P1-P23
- �����¼���������ӣ������Ǹ��ȸ����ŵ����ӣ�������һ�������㷨��������Щ���µ�һ���������ලѧϰ��ϸ���г������ӣ����Ե����ලѧϰ���⣬��Ϊֻ���õ��㷨���ݣ������㷨ȥ�Զ��ط���ϸ���г���
- Octave,����ѵĿ�Դ������ʹ��һ���� Octave �� Matlab�Ĺ��ߣ�����ѧϰ�㷨���ֻ�м��д���Ϳ�ʵ�֡�
- ���ۺ���Ҳ������ƽ����������ʱҲ����Ϊƽ�������ۺ��������ƽ�����ۺ��������ڴ�������⣬�ر��ǻع����⣬����һ��������ѡ����ʦ�����������ǣ��κηǸ����������������ۺ�����ֻ��ʵ���ж����ƽ����������Ϊ������й⻬�ԡ���
- ʵ�������������ϴ������£��ݶ��½��������淽��Ҫ������һЩ������ʦ������Ҫ˼��һ��Ϊʲô��
- ��������Զ�ά���������ʱ������Ҫ��֤��Щ��������������ij߶ȣ��⽫�����ݶ��½��㷨�����������
- ͨ�����Կ��dz���Щѧϰ�ʣ�? = 0.01��0.03��0.1��0.3��1��3��10��
- ������Dz��ö���ʽ�ع�ģ�ͣ��������ݶ��½��㷨ǰ���������ŷdz��б�Ҫ��
P24-P27
P32-P34
- ֻҪ������������Ŀ������������һ���ܺõļ�������ȵ���������������˵��ֻҪ������������С��һ��ͨ��ʹ�ñ����̷�������ʹ���ݶ��½�����
- �ݶ��½�����һ���dz����õ��㷨�����������д����������������Իع����⡣
- ʹ�ò�ͬ�����Դ�����ķ�������Ϊα�档����ʦ������ʹ�ò�ͬ�����Դ�����ķ�������Ϊα�档����IJ��Ǻ�������α��һ��ָ���Dz���������ij�������µġ��������
- ���ֲ���������������ٷ����������ڴ����ʵ�����Իع��У����ֲ���������ⲻӦ�ù���Ĺ�ע???�Dz�����ġ�
- �������淽�̽������ ? = (???)?1??? ��
- Octave ��һ�ֺܺõ�ԭʼ����(prototyping language)��ʹ�� Octave ���ܿ��ٵ�ʵ������㷨��ʣ�µ����飬��ֻ��Ҫ���д��ģ����Դ���ã���ֻ���ٻ�ʱ���� C++�� Java ��Щ�����㷨����ʵ�־����ˡ�
- ���ع��㷨�Ƿ����㷨�����ǽ�����Ϊ�����㷨ʹ�á��������ڱ�ǩ ? ȡֵ��ɢ��������磺1 0 0 1��
P34-P44
- ʵ�������������ϴ������£��ݶ��½��������淽��Ҫ������һЩ��
*���淽�̷���Ҫ����(XTX)-1�������������n�ϴ���������۴����Ƚ�������Ϊ������ļ���ʱ�临�Ӷ�ΪO(n3)��ͨ����˵��nС��10000 ʱ���ǿ��Խ��ܵġ�
- ���ʵ��logistics �ع����ࡣ
*1.OvR������n�����͵��������з���ʱ���ֱ�ȡһ��������Ϊһ�࣬��ʣ����������͵�����������һ�࣬�������γ���n�����������⣬ʹ�����ع��㷨��n�����ݼ�ѵ����n��ģ�ͣ�����Ԥ�������������n��ģ���У����ø�����ߵ��Ǹ�ģ�Ͷ�Ӧ���������ͼ���Ϊ�Ǹ�Ԥ�����������ͣ�n�����ͽ���n�η��࣬ѡ�����÷���ߵġ�
2.OvO������n�������У�ÿ������2�����ͣ�������ϣ�һ����Cn2�ֶ����������ʹ��Cn2��ģ��Ԥ���������ͣ���Cn2��Ԥ�������������������������ͣ�����Ϊ�Ǹ��������յ�Ԥ�����͡�
- ���ع�ģ�͵ļ����ǣ�
 �����У�X������������,g������������logistic function)��һ�����õ�������ΪS�κ�����Sigmoid function������ʽΪ��
�����У�X������������,g������������logistic function)��һ�����õ�������ΪS�κ�����Sigmoid function������ʽΪ��  ��
�� - ���ع�Ĵ��ۺ���Ϊ:
 ��
�� - ��Ȼ���ع�õ����ݶ��½��㷨�����Ͽ���ȥ�����Իع���ݶ��½��㷨һ�����������ع��
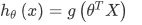 �����Իع��
�����Իع��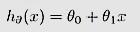 �в�ͬ������ʵ�����Dz�һ���ġ�
�в�ͬ������ʵ�����Dz�һ���ġ� - �����ݶ��½��㷨���⣬����һЩ������������ۺ�����С���㷨����Щ�㷨���Ӹ��Ӻ���Խ������ͨ������Ҫ�˹�ѡ��ѧϰ�ʣ�ͨ�����ݶ��½��㷨Ҫ���ӿ��١���Щ�㷨�У������ݶȣ�Conjugate Gradient�����ֲ��Ż���(Broyden fletcher goldfarb shann,BFGS)�������ڴ�ֲ��Ż���(LBFGS)��
- ������Ƿ����˹�������⣬Ӧ����δ�����1.����һЩ���ܰ���������ȷԤ����������������ֹ�ѡ������Щ����������ʹ��һЩģ��ѡ����㷨����æ������PCA����2.�����������е����������Ǽ��ٲ����Ĵ�С��
 ���������е��κ�һ������
���������е��κ�һ������- ���������Իع黹�����ع鶼������һ��ȱ�㣬����������̫��ʱ������ĸ��ɻ�dz���
P45-P61
- ���������в�����ij�ʼ������Ϊ0��
*��Ϊ��������еij�ʼ������Ϊ0���⽫��ζ�ŵڶ�������м��Ԫ��������ͬ��ֵ��ͬ���������ʼ���еIJ�����Ϊһ����0���������Ҳ��һ���ġ�ͨ����ʼ����Ϊ������֮������ֵ��
- �������Ǽ�������Щƫ����㷨��
- ������ģ������������Ԫ���ղ�ͬ�㼶��֯���������磬ÿһ����������������һ������������
- �������У�������Ԫ�����м�㣩�ļ����������ʾ�����㣬��������(AND)������(OR)��
- �ݶȵ���ֵ���鷽����ͨ�������ݶ�ֵ���������Ǽ���ĵ���ֵ�Ƿ����������Ҫ��ġ����ݶȵĹ��Ʋ��õķ������ڴ��ۺ������������ߵķ���ѡ���������dz����ĵ�Ȼ������������ƽ��ֵ���Թ����ݶȡ�
- ѵ�������磺1.�����������ʼ����2.�������������������еģ�3.��д������ۺ���
 �Ĵ��룻4.���÷���������������ƫ������5.������ֵ���鷽��������Щƫ������6.ʹ���Ż��㷨����С�����ۺ�����
�Ĵ��룻4.���÷���������������ƫ������5.������ֵ���鷽��������Щƫ������6.ʹ���Ż��㷨����С�����ۺ�����
P62-P67
- ѡ��˵ķ���Ϊ��
1.ʹ��ѵ����ѵ����12����ͬ�̶�����ģ�ͣ�
2.��12��ģ�ͷֱ�Խ�����֤������ij�������֤��
3.ѡ��ó�������֤�����С��ģ�ͣ�
4.���ò���3��ѡ��ģ�ͶԲ��Լ�����ó��ƹ���Ҳ����ͬʱ��ѵ�����ͽ�����֤��ģ�͵Ĵ��ۺ��������˵�ֵ������һ��ͼ���ϡ�
- ѵ�������ͽ�����֤��������ʱ��ƫ��/Ƿ��ϣ�������֤�����Զ����ѵ�������ʱ������/����ϡ�
- ����ʹ��ѧϰ�������ж�ijһ��ѧϰ�㷨�Ƿ���ƫ��������⡣
- �ڸ߷���/����ϵ�����£����Ӹ������ݵ�ѵ�������ܿ�������㷨Ч����
- ͨ��ѡ��ϴ�������粢������������Ȳ��ý�С��������Ч��Ҫ�á�
- �����������е����ز�IJ�����ѡ��ͨ����һ�㿪ʼ�����Ӳ�����Ϊ�˸��õ���ѡ�������ݷ�Ϊѵ������������֤���Ͳ��Լ�����Բ�ͬ���ز������������ѵ�������硣
- һ���Ƽ��ڽ�����֤������������������
- ���о�һ���µĻ���ѧϰ����ʱ�������Ƽ���ʵ��һ����Ϊ���١����㲻����ô�������㷨��
P68-P77
- ���ع�ģ�ͣ�֧��������ģ�ͣ�������֮�䣬Ӧ�����ѡ���أ�
#nΪ��������mΪѵ����������
(1)��������m���ԣ�nҪ�����࣬��ѵ��������������֧������ѵ��һ�����ӵķ�����ģ�ͣ�����ѡ�����ع�ģ�ͻ��߲����˺�����֧����������
(2)���n��С������m��С�еȣ�����n�� 1-1000 ֮�䣬��m��10-10000֮�䣬ʹ�ø�˹�˺�����֧����������
(3)���n��С����m�ϴ�����n��1-1000֮�䣬��m����50000����ʹ��֧����������dz�������������Ǵ��졢���Ӹ����������Ȼ��ʹ�����ع���˺�����֧����������
��������������������¶����ܻ��нϺõı��֡�
- ��ƫб�������Ϊ��ѵ�������зdz����ͬһ�����������ֻ�к��ٻ�û���������������
- �����ع����������ȣ�֧���������������SVM����ѧϰ���ӵķ����Է���ʱ�ṩ��һ�ָ�Ϊ����������ǿ��ķ�ʽ��
- ��ʱ��֧�������������Ǵ����������
- ��SVM�У�C�ϴ�ʱ���൱�ڦ˽�С�����ܻᵼ�¹���ϣ��߷��C��Сʱ���൱�ڦ˽ϴ��ܻᵼ�µ���ϣ���ƫ�
- �˺���K��kernel function������ָK(x, y) = <f(x), f(y)>������x��y��nά������ֵ��f(��) �Ǵ�nά��mά��ӳ�䣨ͨ����m>>n����<x, y>��x��y���ڻ���inner product��(Ҳ�Ƶ����dot product��)��
- ͨ���Ǹ���ѵ����������ѡ��ر�������������ѵ��������m��������������ѡȡm���ر꣬������:l(1)=x(1), l(2)=x(2),��, l(m)=x(m)��
- ��ʹ�ø�˹�˺���֮ǰ�������������Ƿdz���Ҫ�ġ�
- ֧��������Ҳ���Բ�ʹ�ú˺�������ʹ�ú˺����ֳ�Ϊ���Ժ˺���(linear kernel)���������÷dz����ӵĺ���������ѵ���������dz���������dz��ٵ�ʱ���Բ������ֲ����˺�����֧����������
 �ϴ�ʱ�����ܻᵼ�µͷ����ƫ�
�ϴ�ʱ�����ܻᵼ�µͷ����ƫ� ��Сʱ�����ܻᵼ�µ�ƫ��߷��
��Сʱ�����ܻᵼ�µ�ƫ��߷��- ����ʹ�ø��Ż������⣨liblinear��libsvm�ȣ���������
 ��
��
P77-P84
- K-��ֵ��һ�������㷨������������Ҫ�����ݾ����n���飬�䷽��Ϊ:
1.����ѡ��K������ĵ㣬��Ϊ�������ģ�cluster centroids����
2.�������ݼ��е�ÿһ�����ݣ����վ���K�����ĵ�ľ��룬�����������������ĵ������������ͬһ�����ĵ���������е�۳�һ�ࡣ
3.����ÿһ�����ƽ��ֵ�������������������ĵ��ƶ���ƽ��ֵ��λ�á�
4.�ظ�����2-4ֱ�����ĵ㲻�ٱ仯��
- K-��ֵ�����ռ��ľ����㷨���㷨����һ��δ��ǵ����ݼ���Ȼ�����ݾ���ɲ�ͬ���顣
- K-��ֵ��С�����⣬��Ҫ��С�����е����ݵ������������ľ������ĵ�֮��ľ���֮�ͣ���� K-��ֵ�Ĵ��ۺ������ֳƻ��亯�� Distortion function��Ϊ��
 ��
�� - Ϊ�˽��K-��ֵ�ľֲ���Сֵ��ȡ���ڳ�ʼ���������������⣬ͨ����Ҫ�������K-��ֵ�㷨��ÿһ�ζ����½��������ʼ��������ٱȽ϶������K-��ֵ�Ľ����ѡ����ۺ�����С�Ľ�������ַ����ڽ�С��ʱ��2--10�����ǿ��еģ��������K�ϴ���ô��Ҳ���ܲ��������Եظ��ơ�Ҫ�Ծ���Ľ�����иĽ��ķ��������Խ��������SSE�����ƽ���ͣ����ڶ�������Ч����ָ�꣬SSEԽС��ʾ���ݵ�Խ�ӽ������ǵ����ģ�����Ч��ҲԽ�ã�ֵ�Ĵػ���Ϊ�����أ�ͬʱΪ�˱��ִ��������䣬���Խ�ij�����ؽ��кϲ���
- �����༰��ѧϰ�����У�����ܽ����ݿ��ӻ�������Ѱ�ҵ�һ�����õĽ����������ά���������ǡ�
- ���ɷַ���(PCA)������Ľ�ά�㷨��
- PCA������һ���ܴ���ŵ��ǣ�������ȫ�������Ƶġ���PCA�ļ����������ȫ����Ҫ��Ϊ���趨�������Ǹ����κξ���ģ�ͶԼ�����и�Ԥ�����Ľ��ֻ��������أ����û��Ƕ����ġ����ǣ���һ��ͬʱҲ���Կ�����ȱ�㡣����û��Թ۲������һ��������֪ʶ�����������ݵ�һЩ������ȴ��ͨ���������ȷ����Դ������̽��и�Ԥ�����ܻ�ò���Ԥ�ڵ�Ч����Ч��Ҳ���ߡ�
P85-P90
- PCA ����nά��kά :
#��һ���Ǿ�ֵ��һ����������Ҫ��������������ľ�ֵ��Ȼ����![]() ������������ڲ�ͬ���������ϣ����ǻ���Ҫ������Ա���
������������ڲ�ͬ���������ϣ����ǻ���Ҫ������Ա���![]() ��
��
�ڶ����Ǽ���Э�������covariance matrix��![]() :
:![]() ��
��
�������Ǽ���Э�������![]() ������������eigenvectors��: [U, S, V]= svd(sigma)��
������������eigenvectors��: [U, S, V]= svd(sigma)��
����һ��![]() ά�ȵľ�����ʽ�е�U��һ������������֮����СͶ�����ķ����������ɵľ������ϣ�������ݴ�nά����kά��ֻ��Ҫ��U��ѡȡǰk�����������һ��n x kά�ȵľ�����
ά�ȵľ�����ʽ�е�U��һ������������֮����СͶ�����ķ����������ɵľ������ϣ�������ݴ�nά����kά��ֻ��Ҫ��U��ѡȡǰk�����������һ��n x kά�ȵľ�����![]() ��ʾ��Ȼ��ͨ�����¼�����Ҫ�������������
��ʾ��Ȼ��ͨ�����¼�����Ҫ�������������![]() :
: ![]() ,����
,����![]() ��
��![]() ά�ģ���˽��Ϊ
ά�ģ���˽��Ϊ![]() ά�ȡ�
ά�ȡ�
- ���ɷ�����ѡ���㷨: ������Э�������sigma�����á�svd��������ʱ�������������[U,S,V]=svd(sigma),����U����������,��S��һ���ԽǾ��Խ��ߵ�Ԫ��Ϊ S11,S22,S33...Snn �����������Ԫ�ض���0������ʹ�þ���
 ��һ��n x n�ľ���ֻ�жԽ�������ֵ����������Ԫ����0��������ƽ�����������ѵ��������ı�����
��һ��n x n�ľ���ֻ�жԽ�������ֵ����������Ԫ����0��������ƽ�����������ѵ��������ı����� ,Ҳ���ǣ�
,Ҳ���ǣ� ��
�� - �������Ҫ�ɷַ��������1. �����ɷַ���PCA��ֹ������Dz��ʺϵģ������Ӧ�ò�������2. ����Ŀ�У�Ӧ�������Ų�����PCA����û��Ǵ�����ԭʼ������ʼ��ֻ���б�Ҫ��ʱ���㷨����̫������ռ��̫���ڴ棩�ſ��Dz�����Ҫ�ɷַ�����
- ����һ���� ����ô�ܻ�ȥ���ԭʼ�Ķ�ά�ռ��أ�xΪ2ά��zΪ1ά��
 ���෴�ķ���Ϊ��
���෴�ķ���Ϊ�� ,
,  ��
�� - �쳣�����Ҫ����ʶ����ƭ��
- ����ѧϰ�ж��ڷ���ͨ��ֻ����(m)����ͳ��ѧ�е�(m-1)���������汾�Ĺ�ʽ���������Ժ���ѧ���������в�ͬ��������ʵ��ʹ���У����ǵ�������С���������Ժ��Բ��ơ�
- ͨ�����������Ϊ����x���ϸ�˹�ֲ�
 ��������ܶȺ���Ϊ��
��������ܶȺ���Ϊ�� ,���ǿ����������е�������Ԥ�������е�
,���ǿ����������е�������Ԥ�������е� ��
�� �ļ��㷽�����£�
�ļ��㷽�����£� ,
,  ��
��
P91-P103
- Эͬ�����㷨ʹ�ò������£�
#1.��ʼ![]() ΪһЩ���Сֵ��
ΪһЩ���Сֵ��
2.ʹ���ݶ��½��㷨��С�����ۺ�����
3.��ѵ�����㷨��Ԥ��![]() Ϊ�û�j����Ӱi�����֡�
Ϊ�û�j����Ӱi�����֡�
- �쳣����㷨�����ڸ��������ݼ�
 ������Ҫ���ÿһ����������͵Ĺ���ֵ��
������Ҫ���ÿһ����������͵Ĺ���ֵ��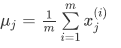 ��
�� һ�����ǻ����ƽ��ֵ�ͷ���Ĺ���ֵ�������µ�һ��ѵ��ʵ��������ģ�ͼ��㣺
һ�����ǻ����ƽ��ֵ�ͷ���Ĺ���ֵ�������µ�һ��ѵ��ʵ��������ģ�ͼ��㣺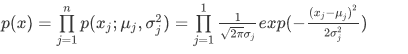 ����
���� ʱ��Ϊ�쳣��
ʱ��Ϊ�쳣�� - �쳣����㷨��һ���Ǽලѧϰ�㷨����ζ�����������ݽ������y��ֵ���������������Ƿ�������쳣�ġ�������һ���쳣���ϵͳʱ�����ԴӴ���ǣ��쳣�����������������֣�������ѡ��һ���������������ڹ���ѵ������Ȼ����ʣ�µ��������ݺ��쳣���ݻ�ϵ����ݹ��ɽ�����鼯�Ͳ��Լ�����������۷������£�1.���ݲ��Լ����ݣ�����������ƽ��ֵ�ͷ������
 ������2.�Խ�����鼯������ʹ�ò�ͬ��ֵ��Ϊ��ֵ����Ԥ�������Ƿ��쳣������F1ֵ��F��P����ȷ�ʣ���R���ٻ��ʣ��ļ�Ȩ����ƽ�������õ���F1ֵ����ֵԽ�� ����Խ�ã����߲������ȫ�ʵı�����ѡ��
������2.�Խ�����鼯������ʹ�ò�ͬ��ֵ��Ϊ��ֵ����Ԥ�������Ƿ��쳣������F1ֵ��F��P����ȷ�ʣ���R���ٻ��ʣ��ļ�Ȩ����ƽ�������õ���F1ֵ����ֵԽ�� ����Խ�ã����߲������ȫ�ʵı�����ѡ��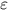 ��3.ѡ��
��3.ѡ�� ����Բ��Լ�����Ԥ�⣬�����쳣����ϵͳ��ֵ�����߲������ȫ��֮�ȡ�
����Բ��Լ�����Ԥ�⣬�����쳣����ϵͳ��ֵ�����߲������ȫ��֮�ȡ� - ��Ԫ��˹�ֲ���
 ��
�� ����
���У� �Ƕ�����
�Ƕ����� ��
�� - ��һ���������ݵ��Ƽ�ϵͳ�㷨�У��������ϣ���Ƽ��Ķ�����һЩ���ݣ���Щ�������й���Щ������������������Щ����������һ���Ƽ�ϵͳ�㷨������������Իع�ģ�ͣ��������ÿһ���û���ѵ��һ�����Իع�ģ�ͣ���
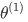 �ǵ�һ���û���ģ�͵IJ����� �����У�
�ǵ�һ���û���ģ�͵IJ����� �����У� �û�j�IJ�����������Ӱi�����������������û��͵�Ӱ������Ԥ������Ϊ��
�û�j�IJ�����������Ӱi�����������������û��͵�Ӱ������Ԥ������Ϊ��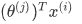 ��
�� - Эͬ�����㷨�ַ�Ϊ�����û���Эͬ�����㷨�ͻ�����Ʒ��Эͬ�����㷨��
- �����е��û������еĵ�Ӱ�������ּ���ʱ���������һ���û� Eve������ Eve û��Ϊ�κε�Ӱ���֣���ô��ʲôΪ����ΪEve�Ƽ���Ӱ�أ�������Ҫ�Խ��
 ������о�ֵ��һ����������ÿһ���û���ijһ����Ӱ�����ּ�ȥ�����û��Ըõ�Ӱ���ֵ�ƽ��ֵ��
������о�ֵ��һ����������ÿһ���û���ijһ����Ӱ�����ּ�ȥ�����û��Ըõ�Ӱ���ֵ�ƽ��ֵ��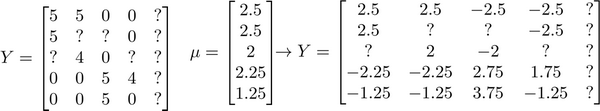 Ȼ����������µ�
Ȼ����������µ� ������ѵ���㷨�� ���Ҫ����ѵ�������㷨��Ԥ�����֣�����Ҫ��ƽ��ֵ���¼ӻ�ȥ��Ԥ��
������ѵ���㷨�� ���Ҫ����ѵ�������㷨��Ԥ�����֣�����Ҫ��ƽ��ֵ���¼ӻ�ȥ��Ԥ��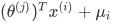 ������Eve����ģ�ͻ���Ϊ����ÿ����Ӱ�����ֶ��Ǹõ�Ӱ��ƽ���֡�
������Eve����ģ�ͻ���Ϊ����ÿ����Ӱ�����ֶ��Ǹõ�Ӱ��ƽ���֡�
P104-P113
- ��һ�Ÿ�����ͼƬ��ʶ�����֣�
#1.������⣨Text detection��������ͼƬ�ϵ���������������������뿪����
2.�ַ��з֣�Character segmentation�����������ַָ��һ������һ���ַ���
3.�ַ����ࣨCharacter classification������ȷ��ÿһ���ַ���ʲô��
- ����ݶ��½��㷨Ϊ�����ȶ�ѵ���������ϴ�ơ���Ȼ�� Repeat (usually anywhere between1-10){

- ����ݶ��½��㷨���������ijһ������ֵ�����ǻ�������ֵ��Ե�������ڴ����������ݶ��½��㷨�У�ѧϰ���ʦ�һ���DZ��ֲ���ģ�����ȷʵ��Ҫ����ݶ��㷨������ȫ������ֵ��������ʱ��ı仯��Сѧϰ���ʦ���ֵ��
- С�����ݶ��½��㷨�ǽ��������ݶ��½��㷨������ݶ��½��㷨֮���һ���㷨��С�����ݶ��½��㷨���кõ�������ʵ��ʱ��������ݶ��½��㷨�ã�����������£�10��������Ϳ���ʹ��һ�ָ��������ķ���ʵ�֣��������ֲ��м���10�������ĺ͡�
- ������һ���������е���վ��������ѧϰ���������£�
 ���㷨֮����û��ʹ��
���㷨֮����û��ʹ��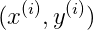 ������Ϊ����ѧϰ���ƽ�ijһ������֮�Ͷ����������������ѧϰϵͳ�ܹ�����ʱ��ı仯�������Ȳ��ϱ仯���£������ʵ����µ��û�Ⱥ����Ӧ�����ֳ����IJ�����
������Ϊ����ѧϰ���ƽ�ijһ������֮�Ͷ����������������ѧϰϵͳ�ܹ�����ʱ��ı仯�������Ȳ��ϱ仯���£������ʵ����µ��û�Ⱥ����Ӧ�����ֳ����IJ����� - ӳ������ݲ��У������ݼ����������̨���������ÿһ̨������������ݼ���һ���Ӽ���Ȼ�����Ľ����������ͣ��������һ̨�������ʵ��Map Reduce���������ִ�������Ķ��ϵͳ����ѵ�������ֳɼ��ݣ�ÿһ���˴�������һ���֣�Ҳ��ʵ�ֲ��е�Ч����������Ϊ����ʼ�ջ�����һ̨���������еģ���˲����������ӳٵ�Ӱ�졣
- ����������һ��������ͼ���г�ȡ����ļ�����Ҳ����������ʶ��
- �йػ�ø������ݵļ��ַ������˹����ݺϳɣ��ֶ��ռ���������ݣ��ڰ���
- �ڻ���ѧϰ��Ӧ���У�ͨ�����������ܹ�֪����һ������ֵ�û�ʱ��;���ȥ���ơ