гХЕуЃКИУdeep sortЫуЗЈЛљгкsortЫуЗЈНјааИФНјЃЌРћгУвЛИіre-id ФЃаЭЮЊФПБъЩњГЩвЛИіЭтЙлЬиеїЃЌЭЌЪБНсКЯСЫдЫЖЏ(motion)КЭЭтЙл(appearance)аХЯЂФмЙЛзЗзйИќГЄекЕВЪБМфЕФЭЌвЛФПБъЃЌМѕЩйФПБъID ЬјБфДЮЪ§ЃЌвВгааЇНЕЕЭСЫ ФПБъIDЖЊЪЇЕФДЮЪ§ЁЃ
ТлЮФСДНгЃКhttps://arxiv.org/abs/1703.07402
ДњТыСДНгЃКhttps://github.com/nwojke/deep_sort
еЊвЊ
МђЕЅЕФдкЯпКЭЪЕЪБИњзйЃЈSORTЃЉЪЧвЛжжЪЕгУЕФЗНЗЈЃЌжївЊеыЖдМђЕЅЕФЖрФПБъИњзйЪЧвЛИігааЇЕФЫуЗЈЁЃ дкБОЮФжаЃЌЮвУЧМЏГЩСЫЭтЙлаХЯЂвдЬсИпSORTЕФадФмЁЃ гЩгкетвЛРЉеЙЃЌЮвУЧФмЙЛдкИќГЄЕФекЕВЧщПіЯТРДИњзйФПБъЃЌДгЖјгааЇЕиМѕЩйСЫid switchЕФДЮЪ§ЁЃ БОзХдЪМПђМмЕФОЋЩёЃЌЮвУЧНЋаэЖрМЦЫуИДдгаджУгкРыЯпдЄбЕСЗНзЖЮЃЌдкДЫНзЖЮжаЃЌЮвУЧдкДѓЙцФЃааШЫжиЪЖБ№Ъ§ОнМЏЩЯбЇЯАЩюЖШЙиСЊmetricЁЃ дкЯпгІгУЪБЃЌЮвУЧЪЙгУЪгОѕЭтЙлПеМфжаЕФзюНќСкОгВщбЏРДНЈСЂВтСПгыЙьЕРЕФЙиСЊЁЃ ЪЕбщЦРЙРБэУїЃЌЮвУЧЕФРЉеЙНЋid switchЕФЪ§СПМѕЩйСЫ45ЃЅЃЌДгЖјдкИпжЁЫйТЪЯТЪЕЯжСЫзмЬхОКељадФмЁЃ

ЭМ1ЃКдкЦЕЗБекЕВЕФГЃМћИњзйЧщПіЯТЃЌЮвУЧЕФЗНЗЈдкMOTЬєеНЪ§ОнМЏЩЯЕФЪОР§ЪфГі[15]ЁЃ
1, в§бд
гЩгкФПБъМьВтЕФзюаТНјеЙЃЌtracking-by-detectionвбГЩЮЊЖрФПБъЯѓИњзйЕФжївЊЗЖР§ЁЃдкетжжЗЖР§жаЃЌЭЈГЃдквЛДЮДІРэећИіЪгЦЕХњДЮЕФШЋОжгХЛЏЮЪЬтжаевЕНФПБъЙьМЃЃЈtrajectoriesЃЉЁЃР§ШчЃЌСїЖЏЭјТчЙЋЪН[1ЁЂ2ЁЂ3]КЭИХТЪЭМаЮФЃаЭ[4ЁЂ5ЁЂ6ЁЂ7]вбГЩЮЊетжжРраЭЕФСїааПђМмЁЃЕЋЪЧЃЌгЩгкНјааХњДІРэЃЌвђДЫетаЉЗНЗЈВЛЪЪгУгкдкЯпЗНАИЃЌ вђЮЊЦфБиаыдкУПИіЪБМфstepОљЬсЙЉФПБъ idЁЃИќДЋЭГЕФЗНЗЈЪЧЖржиМйЩшИњзйЃЈMHTЃЉ[8]КЭСЊКЯИХТЪЪ§ОнЙиСЊЙ§ТЫЦїЃЈJPDAFЃЉ[9]ЁЃетаЉЗНЗЈж№жЁжДааЪ§ОнЙиСЊЁЃдкJPDAFжаЃЌЭЈЙ§ИљОнИїИіЖШСПЕФЙиСЊПЩФмадЖдИїИіЖШСПНјааМгШЈРДЩњГЩЕЅвЛзДЬЌМйЩшЁЃдкMHTжаЃЌЛсИњзйЫљгаПЩФмЕФМйЩшЃЌЕЋЪЧБиаыНЋаоМєЗНАИгІгУгкМЦЫуЕФПЩДІРэадЁЃСНжжЗНЗЈзюНќЖМдкАДtracking-by-detectionГЁОАжаБЛжиаТбаОП[10ЃЌ11]ЃЌВЂЯдЪОГіПЩЯВЕФНсЙћЁЃЕЋЪЧЃЌетаЉЗНЗЈЕФадФмДјРДСЫИќИпЕФМЦЫуКЭЪЕЯжИДдгадЁЃ
