转载 https://wolfsonliu.github.io/archive/python-xue-xi-bi-ji-numpy.html
Numpy 简介
NumPy 是 Python 科学计算的底层包, 提供了 ndarray 等方便大规模科学计算的类和方法等. NumPy 也是 Python 数据分析所用的 Pandas 包的基础, 所以这里简要介绍一下 numpy 的基础使用以方便学习和使用 Pandas 进行生物信息学分析.
NumPy 主要包括: N-dimensional array object, 即 ndarry; 向量化可广播的函数和方法; 方便整合 C/C++ 和 Fortran 代码的工具; 线性代数函数, 傅立叶变换和随机数生成器.
NumPy 已经归属于整合的 SciPy 科学计算包, 有更多复杂的功能, 可以应用于不同的科学计算任务, 本文所介绍的 NumPy 基础主要是作为未来学习和使用 Pandas 包进行数据分析, 所以不会提及太复杂的内容, 主要会是 ndarry 的一些函数和十分好用的生成随机数的函数.
创建数组
NumPy 中有多种创建数组的方法, 还可以根据需要创建单位矩阵或者零矩阵. NumPy 中建立的数组类型为 ndarray, 是能够高效进行大规模计算的数据类型.
np.array: 可以把 list, tuple, array, 或者其他的序列模式的数据转创建为 ndarray, 默认创建一个新的 ndarray.
data = np.array(range(5), dtype = int)
data
# array([0, 1, 2, 3, 4])
np.asarray: 把其他类型的数据转换成为 ndarray, 如果是 ndarray 输入则默认不进行 copy, 而如果是其他类型数据则创建新的 ndarray.
data2 = np.asarray(data)
data2 is data
# True
np.arange: 类似于 range 函数, 创建一个序列.
np.arange(1, 16, 2)
# array([ 1, 3, 5, 7, 9, 11, 13, 15])
np.ones,np.ones_like: 创建一个数组, 其中的元素全为 1.np.ones根据参数设定的纬度创建一个元素为 1 的数组, 而np.ones_like则根据一个已有的数组创建和其有相同纬度的元素全为 1 的数组.np.zeros,np.zeros_like: 创建元素全为 0 的数组, 类似np.ones.np.empty,np.empty_like: 创建空数组, 类似np.ones. 其中每个元素都没有进行初始化, 并不能保证都是 0.
np.ones((2, 3))
# array([[ 1., 1., 1.],
# [ 1., 1., 1.]])
np.zeros((2, 3))
# array([[ 0., 0., 0.],
# [ 0., 0., 0.]])
np.empty((2,3))
# array([[ 0., 0., 0.],
# [ 0., 0., 0.]])
np.ones_like(data)
# array([1, 1, 1, 1, 1])
np.zeros_like(data)
# array([0, 0, 0, 0, 0])
np.empty_like(data)
# array([0, 0, 0, 0, 0])
np.eye: 创建一个对角线为 1 其他为 0 的矩阵.np.identity: 创建一个主对角线为 1 其他为 0 的方阵.
np.eye(2, 2)
# array([[ 1., 0.],
# [ 0., 1.]])
np.identity(3)
# array([[ 1., 0., 0.],
# [ 0., 1., 0.],
# [ 0., 0., 1.]])
ndarray 方法
一个 ndarray 有如下常用的属性.
虽然一个矩阵可能是多维的, 但由于内存的物理特性, 其存储在内存上是线性的. 把二维的矩阵存储成一维需要确定的是一行一行地存 (行优先) 还是一列一列地存 (列优先). 和 R 默认把矩阵按照列优先存储不同, NumPy 的 ndarray 默认把数据按照行优先存储, 这样在考虑 ndarray 地算法的时候也尽量按照行优先.
