ЗжРрЛиЙщ
ВщПДЯЕЭГздДјЕФЪ§ОнМЏ

ЕМШыЪ§ОнВЂфЏРРаХЯЂ
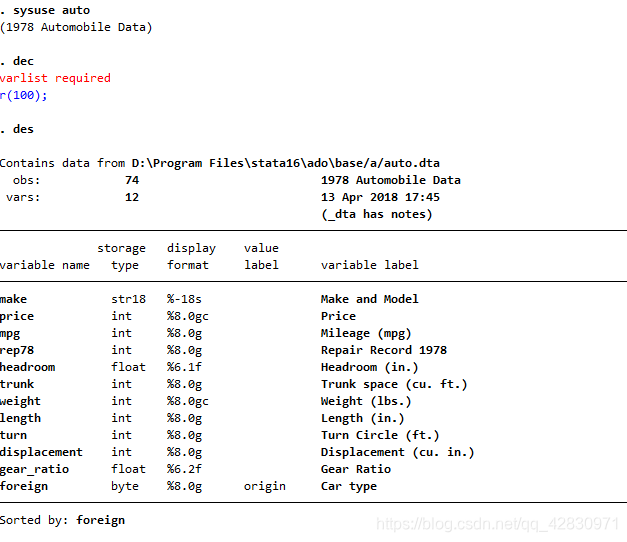
вдЩЯЪЧЮвМЧзХЭцЕФЃЌОљгыБОНкЮоЙиЁЃ
ЕМШыЭтВПЪ§Он
Ъ§ОнМЏЯТдиЕижЗЃК
http://econometrics-stata.com/col.jsp?id=101
ТЗОЖздааНтбЙаоИФ
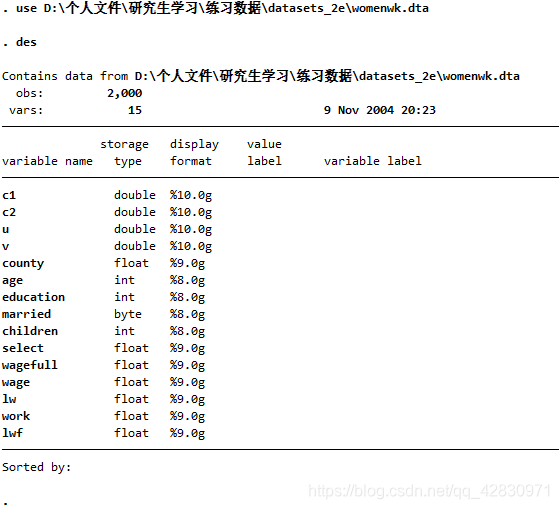
ЗжРрЖўжЕЛиЙщ
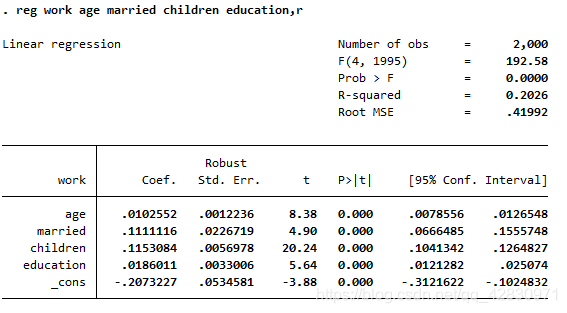
.ЯпадOLS
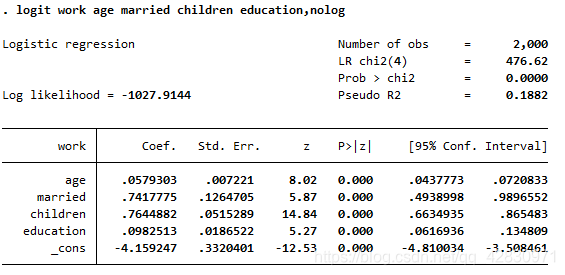
.ЪЙгУlogitЛиЙщ
ЙРМЦ ІТ\betaІТ
КЏЪ§аЮЪНЃК
PЮЊy=1ЗЂЩњЕФИХТЪ,МДУПвЛРрЕФИХТЪ

ЛиЙщУќСюЃК
аТИХФюPseudo R2 БэЪОзМRЗНЃЌ

ПЩвдаДЮЊЃК

втЮЖзХЃК
ЃЈЖдЪ§КЏЪ§ЪЕМЪЪЕМЪШЁжЕ-жЛКЌГЃЪ§ЯюЕФЖдЪ§ШЁжЕЃЉгыЃЈЖдЪ§здШЛКЏЪ§ПЩФмЕФзюДѓШЁжЕ-жЛКЌГЃЪ§ЯюЕФЖдЪ§ШЁжЕЃЉжЎБШЃЌвтЮЖзХМгШыЗжРрБфСПФмЙЛШУФЃаЭЕФзМШЗЕФЩЯЩ§ЖрЩйЁЃ