МђЕЅЕФдкЯпКЭЪЕЪБИњзйЃЈSORTЃЉ[12]ЪЧвЛжжИќЮЊМђЕЅЕФПђМмЃЌИУПђМмЪЙгУВтСПБпНчПђжиЕўЕФЙиСЊЖШСПЃЈassociation metricЃЉЕФайбРРћЫуЗЈЃЌдкЭМЯёПеМфжажДааПЈЖћТќТЫВЈКЭж№жЁЪ§ОнЙиСЊЁЃ етжжМђЕЅЕФЗНЗЈПЩвддкИпжЁЫйТЪЯТЪЕЯжСМКУЕФадФмЁЃ дкMOTЬєеНЪ§ОнМЏ[13]ЩЯЃЌSORTНсКЯSOTAЕФааШЫМьВтЦї[14]дкБъзММьВтЩЯЕФЦНОљХХУћИпгкMHTЁЃ етВЛНіЧПЕїСЫФПБъМьВтЦїадФмЖдећЬхИњзйНсЙћЕФгАЯьЃЌЖјЧвДгДгвЕШЫдБЕФНЧЖШРДПДвВЪЧживЊЕФМћНтЁЃ
ОЁЙмдкИњзйОЋЖШКЭзМШЗадЗНУцзмЬхЩЯШЁЕУСЫСМКУЕФадФмЃЌЕЋSORTЗЕЛиСЫЯрЖдДѓСПЕФidentity sweitchsЃЈid ЬјБфЃЉЁЃ етЪЧвђЮЊЫљВЩгУЕФЙиСЊЖШСП(association metric)НідкзДЬЌЙРМЦВЛШЗЖЈадНЯЕЭЪБВХЪЧзМШЗЕФЁЃ вђДЫЃЌSORTдкИњзйекЕВЗНУцДцдкШБЯнЃЌвђЮЊекЕВЭЈГЃЛсГіЯждкЧАЪгЩуЯёЭЗГЁОАжаЁЃ ЮвУЧЭЈЙ§НЋНсКЯЖШСП(association metric)ЬцЛЛЮЊНсКЯСЫдЫЖЏ(motion)КЭЭтЙлаХЯЂ(appearance infomation)ЕФИќШЋУцЕФЖШСПРДНтОіДЫЮЪЬтЁЃ ЬиБ№ЪЧЃЌЮвУЧгІгУСЫОЙ§бЕСЗЕФОэЛ§ЩёОЭјТчЃЈCNNЃЉЃЌвдЧјЗжДѓЙцФЃааШЫжиЪЖБ№Ъ§ОнМЏЩЯЕФааШЫЁЃ ЭЈЙ§ИУЭјТчЕФМЏГЩЃЌЮвУЧЬсИпСЫеыЖдЖЊЪЇЃЈmissesЃЉКЭекЕВЃЈocclusionsЃЉЕФТГАєадЃЌЭЌЪБЪЙЯЕЭГвзгкЪЕЪЉЃЌИпаЇВЂЪЪгУгкдкЯпЗНАИЁЃ ЮвУЧЕФДњТыКЭОЙ§дЄЯШбЕСЗЕФCNNФЃаЭвбЙЋПЊЬсЙЉЃЌвдДйНјбаОПЪЕбщКЭЪЕМЪгІгУПЊЗЂЁЃ
2ЃЌОпгаЩюЖШЙиСЊЖШСПЕФSORT
ЮвУЧВЩгУОпгаЕнЙщПЈЖћТќТЫВЈКЭж№жЁЪ§ОнЙиСЊЕФГЃЙцЕЅвЛМйЩшИњзйЗНЗЈЁЃ дквдЯТВПЗжжаЃЌЮвУЧНЋИќЯъЯИЕиУшЪіДЫЯЕЭГЕФКЫаФзщМў
2.1 Track ДІРэКЭзДЬЌЙРМЦ
track ДІРэКЭПЈЖћТќТЫВЈПђМмгыSORT[12]жаЕФдЪМЙЋЪНЛљБОЯрЭЌЁЃ ЮвУЧМйЩшвЛИіЗЧГЃЦеЭЈЕФИњзйГЁОАЃЌЦфжаЯрЛњУЛгаБъЖЈЃЌВЂЧвЮвУЧУЛгаПЩгУЕФздЮвдЫЖЏаХЯЂЁЃ ОЁЙметаЉЧщПіЖдЙ§ТЫПђМмЙЙГЩСЫЬєеНЃЌЕЋЫќЪЧзюНќЕФЖрФПБъИњзйЛљзМВтЪджазюГЃгУЕФЩшжУ[15]ЁЃ вђДЫЃЌЮвУЧЕФИњзйГЁОАЪЧдкАќКЌБпНчПђжааФЮЛжУ![]() ЃЌзнКсБШ
