图策略,
为一个P2策略,它是将子博弈求解独立地应用于除S以外的一组不相交的子博弈的结果。因为我们不想为了在S上应用子博弈求解而计算
,让
![]() 作为
作为![]() 的下界,且不需要关于
的下界,且不需要关于的知识。
剩下的证明就不翻啦
6 Nested Subgame Solving
正如我们所讨论的,大型博弈必须被抽象化,以将博弈缩小到可处理的大小。这在具有大型或连续动作空间的博弈中尤其常见。通常,动作空间是通过动作抽象(action abstraction)来离散的,因此抽象中只包含少量的动作。虽然我们可能将自己局限于抽象中包含的行为,但对手可能会选择不在抽象中的行为。在这种情况下,off-tree action可以映射到抽象中的操作,并且可以使用抽象操作中的策略。例如,在一个拍卖博弈中,我们可能在抽象中包含100美元的出价。如果一个玩家出价101美元,我们将其视为100美元。这被称为action translation(动作翻译)。Action translation是处理这一问题的最先进的方法。例如,它已经被年度电脑扑克比赛(ACPC)的所有主要竞争对手所使用。
在这一部分中,我们开发了应用子博弈求解的技术来计算对手的off-tree action的响应,从而避免了动作翻译的需要。也就是说,我们不再是简单地将101美元的出价视为100美元,而是实时计算出对101美元的出价的唯一响应。这也可以用嵌套的方式来响应随后的对手off-tree action。此外,这些技术可用于在博弈树向下进行时求解更细粒度的模型。
(也就是说,在之前的方法中,遇到大型博弈,首先对其进行抽象。在博弈过程中,如果对手的动作不在我们所抽象的动作空间中,那么将这个off-tree action近似地看作抽象动作空间中的某个动作,然后采取这个近似动作的策略。但这样对于这个off-tree action来说,我们所采取的这个近似策略并不是最优策略。所以在这一部分中,不再是近似采取策略,而是真的去求解这个off-tree action的对应策略。)
我们将第一种方法称作“inexpensive”方法。当P1选择了一个off-tree action a,随后会产生一个子博弈S,对于任何P1可能存在的信息集 ,
。这个子博弈本身可能是一个抽象。通过子博弈求解计算出解
, 然后将
与
结合,在扩展的抽象中形成新的蓝图
,该抽象现在包括动作a。当P1再次选择off-tree action时,该过程重复。
为了构造一个safe subgame solving来响应off-tree action a,我们可以通过动作翻译,定义一个跟随a的P2蓝图策略并对其做出最佳响应,从而计算。但是,这可能会导致很高的计算代价并且在实践中可能表现得很差,我们将在之后展示,action translation是具有很高可利用度的。为此我们放松了安全保障,并且使用
作为alternative payoff,其中
是限制在蓝图抽象(不包括动作a)中博弈时,P1在
中的CBV。在这种情况下,exploitability取决于
与
有多近似,这里
是一个P2的最优策略(见附录C)。通常,我们发现
的蓝图抽象中只需要包含少量近似最优的动作,以接近
。即使在连续的动作空间中,我们也可以对任何对手动作的近似得到一个near-optimal response。
“inexpensive”方法不能与Unsafe subgame solving方法结合使用,因为在玩家的抽象之外达到动作的概率是不确定的。然而,通过在h而不是h・a开始子博弈求解,可以使用Unsafe subgame solving(以及所有其他子博弈求解技术)来实现类似的方法。换句话说,如果在节点h处采取的动作a不在抽象中,则在一个较小的包含h的子博弈中采取Unsafe subgame solving(并且向这个抽象中加入动作a)。这个方法跟inexpensive方法比起来增加了子博弈的规模,因为除了a之外,还必须对每一个动作a'∈A(h)重新计算策略。因此我们称此方法为“expensive”方法。我们用这两种方法进行实验。
7 Experiments
实验部分就不翻译啦
8 Conclusion
我们为不完全信息博弈引入了一种子博弈解决技术,与以前的子博弈解决方法相比,它具有更强的理论保证和更好的实际性能。 我们介绍了安全和不安全的子博弈解决技术的可利用性结果。 我们还引入了一种嵌套子博弈解决方法,以响应对手的off-tree动作,并证明这导致了比通常的action translation方法更好的性能。 据我们所知,这是第一次在大型博弈中测量了子博弈解决技术的可利用性。
最后,我们在单挑无限注德州扑克中证明了这些技术在实践中的有效性,这是AI在不完全信息博弈中的主要基准挑战。 我们开发了第一个AI,到达了在单挑无限注德州扑克中击败顶级人类的里程碑。