np.size: ndarray 的属性, ndarray 的元素的数量.np.dtype: ndarray 的属性, ndarray 的元素的类型, 和 C/C++ 中的类型有对应关系.np.sctypes为一个存有 numpy 支持的 dtype 的 dict. 整型 (int) 有 int8 (代表其长度为 8 个字, 即 1 个字节, 后面类似), int16, int32, int64. 无符号整型 (unit) 有 uint8, uit16, uint32, uint64. 浮点型 (float) 有 float16, float32, float64, float128. 复数型 (complex) 有 complex64, complex 128, complex256. 其他还有布尔型 (bool), 字符串型 (object, str) 等.np.itemsize: ndarray 的属性, 元素的字节数, 例如一个 dtype 为 float64 的 ndarray 的元素的大小为 8.np.ndim: ndarray 的属性, ndarray 的维度数.np.shape: ndarray 的属性, 为包含 ndarray 每个维度的大小的 tuple.
nd = np.random.randint(10, size = (3, 4))
# array([[6, 2, 4, 5],
# [5, 3, 6, 9],
# [5, 1, 3, 5]])
nd.size
# 12
nd.dtype
# dtype('int64')
nd.itemsize
# 8
nd.ndim
# 2
nd.shape
# (3, 4)
NumPy 提供了常用的对 ndarray 进行变换的方法.
np.reshape: 返回一个按照给定的维度改变的 ndarray.np.resize: 在原位修改 ndarray 的维度.np.ravel: 把 ndarray 拉成线性, 即一个维度的长度为其元素数量, 其他维度为 1.np.squeeze: 返回一个把长度为 1 的维度去掉的 ndarray.
nd.reshape((2, 6))
# array([[6, 2, 4, 5, 5, 3],
# [6, 9, 5, 1, 3, 5]])
nd
# array([[6, 2, 4, 5],
# [5, 3, 6, 9],
# [5, 1, 3, 5]])
nd.ravel()
# array([6, 2, 4, 5, 5, 3, 6, 9, 5, 1, 3, 5])
nd.ravel().reshape((12, 1))
# array([[6],
# [2],
# [4],
# [5],
# [5],
# [3],
# [6],
# [9],
# [5],
# [1],
# [3],
# [5]])
nd.ravel().reshape((12, 1)).sequeeze()
# array([6, 2, 4, 5, 5, 3, 6, 9, 5, 1, 3, 5])
nd.resize((2, 6))
nd
# array([[6, 2, 4, 5, 5, 3],
# [6, 9, 5, 1, 3, 5]])
np.nonzero: 返回元素中非零的索引, 如果是多维的, 则每个维度都会有一个包含该维度的序号的 ndarray.
nd.nonzero()
# (array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]),
# array([0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5]))
np.repeat: 复制 ndarray 的每个元素的值, 返回一个延长的 ndarray, 需要传入复制的次数作为参数. 当 ndarray 不是一维的时候, 返回的 ndarray 也会是一维的.
nd.repeat(2)
# array([6, 6, 2, 2, 4, 4, 5, 5, 5, 5, 3, 3,
# 6, 6, 9, 9, 5, 5, 1, 1, 3, 3, 5, 5])
np.compress: 按照给定的 bool list 来选取 ndarray 中的值, 返回一个新的 ndarray.np.itemset: 按照元素的序号设定元素的值.np.put: 按照元素的索引设定元素的值.
nd.compress([True, True, False, False, True], axis = 1)
# array([[6, 2, 5],
# [6, 9, 3]])
ndarray 也有排序的方法可以使用.
np.partition: 返回一个 ndarray 的 copy, 其中 kth 参数指定的原 ndarray 中的值在返回的 ndarray 中处于排序后的对应的位置, 比其小的元素均在前面, 和其相同或比其大的在后面.np.argpartition: 类似于np.partition函数, 返回值为对应的编号而非值.np.argsort: 返回元素排序所对应的序号.np.sort: 在原位排序.