ЃЌзнКсБШ![]() ЃЌИпЖШ h МАЦфдкЭМЯёзјБъжаЕФИїздЫйЖШЕФАЫЮЌзДЬЌПеМф
ЃЌИпЖШ h МАЦфдкЭМЯёзјБъжаЕФИїздЫйЖШЕФАЫЮЌзДЬЌПеМф![]() ЩЯЖЈвхЕФ ЁЃ ЮвУЧЪЙгУДјгадШЫйдЫЖЏКЭЯпадЙлВтФЃаЭЕФБъзМПЈЖћТќТЫВЈЦїЃЌЦфжаЮвУЧНЋБпНчзјБъ
ЩЯЖЈвхЕФ ЁЃ ЮвУЧЪЙгУДјгадШЫйдЫЖЏКЭЯпадЙлВтФЃаЭЕФБъзМПЈЖћТќТЫВЈЦїЃЌЦфжаЮвУЧНЋБпНчзјБъ![]() зїЮЊЖдЮяЬхзДЬЌЕФжБНгЙлВтЁЃ
зїЮЊЖдЮяЬхзДЬЌЕФжБНгЙлВтЁЃ
ЖдгкУПИіtrack kЃЌЮвУЧМЦЫуздЩЯвЛДЮГЩЙІЕФВтСПЙиСЊ ![]() вдРДЕФжЁЪ§ЁЃ дкПЈЖћТќТЫВЈЦїдЄВтЦкМфЃЌДЫМЦЪ§ЦїЛсдіМгЃЌВЂЧвдкЙьМЃЃЈtrackЃЉгыВтСП(measurement)ЯрЙиСЊЪБЛсжижУЮЊ0ЁЃ ГЌЙ§дЄЖЈвхЕФзюДѓage
вдРДЕФжЁЪ§ЁЃ дкПЈЖћТќТЫВЈЦїдЄВтЦкМфЃЌДЫМЦЪ§ЦїЛсдіМгЃЌВЂЧвдкЙьМЃЃЈtrackЃЉгыВтСП(measurement)ЯрЙиСЊЪБЛсжижУЮЊ0ЁЃ ГЌЙ§дЄЖЈвхЕФзюДѓage ![]() ЕФЙьЕР(track)БЛЪгЮЊвбРыПЊГЁОАЃЌВЂДгЙьЕРМЏ(track set)жаЩОГ§ЁЃ ЖдгкЮоЗЈгыЯжгаЙьЕРЯрЙиСЊЕФУПДЮМьВтЃЌЖМЛсЦєЖЏаТЕФЙьЕРМйЩш(track hypotheses)ЁЃ етаЉаТtracksдкЧАШ§жЁжаБЛЗжРрЮЊднЖЈЁЃ дкетЖЮЪБМфФкЃЌЮвУЧЯЃЭћУПИіЪБМфВНЖМФмГЩЙІНјааВтСПЙиСЊЁЃ дкЧАШ§жЁжаЮДГЩЙІгыВтСПЙиСЊЕФЙьЕР(track)НЋБЛЩОГ§ЁЃ
ЕФЙьЕР(track)БЛЪгЮЊвбРыПЊГЁОАЃЌВЂДгЙьЕРМЏ(track set)жаЩОГ§ЁЃ ЖдгкЮоЗЈгыЯжгаЙьЕРЯрЙиСЊЕФУПДЮМьВтЃЌЖМЛсЦєЖЏаТЕФЙьЕРМйЩш(track hypotheses)ЁЃ етаЉаТtracksдкЧАШ§жЁжаБЛЗжРрЮЊднЖЈЁЃ дкетЖЮЪБМфФкЃЌЮвУЧЯЃЭћУПИіЪБМфВНЖМФмГЩЙІНјааВтСПЙиСЊЁЃ дкЧАШ§жЁжаЮДГЩЙІгыВтСПЙиСЊЕФЙьЕР(track)НЋБЛЩОГ§ЁЃ
2.2 ЗжХфЮЪЬт
НтОідЄВтЕФПЈЖћТќзДЬЌгыаТЕНДяЕФВтСПжЕжЎМфЕФЙиСЊЕФГЃЙцЗНЗЈЪЧНЈСЂПЩвдЪЙгУайбРРћЫуЗЈНтОіЕФЗжХфЮЪЬтЁЃ дкетИіЮЪЬтБэЪіжаЃЌЮвУЧЭЈЙ§НсКЯСНИіЪЪЕБЕФжИБъРДећКЯдЫЖЏКЭЭтЙлаХЯЂЁЃ
