OpenPose
¬έΈΡ‘≠ΈΡΘΚhttps://arxiv.org/pdf/1611.08050.pdf
Abstract
Έ“Ο«Χα≥ωΝΥ“Μ÷÷”––ßΦλ≤βΕύ»ΥΆΦœώ÷–ΒΡ2DΉΥ ΤΒΡΖΫΖ®ΓΘ ΗΟΖΫΖ® Ι”ΟΖ«≤Έ ΐ±μ ΨΘ§Έ“Ο«≥Τ÷°ΈΣ≤ΩΖ÷«ΉΚΆΝΠΉ÷ΕΈΘ®PAFΘ©Θ§”Ο”Ύ―ßœΑΫΪΆΦœώ÷–ΒΡ…μΧε≤ΩΈΜ”κΗωΧεΝΣœΒΤπά¥ΓΘ ΗΟΧεœΒΫαΙΙ±ύ¬κ»ΪΨ÷…œœ¬ΈΡΘ§‘ –μΧΑάΖΒΡΉ‘œ¬Εχ…œΫβΈω≤Ϋ÷ηΘ§Έό¬έΆΦœώ÷–ΒΡ»Υ ΐΕύ…ΌΘ§Ά§ ± Βœ÷ΗΏΨΪΕ»ΚΆ Β ±–‘ΡήΓΘ ΦήΙΙ÷Φ‘ΎΫΪ―ßœΑΙΊΫΎΒψΚΆΙΊΫΎΒψ÷°ΦδΒΡΝ§Ϋ”»ΎΚœΤπά¥Θ§Ά®ΙΐœύΆ§Υ≥–ρΒΡΝΫΗωΖ÷÷ßΫχ––ΙΊΝΣ‘Λ≤βΓΘ
1. Introduction
»ΥΧε2DΉΥ ΤΙάΦΤ - ±ΨΒΊΜ·ΒΡΈ ΧβΫβΤ ―ßΙΊΦϋΒψΜρΓΑ≤ΩΖ÷Γ± - ÷ς“ΣΦ·÷–”Ύ’“ΒΫΗωΧεΒΡ…μΧε≤ΩΈΜ8,4,3,21,33,13,25,31Θ§6,24.ΧΊ±π «‘ΎΆΦœώ÷–ΆΤΕœ≥ωΕύΗω»ΥΒΡΉΥ ΤΘ§≥ œ÷≥ω“ΜΧΉΕάΧΊΒΡΖγΗώΧτ’ΫΓΘ Ήœ»Θ§ΟΩΗωΆΦœώΩ…ΡήΑϋΚ§Ω…“‘‘Ύ»ΈΚΈΈΜ÷ΟΜρΙφΡΘΖΔ…ζΈ¥÷Σ ΐΝΩΒΡ»ΥΓΘΤδ¥ΈΘ§»Υ”κ»Υ÷°ΦδΒΡΜΞΕ·ΒΦ÷¬Η¥‘”ΒΡΩ’ΦδΗ…»≈Θ§”…”ΎΫ”¥ΞΘ§±’»ϊΚΆ÷ΪΧεΙΊΫΎΘ§ Ι≤ΩΦΰΙΊΝΣ±δΒΟάßΡ―ΓΘ ΒΎ»ΐΘ§‘Υ–– ±ΥφΉ≈»ΥΩΎ ΐΝΩΒΡ‘ωΦ”Θ§Η¥‘”–‘«ς”Ύ‘ω≥ΛΘ§ Ι Β ±–‘Ρή≥…ΈΣ“ΜœνΧτ’ΫΓΘ

Figure 1.ΕΞ≤ΩΘΚΕύ»ΥΉΥ ΤΙάΦΤΓΘ Ά§“ΜΗω»ΥΒΡ…μΧε≤ΩΈΜ÷°Φδ”ΟœΏœύΝ§ΓΘ Ήσœ¬ΘΚ≤ΩΖ÷«ΉΚΆΝΠΉ÷ΕΈΘ®PAFsΘ©Ε‘”Π”ΎΝ§Ϋ””“÷βΚΆ”“≤ύΒΡ÷ΪΧεΆσΓΘ ―’…Ϊ±ύ¬κΖΫœρΓΘ ”“œ¬ΘΚΖ≈¥σ‘Λ≤βΒΡPAFΒΡ ”ΆΦΓΘ ‘Ύ≥Γ÷–ΒΡΟΩΗωœώΥΊ¥ΠΘ§2D ΗΝΩ±ύ¬κΥΡ÷ΪΒΡΈΜ÷ΟΚΆΖΫœρΓΘ
≤…”Ο“Μ÷÷≥ΘΦϊΒΡΖΫΖ®23,9,27,12,19»ΥΦλ≤βΤς≤Δ÷¥––ΒΞ»ΥΉΥ ΤΙάΦΤΕ‘”ΎΟΩ¥ΈΦλ≤βΓΘ ’β–©Ή‘…œΕχœ¬ΒΡΖΫΖ®÷±Ϋ”άϊ”Οœ÷”–ΦΦ θΫχ––ΒΞ»ΥΉΥ ΤΙάΦΤ17,11,18,28,29,7,30,5,6,20Θ§ΒΪ¥”‘γΤΎΒΡΙΛΉςΘΚ»γΙϊ»Υ‘±Φλ≤βΤς ßΑή - “ρΈΣΥϋΒ±»ΥΟ«Ϋϋ‘Ύεκ≥Ώ ±Κή»ί“ΉΦλ≤β≤Μ≥ωά¥Θ§’β÷÷«ιΩωΈόΖ®Φλ≤βΓΘ Εχ«“Θ§’β–©Ή‘…œΕχœ¬ΖΫΖ®ΒΡ‘Υ–– ±Φδ”κ»Υ ΐ≥…’ΐ±»ΘΚΕ‘”ΎΟΩ¥ΈΦλ≤βΘ§»Υ ΐ‘ΫΕύΘ§ΒΞ»ΥΉΥ ΤΙάΦΤΤςΦΤΥψΝΩ≥…±Ψ‘Ϋ¥σΓΘœύ±»÷°œ¬Θ§Ή‘œ¬Εχ…œΒΡΖΫΖ®Κή”–Έϋ“ΐΝΠ,“ρΈΣΥϋΟ«ΈΣ‘γΤΎ≥–≈ΒΧαΙ©ΝΥΈ»ΫΓ–‘≤Δ«“”Β”–ΫΪ‘Υ–– ±Η¥‘”–‘”κΆΦœώ÷–ΒΡ»Υ ΐ÷°ΦδΙΊœΒΖ÷άκΓΘ»ΜΕχΘ§Ή‘œ¬Εχ…œΒΡΖΫΖ®»¥ΟΜ”–÷±Ϋ” Ι”Οά¥Ή‘ΤδΥϊ…μΧε≤ΩΈΜΚΆΤδΥϊ»ΥΒΡ»ΪΨ÷…œœ¬ΈΡœΏΥςΓΘ‘Ύ ΒΦυ÷–Θ§“‘«ΑΒΡΉ‘œ¬Εχ…œΒΡΖΫΖ®22,11≤ΜΜα±ΘΝτ–߬ ΒΡΧα…ΐΘ§“‘÷Ν”ΎΉν÷’ΒΡΫβΈω–η“ΣΑΚΙσΒΡ»ΪΨ÷ΆΤάμΓΘάΐ»γΘ§PishchulinΒ»»ΥΒΡΩΣ¥¥–‘ΙΛΉςΓΘ 22Χα≥ωΝΥΉ‘œ¬Εχ…œΒΡΫ®“ιΘΚΝΣΚœ±ξΦ«≤ΩΖ÷Φλ≤βΚρ―Γ’ΏΒΡΖΫΖ®ΫΪΥϋΟ«”κΗω»ΥΝΣœΒΤπά¥ΓΘΒΪ «Θ§‘Ύ“ΜΗωΆξ»ΪΝ§Ϋ”ΒΡΆΦ…œΫβΨω’ϊ ΐœΏ–‘ΙφΜ°Έ Χβ“ΜΗωNPΈ ΧβΚΆΤΫΨυ¥Πάμ ±Φδ¥σ‘Φ «ΦΗΗω–Γ ±ΓΘ InsafutdinovΒ»ΓΘ 11Ϋ®≥…22Μυ”ΎResNetΒΡΗϋ«Ω≤ΩΖ÷ΧΫ≤βΤς10ΚΆΆΦœώœύΙΊΒΡ≥…Ε‘Ζ÷ ΐΘ§≤Δ¥σ¥σΗΡ…Τ‘Υ–– ±Θ§ΒΪΗΟΖΫΖ®‘Ύœό÷Τ≤ΩΖ÷ΧαΑΗΒΡ ΐΝΩΒΡ«ιΩωœ¬¥Πάμ“Μ’≈ΆΦΤ§»‘»Μ–η“ΣΦΗΖ÷÷”ΓΘ11÷– Ι”ΟΒΡ≥…Ε‘±μ ΨΚήΡ―ΜΊΙι,“ρ¥ΥΘ§–η“Σ“ΜΗωΒΞΕάΒΡ¬ΏΦ≠ΜΊΙιΓΘ

