本专栏按照 https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html 顺序进行总结 。
文章目录
- 原理解析
-
- 回顾策略梯度
- DPG算法
- 算法实现
-
- 总体流程
- 代码实现
DPG\color{red}DPGDPG :[ paper | code ]
原理解析
Stochastic Policy Gradient (SPG) 是通过参数化的概率分布 πθ(a∣s)=P[a∣s;θ]{\pi _\theta }(a|s) = P[a|s;\theta ]πθ?(a∣s)=P[a∣s;θ] 随机地选择动作,即 πθ(a∣s){\pi _\theta }(a|s)πθ?(a∣s) 是一个动作的概率分布。
Deterministic Policy Gradient (DPG) 与SPG 不同之处是,这个方法会确定地选择一个动作: a=μθ(s)a = {\mu _\theta }(s)a=μθ?(s) 。
简而言之:
- 随机策略,在同一个状态处,采用的动作是基于一个概率分布的,即是不确定的。
- 确定性策略,虽然在同一个状态处,采用的动作概率不同,只取最大概率的动作。
看起来很奇怪吧!当仅仅只输出一个动作的时候,怎么计算动作概率的梯度呢?
接下来我们一步一步地看看~
回顾策略梯度
-
策略梯度:
首先解决一个强化学习问题,我们想到的就是累计折扣奖励的定义,即状态满足 ρπ\rho^{\pi}ρπ 分布上的累计奖励,如下:
J(πθ)=∫Sρπ(s)∫Aπθ(s,a)r(s,a)dads=Es?ρπ,a?πθ[r(s,a)]\begin{aligned}J(\pi_\theta)=&\int_S \rho^\pi(s)\int_A \pi_\theta (s,a)r(s,a)dads\\=&\textcolor{red}{E_{s\sim \rho^\pi ,a\sim \pi_\theta}[r(s,a)]}\end{aligned}J(πθ?)==?∫S?ρπ(s)∫A?πθ?(s,a)r(s,a)dadsEs?ρπ,a?πθ??[r(s,a)]?
ρπ(s′)=∫S∑t=1∞γt?1p1(s)p(s→s′,t,π)ds\rho^\pi(s') = \int_S \sum_{t=1}^ {\infty} \gamma^{t-1}\textcolor{blue}{p_1(s) }p(s\to s',t,\pi)dsρπ(s′)=∫S?∑t=1∞?γt?1p1?(s)p(s→s′,t,π)ds- p1(s)\textcolor{blue}{p_1(s)}p1?(s) 表示初始状态为 sss 的概率
- p(s→s′,t,π)p(s\to s',t,\pi)p(s→s′,t,π) 表示在策略 πππ 下状态 sss 经过t时间步到达 s′s′s′
-
策略梯度定理:
那么什么是策略梯度呢?策略梯度就是沿着使目标函数变大的方向调整策略的参数,它被定义为:
?θJ(πθ)=∫Sρπ(s)∫A?θπθ(s,a)Qπ(s,a)dads=Es?ρπ,a?πθ[?θlogπθ(s,a)Qπ(s,a)]\begin{aligned} \nabla_\theta J(\pi_\theta)=&\int_S \rho^\pi(s)\int_A \nabla_\theta \pi_\theta (s,a)Q^\pi(s,a)dads\\=&E_{s\sim \rho^\pi ,a\sim \pi_\theta}[\nabla_\theta log \pi_\theta(s,a)Q^\pi(s,a)]\end{aligned}?θ?J(πθ?)==?∫S?ρπ(s)∫A??θ?πθ?(s,a)Qπ(s,a)dadsEs?ρπ,a?πθ??[?θ?logπθ?(s,a)Qπ(s,a)]? -
stochastic Actor-Critic algorithm
critic 通过TD的方式估计 action-value function:Qw(s,a)=Qπ(s,a)Q^w(s,a)=Q^\pi(s,a)Qw(s,a)=Qπ(s,a)
所以,策略梯度定理演化为:?θJ(πθ)=∫Sρπ(s)∫A?θπθ(s,a)Qw(s,a)dads=Es?ρπ,a?πθ[?θlogπθ(s,a)Qw(s,a)]\begin{aligned} \nabla_\theta J(\pi_\theta)=&\int_S \rho^\pi(s)\int_A \nabla_\theta \pi_\theta (s,a)Q^w(s,a)dads\\=&E_{s\sim \rho^\pi ,a\sim \pi_\theta}[\nabla_\theta log \pi_\theta(s,a)Q^w(s,a)]\end{aligned}?θ?J(πθ?)==?∫S?ρπ(s)∫A??θ?πθ?(s,a)Qw(s,a)dadsEs?ρπ,a?πθ??[?θ?logπθ?(s,a)Qw(s,a)]?