ЮЊСЫећКЯдЫЖЏаХЯЂЃЌЮвУЧЪЙгУдЄВтЕФПЈЖћТќзДЬЌгыаТЕНДяЕФВтСПжЕжЎМфЕФЃЈЦНЗНЃЉТэЪЯОрРыЃК
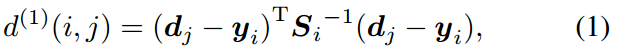
ЦфжаЃЌЮвУЧгУ![]() БэЪОЕк i ИіЙьЕРЗжВМЕНВтСППеМфЕФЭЖгАЃЌгУ
БэЪОЕк i ИіЙьЕРЗжВМЕНВтСППеМфЕФЭЖгАЃЌгУ![]() БэЪОЕк j ИіbboxМьВтЁЃ ТэЪЯОрРыЭЈЙ§ВтСПМьВтОрРыЦНОљЙьЕРЮЛжУгаЖрЩйБъзМЦЋВюРДПМТЧзДЬЌЙРМЦЕФВЛШЗЖЈадЁЃ СэЭтЃЌЪЙгУИУЖШСПЃЌПЩвдЭЈЙ§ИљОнДгФц
БэЪОЕк j ИіbboxМьВтЁЃ ТэЪЯОрРыЭЈЙ§ВтСПМьВтОрРыЦНОљЙьЕРЮЛжУгаЖрЩйБъзМЦЋВюРДПМТЧзДЬЌЙРМЦЕФВЛШЗЖЈадЁЃ СэЭтЃЌЪЙгУИУЖШСПЃЌПЩвдЭЈЙ§ИљОнДгФц![]() ЗжВММЦЫуГіЕФ95ЃЅжУаХЧјМфЖдТэЪЯОрРыНјаауажЕЛЏРДХХГ§ВЛЬЋПЩФмЕФЙиСЊЁЃ ЮвУЧгУвЛИіжИБъРДБэЪОетИіОіЖЈ
ЗжВММЦЫуГіЕФ95ЃЅжУаХЧјМфЖдТэЪЯОрРыНјаауажЕЛЏРДХХГ§ВЛЬЋПЩФмЕФЙиСЊЁЃ ЮвУЧгУвЛИіжИБъРДБэЪОетИіОіЖЈ
![]()
ШчЙћЕк i ИіtrackКЭЕк j ИіМьВтжЎМфЕФЙиСЊЪЧдЪаэЕФЃЌдђНсЙћЮЊ1ЁЃ ЖдгкЮвУЧЕФЫФЮЌВтСППеМфЃЌЖдгІЕФMahalanobisуажЕЮЊ![]() ЁЃ
ЁЃ
ЕБдЫЖЏВЛШЗЖЈадНЯЕЭЪБЃЌТэЪЯОрРыЪЧКЯЪЪЕФЙиСЊЖШСПЃЌЕЋдкЮвУЧЕФЭМЯёПеМфЮЪЬтЙЋЪНжаЃЌДгПЈЖћТќТЫВЈПђМмЛёЕУЕФдЄВтзДЬЌЗжВМНіЬсЙЉСЫФПБъЮЛжУЕФДжТдЙРМЦЁЃ гШЦфЪЧЃЌЮоЗЈНтЪЭЕФЩуЯёЛњдЫЖЏЛсдкЭМЯёЦНУцжав§ШыПьЫйЮЛвЦЃЌДгЖјЪЙТэЪЯОрРыГЩЮЊгУгкИњзйекЕВЕФЯрЕБВЛУїжЧЕФжИБъЁЃ вђДЫЃЌЮвУЧНЋЕкЖўИіжИБъМЏГЩЕНЗжХфЮЪЬтжаЁЃ ЖдгкУПИіБпНчПђМьВт ![]() ЃЌЮвУЧМЦЫу
ЃЌЮвУЧМЦЫу![]() ЕФЭтЙлУшЪіЗћ
ЕФЭтЙлУшЪіЗћ![]() ЁЃДЫЭтЃЌЖдгкУПИіЙьЕР kЃЌЮвУЧБЃСєзюКѓ
ЁЃДЫЭтЃЌЖдгкУПИіЙьЕР kЃЌЮвУЧБЃСєзюКѓ ![]() ЕФЙиСЊЭтЙлУшЪіЗћЕФgallery
ЕФЙиСЊЭтЙлУшЪіЗћЕФgallery ![]()
![]() ЁЃ ШЛКѓЃЌЮвУЧЕФЕкЖўИіЖШСПЃЈmetricЃЉНЋВтСПЭтЙлПеМфжаЕк i ИіtrackКЭЕк j ИіМьВтжЎМфЕФзюаЁгрЯвОрРыЃК