Figure 2.’ϊΧεΙΐ≥ΧΓΘ Έ“Ο«ΫΪ’ϊΗωΆΦœώΉςΈΣΥΪΖ÷÷ßCNNΒΡ δ»κά¥ΝΣΚœ‘Λ≤β÷Ο–≈ΆΦ,Θ®bΘ©÷–Υυ ΨΒΡ…μΧε≤ΩΈΜΦλ≤βΘ§“‘ΦΑΘ®cΘ©÷–Υυ ΨΒΡ≤ΩΈΜΙΊΝΣΒΡ≤ΩΖ÷«ΉΚΆΝΠΉ÷ΕΈΓΘ ΫβΈω≤Ϋ÷η÷¥––“ΜΉιΕΰΖ÷ΤΞ≈δ…μΧε≤ΩΈΜΚρ―Γ»ΥΒΡΤΞ≈δΘ®dΘ©ΓΘ Έ“Ο«Ήν÷’ΫΪΥϋΟ«ΉιΉΑ≥…ΆΦœώ÷–Υυ”–»ΥΒΡ»Ϊ…μΉΥ ΤΘ®eΘ©ΓΘ
‘Ύ±ΨΈΡ÷–Θ§Έ“Ο« Ή¥ΈΧα≥ω“Μ÷÷Ή‘œ¬Εχ…œΟη ωΙΊΝΣΖ÷ ΐΒΡΖΫΖ®ΘΚPart Affinity FieldsΘ®PAFΘ©Θ§PAF «“ΜΉιΕ‘ΈΜ÷ΟΚΆΆΦœώ…œ÷ΪΧεΒΡΖΫœρΫχ––±ύ¬κΒΡ2D ΗΝΩ≥ΓΓΘ Έ“Ο«÷ΛΟςΆ§ ±ΆΤΕœ’β–©Ή‘œ¬Εχ…œΒΡΦλ≤βΚΆΙΊΝΣ±μ ΨΉψ“‘ΚήΚΟΒΊ±ύ¬κ»ΪΨ÷…œœ¬ΈΡΘ§“‘“Μ–Γ≤ΩΖ÷ΦΤΥψ≥…±ΨΜώΒΟΗΏ÷ ΝΩΒΡΫαΙϊΓΘΈ“Ο«ΙΪΩΣΖΔ≤ΦΝΥΆξ»ΪΩ…÷ΊΗ¥–‘ΒΡ¥ζ¬κΘ§≥ œ÷ ΒΎ“ΜΗω”Ο”ΎΕύ»Υ2DΉΥ ΤΦλ≤βΒΡ Β ±œΒΆ≥ΓΘ
2.Method
Figure 2ΥΒΟςΝΥΈ“Ο«ΖΫΖ®ΒΡ’ϊΗωΝςΥ°œΏΓΘ ΗΟœΒΆ≥≤…”Ο≥Ώ¥γΈΣwΓΝhΒΡ≤ …ΪΆΦœώΉςΈΣ δ»κΘ®Fig.2aΘ©Θ§≤Δ«“ΈΣΆΦœώ÷–ΒΡΟΩΗω»Υ≤ζ…ζΫβΤ ΙΊΦϋΒψΒΡ2DΈΜ÷ΟΉςΈΣ δ≥ωΘ®Fig.2eΘ©ΓΘ Ήœ»Θ§«ΑœρΆχ¬γΆ§ ±‘Λ≤β“ΜΉι…μΧε≤ΩΈΜΈΜ÷ΟΒΡ2D÷Ο–≈Ε»ΆΦSΘ®Fig.2bΘ©ΚΆ±ύ¬κ“ΜΉι…μΧε≤ΩΖ÷÷°ΦδΙΊΝΣ≥ΧΕ»(«ΉΚΆΕ»)ΒΡ2D ΗΝΩ≥ΓLΘ®ΆΦ2cΘ©ΓΘ Φ·ΚœS =![]() ΨΏ”–JΗω÷Ο–≈ΆΦΘ§ΟΩΗω≤ΩΖ÷“ΜΗωΘ§Τδ÷–
ΨΏ”–JΗω÷Ο–≈ΆΦΘ§ΟΩΗω≤ΩΖ÷“ΜΗωΘ§Τδ÷–![]() ΓΘ Φ·Κœ
ΓΘ Φ·Κœ![]() ΨΏ”–CΗω ΗΝΩ≥ΓΘ§ΟΩΗω÷ΪΧε1ΗωΘ§Τδ÷–
ΨΏ”–CΗω ΗΝΩ≥ΓΘ§ΟΩΗω÷ΪΧε1ΗωΘ§Τδ÷–![]() Θ§
Θ§![]() ÷–ΒΡΟΩΗωΆΦœώΈΜ÷Ο±ύ¬κ2D ΗΝΩΘ®»γFig.1Υυ ΨΘ©ΓΘ ΉνΚσΘ§Ά®ΙΐΧΑ–ΡΆΤάμΘ®Fig.2dΘ©ΫβΈω÷Ο–≈Ε»ΆΦΚΆ«ΉΚΆΕ»Ή÷ΕΈΘ§“‘ δ≥ωΆΦœώ÷–Υυ”–»ΥΒΡ2DΙΊΦϋΒψΓΘ
÷–ΒΡΟΩΗωΆΦœώΈΜ÷Ο±ύ¬κ2D ΗΝΩΘ®»γFig.1Υυ ΨΘ©ΓΘ ΉνΚσΘ§Ά®ΙΐΧΑ–ΡΆΤάμΘ®Fig.2dΘ©ΫβΈω÷Ο–≈Ε»ΆΦΚΆ«ΉΚΆΕ»Ή÷ΕΈΘ§“‘ δ≥ωΆΦœώ÷–Υυ”–»ΥΒΡ2DΙΊΦϋΒψΓΘ
2.1. Simultaneous Detection and Association
Έ“Ο«ΒΡΦήΙΙ Fig.3Υυ ΨΘ§Ά§ ±‘Λ≤βΦλ≤β±ύ¬κΒΡ÷Ο–≈Ε»ΆΦΚΆ«ΉΚΆΝΠΉ÷ΕΈΘ®…μΧε≤ΩΈΜ÷°ΦδΒΡΙΊΝΣΘ©ΓΘ Άχ¬γΖ÷ΈΣΝΫ≤ΩΖ÷Ζ÷÷ßΘΚ“‘ΟΉ…Ϊœ‘ ΨΒΡΕΞ≤ΩΖ÷÷ß‘Λ≤β÷Ο–≈Ε»ΆΦΚΆ“‘άΕ…Ϊœ‘ ΨΒΡΒΉ≤ΩΖ÷÷ß‘Λ≤β«ΉΚΆΝλ”ρΓΘΟΩΗωΖ÷÷ßΕΦ «“ΜΗωΒϋ¥ζ‘Λ≤βΦήΙΙΓΘ‘ΎWeiΒ»»ΥΒΡΜυ¥Γ…œΗΡΫχΝΥΝ§–χΫΉΕΈΒΡ‘Λ≤βΘ§WeiΒ»»Υ≤…»ΓΒΡ «![]() Θ§ΟΩΗωΫΉΕΈ“Σ”Ο÷–ΦδΦύΕΫΓΘ
Θ§ΟΩΗωΫΉΕΈ“Σ”Ο÷–ΦδΦύΕΫΓΘ
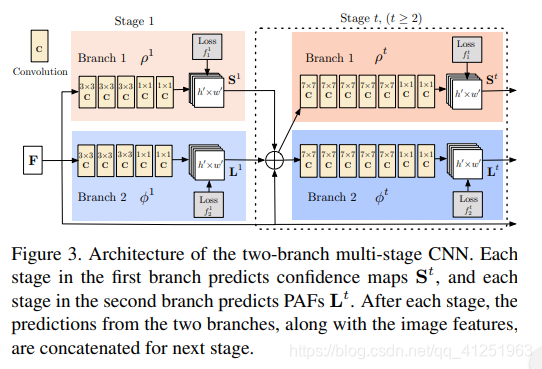
Figure 3.ΥΪΖ÷÷ßΕύΦΕCNNΒΡΧεœΒΫαΙΙΓΘ ΟΩΒΎ“ΜΗωΖ÷÷ß÷–ΒΡΫΉΕΈ‘Λ≤β÷Ο–≈Ε»ΆΦ ${S}^{t}$Θ§ΟΩ“ΜΗω
ΒΎΕΰΗωΖ÷÷ß÷–ΒΡΫΉΕΈ‘Λ≤βPAFs $L^t$ΓΘ ΟΩΗωΫΉΕΈ÷°ΚσΘ§ά¥Ή‘ΝΫΗωΖ÷÷ßΒΡ‘Λ≤βΘ§“‘ΦΑΆΦœώΧΊ’ςΘ§Ϋχ––Ν§Ϋ”Ϋχ»κœ¬“ΜΫΉΕΈΓΘ
Ήœ»Ά®ΙΐΨμΜΐΆχ¬γΖ÷ΈωΆΦœώΘ®”…«Α10≤ψVGG-19 26≥θ ΦΜ·≤ΔΨ≠ΙΐΈΔΒςΘ©Θ§…ζ≥…“ΜΉιΧΊ’ς”≥…δF ΉςΈΣΟΩΗωΖ÷÷ßΒΡΒΎ“ΜΫΉΕΈΒΡ δ»κΓΘ ‘ΎΒΎ“ΜΫΉΕΈΘ§Άχ¬γ≤ζ…ζ“ΜΉιΦλ≤β÷Ο–≈Ε»ΆΦ![]() ΚΆ“ΜΉι≤ΩΖ÷«ΉΚΆΝΠΉ÷ΕΈ
ΚΆ“ΜΉι≤ΩΖ÷«ΉΚΆΝΠΉ÷ΕΈ![]() ,
