前言
先简单聊聊分布式算法的重要性问题
在分布式微服务系统的项目中,最重要的是 如何选择或者设计合适的算法,来解决一致性问题以及可用性等相关问题
而分布式系统的最关键之处,在于根据场景的需要选择合适的算法,在一致性和可用性之间权衡(注:因为分区容错性是必须满足的),而权衡妥协的关键在于是否了解各个算法的特点,对于其他技术也适用。找到影响选择的因素,了解各个技术的特点,根据场景需要权衡选择。
下面是一些分布式算法的比较:
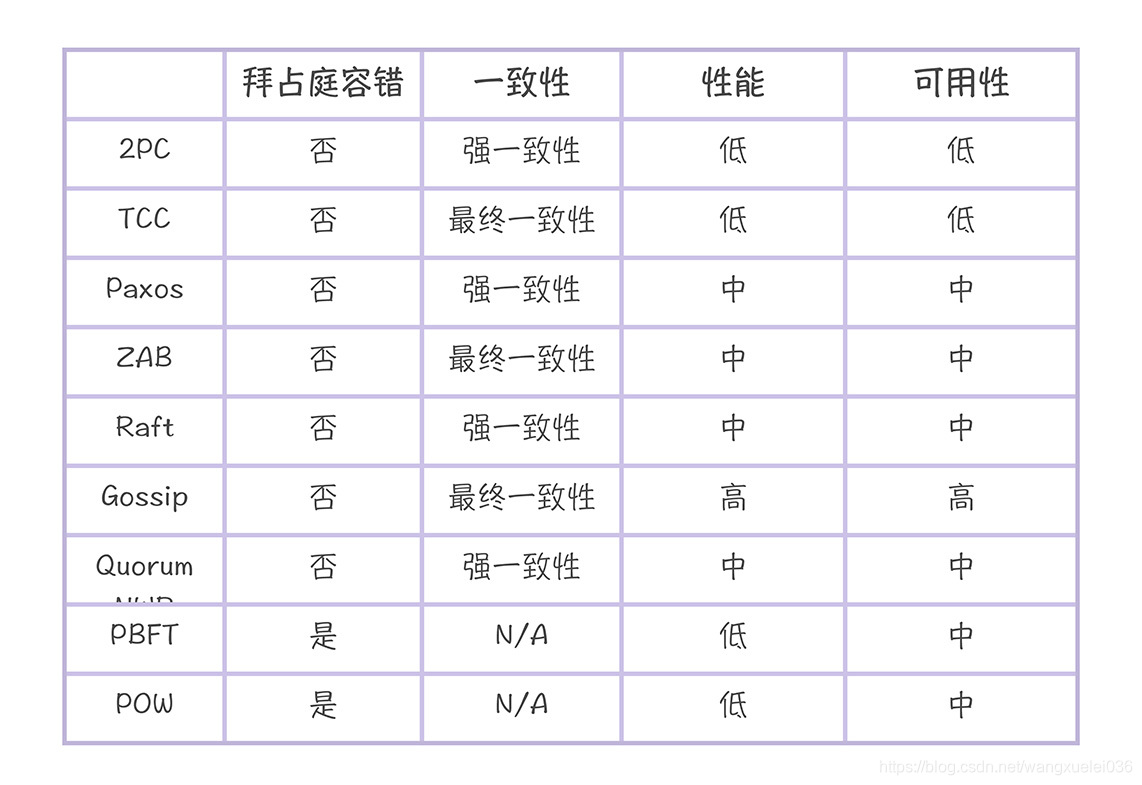
当然本章不是介绍所有的分布式算法,我也没法仅仅使用一篇文章就把上面表格中覆盖的分布式算法知识清晰的讲述。
所有我们重点讲解的是现在分布式算法或者说现在分布式数据一致性首选算法:Raft 算法
raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。在这里强调了是在工程上,因为在学术理论界,最耀眼的还是大名鼎鼎的Paxos。但Paxos是:少数真正理解的人觉得简单,尚未理解的人觉得很难,大多数人都是一知半解。本人也花了很多时间、看了很多材料也没有真正理解。直到看到raft的论文,两位研究者也提到,他们也花了很长的时间来理解Paxos,他们也觉得很难理解,于是研究出了raft算法。
?? raft是一个共识算法(consensus algorithm),所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。这些年最为火热的加密货币(比特币、区块链)就需要共识算法,而在分布式系统中,共识算法更多用于提高系统的容错性。raft协议就是一种leader-based的共识算法,与之相应的是leaderless的共识算法。
??本文基于论文In Search of an Understandable Consensus Algorithm对raft协议进行分析,当然,还是建议读者直接看论文。
简单提一下,因为Raft协议也是基于CAP理论,但是现在大部分人对CAP 存在一个误解,认为无论在什么情况下,A和C 只能选择一个,因为P必选,其实,在不存在网络分区的情况下或者网络故障等问题的时候,也就是分布式系统正常,P 不需要的时候,C和P是能同时保证的。只有发生故障分区的时候,在需要的P的时候,才会在C和P 中抉择。
Raft协议
首先来一句话简单说下Raft 是什么:从本质上,Raft协议就是一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致性
现在我们带着一些问题,边思考边分析Raft协议
(1)如何选举leader?