逻辑计算
如果想要对布尔数组进行一个对一个地和与或操作, Python 的 and 和 or 操作符是不能用的, 而应该使用 numpy 提供的函数: np.logical_and, np.logical_or 和 np.logical_xor 接受两个等长的布尔数组, 分别进行元素一一对应的和, 或, 异或的逻辑运算; np.logical_not 则是对布尔数组进行取非运算.
bool1 = np.random.choice([True, False], 5)
bool1
# array([ True, True, False, True, True], dtype=bool)
bool2 = np.random.choice([True, False], 5)
bool2
# array([ True, False, False, True, True], dtype=bool)
np.logical_and(bool1, bool2)
# array([ True, False, False, True, True], dtype=bool)
np.logical_or(bool1, bool2)
# array([ True, True, False, True, True], dtype=bool)
np.logical_xor(bool1, bool2)
# array([False, True, False, False, False], dtype=bool)
np.logical_not(bool1)
# array([False, False, True, False, False], dtype=bool)
np.all: 如果所有的值都是真或者非零则返回 True, 否则返回 False.np.any: ndarray 中有任何真值或者非零值则返回 True.
mybool = np.random.choice([True, False], 10)
# array([False, True, True, False, True, False, True, False, True, False], dtype=bool)
mybool.all()
# False
mybool.any()
# True
数值计算
NumPy 中有许多和数值计算相关的函数, 这些函数与 math module 中的不同, 是向量化的, 能够高效地对 ndarray 类型的数组中的每一个元素进行运算. 这些函数也被称为通用函数 (ufunc).
下面是一些单目运算函数.
np.max: 返回 ndarray 中的最大值.np.argmax: 返回 ndarray 中最大的值的序号.np.min: 返回 ndarray 中的最小值.np.argmin: 返回 ndarray 中最小的值的序号.np.absolute: 计算绝对值.np.absolute(a)或者np.abs(a), 对于非复数的数组,np.fabs速度更快.np.exp: 计算 e 的指数,e ** x, e 约等于 2.718281828,还称为欧拉数。 指数函数介绍
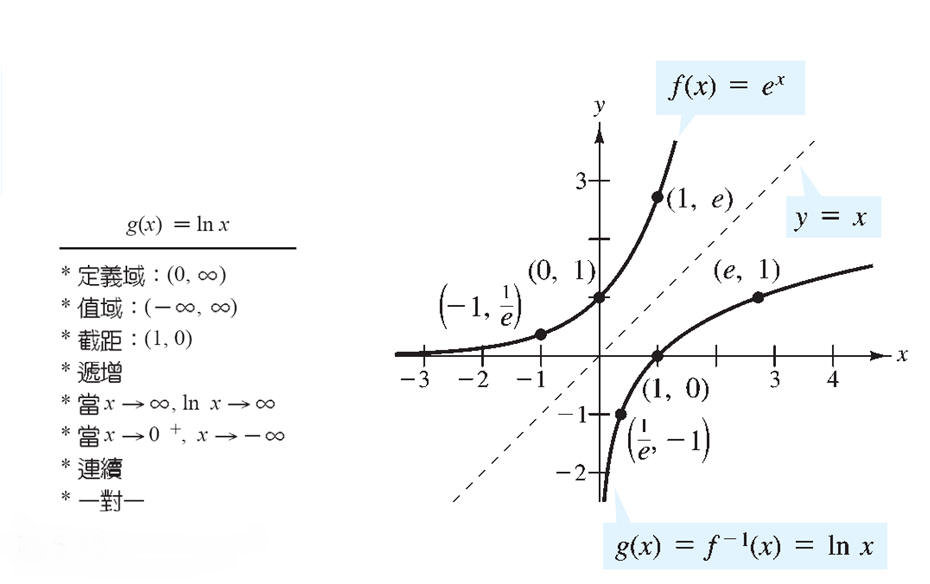
动态图
np.sqrt: 计算平方根,x ** 0.5.np.square: 计算平方,x ** 2.np.log,np.log10,np.log2,np.log1p: 分别为以 e, 10, 2 为底取 log, 和log(1 + x). 对数函数
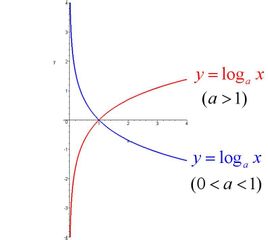
动态图
np.sign: 取数值的正负号.np.ceil: 计算比每一个元素大或相等的最小的整数.np.floor: 计算比每一个元素小或相等的最大的整数.np.rint: 近似到最近的整数.np.clip: 返回一个 ndarray, 其元素的值限制在给定的最大最小值之间. 如果原 ndarray 的值在给定的范围之外, 则替换成最大或最小值.np.modf: 返回一个 tuple, 包含两个数组, 一个是小数部分, 一个是整数部分.np.cos,np.cosh,np.sin,np.sinh,np.tan,np.tanh,np.arccos,np.arccosh,np.arcsin,np.arcsinh,np.arctan,np.arctanh: 三角函数和反三角函数.