,
Τδ÷–![]() ΚΆ
ΚΆ![]() «ΒΎ1ΫΉΕΈΆΤΕœΒΡCNNΓΘ‘ΎΥφΚσΒΡΟΩ“ΜΗω÷–ΫΉΕΈΘ§ά¥Ή‘«ΑΝΫΗωΖ÷÷ßΫΉΕΈΒΡ‘Λ≤βΫαΙϊΘ§“‘ΦΑ‘≠ ΦΆΦœώΧΊ’ςFΘ§ «Ν§Ϋ”≤Δ”Ο”Ύ≤ζ…ζΗϋΨΪ»ΖΒΡ‘Λ≤βΓΘ
«ΒΎ1ΫΉΕΈΆΤΕœΒΡCNNΓΘ‘ΎΥφΚσΒΡΟΩ“ΜΗω÷–ΫΉΕΈΘ§ά¥Ή‘«ΑΝΫΗωΖ÷÷ßΫΉΕΈΒΡ‘Λ≤βΫαΙϊΘ§“‘ΦΑ‘≠ ΦΆΦœώΧΊ’ςFΘ§ «Ν§Ϋ”≤Δ”Ο”Ύ≤ζ…ζΗϋΨΪ»ΖΒΡ‘Λ≤βΓΘ

ΆΦ4œ‘ ΨΝΥΗςΫΉΕΈ÷Ο–≈ΆΦΚΆ«ΉΚΆΝΠΝλ”ρΒΡ”≈Μ·ΓΘ
ΈΣΝΥ“ΐΒΦ…ώΨ≠Άχ¬γ“‘Βϋ¥ζΖΫ Ϋ‘ΎΖ÷÷ß“Μ‘Λ≤β…μΧε≤ΩΈΜΒΡ÷Ο–≈Ε»ΆΦΚΆ‘ΎΒΎΕΰΗωΖ÷÷ß‘Λ≤βPAFΘ§Έ“Ο«‘ΎΟΩΗωΫΉΕΈΫα χ ±”Π”ΟΝΥΝΫΗωΥπ ßΚ· ΐΘ§ΟΩΗωΖ÷÷ß“ΜΗωΓΘΈ“Ο«‘ΎΙάΦΤΒΡ‘Λ≤β÷ΒΚΆ’φ ΒΒΡΙΊΫΎΆΦΘ§ΙΊΫΎΝ§Ϋ”÷°Φδ Ι”ΟL2Υπ ßΓΘ ‘Ύ’βάοΘ§Έ“Ο«‘ΎΩ’Φδ…œΕ‘Υπ ßΚ· ΐΫχ––Φ”»®Θ§“‘ΫβΨω“Μ–© ΒΦ Έ ΧβΘ§Φ¥Ρ≥–© ΐΨίΦ·≤ΔΈ¥Άξ»Ϊ±ξΦ«Υυ”–»ΥΓΘ
1ΈΣΝΥ«εΈζΤπΦϊΘ§Έ“Ο«ΫΪ≤ΩΦΰΕ‘≥ΤΈΣ÷ΪΧεΘ§ΨΓΙή”––©Ε‘≤Μ «»ΥΒΡ÷ΪΧε
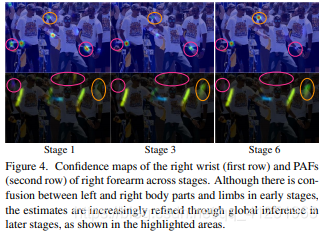
Figure 4.ΗςΗωΫΉΕΈΒΡ”“ ÷ΆσΘ®ΒΎ“Μ≈≈Θ©ΚΆPAFΒΡ÷Ο–≈Ε»ΆΦΘ®ΒΎΕΰ≈≈Θ©”“«Α±έΓΘ Υδ»Μ‘Ύ‘γΤΎΫΉΕΈΉσ”“…μΧε≤ΩΈΜΚΆΥΡ÷Ϊ÷°ΦδΨ≠≥ΘΜαΜ묓ȧΒΪ «Ά®ΙΐΚσΤΎΫΉΕΈΒΡ»ΪΟφΆΤάμΘ§‘Λ≤β‘Ϋά¥‘ΫΨΪ»ΖΘ§»γΆΦ÷–ΗΏΝΝ«χ”ρΥυ ΨΓΘ
ΧΊ±πΒΊΘ§ΒΎtΫΉΕΈΒΡΝΫΗωΥπ ßΚ· ΐ»γœ¬:

2.2. Confidence Maps for Part Detection
ΈΣΝΥ‘Ύ―ΒΝΖΙΐ≥Χ÷–ΤάΙάΙΪ ΫΘ®5Θ©÷–ΒΡ![]() Θ§Έ“Ο«¥”±ξΉΔΒΡ2DΙΊΦϋΒψ÷–…ζ≥…ΝΥ’φ ΒΒΡ÷Ο–≈ΆΦ
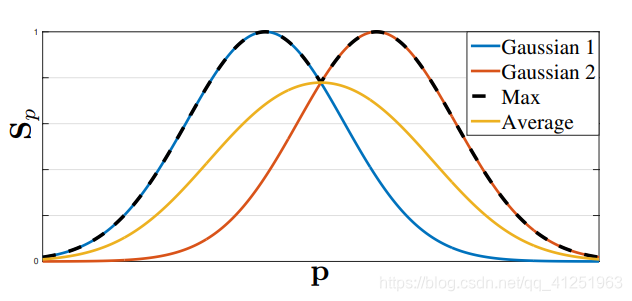
Θ§Έ“Ο«¥”±ξΉΔΒΡ2DΙΊΦϋΒψ÷–…ζ≥…ΝΥ’φ ΒΒΡ÷Ο–≈ΆΦ![]() ΓΘΟΩΗω÷Ο–≈ΆΦ «“ΜΗωΧΊΕ®…μΧε≤ΩΈΜ‘ΎΟΩΗωœώΥΊΒψΖΔ…ζΒΡΩ…Ρή–‘ΓΘάμœκ«ιΩωœ¬Θ§»γΙϊΆΦœώ÷–÷Μ”–“ΜΗω»ΥΘ§‘ΎΟΩΗω÷Ο–≈ΆΦ÷–”ΠΗΟ÷Μ”–“ΜΗωΖε÷ΒΘ§»γΙϊΕ‘”ΠΒΡ…μΧε≤ΩΈΜ‘ΎΆΦœώ…œ «Ω…ΦϊΒΡΜΑΘΜ»γΙϊΆΦœώ…œ”–ΕύΗω»ΥΘ§”ΠΗΟΜα”–“ΜΗωΕ‘”ΠΟΩΗω»ΥkΒΡΟΩ“ΜΗωΩ…ΦϊΒΡ…μΧε≤ΩΈΜjΒΡΖε÷ΒΓΘ
ΓΘΟΩΗω÷Ο–≈ΆΦ «“ΜΗωΧΊΕ®…μΧε≤ΩΈΜ‘ΎΟΩΗωœώΥΊΒψΖΔ…ζΒΡΩ…Ρή–‘ΓΘάμœκ«ιΩωœ¬Θ§»γΙϊΆΦœώ÷–÷Μ”–“ΜΗω»ΥΘ§‘ΎΟΩΗω÷Ο–≈ΆΦ÷–”ΠΗΟ÷Μ”–“ΜΗωΖε÷ΒΘ§»γΙϊΕ‘”ΠΒΡ…μΧε≤ΩΈΜ‘ΎΆΦœώ…œ «Ω…ΦϊΒΡΜΑΘΜ»γΙϊΆΦœώ…œ”–ΕύΗω»ΥΘ§”ΠΗΟΜα”–“ΜΗωΕ‘”ΠΟΩΗω»ΥkΒΡΟΩ“ΜΗωΩ…ΦϊΒΡ…μΧε≤ΩΈΜjΒΡΖε÷ΒΓΘ


Figure 5.…μΧε≤ΩΈΜΙΊΝΣ≤Ώ¬‘ΓΘ(a)ΝΫΗω≤ΜΆ§…μΧε≤ΩΈΜΦλ≤βΚρ―ΓΒψΘ®Κλ…ΪΚΆάΕ…ΪΒψΘ©ΚΆΥϋΟ«÷°ΦδΒΡ»Ϊ≤ΩΝ§Ϋ”Θ®Μ“…ΪΒΡœΏΘ©Θ®bΘ©Ν§Ϋ”ΫαΙϊ”Ο÷–ΦδΒψΘ®ΜΤ…ΪΒΡΒψΘ©±μ ΨΘΚ’ΐ»ΖΒΡΝ§Ϋ”Θ®ΚΎ…ΪΒΡœΏΘ©ΚΆ¬ζΉψΖΔ…ζ¬ ‘Φ χΒΡ≤Μ’ΐ»ΖΒΡΝ§Ϋ”Θ®¬Χ…ΪΒΡœΏΘ©Θ®cΘ©ΫαΙϊ Ι”ΟPAFsΘ®ΜΤ…ΪΒΡΦΐΆΖΘ©Θ§Ά®Ιΐ±ύ¬κ÷ΪΧεΒΡΈΜ÷ΟΚΆΖΫœρΘ§PAFsœϊ≥ΐΝΥ¥μΈσΒΡΝ§Ϋ”ΓΘ

Έ“Ο«»Γ÷Ο–≈ΆΦ÷–Ήν¥σΒΡ≤ΩΖ÷Εχ≤Μ «»ΓΤΫΨυΘ§ ΙΒΟΩΩΫϋΖε÷ΒΒΡ‘Λ≤βΜαΚήΟςœ‘Θ§ΨΆœώ…œΆΦΥυ ΨΓΘ‘Ύ≤β ‘ΒΡ ±ΚρΘ§Έ“Ο«‘Λ≤β÷Ο–≈ΆΦΘ®‘ΎFigure 4.÷–ΒΡΒΎ“Μ––Θ©Θ§Ά®ΙΐΖ«Ήν¥σ÷Β“÷÷ΤΒΟΒΫ…μΧε≤ΩΈΜΒΡΚρ―Γ.