ЛиЙщНсЙћЕФЕФНтЖСЃК
LRЮЊ476.62ЃЌLRЕФPжЕМьбщЪЧ0.00000<0.05ЃЌЫЕУїЗНГЬећЬхЪЧЯджјЕФЃЌLR = n*RЗН ДѓбљБОЯТЗўДгПЈЗНЗжВМ
Pseudo R2 БэЪОзМRЗНЃКга0.1882,ЦфКЌвхРрЫЦгкФтКЯгХЖШ
ЦфcoefЮЊИїздБфСПЕФЯЕЪ§ІТ\betaІТЃЌЖдгІPжЕЮЊИїздЯджјадЫЎЦН
$exp(\beta)$БэЪОXУПдіМгвЛЕЅЮЛ,ЕМжТНсЙћЗЂЩњЕФИХТЪБШдіМгЕФБЖЪ§
ЛуБЈ exp(ІТ)exp(\beta)exp(ІТ)ЕФУќСюШчЯТЃК
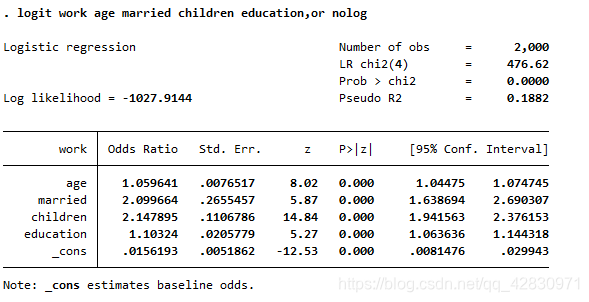
НтЪЭЃК
вдlist the example of coefficient about married's and age's вбЛщИОХЎВЮМгЙЄзїЕФМИТЪБШЪЧЮДЛщИОХЎЕФ2.099664БЖЃЈМДИпГі109.9664%ЃЉЃЛФъСфУПдіМгвЛЫъЃЌВЮМгЙЄзЪЕФМИТЪБШді Мг5.9641%ЃЌЦфЫћЕФБфСПРрЫЦНтЪЭ
are you ЛЙ ok?ЙўЙўЃЌМЬајЃЌШчЙћФуВЛЯраХетИіФЃаЭЃЌФуПЩвдЪЙгУlogitЮШНЁБъзМЮѓВюЃЌЯђЯТПДЁЃ
