推荐阅读:
-
这套Github上40K+star学习笔记,可以帮你搞定95%以上的Java面试
-
毫不夸张的说,这份SpringBoot学习指南能解决你遇到的98%的问题
-
给跪了!这套万人期待的 SQL 成神之路PDF,终于开源了
建表及插入数据
聚簇索引和非聚簇索引的数据分布有区别,以及对应的主键索引和二级索引的数据分布也有区别。下面我们看 InnoDB 和 MyISAM 是如何存储下面这个表:
DROP TABLE IF EXISTS `test`; -- 若表已存在,则删除
CREATE TABLE test (id INT NOT NULL,num int NOT NULL,tag CHAR(12) NOT NULL,PRIMARY KEY(id), -- 主键索引KEY(num) -- 辅助索引-- 尝试不同的引擎 MyISAM InnoDB
) ENGINE=MyISAM;
复制代码
然后插入下面的数据,id从1-9,故意把插入顺序打乱,tag代表插入顺序
INSERT test(id, num, tag) VALUES(7, 1, 'no.1');
INSERT test(id, num, tag) VALUES(5, 19, 'no.2');
INSERT test(id, num, tag) VALUES(6, 7, 'no.3');
INSERT test(id, num, tag) VALUES(9, 5, 'no.4');
INSERT test(id, num, tag) VALUES(3, 13, 'no.5');
INSERT test(id, num, tag) VALUES(4, 17, 'no.6');
INSERT test(id, num, tag) VALUES(2, 3, 'no.7');