2.3. Part Affinity Fields for Part Association
Ηχ≥ω“ΜΉιΦλ≤βΒΫΒΡ…μΧε≤ΩΈΜΘ®ΨΆœώFigure 5a÷–ΒΡΚλ…ΪΚΆάΕ…ΪΒψΘ©Θ§Έ“Ο«»γΚΈΑ―ΥϋΟ«ΉιΉΑ≥…»τΗ…Ηω»ΥΒΡΆξ’ϊ…μΧεΉΥΧ§ΡΊΘΩΈ“Ο«–η“ΣΕ‘ΟΩΗω…μΧε≤ΩΖ÷ΒΡΝ§Ϋ”Ϋχ––“ΜΗωΩ…Ρή–‘≤βΝΩΘ§“≤ΨΆ «±Θ÷ΛΥϋΟ« τ”ΎΆ§“ΜΗω»ΥΓΘ“Μ÷÷Ω…ΡήΒΡΦλ≤βΝ§Ϋ”ΒΡΖΫΖ® «Φλ≤βΟΩΕ‘…μΧε≤ΩΈΜ÷°ΦδΒΡ÷ΪΧεΒΡ÷–ΦδΒψΘ§≤ΔΦλ≤ιΥϋ‘ΎΚρ―Γ…μΧε≤ΩΈΜ÷°ΦδΖΔ…ζΒΡΩ…Ρή–‘Θ§»γFigure 5bΥυ ΨΓΘ»ΜΕχΒ±»ΥΟ«ΦΖ‘Ύ“ΜΤπΒΡ ±ΚρΘ§Κή»ί“ΉΖΔ…ζ’β÷÷«ιΩωΘ§’β–©÷–ΒψΩ…Ρή¥ζ±μ¥μΈσΒΡΝ§Ϋ”Θ®ΨΆœώFigure 5b÷–ΒΡ¬Χ…ΪœΏΘ©ΓΘ’β–©¥μΈσΝ§Ϋ”ΒΡ≤ζ…ζΒΡ‘≠“ρ «”…’β÷÷±μ ΨΖΫΖ®ΒΡΝΫ÷÷œό÷ΤΘΚΘ®1Θ©Υϋ÷Μ±ύ¬κΝΥΈΜ÷ΟΟΜ”–±ύ¬κΖΫœρΘ®2Θ©Υϋ»±…ΌΝΥΕ‘ΒΞΗωΒψ¥ζ±μ“ΜΗω÷ΪΧεΒΡ÷ß≥÷ΓΘ
ΈΣΝΥΫβΨω’β–©œό÷ΤΘ§Έ“Ο«Χα≥ωΝΥ“Μ÷÷–¬ΒΡ±μ ΨΖΫΖ®Θ§≤ΩΖ÷«ΉΚΆ–‘Ή÷ΕΈΘ§Ά§ ±±ΘΝτ±μ Ψ÷ΪΧεΒΡ«χ”ρ÷°ΦδΒΡΈΜ÷ΟΚΆΖΫœρ–≈œΔΘ§Θ®»γFigure 5cΥυ ΨΘ©≤ΩΖ÷«ΉΚΆΝΠ «…μΧεΟΩΗω÷ΪΧεΒΡ2DœρΝΩΘ§»γΆΦ Figure 1dΥυ ΨΘ§Ε‘”Ύ τ”ΎΧΊΕ®÷ΪΧε≤ΩΖ÷ΒΡΟΩ“ΜΗωœώΥΊΘ§“ΜΗω2DœρΝΩ±ύ¬κΝΥ¥”÷ΪΧεΒΡ“Μ≤ΩΖ÷÷ΗœρΝμ“Μ≤ΩΖ÷ΒΡΖΫœρΓΘΟΩ“Μ÷÷άύ–ΆΒΡ÷ΪΧεΕΦ”–ΤδΕ‘”ΠΒΡΨέΚœœύΝ§ΒΡΝΫ≤ΩΖ÷ΒΡ«ΉΚΆΝΠΓΘ
ΩΦ¬«“ΜΗωΦρΒΞΒΡ÷ΪΧεΘ§»γœ¬ΆΦΥυ ΨΓΘ

‘Ύ ΒΦυ÷–Θ§Έ“Ο«Ά®Ιΐ≥ι―υά¥ΙάΦΤΜΐΖ÷«σΚΆΒΡΨυ‘»ΦδΗτ÷Β

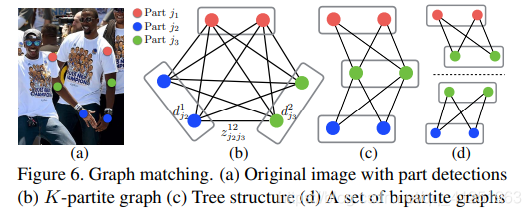
2.4. Multi-Person Parsing using PAFs
Έ“Ο«‘ΎΦλ≤βΒΡ÷Ο–≈ΆΦ…œ÷¥––Ήν¥σœό÷Τά¥Μώ»Γ“ΜΉιάκ…ΔΒΡΚρ―Γ…μΧε≤ΩΈΜΓΘΕ‘”ΎΟΩ“ΜΗω≤ΩΈΜΘ§Έ“Ο«Ω…Ρή”–ΕύΗωΚρ―ΓΘ§“ρΈΣΆΦœώ…œ”–ΕύΗω»ΥΘ§Μρ’ΏΈσ±®Θ®»γFigure .6bΥυ ΨΘ©ΓΘ’β–©Κρ―ΓΒΡ…μΧε≤ΩΈΜΕ®“εΝΥ“ΜΗωΚή¥σΒΡΩ…Ρή÷ΪΧεΦ·ΚœΓΘΈ“Ο«”ΟΙΪ Ϋ Θ®10Θ©÷–ΒΡœΏΜΐΖ÷ά¥ΦΤΥψΟΩΗωΚρ―Γ÷ΪΧεΒΡΒΟΖ÷ΓΘKΖ÷ΆΦΒΡΉν”≈ΫβΈω «±Μ λ÷ΣΒΡnpΈ ΧβΘ®»γFigure 6Υυ ΨΘ©ΓΘ‘Ύ’βΤΣ¬έΈΡ÷–Θ§Έ“Ο« Ι”ΟΝΥ“Μ÷÷ΧΑάΖΒΡΥ…≥ΎΖΫΖ®Θ§Ήή «ΡήΙΜ≤ζ…ζΗΏ÷ ΝΩΒΡΤΞ≈δΓΘΈ“Ο«ΆΤ≤β‘≠“ρ «≥…Ε‘ΒΡΙΊΝΣ“ΰΚ§Ή≈»ΪΨ÷…œœ¬ΈΡΘ§”…”Ύ¥σΒΡPAFΗ–÷ΣΆχ¬γΓΘ
’ΐ ΫΒΊΘ§Έ“Ο« Ήœ»ΒΟΒΫ“ΜΗωΕύ»ΥΒΡΚρ―Γ…μΧεΦλ≤β≤ΩΈΜΒΡΦ·Κœ![]() Θ§D_J = { d_j^m : for j in {1...J},m in {1...N_j}}$N_j¥ζ±μ…μΧε≤ΩΈΜjΒΡΚρ―ΓΗω ΐΘ§d_j^m in R^2 ΈΣ…μΧε≤ΩΈΜjΒΡΒΎmΗωΚρ―ΓΦλ≤βΓΘ’β–©Φλ≤βΒΡΚρ―Γ≤ΩΈΜ–η“Σ”κΆ§“ΜΗω»ΥΒΡΤδΥϊΚρ―Γ≤ΩΈΜΝ§Ϋ”Θ§ΜΜΨδΜΑΥΒΘ§Έ“Ο«–η“Σ’“ΒΫ≥…Ε‘ΒΡ…μΧεΦλ≤βΘ§±Θ÷ΛΥϋΟ« ΒΦ …œ «Ν§Ϋ”Ή≈ΒΡ÷ΪΧεΓΘΈ“Ο«Ε®“εΝΥ“ΜΗω±δΝΩ
Θ§D_J = { d_j^m : for j in {1...J},m in {1...N_j}}$N_j¥ζ±μ…μΧε≤ΩΈΜjΒΡΚρ―ΓΗω ΐΘ§d_j^m in R^2 ΈΣ…μΧε≤ΩΈΜjΒΡΒΎmΗωΚρ―ΓΦλ≤βΓΘ’β–©Φλ≤βΒΡΚρ―Γ≤ΩΈΜ–η“Σ”κΆ§“ΜΗω»ΥΒΡΤδΥϊΚρ―Γ≤ΩΈΜΝ§Ϋ”Θ§ΜΜΨδΜΑΥΒΘ§Έ“Ο«–η“Σ’“ΒΫ≥…Ε‘ΒΡ…μΧεΦλ≤βΘ§±Θ÷ΛΥϋΟ« ΒΦ …œ «Ν§Ϋ”Ή≈ΒΡ÷ΪΧεΓΘΈ“Ο«Ε®“εΝΥ“ΜΗω±δΝΩ ![]() ”Οά¥±μ ΨΚρ―ΓΦλ≤β…μΧε≤ΩΈΜ