nd = np.random.randn(10)
# array([-1.38153059, -0.66621482, -0.58001284, -0.81628342, 0.0656215 ,
# -0.01538155, -0.77812592, 0.94664076, 0.85143997, -0.68542156])
np.absolute(nd)
# array([ 1.38153059, 0.66621482, 0.58001284, 0.81628342, 0.0656215 ,
# 0.01538155, 0.77812592, 0.94664076, 0.85143997, 0.68542156])还有一些双目运算函数.
np.add,+: 两个数组元素一一对应相加.np.substract,-: 两个数组元素一一对应相减.np.multiply,*: 两个数组元素一一对应相乘.np.devide,/: 两个数组元素一一对应相除.np.floor_divide,np.remainder,np.mod,np.fmod:np.floor_divide返回一一对应相除的最大整数商, 即 floor, 而np.remainder或np.mod则返回余数. 同时,np.fmod返回的余数则根据被除数和除数的符号可能是负数.np.power: 计算幂, 以第一个数组中元素为底, 以第二个数组中元素为指数.np.maximum,np.fmax: 一一比较两个数组中元素大小, 返回相应位置最大的.np.fmax会忽略 np.NAN, 而np.maximum则返回 np.NAN.np.minimum,np.fmin: 一一比较两个数组中元素大小, 返回相应位置最小的.np.fmin会忽略 np.NAN, 而np.minimum则返回 np.NAN.np.copysign: 把第二个数组中的元素的符号复制给第一个数组中的相应元素.
nd1 = np.random.randint(0, 20, 10)
# array([ 8, 15, 15, 0, 10, 13, 19, 5, 19, 10])
nd2 = np.random.randint(0, 20, 10)
# array([ 8, 18, 1, 15, 16, 2, 5, 12, 15, 9])
np.add(nd1, nd2)
# array([16, 33, 16, 15, 26, 15, 24, 17, 34, 19])
np.maximum(nd1, nd2)
# array([ 8, 18, 15, 15, 16, 13, 19, 12, 19, 10])
集合运算
我们有时候关心的是数据中有多少个单一的值, 或者两个数据中相同的值有哪些, 这个时候可以通过集合运算函数来获取所关心的值. NumPy 中提供了高效的集合运算的函数.
np.unique: 返回一个包含有输入的数组元素中所有不重复的值的排序的数组.np.intersect1d: 计算两个数组的一维交集, 返回排序后的交集数组.np.union1d: 返回两个数组的排序后的并集.np.in1d: 返回一个布尔值数组, 判断一个数组元素是否在另一个数组中.np.setdiff1d: 返回一个数组, 其中包含在第一个输入数组而不在第二个输入数组的元素.np.setxor1d返回不同时在两个输入数组的元素的数组.
nd1 = np.random.choice(['A', 'B', 'C', 'D'], 10)
# array(['A', 'D', 'B', 'C', 'B', 'B', 'D', 'A', 'C', 'B'],
# dtype='<U1')
nd2 = np.random.choice(['D', 'E', 'F'], 10)
# array(['F', 'E', 'E', 'D', 'D', 'D', 'D', 'E', 'E', 'F'],
# dtype='<U1')
np.unique(nd1)
# array(['A', 'B', 'C', 'D'],
# dtype='<U1')
np.intersect1d(nd1, nd2)
# array(['D'],
# dtype='<U1')
np.setdiff1d(nd1, nd2)
# array(['A', 'B', 'C'],
# dtype='<U1')
np.setdiff1d(nd2, nd1)
# array(['E', 'F'],
# dtype='<U1')
np.setxor1d(nd1, nd2)
# array(['A', 'B', 'C', 'E', 'F'],
# dtype='<U1')
统计量
NumPy 中有简单的统计计算的方法或者函数, 有着很好的效率. 统计量计算的函数和方法可以通过更高层调用, 如 np.sum(arr), 或者使用数组的方法, 如 arr.sum.