公式非常直白的告诉我们,J()J()J() 函数主要与策略梯度和值函数的期望有关,尽管状态空间分布 ρπ\rho^{\pi}ρπ 的分布依赖于策略参数,但是策略梯度并不依赖于状态分布上的梯度。另外, 在DQN中我们使用了 评价网络 和 target网络,采用了experimence replay的方式打乱了数据之间的相关性而使得满足独立同分布条件,利用softupdating方式更新target网络,但总结一句话,它的策略网路和值函数网络使用的是同一个网络。在DPG的公式表明,J()J()J() 和策略梯度与值函数有关,因此为了解决策略和值函数之间的问题,采用了一种新的解决思路将两个网络分开,即:Actor-critic异步框架。(Actor就是策略网络,来做动作选择(空间探索)。Critic就是值函数,对策略函数进行评估),具体的流程如图:

简单描述一下图:其中的TD-error就是Critic告诉Actor的偏差。
具体的更新过程:
δt=Rt+γQw(st+1,at+1)?Qw(st,at); TD error in SARSAwt+1=wt+αwδt?wQw(st,at)θt+1=θt+αθ?aQw(st,at)?θμθ(s)∣a=μθ(s); 确定性策略梯度定理\begin{aligned} \quad \delta_t &= R_t + \gamma Q_w(s_{t+1}, a_{t+1}) - Q_w(s_t, a_t) & \scriptstyle{\text{; TD error in SARSA}}\\ w_{t+1} &= w_t + \alpha_w \delta_t \nabla_w Q_w(s_t, a_t) & \\ \qquad\qquad \theta_{t+1} &= \theta_t + \alpha_\theta \color{red}{\nabla_a Q_w(s_t, a_t) \nabla_\theta \mu_\theta(s) \rvert_{a=\mu_\theta(s)}} & \scriptstyle{\text{; 确定性策略梯度定理}} \end{aligned}δt?wt+1?θt+1??=Rt?+γQw?(st+1?,at+1?)?Qw?(st?,at?)=wt?+αw?δt??w?Qw?(st?,at?)=θt?+αθ??a?Qw?(st?,at?)?θ?μθ?(s)∣a=μθ?(s)??; TD error in SARSA; 确定性策略梯度定理?
但是,由于策略的确定性,除非环境中有足够的噪声,否则很难保证足够的探索。我们可以在策略中添加噪声(讽刺的是这会使它变得不确定)或者通过遵循不同的随机行为策略来收集样本来 离线策略地学习它。下面来简单提一下。
- Off-policy AC
比如说,在离线策略方法中,训练轨迹是由随机策略 β(a∣s)\beta(a|s)β(a∣s) 产生的,因此,状态分布遵循相应的折扣状态密度 ρβ\rho^\betaρβ。
行为策略:β(a∣s)≠πθ(a∣s)\beta(a|s)\neq \pi_\theta(a|s)β(a∣s)??=πθ?(a∣s)
Jβ(πθ)=∫Sρβ(s)Vπ(s)ds=∫S∫Aρβπθ(s,a)Qπ(s,a)dads\qquad\begin{aligned}J_\beta(\pi_\theta)=&\int_S \rho^\beta(s)V^\pi(s)ds\\ =&\int_S \int_A \rho^\beta \pi_\theta (s,a)Q^\pi(s,a)dads\end{aligned}Jβ?(πθ?)==?∫S?ρβ(s)Vπ(s)ds∫S?∫A?ρβπθ?(s,a)Qπ(s,a)dads?
?θJβ(πθ)≈∫S∫Aρβ(s)?θπθ(s,a)Qπ(s,a)dads=Es?ρβ,a?β[πθ(a∣s)βθ(a∣s)?θlogπθ(s,a)Qπ(s,a)]\quad\begin{aligned}\nabla_\theta J_\beta(\pi_\theta)\approx&\int_S \int_A \rho^\beta(s)\nabla_\theta \pi_\theta (s,a)Q^\pi(s,a)dads\\=&E_{s\sim \rho^\beta ,a\sim \beta}[\frac{\pi_\theta(a|s)}{\beta_\theta(a|s)} \nabla_\theta log \pi_\theta(s,a)Q^\pi(s,a)]\end{aligned}?θ?Jβ?(πθ?)≈=?∫S?∫A?ρβ(s)?θ?πθ?(s,a)Qπ(s,a)dadsEs?ρβ,a?β?[βθ?(a∣s)πθ?(a∣s)??θ?logπθ?(s,a)Qπ(s,a)]?