”Οά¥±μ ΨΚρ―ΓΦλ≤β…μΧε≤ΩΈΜ![]() «Ζώ «’φ’ΐΒΡΝ§Ϋ”Θ§ΡΩ±ξ «ΈΣΝΥ’“ΒΫΕ‘”ΎΥυ”–Ω…ΡήΒΡΝ§Ϋ”ΒΡΉνΦ―ΤΞ≈δΘ§
«Ζώ «’φ’ΐΒΡΝ§Ϋ”Θ§ΡΩ±ξ «ΈΣΝΥ’“ΒΫΕ‘”ΎΥυ”–Ω…ΡήΒΡΝ§Ϋ”ΒΡΉνΦ―ΤΞ≈δΘ§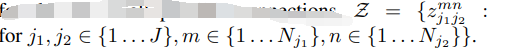
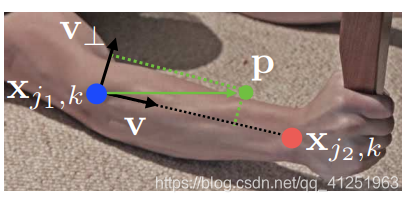
»γΙϊΈ“Ο«ΩΦ¬«ΒΞΕάΒΡΒΎcΗω÷ΪΧεΒΡ“ΜΕ‘…μΧε≤ΩΈΜΘ§j1ΚΆj2(άΐ»γΨ±≤ΩΚΆ”“ΆΈ)Θ§’“ΒΫΉνΦ―ΤΞ≈δΨΆΦρΜ·≥…ΝΥ“ΜΗωΕΰΖ÷ΆΦΒΡΉν¥σΤΞ≈δΈ Χβ32ΓΘ’β÷÷«ιΩω»γΆΦFigure 5b÷–Υυ ΨΓΘ‘Ύ’βΗωΆΦΤΞ≈δΒΡΈ Χβ÷–Θ§ΆΦ…œΒΡΫΎΒψΕΦ «Κρ―ΓΒΡ…μΧεΦλ≤β≤ΩΈΜ![]() ΚΆ
ΚΆ![]() ,±Ώ «Κρ―Γ…μΧε≤ΩΈΜ÷°ΦδΒΡ»Ϊ≤ΩΩ…ΡήΒΡΝ§Ϋ”ΓΘΝμΆβΘ§ΟΩ“ΜΧθ±Ώ”…ΙΪ ΫΘ®10Θ©Φ”»®Θ§Φ¥≤ΩΖ÷«ΉΚΆΝΠΓΘΕΰΖ÷ΆΦΒΡ“ΜΗωΤΞ≈δ «’“ΒΫ“ΜΗωΉ”Φ·Θ§‘ΎΉ”Φ·÷–»Έ“βΝΫΧθ±ΏΟΜ”–ΙΪΙ≤ΒψΓΘΈ“Ο«ΒΡΡΩ±ξΨΆ «‘Ύ±Μ―Γ‘ώΒΡ±δ÷–’“ΒΫ“ΜΗω”Β”–Ήν¥σ»®÷ΒΒΡΤΞ≈δΘ§
,±Ώ «Κρ―Γ…μΧε≤ΩΈΜ÷°ΦδΒΡ»Ϊ≤ΩΩ…ΡήΒΡΝ§Ϋ”ΓΘΝμΆβΘ§ΟΩ“ΜΧθ±Ώ”…ΙΪ ΫΘ®10Θ©Φ”»®Θ§Φ¥≤ΩΖ÷«ΉΚΆΝΠΓΘΕΰΖ÷ΆΦΒΡ“ΜΗωΤΞ≈δ «’“ΒΫ“ΜΗωΉ”Φ·Θ§‘ΎΉ”Φ·÷–»Έ“βΝΫΧθ±ΏΟΜ”–ΙΪΙ≤ΒψΓΘΈ“Ο«ΒΡΡΩ±ξΨΆ «‘Ύ±Μ―Γ‘ώΒΡ±δ÷–’“ΒΫ“ΜΗω”Β”–Ήν¥σ»®÷ΒΒΡΤΞ≈δΘ§
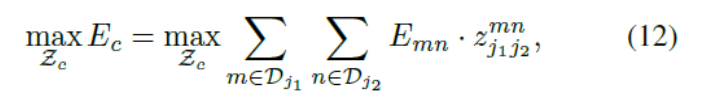
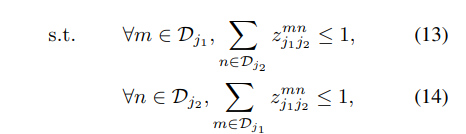
![]() «÷ΪΧεcΒΡΤΞ≈δΒΡΉή»®÷ΒΘ§
«÷ΪΧεcΒΡΤΞ≈δΒΡΉή»®÷ΒΘ§![]() «÷ΪΧεcœύΕ‘”ΎZΒΡΉ”Φ·Θ§
«÷ΪΧεcœύΕ‘”ΎZΒΡΉ”Φ·Θ§![]() «…μΧε≤ΩΖ÷
«…μΧε≤ΩΖ÷![]() ΚΆ
ΚΆ![]() ÷°ΦδΒΡ«ΉΚΆΝΠΘ§»γΙΪ Ϋ Θ®10Θ©Ε®“εΓΘΙΪ ΫΘ®13Θ©ΚΆΙΪ Ϋ(14)“Σ«σ≤Μ¥φ‘Ύ”–Ι≤Ά§ΒψΒΡΝΫΧθ±ΏΘ§Φ¥≤ΜΩ…Ρή”–Ά§÷÷άύ–ΆΒΡ÷ΪΧεΒΡΝΫΗωΙΪ”Ο“ΜΗω…μΧε≤ΩΈΜΓΘΈ“Ο«Ω…“‘”Ο–Ό―άάϊΥψΖ®14»ΞΜώΒΟ“ΜΗωΉν”≈ΤΞ≈δΓΘ
÷°ΦδΒΡ«ΉΚΆΝΠΘ§»γΙΪ Ϋ Θ®10Θ©Ε®“εΓΘΙΪ ΫΘ®13Θ©ΚΆΙΪ Ϋ(14)“Σ«σ≤Μ¥φ‘Ύ”–Ι≤Ά§ΒψΒΡΝΫΧθ±ΏΘ§Φ¥≤ΜΩ…Ρή”–Ά§÷÷άύ–ΆΒΡ÷ΪΧεΒΡΝΫΗωΙΪ”Ο“ΜΗω…μΧε≤ΩΈΜΓΘΈ“Ο«Ω…“‘”Ο–Ό―άάϊΥψΖ®14»ΞΜώΒΟ“ΜΗωΉν”≈ΤΞ≈δΓΘ
Β±”ωΒΫ“Σ’“Εύ»ΥΒΡ»Ϊ…μ…μΧεΉΥ Τ ±Θ§ΨωΕ®ΝΥZ «“ΜΗωKΖ÷ΆΦΤΞ≈δΈ ΧβΓΘ’β «“ΜΗωnpΈ ΧβΘ§”–ΚήΕύΥ…≥ΎΖΫΖ®¥φ‘ΎΓΘ‘ΎΈ“Ο«ΒΡΙΛΉς÷–Θ§Έ“Ο«Ε‘ΉνΦ―ΤΞ≈δΧμΦ”ΝΥΝΫΗωΥ…≥ΎΘ§’κΕ‘Έ“Ο«ΒΡΈ ΧβΓΘ Ήœ»Θ§Έ“Ο«―Γ‘ώΉν…Ό ΐΝΩΒΡ±Ώά¥ΜώΒΟ»ΥΧεΉΥ ΤΒΡ…ζ≥… ςΙ«ΦήΘ§»γFigure 6cΥυ ΨΓΘΤδ¥Έ,Έ“Ο«ΫΪ―Α’“Ι«ΦήΤΞ≈δΒΡΈ ΧβΖ÷ΫβΈάΝΥ“ΜΉιΕΰΖ÷ΤΞ≈δΒΡΈ ΧβΘ§≤Δ«“ΙφΕ®œύΝΎ ςΫΎΒψ÷–ΒΡΤΞ≈δœύΜΞΕάΝΔΘ§»γFigure 6dΥυ ΨΓΘΈ“Ο«‘Ύ3.1ΫΎ÷–œ‘ ΨΝΥœξœΗΒΡ±»ΫœΫαΙϊΘ§÷ΛΟςΝΥ «Ήν–ΓΒΡΦΤΥψ≥…±Ψ≤Δ«“ΧΑ–ΡΆΤάμΚήΚΟΒΊΫϋΥΤ±ΤΫϋ»ΪΨ÷ΫβΨωΖΫΑΗΓΘ‘≠“ρ «œύΝΎ ςΫΎΒψ÷°ΦδΒΡΙΊœΒ±ΜPAFœ‘ ΫΫ®ΝΔΘ§ΒΪ‘ΎΡΎ≤ΩΘ§≤ΜœύΝΎΒΡ ςΫΎΒψ÷°Φδ”…CNN“ΰ ΫΫ®ΡΘΓΘ≥ωœ÷’βΗω–‘÷ ΒΡ‘≠“ρ «CNN ήΒΫ¥σΒΡΗ–÷Σ≥Γ―ΒΝΖΘ§≤Δ«“Ζ«œύΝΎ ςΫΎΒψΒΡPAF“≤”ΑœλPAFΒΡ‘Λ≤βΓΘ
‘Ύ”–’βΝΫΗωΥ…≥ΎΒΡ«ιΩωœ¬Θ§”≈―ΓΩ…“‘ΦρΜ·ΈΣΘΚ

3.Result