ЁЃ ШЛКѓЃЌЮвУЧЕФЕкЖўИіЖШСПЃЈmetricЃЉНЋВтСПЭтЙлПеМфжаЕк i ИіtrackКЭЕк j ИіМьВтжЎМфЕФзюаЁгрЯвОрРыЃК
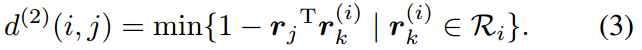
ЭЌбљЃЌИљОнетИіmetricЃЌЮвУЧв§ШывЛИіЖўНјжЦБфСПРДХаЖЯЪЧЗёдЪаэвЛИіЙиСЊЁЃ
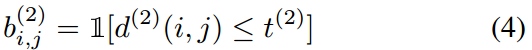
ЮвУЧдкЕЅЖРЕФбЕСЗЪ§ОнМЏЩЯЮЊДЫжИБъевЕНСЫКЯЪЪЕФуажЕЁЃ дкЪЕМљжаЃЌЮвУЧгІгУдЄбЕСЗЕФCNNРДМЦЫуБпНчПђЭтЙлУшЪіЗћЁЃ ИУЭјТчЕФЬхЯЕНсЙЙдк2.4НкжаУшЪіЁЃ
ЭЈЙ§НсКЯЪЙгУЗжХфЮЪЬтЕФВЛЭЌЗНУцЃЌСНИіжИБъПЩвдЯрЛЅВЙГфЁЃ вЛЗНУцЃЌТэЪЯОрРыЛљгкдЫЖЏЬсЙЉгаЙиПЩФмЕФФПБъЮЛжУЕФаХЯЂЃЌетЖдгкЖЬЦкдЄВтЬиБ№гагУЁЃ СэвЛЗНУцЃЌЕБдЫЖЏЕФХаБ№СІНЯШѕЪБЃЌгрЯвОрРыЛсПМТЧЭтЙлаХЯЂЃЌетаЉаХЯЂЖдгкГЄЪБМфекЕВКѓЛжИДЩэЗнЃЈidentityЃЉЬиБ№гагУЁЃ ЮЊСЫНЈСЂЙиСЊЮЪЬтЃЌЮвУЧЪЙгУМгШЈзмКЭНЋСНИіжИБъНсКЯЦ№РДЁЃ
![]()
ШчЙћЫќдкСНИіжИБъЕФУХПиЧјМфжЎФкЃЌЮвУЧГЦЦфЮЊПЩНгЪмЕФЙиСЊЃК
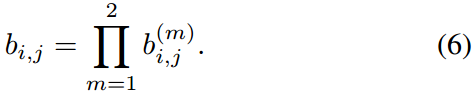
ПЩвдЭЈЙ§ГЌВЮЪ§ ІЫ РДПижЦУПИіЖШСПЖдКЯВЂЙиСЊГЩБОЕФгАЯьЁЃ дкЮвУЧЕФЪЕбщЙ§ГЬжаЃЌЮвУЧЗЂЯжЃЌЕБЩуЯёЛњДѓСПдЫЖЏЪБЃЌЩшжУІЫ= 0ЪЧвЛИіКЯРэЕФбЁдёЁЃ дкДЫЩшжУжаЃЌЙиСЊДњМлЯюжаНіЪЙгУЭтЙлаХЯЂЁЃ ШЛЖјЃЌЛљгкПЈЖћТќТЫВЈЦїЭЦЖЯГіЕФПЩФмЕФФПБъЮЛжУЃЌТэЪЯУХШдШЛБЛгУРДКіТдВЛПЩааЕФЗжХфЁЃ
2.3 ЦЅХфМЖСЊ
ЖјВЛЪЧНтОіШЋОжЗжХфЮЪЬтжаЕФВтСПгыИњзйЙиСЊЃЌЮвУЧв§ШыСЫвЛИіМЖСЊРДНтОівЛЯЕСазгЮЪЬтЁЃЮЊСЫМЄЗЂетжжЗНЗЈЃЌЧыПМТЧвдЯТЧщПіЃКЕБЮяЬхБЛГЄЪБМфекЕВЪБЃЌКѓајЕФПЈЖћТќТЫВЈЦїдЄВтЛсдіМггыЮяЬхЮЛжУЯрЙиЕФВЛШЗЖЈадЁЃвђДЫЃЌИХТЪжЪСПдкзДЬЌПеМфжаРЉЩЂЃЌЙлВьЫЦШЛадБфЕУВЛФЧУДМтШёЁЃжБЙлЕиЃЌЙиСЊЖШСПгІЭЈЙ§діМгВтСПЕНЙьЕРЕФОрРыРДПМТЧИХТЪжЪСПЕФетжжРЉеЙЁЃгыжБОѕЯрЗДЃЌЕБСНИіtrackОКељЭЌвЛМьВтЪБЃЌТэЪЯОрРыгаРћгкИќДѓЕФВЛШЗЖЈадЃЌвђЮЊЫќгааЇЕиМѕаЁСЫШЮКЮМьВтЕФБъзМЦЋВюгыЭЖгАtrackОљжЕжЎМфЕФОрРыЁЃетЪЧВЛЯЃЭћЕФааЮЊЃЌвђЮЊЫќПЩФмЕМжТ track ЫщЦЌдіМгКЭ track ВЛЮШЖЈЁЃвђДЫЃЌЮвУЧв§ШыСЫвЛИіЦЅХфМЖСЊЃЌИУМЖСЊНЋгХЯШГіЯждкНЯГЃМћЕФФПБъЩЯЃЌвдЖдЙиСЊПЩФмаджаЕФИХТЪЩЂВМИХФюНјааБрТыЁЃ