INSERT test(id, num, tag) VALUES(8, 23, 'no.8');
INSERT test(id, num, tag) VALUES(1, 11, 'no.9');
复制代码
MyISAM的数据存储
MyISAM按照数据插入的顺序存储在磁盘上,我们假设第一行数据在数据库表文件中的偏移位置是1,以此类推。 如下图
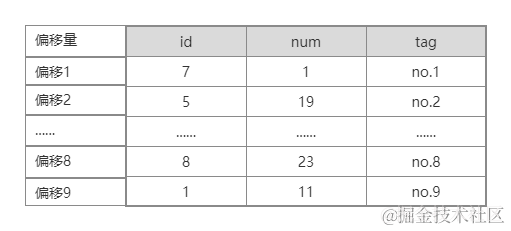
现在我们验证一下,使用 SELECT * FROM test; 扫描全表(SELECT * 不会使用任何索引,可以用 explain 实际观察下),输出的顺序正是我们sql插入的顺序,大家可以调整sql的顺序再次插入,观察输出顺序。

搞清楚了MyISAM的数据存储方式,再来看下主键索引的存储。我们假设每个磁盘块只能存储两个节点数据,MyISAM的主键分布如下图:
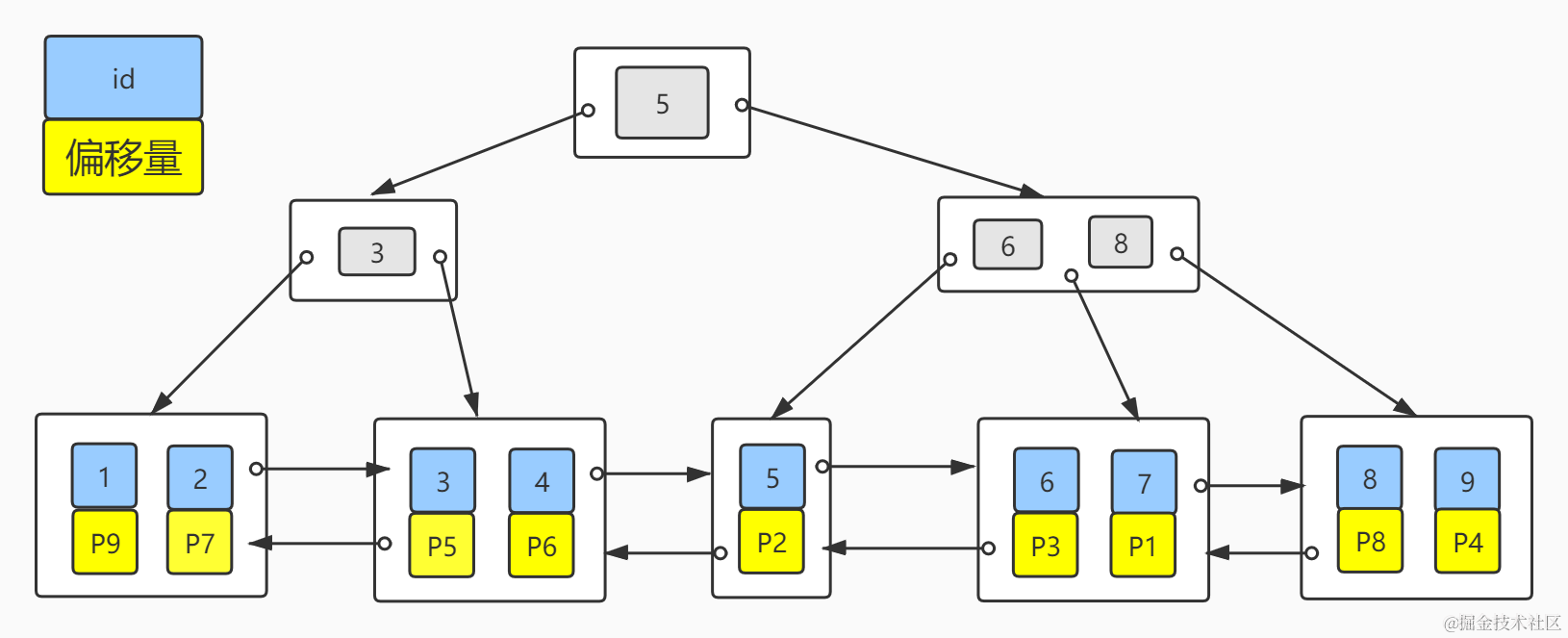
其实MyISAM的二级索引和主键索引并无区别,只是名称不同罢了,二级索引key(num)分布如下图:
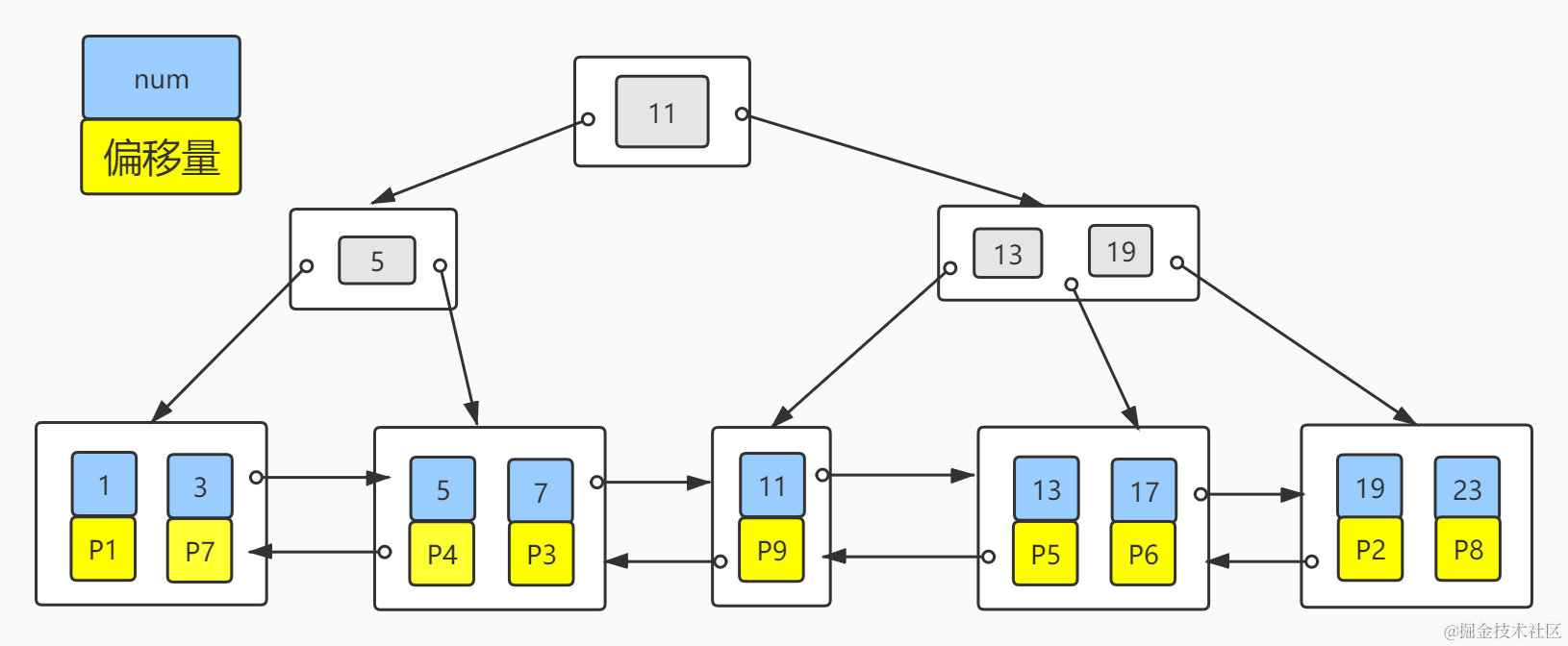
二级索引子节点也只存储了索引列(num)和文件的偏移量(P),但可以看出num是有序的,这在范围查找(比如:where num > 3)是非常有利的,但文件的偏移量并没有规律,当需要回表查询其他字段,可能会导致多次随机I/O。
当对增加数据时MyISAM直接添加到文件尾部,不需要移动其他数据,而且更新主键时,也不会导致其他行数据移动,但它不支持行级锁,修改时直接锁表。若不需要事务支持,对读多写少的场景可以考虑MyISAM引擎,但不要默认使用MyISAM引擎。
InnoDB的数据存储