Έ“Ο«‘ΎΝΫΗω÷Η±ξ…œ≤β ‘Έ“Ο«ΒΡΖΫΖ®‘ΎΕύ»ΥΉΥΧ§Φλ≤βΘΚΘ®1Θ©MPII »ΥΧεΕύ»Υ ΐΨίΦ·2COCO2016»ΥΧεΙΊΦϋΒψΦλ≤β ΐΨίΦ·15ΓΘ’βΝΫΗω ΐΨίΦ· ’Φ·ΒΡΆΦœώΑϋΚ§œ÷ Β άΫγ÷–ΚήΕύΧτ’Ϋ±»»γ”ΒΦΖΒΡ»Υ»ΚΘ§ΙφΡΘ±δΜ·Θ§’ΎΒ≤Θ§Ϋ”¥Ξ»»ΓΘΈ“Ο«ΒΡΖΫΖ®‘Ύ ΉΫλCOCO 2016ΙΊΦϋΒψΧτ’Ϋ…œ’Ι ΨΝΥΉνœ»ΫχΒΡΦΦ θ1Θ§≤Δ«“≥§Ιΐ“‘«ΑMPIIΕύ»ΥΜυΉΦ≤β ‘ΒΡΉν–¬ΫαΙϊΓΘ
Έ“Ο«ΜΙΧαΙ©‘Υ–– ±Ζ÷Έωά¥ΝΩΜ·œΒΆ≥ΒΡ–ß¬ ΓΘ ΆΦ10œ‘ ΨΝΥΈ“Ο«ΥψΖ®ΒΡ“Μ–©Ε®–‘ΫαΙϊΓΘ
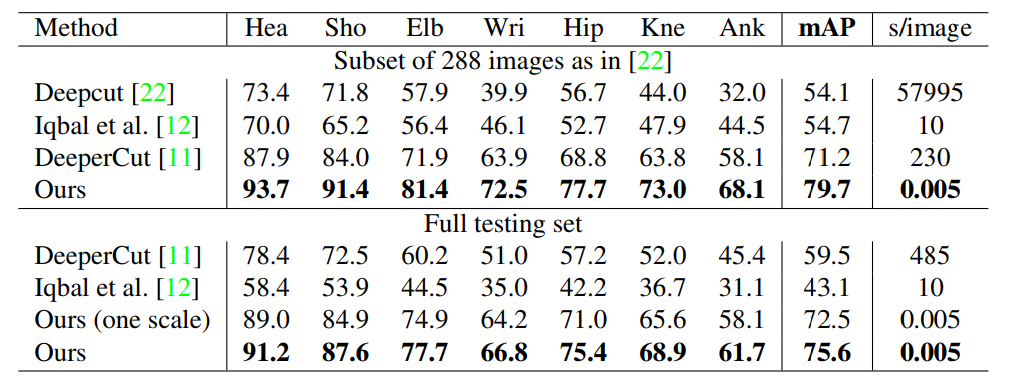
Table1.‘ΎMPII ΐΨίΦ·…œΒΡΫαΙϊΓΘΕΞ≤ΩΘΚ‘Ύ≤β ‘Φ·…œΒΡΫαΙϊΕ‘±»ΓΘ÷–Φδ:‘Ύ’ϊΗω ΐΨίΦ·…œΒΡΕ‘±»ΓΘΟΜ”–±»άΐΥ―ΥςΒΡ≤β ‘±μ ΨΈΣΓΑΘ®“ΜΗω±»άΐΘ©Γ±ΓΘ
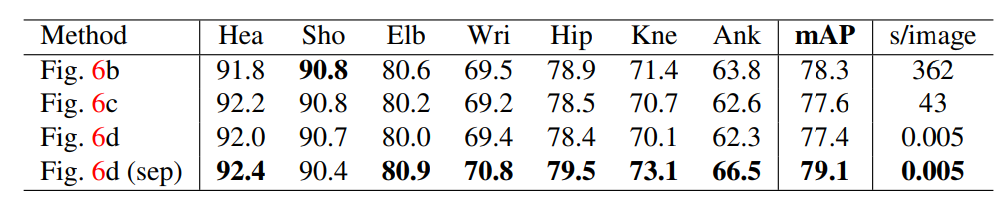
±μ2.―ι÷ΛΦ·…œ≤ΜΆ§ΫαΙΙΒΡ±»Ϋœ
3.1.Results on the MPII Multi-Person Dataset
ΈΣΝΥ±»ΫœMPII ΐΨίΦ·Θ§Έ“Ο« Ι”ΟΝΥΙΛΨΏΑϋ22≤βΝΩΝΥΥυ”–…μΧε≤ΩΈΜΕΦΜυ”ΎPCKhΒΡΤΫΨυΨΪΕ»Θ®mAPΘ©ψ–÷ΒΓΘ±μ1±»ΫœΝΥΈ“Ο«ΒΡΖΫΖ®ΚΆΤδΥϊΖΫΖ®÷°ΦδΒΡ‘ΎΫ”Ϋϋ288Ηω≤β ‘ΆΦœώΒΡœύΆ§Ή”Φ·22÷–mAP–‘ΡήΘ§ΚΆ’ϊΗωMPI≤β ‘Φ·Θ§“‘ΦΑ‘ΎΈ“Ο«Ή‘ΦΚΒΡ―ι÷ΛΦ·…œΒΡΉ‘Έ“±»ΫœΓΘ≥ΐΝΥ’β–©¥κ ©Θ§Έ“Ο«Ϋχ––±»ΫœΟΩΗωΆΦœώΒΡΤΫΨυΆΤΕœ/”≈Μ· ±ΦδΟκΓΘΕ‘”Ύ288ΗωΆΦœώΉ”Φ·Θ§Έ“Ο«ΒΡΖΫΖ®”≈”Ύ“‘«ΑΉνœ»ΫχΒΡΉ‘œ¬Εχ…œΒΡΖΫΖ®11≥§Ιΐ8.5ΘΞmAPΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§Έ“Ο«ΒΡΆΤάμ ±Φδ «6±Ε÷Η ΐΖυΕ»œ¬ΫΒΓΘΈ“Ο«‘Ύ3.3ΫΎ÷–Ϋι…ήΝΥΗϋœξœΗΒΡ‘Υ–– ±Ζ÷ΈωΓΘΕ‘”Ύ’ϊΗωMPII≤β ‘Φ·Θ§Έ“Ο«ΒΡΟΜ”–±»άΐΥ―ΥςΒΡΖΫΖ®“―Ψ≠”≈”Ύ“‘«ΑΒΡΉνœ»ΫχΒΡΖΫΖ®Θ§Φ¥‘ωΦ”ΝΥΨχΕ‘÷ΒΈΣ13ΘΞmAPΓΘ Ι”Ο3±»άΐΥ―ΥςΘ®ΓΝ0.7Θ§ΓΝ1ΚΆΓΝ1.3Θ©Ϋχ“Μ≤ΫΫΪ–‘ΡήΧαΗΏΒΫ75.6ΘΞmAPΓΘΗΟmAP”κ÷°«ΑΉ‘œ¬Εχ…œΒΡΖΫΖ®±»Ϋœ±μΟςΈ“Ο« Ι”ΟPAFΘ§”Ο”ΎΙΊΝΣ…μΧε≤ΩΈΜ–¬”±ΒΡΧΊ’ς±μ ΨΒΡ”––ß–‘ΓΘΜυ”Ύ ς–ΈΫαΙΙΘ§Έ“Ο«Μυ”ΎΆξ»ΪΝ§Ά®ΒΡΆΦ«–”≈Μ·ΙΪ ΫΒΡΧΑάΖΒΡΫβΈωΖΫΖ®±»÷±Ϋ” Ι”Ο’ϊΗωΆΦΫαΙΙΗϋΉΦ»ΖΓΘ
‘Ύ±μ2÷–Θ§Έ“Ο«œ‘ ΨΝΥ≤ΜΆ§ΒΡ±»ΫœΫαΙϊ.‘ΎΈ“Ο«ΒΡ―ι÷ΛΦ·…œ»γFigure6Υυ ΨΒΡΙ«ΦήΫαΙΙΘ§Φ¥Θ§¥”MPII―ΒΝΖΦ·÷–≈≈≥ΐΒΡ343ΗωΆΦœώΓΘ Έ“Ο«Μυ”ΎΆξ»ΪΝ§Ά®ΒΡΆΦ–Έ―ΒΝΖΈ“Ο«ΒΡΡΘ–ΆΘ§≤ΔΫχ––±»Ϋœ―Γ‘ώΥυ”–±Ώ‘ΒΒΡΫαΙϊΘ®Figure 6bΘ§¥σ‘Φ”…’ϊ ΐœΏ–‘ΙφΜ°«σΫβΘ©ΚΆΉν–Γ ς±ΏΫγΘ®Figure 6cΘ§¥σ÷¬”…œΏ–‘ΙφΜ°ΫβΨωΘ©
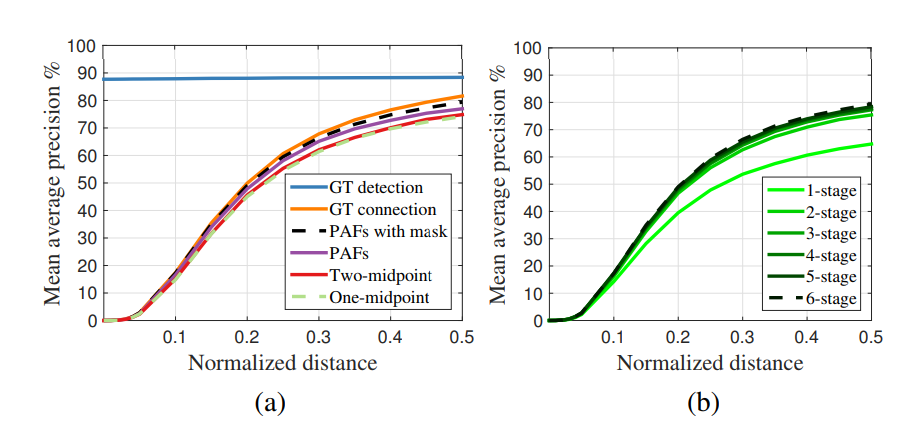
Figure 7. MPII―ι÷Λ ±≤ΜΆ§PCKhψ–÷Β…œΒΡmAP«ζœΏΉιΓΘ Θ®aΘ©Ή‘Έ“±»Ϋœ Β―ιΒΡmAP«ζœΏΓΘΘ®bΘ©PAFΩγΫΉΕΈΒΡmAP«ζœΏΓΘ*
Figure 6dΘ§Ά®Ιΐ‘Ύ±ΨΈΡ÷–ΥυΧα≥ωΒΡΧΑάΖΥψΖ®«σΫβΘ©ΓΘ ΥϊΟ«ΒΡœύΥΤ±μœ÷±μΟς Ι”ΟΉν–Γ±Ώ‘ΒΨΆΉψΙΜΝΥΓΘ Έ“Ο«―ΒΝΖΝμ“ΜΗωΡΘ–Ά÷Μ―ßœΑΉν–Γ±Ώ‘Β“‘≥δΖ÷άϊ”ΟΆχ¬γΡήΝΠ - ±ΨΈΡΧα≥ωΒΡΖΫΖ® - Φ¥±μ ΨΈΣFigure 6dΘ®sepΘ©ΓΘ ΗΟΖΫΖ®”≈”ΎFigure -6c …θ÷ΝFigure 6bΘ§Ά§ ±±Θ≥÷–߬ ΓΘ ‘≠“ρ «Ηϋ…ΌΒΡΝ§Ϋ”Θ®13Ηω±ΏΒΡ ςΡΨ”κ91Ηω±ΏΒΡ ςΘ©œύ±»ΗϋΦ”»ί“Ή ’Ν≤ΓΘ