Listing 1ИХЪіСЫЮвУЧЕФЦЅХфЫуЗЈЁЃ зїЮЊЪфШыЃЌЮвУЧЬсЙЉtrack T КЭМьВт D Ыїв§вдМАзюДѓage ![]() ЕФМЏКЯЁЃ дкЕк 1 ааКЭЕк 2 аажаЃЌЮвУЧМЦЫуЙиСЊГЩБООиеѓКЭПЩдЪаэЙиСЊЕФОиеѓЁЃ ШЛКѓЃЌЮвУЧЖдЙьЕР age nНјааЕќДњЃЌвдНтОіЫцзХ age діГЄЕФ track ЕФЯпадЗжХфЮЪЬтЁЃ дкЕк6аажаЃЌЮвУЧбЁдёдкзюНќ n жЁжаЮДгыМьВтЙиСЊЕФ track
ЕФМЏКЯЁЃ дкЕк 1 ааКЭЕк 2 аажаЃЌЮвУЧМЦЫуЙиСЊГЩБООиеѓКЭПЩдЪаэЙиСЊЕФОиеѓЁЃ ШЛКѓЃЌЮвУЧЖдЙьЕР age nНјааЕќДњЃЌвдНтОіЫцзХ age діГЄЕФ track ЕФЯпадЗжХфЮЪЬтЁЃ дкЕк6аажаЃЌЮвУЧбЁдёдкзюНќ n жЁжаЮДгыМьВтЙиСЊЕФ track ![]() ЕФзгМЏЁЃ дкЕк7аажаЃЌЮвУЧНтОіСЫ
ЕФзгМЏЁЃ дкЕк7аажаЃЌЮвУЧНтОіСЫ ![]() жаЕФtrack гыВЛЦЅХфЕФМьВт
жаЕФtrack гыВЛЦЅХфЕФМьВт ![]() жЎМфЕФЯпадЗжХфЁЃ
жЎМфЕФЯпадЗжХфЁЃ
дкЕк8ааКЭЕк9аажаЃЌЮвУЧИќаТСЫЦЅХфЯюКЭЮДЦЅХфЕФМьВтЯюМЏЃЌЮвУЧНЋдкЕк11аажаЭъГЩКѓЗЕЛиЁЃЧызЂвтЃЌДЫЦЅХфМЖСЊНЋгХЯШПМТЧageНЯаЁЕФЙьЕРЃЌМДзюНќЗЂЯжЕФЙьЕРЁЃ

дкзюКѓЕФЦЅХфНзЖЮЃЌЮвУЧАДеедЪМSORTЫуЗЈ[12]жаЬсГіЕФЗНЗЈЃЌЖдage n = 1ЕФЮДШЗШЯКЭЮДЦЅХфЕФЙьМЃМЏдЫааiouЙиСЊЁЃетгажњгкНтОіЭЛШЛГіЯжЕФЭтЙлБфЛЏЃЌР§ШчЃЌгЩгкОпгаОВЬЌГЁОАМИКЮЬхЕФВПЗжекЕВЃЌВЂЬсИпСЫеыЖдДэЮѓГѕЪМЛЏЕФТГАєадЁЃ
2.4 ЩюЖШЭтЙлУшЪіЦї
ЭЈЙ§ЪЙгУМђЕЅЕФзюНќСкВщбЏЖјВЛНјааЖюЭтЕФЖШСПбЇЯАЃЌЮвУЧЗНЗЈЕФГЩЙІгІгУвЊЧѓдкЪЕМЪЕФдкЯпИњзйгІгУжЎЧАЃЌНЋОпгаСМКУЧјЗжадЕФfeature embedding НјааРыЯпбЕСЗЁЃ ЮЊДЫЃЌЮвУЧВЩгУСЫОЙ§ДѓЙцФЃааШЫжиЪЖБ№Ъ§ОнМЏ[21]бЕСЗЕФCNNЃЌИУЪ§ОнМЏАќКЌ1,261ЮЛааШЫЕФ1,100,000ЖреХЭМЯёЃЌЪЙЦфЗЧГЃЪЪКЯдкааШЫИњзйЛЗОГжаНјааЩюЖШЖШСПбЇЯАЁЃ