InnoDB支持聚簇索引,所以使用非常不同的方式存储同样的数据。InnoDB数据存储方式如下图:

注意整个树和MyISAM的主键索引非常类似,唯一的区别是叶子节点,InnoDB的叶子节点存储了整个行数据(id、num、tag),而不是只有索引。聚簇索引“就是”整个表,而不像MyISAM那样需要单独的行存储文件。当更新主键id时,可能会导致数据行移动,因为索引和数据是存储在一起的。若主键id是乱序写入的,InnoDB不得不做页分裂操作时,至少会导致修改三个页(分裂产生的两个页,以及他们的父节点页面),而不是一个页,这和MyISAM新增数据时添加到文件尾部很不一样。所以使用InnoDB引擎尽可能的按主键顺序插入数据。
InnoDB的二级索引和聚簇索引也不一样。InnoDB二级索引的叶子节点中存储的不是行数据的“偏移量”,而是主键值。这意味着通过二级索引查找行数据,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行数据。这里做了重复的工作:两次B-Tree查找,而不是一次。这样的策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。二级索引的数据分布如下图:
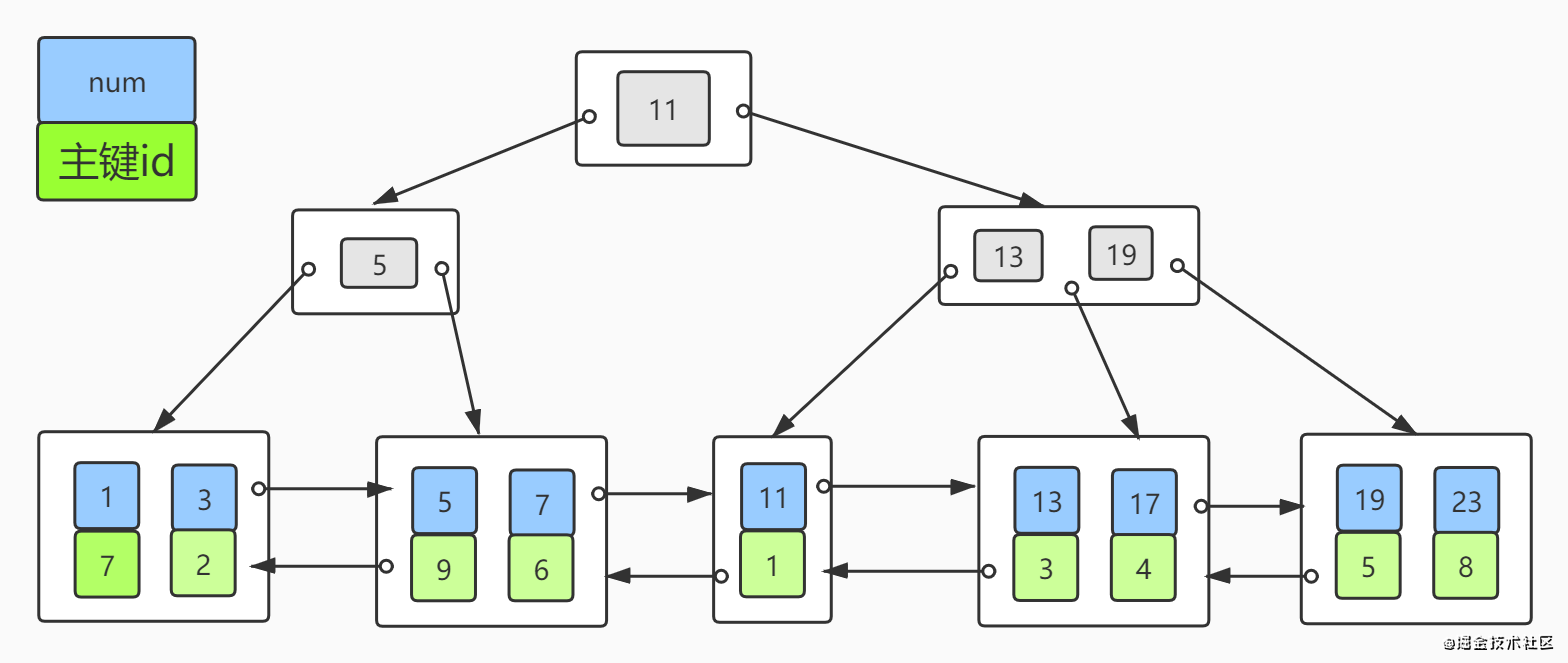
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引InnoDB会隐式的定义一个主键作为聚簇索引。选择主键最好是自增id,如果采用字符串当做主键,不仅仅会增加聚簇索引的大小,也会增加二级索引的大小(二级索引叶子节点包含主键值),并且字符串匹配需要一个个字符判断,更加降低索引的查找性能。当然某些场景使用字符串作为主键带来的优势要比这些损失更有利,需要根据场景具体评估。