Figure 7aœ‘ ΨΝΥΈ“Ο«‘Ύ―ι÷ΛΦ·…œΒΡΒΡœϊ»ΎΖ÷ΈωΓΘΕ‘”ΎPCKh-0.5ΒΡψ–÷ΒΘ§ Ι”ΟPAFΒΡΫαΙϊ
”≈”Ύ Ι”Ο÷–Βψ±μ ΨΒΡΫαΙϊΘ§ΨΏΧεά¥ΥΒΘ§Υϋ±»“ΜΗω÷–ΒψΗΏ≥ω2.9ΘΞΚΆ2.3ΘΞΗΏ”ΎΝΫΗω÷–ΦδΒψΓΘ±ύ¬κ
»ΥΒΡΈΜ÷ΟΚΆΥΡ÷ΪΖΫœρ–≈œΔΒΡ PAFΘ§ΡήΗϋΚΟΒΊ«χΖ÷≥ΘΦϊΒΡΫΜ≤φΓΘάΐ»γΘ§÷ΊΒΰΒΡΗλ≤≤ΓΘ”ΟΈ¥±ξΦ«ΒΡ»Υ
Ϋχ––―ΒΝΖΫχ“Μ≤ΫΧαΗΏΝΥ2.3ΘΞΒΡ±μœ÷Θ§“ρΈΣΥϋ±ήΟβΝΥ≥ΆΖΘ’φ’ΐΒΡΜΐΦΪ‘Λ≤β‘Ύ―ΒΝΖΤΎΦδΒΡΥπ ßΓΘ»γΙϊΈ“Ο«ΒΡΫβΈωΥψΖ® Ι”Ο’φ’φ ΒΒΡΙΊΦϋΒψΈΜ÷ΟΘ§Έ“Ο«Ω…“‘ΜώΒΟ“ΜΗω88.3ΘΞΒΡmAPΓΘ‘ΎFigure 7a÷–Θ§Έ“Ο« Ι”ΟGTΦλ≤βΫχ––ΫβΈωΒΡmAP
‘Ύ≤ΜΆ§ΒΡPCKhψ–÷Β÷°Φδ±Θ≥÷≤Μ±δΘ§“ρΈΣΟΜ”–±ΨΒΊΜ·¥μΈσΘ§“ρ¥ΥΓΘ Ι”ΟΈ“Ο«ΒΡΙΊΦϋΒψΒΡGTΝ§Ϋ”Φλ≤β¥οΒΫ81.6ΘΞΒΡmAPΓΘ÷ΒΒΟΉΔ“βΒΡ «Έ“Ο«ΒΡΜυ”ΎPAFΒΡΫβΈωΥψΖ® Βœ÷ΝΥάύΥΤ Ι”ΟGTΝ§Ϋ”Θ®79.4ΘΞΕ‘81.6ΘΞΘ©ΒΡmAPΓΘ’β±μΟς
Μυ”ΎPAFΒΡΫβΈω‘ΎΙΊΝΣ’ΐ»ΖΦλ≤β≤ΩΖ÷ΖΫΟφΖ«≥ΘΈ»ΫΓΓΘFigure 7bœ‘ ΨΝΥΩγΫΉΕΈ–‘ΡήΒΡ±»ΫœΓΘ mAPΥφΉ≈ΩρΦήΒΡ≤ΜΆΘ”≈Μ·ΒΞΒς‘ωΦ”ΓΘFigure 4œ‘ ΨΝΥΫΉΕΈ‘Λ≤βΒΡ÷ ΝΩΧαΗΏΓΘ
3.2. Results on the COCO Keypoints Challenge
COCO―ΒΝΖΦ·ΑϋΚ§≥§Ιΐ10Άρ»ΥΒΡ Βάΐ±ξ”–≥§Ιΐ100ΆρΗωΉήΙΊΦϋΒψΘ®Φ¥…μΧε≤ΩΖ÷Θ©ΓΘ≤β ‘Φ·ΑϋΚ§ΓΑtest-challengeΓ±Θ§ΓΑtest-devΓ±ΚΆΓΑtest-standardΓ±Ή”Φ·,ΟΩΗωΉ”Φ·¥σΗ≈”–20K’≈ΆΦœώΓΘ
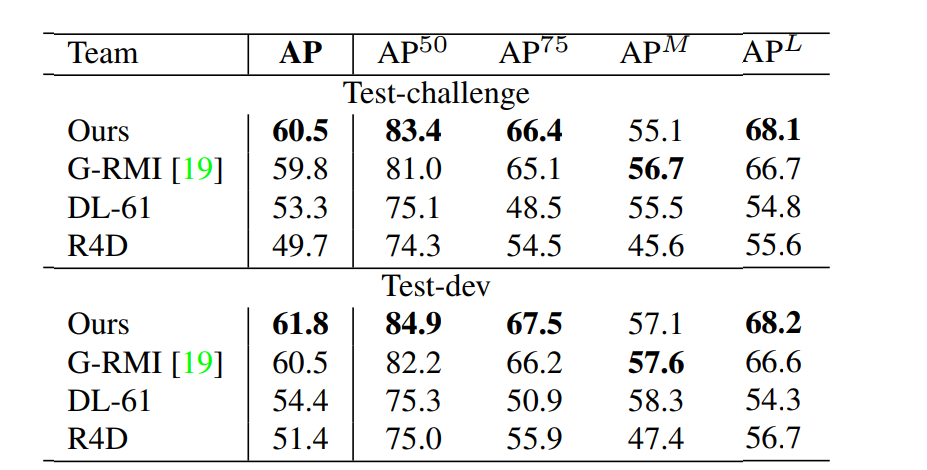
Table 3. COCO 2016ΙΊΦϋΒψΧτ’ΫΒΡΫαΙϊΓΘ …œΑκ≤ΩΖ÷ΘΚ‘Ύ≤β ‘Φ·test-challenge÷–ΒΡΫαΙϊΓΘ œ¬Ακ≤ΩΖ÷ΘΚ‘Ύtest-devΒΡΫαΙϊ(÷Μ”–ΉνΕΞΦβΒΡΖΫΖ®ΒΡ“Μ–©ΫαΙϊ)ΓΘ $AP^{50}$ «’κΕ‘”Ο”Ύ¥σΙφΡΘ»Υ»ΚΘ§OKS = 0.5ΓΘ$AP^L$ «Ε‘”Ύ¥σΙφΡΘ»Υ»Κά¥ΥΒΒΡΓΘ
COCOΤάΙάΕ®“εΕ‘œσΙΊΦϋΒψœύΥΤ–‘Θ®OKSΘ©≤Δ Ι”ΟΤΫΨυΤΫΨυΨΪΕ»Θ®APΘ©≥§Ιΐ10ΗωOKSψ–÷ΒΉςΈΣ÷ς“ΣΨΚ’υ÷Η±ξ
1ΓΘ OKS”κΕ‘œσ÷–ΒΡIoU‘ΎΡΩ±ξΦλ≤β÷–Αγ―ίΒΡΫ«…ΪœύΆ§ΓΘ Υϋ «ΗυΨί»ΥΒΡΙφΡΘΚΆ‘Λ≤βΒψ”κGTΒψ÷°ΦδΒΡΨύάκά¥ΦΤΥψΒΡΓΘ Table 3œ‘ ΨΧτ’Ϋ÷–ΕΞΦΕΆ≈Ε”ΒΡΫαΙϊΓΘ ÷ΒΒΟΉΔ“βΒΡ «Έ“Ο«ΒΡΖΫΖ®ΨΪΕ»ΒΆ”ΎΉ‘…œΕχœ¬–ΓΙφΡΘ»Υ»ΚΒΡΖΫΖ®Θ®$AP^M$Θ© ‘≠“ρ «Έ“Ο«ΒΡΖΫΖ®±Ί–κ¥ΠάμΗϋ¥σΒΡΖΕΈßΘ§ΆΦœώ÷–ΒΡΥυ”–»Υ“Μ¥Έ–‘Μώ»ΓΓΘ œύΖ¥Θ§
Ή‘…œΕχœ¬ΒΡΖΫΖ®Ω…“‘’κΕ‘«χ”ρΟφΜΐΗϋ¥σΒΡ«ιΩω÷Ί–¬Βς’ϊΟΩΗωΦλ≤βΒΫΒΡ≤ΙΕΓ
Θ§“ρ¥Υ‘ΎΫœ–ΓΒΡΙφΡΘœ¬ΆΥΜ·Ηϋ…ΌΓΘ
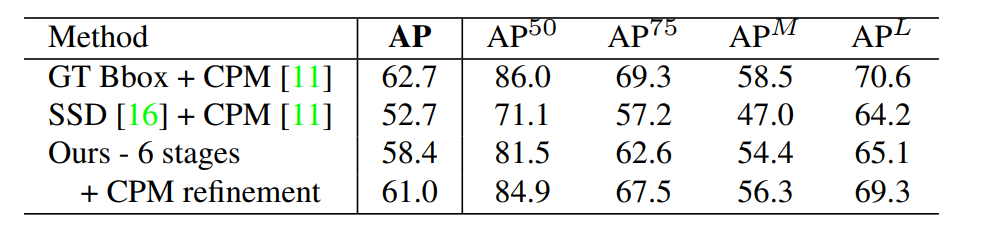
Table4.‘ΎCOCO―ι÷ΛΦ·…œΉωΉ‘Έ“Ε‘±» Β―ιΓΘ
‘Ύ±μ4÷–Θ§Έ“Ο«±®ΗφΝΥ‘ΎCOCO―ι÷ΛΦ·ΒΡΉ‘Έ“±»ΫœΘ§Φ¥ΥφΜζ―Γ‘ώΒΡ1160ΗωΆΦœώΓΘ»γΙϊΈ“Ο« Ι”ΟGT±ΏΫγΩρΚΆΒΞΗω
»ΥCPM 31Θ§Έ“Ο«Ω…“‘ Βœ÷…œœό Ι”ΟCPMΒΡΉ‘…œΕχœ¬ΖΫΖ®Θ§Φ¥62.7ΘΞΒΡAPΓΘ»γΙϊΈ“Ο« Ι”ΟΉνœ»ΫχΒΡΈοΧεΧΫ≤βΤςΘ§ΒΞΜςΕύΚ–Φλ≤βΤςΘ®SSDΘ©16Θ§–‘Ρήœ¬ΫΒ10ΘΞΓΘΗΟ±»Ϋœ±μΟςΝΥΉ‘…œΕχœ¬ΖΫΖ®ΒΡ±μœ÷―œ÷Ί“άάΒ»ΥΧεΧΫ≤βΤςΓΘœύΖ¥Θ§