Бэ1 ИјГіСЫЮвУЧЭјТчЕФCNNЬхЯЕНсЙЙЁЃзмжЎЃЌЮвУЧЪЙгУСЫвЛИіПэВаВюЭјТч[22]ЃЌИУЭјТчОпгаСНИіОэЛ§ВуКЭСљИіВаВюПщЁЃ дкШЋСЌНгВу10жаМЦЫуЮЌЖШЮЊ128ЕФШЋОжЬиеїЭМЁЃзюКѓвЛИіbatchКЭL2ЙщвЛЛЏЯюНЋЬиеїЭЖгАЕНЕЅЮЛГЌЧђУцЩЯЃЌвдгыЮвУЧЕФгрЯвЭтЙлЖШСПМцШнЁЃ ИУЭјТчзмЙВОпга2,800,864ИіВЮЪ§ЃЌдкNvidia GeForce GTX 1050вЦЖЏGPUЩЯЃЌforward 32ИіБпНчПђЕФДЋЕнДѓдМашвЊ30КСУыЁЃ вђДЫЃЌжЛвЊгаПЩгУЕФЯжДњGPUЃЌДЫЭјТчЗЧГЃЪЪКЯдкЯпИњзйЁЃ ОЁЙмЮвУЧЕФбЕСЗЙ§ГЬЕФЯъЯИаХЯЂВЛдкБОЮФЬжТлЗЖЮЇжЎФкЃЌЕЋЮвУЧдкGitHubВжПт 1 жаЬсЙЉСЫвЛИідЄбЕСЗЕФФЃаЭвдМАвЛИіПЩгУгкЩњГЩfeaturesЕФНХБОЁЃ

Бэ1ЃКCNNМмЙЙИХЪіЁЃ зюКѓвЛИіbatchКЭ L2БъзМЛЏНЋЬиеїЭЖгАЕНЕЅЮЛГЌЧђУцЩЯЁЃ
3ЃЌЪЕбщ
ЮвУЧИљОнMOT16ЛљзМ[15]ЦРЙРИњзйЦїЕФадФмЁЃ ИУЛљзМЦРЙРСЫЦпИіЬєеНадВтЪдађСаЕФИњзйадФмЃЌАќРЈОпгавЦЖЏЩуЯёЛњЕФЧАЪгГЁОАвдМАздЩЯЖјЯТЕФМрЪгЩшжУЁЃ зїЮЊЖдИњзйЦїЕФЪфШыЃЌЮвУЧвРППYuЕШШЫЬсЙЉЕФМьВтНсЙћ[16]ЁЃ ЫћУЧвбОдквЛзщЙЋЙВКЭЫНгаЪ§ОнМЏЩЯбЕСЗСЫFaster RCNNЃЌвдЬсЙЉГіЩЋЕФадФмЁЃ ЮЊСЫЙЋЦНЦ№МћЃЌЮвУЧЖдЯрЭЌЕФМьВтжиаТдЫааСЫSORTЁЃ
ЪЙгУ ІЫ= 0 КЭ age Amax = 30 жЁЖдВтЪдађСаНјааЦРЙРЁЃ Шч[16]жаЫљЪіЃЌМьВтуажЕЕФжУаХЖШЮЊ0.3ЁЃ ЮвУЧЕФЗНЗЈЕФЦфгрВЮЪ§вбдкЛљзМЬсЙЉЕФЕЅЖРбЕСЗађСажаевЕНЁЃ ЦРЙРЪЧИљОнвдЯТжИБъНјааЕФЃК
?ЖрФПБъИњзйзМШЗТЪЃЈMOTAЃЉЃКвдFPЃЌFNКЭ id switchsЮЊвРОнЕФзмЬхИњзйОЋЖШеЊвЊ[23]ЁЃ
?ЖрФПБъИњзйОЋЖШЃЈMOTPЃЉЃКИљОнground truthгыБЈИцlocationжЎМфЕФБпНчПђжиЕўЧщПіЃЌзмЬхИњзйОЋЖШеЊвЊ[23]ЁЃ
?зюЖрЕФИњзйЃЈMTЃЉЃКдкжСЩй80ЃЅЕФЪЙгУЪйУќжаОпгаЯрЭЌБъЧЉЕФground truth tracksЕФАйЗжБШЁЃ
?зюЖрЕФЖЊЪЇЃЈMLЃЉЃКБЛИњзйЕНзюГЄЪйУќ20ЃЅЕФground truth ЙьЕРЕФАйЗжБШЁЃ
?IDЬјБфЃЈIDЃЉЃКБЈИцЕФground truth ЙьЕРЩэЗнЬјБфЕФДЮЪ§ЁЃ