ЪЙгУlogitЮШНЁБъзМЮѓВюНјааЙРМЦЃК
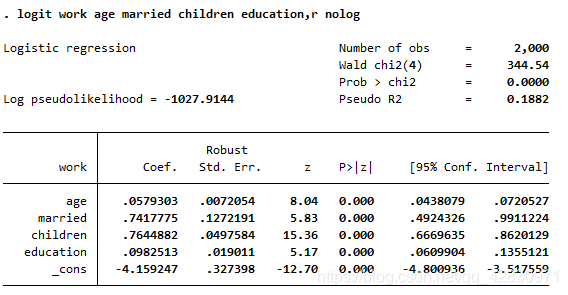
гыЦеЭЈЕФЙРМЦЮоЬЋДѓВюБ№ЃЌвђДЫВЛашвЊЕЃаФФЃаЭЩшЖЈЦЋЮѓ
ПДвЛЯТБпМЪаЇгІ
ЯИжТЕФЗжЮіЃЌБпМЪаЇгІ
ФЃаЭЕФЦНОљБпМЪаЇгІ
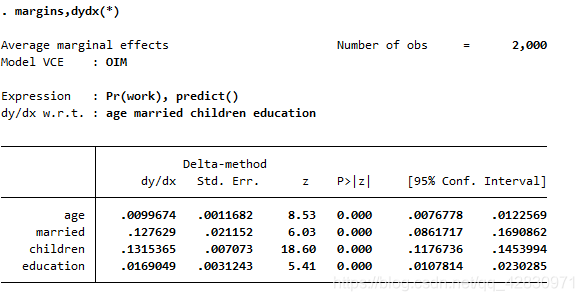
етИіНсЙћКЭЪЙгУOLSЛиЙщГіРДЕФРрЫЦЃЌецЕФРрЫЦЁЃЖМЪЧБпМЪСПТяЁЃ
бљБООљжЕДІЕФБпМЪаЇгІ
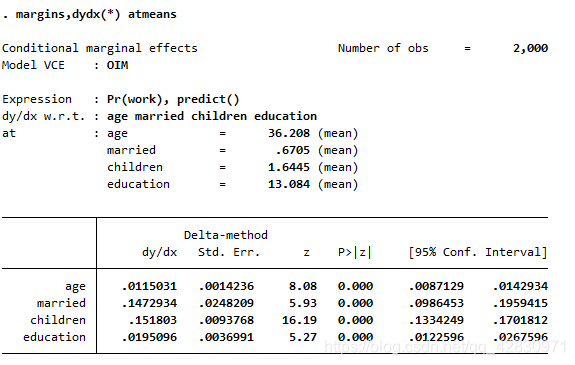
бљБОЬиЖЈжЕЕФБпМЪаЇгІ
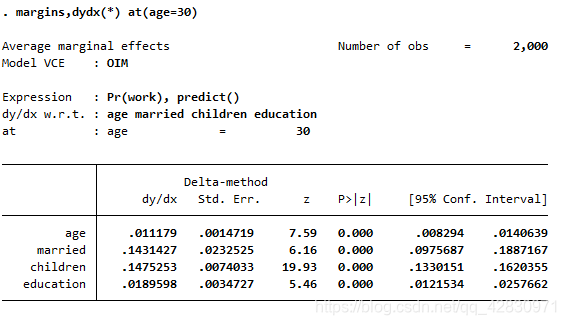
МЦЫуLogitЕФзМШЗдЄВтБШТЪ
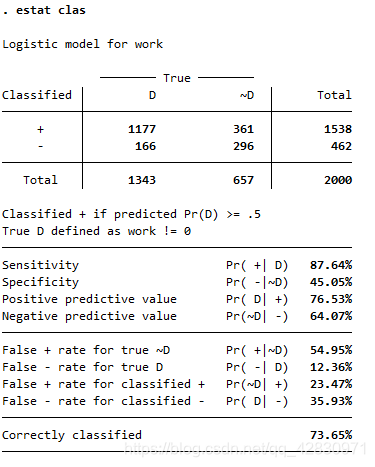
зМШЗТЪга73.65%ЃЌзМШЗТЪЛЙПЩвд
НтОізщФкЯрЙиЃЌОлРрБфСПЛиЙщ
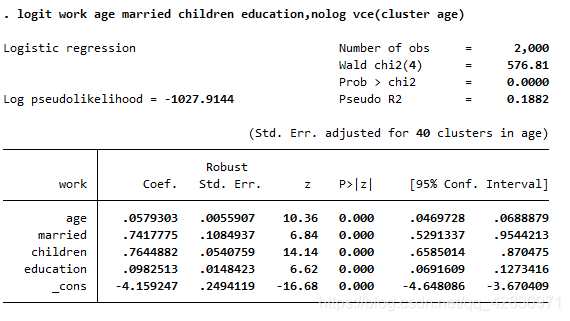
ЕБШЛСЫЃЌЮвУЧМйЩшСЫФъСфДцдкзщФкЯрЙи