Έ“Ο«Ή‘œ¬Εχ…œΒΡΖΫΖ®¥οΒΫΝΥ58.4ΘΞΒΡAPΓΘ»γΙϊ‘ΎΈ“Ο«ΫβΈωΒΡΟΩΗω»ΥΒΡ÷Ί–¬Βς’ϊΒΡ«χ”ρ…œ”Π”ΟΒΞΗω»ΥCPMΗΡΫχΝΥΫαΙϊΘ§Έ“Ο«ΜώΒΟΝΥ2.6ΘΞΒΡ’ϊΧεAP‘ω≥ΛΓΘΉΔ“βΈ“Ο«÷ΜΗϋ–¬ΝΫ÷÷ΖΫΖ®ΒΡ‘Λ≤βΙάΦΤΘ§ΖϊΚœΒΟΚήΚΟΘ§ΒΦ÷¬ΨΪ»Ζ¬ ΚΆ’ΌΜΊ¬ ΨΪΕ»ΧαΗΏΓΘΈ“Ο«‘ΛΦΤΗϋ¥σΙφΡΘΒΡΥ―ΥςΩ…“‘Ϋχ“Μ≤ΫΗΡ…ΤΈ“Ο«Ή‘œ¬Εχ…œΒΡΖΫΖ®ΒΡ±μœ÷ΓΘFigure 8œ‘ ΨΝΥ“ΜΗωΈ“Ο«ΒΡΖΫΖ®‘ΎCOCO―ι÷Λ÷–ΒΡ¥μΈσΖ÷ΫβΓΘ¥σΕύ ΐΈσ±®ά¥Ή‘±ΨΒΊΜ·≤ΜΨΪ»ΖΘ§≥ΐ¥Υ“‘ΆβΜΙ”–±≥ΨΑΜ묓ΓΘ’β±μΟς‘Ύ≤ΕΉΫΩ’ΦδΖΫΟφ±» Ε±π…μΧε≤ΩΈΜ≥ωœ÷ΒΡΜζ¬ ΖΫΟφ”–ΗϋΕύΧα…ΐΩ’ΦδΓΘ

Figure 8.ΒΎ3.2ΫΎΘ®aΘ©Θ§Θ®bΘ©ΚΆΘ®cΘ©÷–COCO―ι÷ΛΒΡAP–‘ΡήΘ§“‘ΦΑ3.3ΫΎΘ®dΘ©÷–ΒΡ‘Υ–– ±Ζ÷ΈωΓΘ

Figure 9.≥ΘΦϊΦλ≤β ßΑήΒΡ«ιΩωΘΚΘ®aΘ©Κ±ΦϊΒΡΉΥ ΤΜρΆβΙέΘ§Θ®bΘ©»± ßΜρ¥μΈσΒΡ≤ΩΦΰΦλ≤βΘ§Θ®cΘ©÷ΊΒΰ≤ΩΦΰΘ§Φ¥≤ΩΦΰΦλ≤β”…ΝΫΗω»ΥΙ≤œμΘ§Θ®dΘ©”κΝΫΗω»ΥΒΡ≤ΩΖ÷ΝΣœΒ¥μΈσΘ§Θ®e-fΘ©ΘΚΕ‘ΒώœώΜρΕ·ΈοΒΡΈσ±®
3.3. Runtime Analysis
ΈΣΝΥΖ÷ΈωΈ“Ο«ΖΫΖ®ΒΡ‘Υ–– ±–‘ΡήΘ§Έ“Ο« ’Φ·Κ§”–≤ΜΆ§»Υ ΐΒΡ ”ΤΒΓΘ‘≠±ΨΒΡ÷Γ¥σ–ΓΈΣ1080ΓΝ1920Θ§Έ“Ο«ΫΪΤδΒς’ϊΈΣ368ΓΝ654‘Ύ≤β ‘ΤΎΦδΒς’ϊΒΫ ΚœGPUΡΎ¥φ¥σ–ΓΓΘ‘Υ–– ±Ζ÷Έω «‘Ύ≈δ±Η“ΜΩιNVIDIA GeForce GTX-1080 GPUΒΡ± Φ«±ΨΒγΡ‘…œΫχ––ΒΡΓΘ‘ΎFigure 8d÷–Θ§Έ“Ο« Ι”Ο»ΥΈοΦλ≤βΚΆΒΞ»ΥCPMΉςΈΣΉ‘…œΕχœ¬ΒΡ±»ΫœΘ§ΥϋΟ«‘Υ–– ±Φδ¥σ÷¬”κ»Υ ΐ≥…’ΐ±»ΓΘœύ±»÷°œ¬Θ§Έ“Ο«Ή‘œ¬Εχ…œΒΡΖΫΖ®ΒΡ‘Υ–– ±ΦδΥφΉ≈»Υ ΐΒΡ‘ωΦ”Θ§‘ω≥ΛœύΕ‘ΜΚ¬ΐΓΘ‘Υ–– ±Φδ”…ΝΫΗω÷ς“Σ≤ΩΖ÷Ήι≥…ΘΚΘ®1Θ©CNN¥Πάμ ±ΦδΘ§Τδ‘Υ–– ±Η¥‘”Ε»ΈΣOΘ®1Θ©Θ§≥ΘΝΩΈΣ≤ΜΕœ±δΜ·ΒΡ»Υ ΐ; Θ®2Θ©Εύ»ΥΫβΈω‘Υ–– ±Η¥‘”Ε»ΈΣ$O(n^2)$Θ§Τδ÷–n¥ζ±μ»Υ ΐΓΘΒΪ «Θ§ΫβΈω ±Φδ≤ΜΜαœ‘Ή≈”Αœλ’ϊΧε‘Υ–– ±ΦδΘ§“ρΈΣΥϋ±»CNN¥Πάμ–ΓΝΫΗω ΐΝΩΦΕΓΘάΐ»γΘ§Ε‘”Ύ9Ηω»Υά¥ΥΒΘ§ΫβΈω–η“Σ0.58ΚΝΟκΘ§CNN–η“Σ99.6ΚΝΟκΓΘΈ“Ο«ΒΡΖΫΖ®“―Ψ≠¥οΒΫΝΥ“ΜΗω19»ΥΒΡ ”ΤΒ8.8 fpsΒΡ–ßΙϊΓΘ
4. Discussion
ΨΏ”–…γΜα“β“εΒΡ ±ΩΧΘ§±» ≤Ο¥ΕΦ÷Ί“ΣΘ§Ζώ‘ρΘ§Τ» Ι»ΥΟ«÷ΤΉς’’Τ§ΚΆ ”ΤΒΓΘΈ“Ο«ΒΡ’’Τ§Φ·«ψœρ”Ύ≤ΕΉΫΕ‘”ΎΗω»Υ”–“β“εΒΡ ±ΩΧΘΚ…ζ»’Θ§ΜιάώΘ§ΦΌΤΎΘ§≥· ΞΘ§Χε”ΐ»ϋ ¬Θ§±œ“ΒΒδάώΘ§Φ“ΆΞ–ΛœώΒ»ΓΘΈΣΝΥ ΙΜζΤςΡήΙΜΫβ Ά’β–©’’Τ§ΒΡ÷Ί“Σ–‘Θ§
ΥϊΟ«–η“ΣΝΥΫβΆΦΤ§÷–ΒΡ»ΥΓΘ Β ±ΨΏ”–’β÷÷Η–÷ΣΗω»ΥΚΆ…γΜα––ΈΣΒΡ»ΥΒΡΡήΝΠΒΡΜζΤςΫΪΡήΙΜΉς≥ωΖ¥”Π…θ÷Ν≤Έ”κΤδ÷–ΓΘ
‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«ΩΦ¬«ΝΥ’β“ΜΗ–÷ΣΈ ΧβΒΡΙΊΦϋΉι≥…≤ΩΖ÷ΘΚ Β ±ΥψΖ®Φλ≤β2DΉΥ ΤΆΦœώ÷–ΒΡΕύΗω»ΥΓΘΈ“Ο«Χα≥ωΝΥ“ΜΗωΟς»ΖΒΡΖ«≤Έ ΐΒΡΆ®Ιΐ±ύ¬κ»ΥΧεΥΡ÷ΪΒΡΈΜ÷ΟΚΆΖΫœρΒΡΙΊΦϋΒψΝ§Ϋ”±μ ΨΖΫΖ®ΓΘΒΎΕΰΘ§Έ“Ο«…ηΦΤΝΥ“ΜΗω…μΧε≤ΩΖ÷Φλ≤βΚΆ…μΧε≤ΩΖ÷Ν§Ϋ”Ι≤Ά§―ßœΑΒΡ“ΜΗωΦήΙΙΓΘΒΎ»ΐΘ§Έ“Ο«÷ΛΟςΝΥ’β“ΜΒψΧΑάΖΒΡΫβΈωΥψΖ®Ήψ“‘≤ζ…ζΗΏ÷ ΝΩ…θ÷Ν±Θ≥÷–߬
…μΧεΉΥΧ§ΒΡΦλ≤βΘ§Φ¥ Ι‘ΎΥφΉ≈ΆΦœώ÷–»Υ ΐΒΡ‘ωΦ”ΒΡ«ιΩωœ¬“άΨ…Ρή±Θ≥÷ΓΘΈ“Ο«‘ΎFigure 9÷–’Ι ΨΝΥ¥ζ±μ–‘ ßΑήΑΗάΐΓΘΈ“Ο«“―ΙΪΩΣΖΔ≤ΦΈ“Ο«ΒΡ¥ζ¬κΘ®Αϋά®Ψ≠Ιΐ―ΒΝΖΒΡΡΘ–ΆΘ©»Ζ±ΘΆξ»ΪΩ…Η¥œ÷≤ΔΙΡάχ‘Ύ’β“ΜΝλ”ρΈ¥ά¥ΒΡ―–ΨΩΓΘ