注意,由于策略是确定性的,所以我们只需要 Qμ(s,μθ(s))Q^\mu(s, \mu_\theta(s))Qμ(s,μθ?(s)) 作为给定状态 sss 的估计奖励,而不是 ∑aπ(a∣s)Qπ(s,a)\sum_a \pi(a \vert s) Q^\pi(s, a)∑a?π(a∣s)Qπ(s,a)。
在随机策略的 off-policy 方法中,我们经常使用重要性采样 来纠正 行为和目标政策 之间的不匹配,正如我们上面所描述的。然而,由于确定性策略梯度消除了对动作的积分,我们可以避免重要性抽样。
DPG算法
现在考虑如何将策略梯度框架扩展到确定性政策。【确定性策略梯度定理实际上是随机策略梯度定理的一个极限情况,具体证明见论文】
那么极限情况是啥呢?就是当概率策略的方差趋近于0的时候,就是 确定性策略,即

上面这个式子的推导过程可以理解为 :
DPG算法本身采用的是PG方法,因而直接对轨迹的价值回报进行求导:?θvμθ(s)=?θ[Qμ(s,μθ(s))]\nabla_\theta v_{\mu_{\theta}} (s)=\nabla_\theta[Q^\mu(s,\mu_\theta(s))]?θ?vμθ??(s)=?θ?[Qμ(s,μθ?(s))]
链式法则,由于 μθ(s)μ_θ(s)μθ?(s) 与确定性策略价值函数 QμQ^μQμ 有关,因而 :?θvμ(s)=?μθ(s)[Qμ(s,μθ(s))]?θμθ(s)\nabla_\theta v_\mu(s) = \nabla_{\mu_\theta(s)}[Q^\mu(s, \mu_\theta(s))]\nabla_\theta\mu_\theta(s)?θ?vμ?(s)=?μθ?(s)?[Qμ(s,μθ?(s))]?θ?μθ?(s)
- on-policy的确定性策略梯度算法:
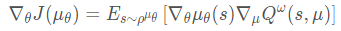
- off-policy的确定性策略梯度算法(Replay buffer中的数据是通过 βββ 采样得到的),异策略确定性策略梯度:
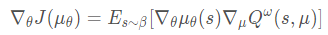
上两式的区别就是使用了不同的数据采样分布。可以看到off-policy缺少了重要性采样,这是由于确定性策略的动作是固定值,不是一个分布。(β\betaβ 是采样策略, μ\muμ 是评估策略)
该算法采用AC框架:
-
[Actor] 衡量一个策略网络的表现(策略网络目标函数),最大化策略目标: (根据上面推导的DPG)
Jβ(θ)=∫Sρβ(s)Qω(s,μ(s))ds=Es?ρβ[Qω(s,μ(s))]\begin{aligned} J_\beta (\theta)&=\int_S ρ^\beta(s)Q^\omega(s, \mu(s))ds\\ &=\mathbb{E}_{s\simρ^\beta}[Q^\omega(s, \mu(s))] \end{aligned}Jβ?(θ)?=∫S?ρβ(s)Qω(s,μ(s))ds=Es?ρβ?[Qω(s,μ(s))]?- sss 是环境的状态,这些状态 是基于agent 的 行动策略产生的,它们的分布函数 为 ρβρ^βρβ ;
- Qω(s,μ(s))Q^ω(s,μ(s))Qω(s,μ(s)) 是在每个状态下,如果都按照 μμμ 策略选择action时,能够产生的 QQQ 值。 也即,Jβ(μ)J_β(μ)Jβ?(μ) 是在 sss 根据 ρβρ^βρβ 分布时,Qω(s,μ(s))Q^ω(s,μ(s))Qω(s,μ(s)) 的期望值。
-
[Critic] 最小化值网络目标:
\qquadQ^ω(st,at)=E[r(st,at)+γQω(st+1,at+1)]\hat{Q}^\omega(s_t, a_t)=\mathbb{E}[r(s_t,a_t)+\gamma Q^\omega(s_{t+1},a_{t+1})]Q^?ω(st?,at?)=E[r(st?,at?)+γQω(st+1?,at+1?)]
\qquadJβ(ω)=Es?ρβ[12(rt+γQω(st+1,at+1)?Qω(st,at))2]J_\beta(\omega)=\mathbb{E}_{s\simρ^\beta}[\frac{1}{2}(r_t+\gamma Q^\omega(s_{t+1},a_{t+1})-Q^\omega(s_t,a_t))^2]Jβ?(ω)=Es?ρβ?[21?(rt?+γQω(st+1?,at+1?)?Qω(st?,at?))2]
最终DPG的目标函数为:( ωωω 是值网络 ,θθθ 是策略网络 )
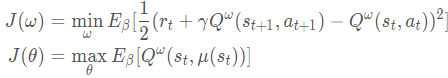
参数更新为:
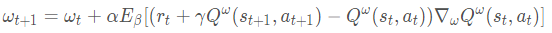
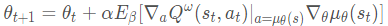
确定性策略梯度的优点在于 需要采样的数据少,算法效率高。
算法实现
总体流程
暂无
代码实现
暂无