np.sum: 计算数组的和, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的和.np.mean: 计算数组的均值, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的均值.np.std: 计算数组的标准差, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的标准差.np.var: 计算数组的标准差, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的标准差.np.min,np.max: 计算数组的最小值或最大值, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的最小值或最大值.np.argmin,np.argmax: 计算数组的最小值或最大值的 index, 可以设置参数 axis 为 0 或者 1 单独计算每行或每列的最小值或最大值 index.np.cumsum: 累加.np.cumprod: 累乘.
nd = np.random.randn(100) # 随机产生 100 个随机数.
nd.sum()
# -13.300540142526414
np.mean(nd)
# -0.13300540142526412
nd.std()
# 1.0860199448302112
nd.var()
# 1.1794393205690152
nd.min(), np.max(nd)
# (-3.2346987329963834, 2.3950110710189687)
nd.argmin(), np.argmax(nd)
# (24, 31)
nd.cumsum()
# array([ -0.55436107, -0.86184171, -2.47687452, -5.0649675 ,
# ... ... ... ...
# -13.96853959, -13.59106636, -14.16799745, -13.30054014])
线性代数
NumPy 中提供了一些线性代数运算的函数, 在 linalg 中有更全的线性代数的计算函数. 更多的线性代数相关函数包含在 scipy.linalg 包中.
np.dot: 矩阵乘法.np.transpose: 返回转置, 也可以使用一个 ndarray 的 nd.T 属性.np.diagonal: 返回矩阵的对角元素.np.trace: 返回矩阵的迹.np.linalg.eig: 返回方阵的特征值和特征向量.np.linalg.inv: 返回方阵的逆矩阵.np.linalg.pinv: 返回方阵的 Moore-Penrose 伪逆矩阵.np.linalg.solve: 解线性方程组, 输入值是系数矩阵和线性方程组的常数项.np.linalg.det: 求方阵的行列式.np.linalg.matrix_rank: 求一个矩阵的秩.np.linalg.svd: 奇异值分解.
nd1 = np.arange(9, 1).reshape(2,4)
# array([[1, 2, 3, 4],
# [5, 6, 7, 8]])
nd2 = np.arange(1, 9).reshape(4,2)
# array([[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]])
nd1.dot(nd2)
# array([[ 50, 60],
# [114, 140]])
nd1.dot(nd2).trace()
# 190
随机数和随机排列
不论是在构建模拟数据还是实际数据分析中, 我们都需要频繁地生成随机数或者随机抽样. NumPy 提供了众多方便使用的生成各种分布的伪随机数的函数.
np.random.seed: 设置随机数的种子.np.random.permutation: 返回一个随机打乱的数组.np.random.shuffle: 在原位随机打乱一个数组.np.random.rand: 从均匀分布中抽取样本, 其接受参数指定返回的数组的维度.np.random.rand(3, 2)返回一个 3 乘 2 的矩阵.np.random.randint: 从指定的最低和最高的范围内抽取指定数量的整数. 如np.random.randint(1, 100, 20)从 1 到 100 中随机抽取 20 个整数.np.random.randn: 从均值为 0, 方差为 1 的正态分布中抽取随机数, 返回指定的数量或者维度的矩阵.np.random.binomial: 从给定数量 n 和成功概率 p 的二项分布中抽取一定数量的样本.np.random.binomial(n, p, size), 其中 n 是试验的次数, p 是成功的概率, size 是抽样的数量或者维度.np.random.normal: 从正态分布中抽取一定数量的样本.np.random.beta: 从 beta 分布中抽取一定数量的样本.np.random.chisquare: 从 chisquare 分布中抽取一定数量的样本.np.random.gamma: 从 gamma 分布中抽取一定数量的样本.np.random.uniform: 从均匀分布中抽取一定数量的样本.
np.random.permutation(5)
# array([2, 0, 1, 3, 4])
np.random.permutation(np.arange(6).reshape((2,3)))
# array([[3, 4, 5],
# [0, 1, 2]])