?ЫщЦЌЃЈFMЃЉЃКгЩгкШБЩйМьВтЪЙЕУtrackжаЖЯЕФДЮЪ§ЁЃ
ЮвУЧЕФЦРЙРНсЙћЯдЪОдкБэ2жаЁЃЮвУЧЕФЕїећГЩЙІЕиМѕЩйСЫid switchsЕФЪ§СПЁЃ гыSORTЯрБШЃЌID switchДг1423МѕЩйЕН781ЁЃетМѕЩйСЫДѓдМ45ЃЅЁЃ ЭЌЪБЃЌгЩгкЭЈЙ§екЕВКЭЖЊЪЇРДБЃГжФПБъЕФ idЃЌвђДЫtracksЫщЦЌЛсЩдЮЂдіМгЁЃ ЮвУЧЛЙПДЕНЃЌДѓЖрЪ§ИњзйФПБъЕФЪ§СПЯдзХдіМгЃЌЖјДѓЖрЪ§ЖЊЪЇФПБъЕФЪ§СПдђМѕЩйСЫЁЃ змЬхЖјбдЃЌгЩгкЭтЙлаХЯЂЕФећКЯЃЌЮвУЧЭЈЙ§ИќГЄЕФекЕВГЩЙІЕиБЃГжСЫIDЁЃ ЭЈЙ§ЖдВЙГфВФСЯжаЬсЙЉЕФИњзйЪфГіНјааЖЈадЗжЮіЃЌвВПЩвдПДГіетвЛЕуЁЃ ЮвУЧЕФИњзйЦїЕФЪОР§ЪфГіШчЭМ1ЫљЪОЁЃ

Бэ2ЃКЙигкMOT16 [15]ЬєеНЕФИњзйНсЙћЁЃ ЮвУЧНЋЦфгыЦфЫћЗЧБъзММьВтЗНЗЈНјааСЫБШНЯЁЃ ЭъећЕФНсЙћБэПЩдкЬєеНЭјеОЩЯевЕНЁЃ Бъга * ЕФЗНЗЈ ЪЙгУ[16]ЬсЙЉЕФМьВтЁЃ
ЮвУЧЕФЗНЗЈвВЪЧЦфЫћдкЯпИњзйПђМмЕФгаСІОКељепЁЃЬиБ№ЪЧЃЌЮвУЧЕФЗНЗЈЗЕЛиСЫЫљгадкЯпЗНЗЈжазюЩйЕФid switchДЮЪ§ЃЌЭЌЪББЃГжСЫОКељадЕФ MOTAЗжЪ§ЃЌИњзйЫщЦЌКЭМйвѕадЁЃДѓСПЕФFPЛсДѓДѓЯїШѕЫљБЈИцЕФИњзйзМШЗадЁЃПМТЧЕНЫќУЧЖдMOTAЗжЪ§ЕФзмЬхгАЯьЃЌЖдМьВтНсЙћгІгУНЯДѓЕФжУаХЖШуажЕПЩФмЛсДѓДѓЬсИпЮвУЧЫуЗЈЕФБЈИцадФмЁЃЕЋЪЧЃЌЖдИњзйЪфГіЕФЪгОѕМьВщБэУїЃЌетаЉЮѓБЈжївЊЪЧгЩОВЬЌГЁОАМИКЮНсЙЙЩЯЕФСуаЧМьВтЦїЯьгІВњЩњЕФЁЃгЩгкЮвУЧЕФзюДѓдЪаэИњзй age БШНЯДѓЃЌетаЉЭЈГЃЛсгыФПБъЙьМЃНсКЯдквЛЦ№ЁЃЭЌЪБЃЌЮвУЧУЛгаЙлВьЕНдкДэЮѓОЏБЈжЎМфЦЕЗБЬјдОЕФЙьМЃЁЃЯрЗДЃЌИњзйЦїЭЈГЃдкБЈИцЕФФПБъЮЛжУЩњГЩЯрЖдЮШЖЈЕФЙЬЖЈtracksЁЃ
ЮвУЧЕФЪЕЯжвдДѓдМ20 HzЕФЦЕТЪдЫааЃЌЦфжаДѓдМвЛАыЕФЪБМфЛЈдкСЫЬиеїЩњГЩЩЯЁЃ вђДЫЃЌдкЪЙгУЯжДњGPUЕФЧщПіЯТЃЌЯЕЭГБЃГжСЫМЦЫуаЇТЪЃЌВЂПЩвдЪЕЪБдЫааЁЃ
4ЃЌзмНс
ЮвУЧвбОНщЩмСЫSORTЕФРЉеЙЃЌИУРЉеЙЭЈЙ§дЄбЕСЗЕФЙиСЊЖШСПНсКЯСЫЭтЙлаХЯЂЁЃ гЩгкДЫРЉеЙЃЌЮвУЧФмЙЛИњзйИќГЄЕФекЕВЪБМфЃЌЪЙSORTГЩЮЊзюЯШНјЕФдкЯпИњзйЫуЗЈЕФЧПДѓОКељепЁЃ ЕЋЪЧЃЌИУЫуЗЈШдШЛвзгкЪЕЯжВЂЧвПЩвдЪЕЪБдЫааЁЃ