(2)节点间是如何通讯的呢?
(3)数据一致性是如何保证的?
(4)数据不一种的时候如何进行修复?
leader选举
领导者周期性地向所有跟随者发送心跳消息(即不包含日志项的日志复制 RPC 消息),通知大家我是领导者,阻止跟随者发起新的选举。
如果在指定时间内,跟随者没有接收到来自领导者的消息,那么它就认为当前没有领导者,推举自己为候选人,发起领导者选举。
在一次选举中,赢得大多数选票的候选人,将晋升为领导者。在一个任期内,领导者一直都会是领导者,直到它自身出现问题(比如宕机),或者因为网络延迟,其他节点发起一轮新的选举。
在一次选举中,每一个服务器节点最多会对一个任期编号投出一张选票,并且按照“先来先服务”的原则进行投票。比如节点 C 的任期编号为 3,先收到了 1 个包含任期编号为 4 的投票请求(来自节点 A),然后又收到了 1 个包含任期编号为 4 的投票请求(来自节点 B)。
那么节点 C 将会把唯一一张选票投给节点 A,当再收到节点 B 的投票请求 RPC 消息时,对于编号为 4 的任期,已没有选票可投了。
?思考:万一节点都同时选举自己,那不是一直都没法重新选举leader成功?
Raft 算法实现了随机超时时间的特性。也就是说,每个节点等待领导者节点心跳信息的超时时间间隔是随机的。集群中没有领导者,而节点 A 的等待超时时间最小(150ms),它会最先因为没有等到领导者的心跳信息,发生超时。这个时候,节点 A 就增加自己的任期编号,并推举自己为候选人,先给自己投上一张选票,然后向其他节点发送请求投票 RPC 消息,请它们选举自己为领导者,如果选举失败,各个节点就会随机进入一个睡眠时间,因为各个节点随机,一般最多几次一定能选举成功。
在 Raft 算法中,随机超时时间是有 2 种含义的,这里是很多同学容易理解出错的地方,需要你注意一下:
(1) 跟随者等待领导者心跳信息超时的时间间隔,是随机的;
(2)如果候选人在一个随机时间间隔内,没有赢得过半票数,那么选举无效了,然后候选人发起新一轮的选举,也就是说,等待选举超时的时间间隔,是随机的。
?思考:raft协议是以leader为准的协议,那新leader节点数据是完整的?
在Raft 中,副本数据是以日志的形式存在的,其中日志项中的指令表示用户指定的数据。兰伯特的 Multi-Paxos 不要求日志是连续的,但在 Raft 中日志必须是连续的。
因为在 Raft 中,日志不仅是数据的载体,同时,日志的完整性还影响领导者选举的结果。也就是说,日志完整性最高的节点才能当选领导者
在选举中,会选择日志完整性高的跟随者(也就是最后一条日志项对应的任期编号值更大,索引号更大),拒绝投票给日志完整性低的候选人。比如节点 B 的任期编号为 3,节点 C 的任期编号是 4,节点 B 的最后一条日志项对应的任期编号为 3,而节点 C 为 2,那么当节点 C 请求节点 B 投票给自己时,节点 B 将拒绝投票。也就是日志完整度不比半数节点低的节点),才能当选领导者;其次,在 Raft 中,日志必须是连续的,这个很重要。
第二个问题没怎么懂,没多大关系,你只需要知道,选举的时候,类似于kafka里面的high watermark机制,从满足最全副本中选举出一个新leader领导者。
但这里希望你能又想到两个问题,为什么副本数据是以日志的形式存在的?那什么时候日志数据转为真正的数据集?
注 : 方式得当,知识不难学,每个人有每个人的学习方式,如果你还没找到属于自己的独特方式,可以多借鉴别人的,我个人喜欢学一个知识,就提出一些关键的疑问,先自己分析思考,然后查阅相关的文章。
Raft一次请求流程
共识算法的实现一般是基于复制状态机(Replicated state machines),何为复制状态机:
If two identical, deterministic processes begin in the same state and get the same inputs in the same order, they will produce the same output and end in the same state.
简单来说:相同的初识状态 + 相同的输入 = 相同的结束状态。引文中有一个很重要的词deterministic,就是说不同节点要以相同且确定性的函数来处理输入,而不要引入一下不确定的值,比如本地时间等。如何保证所有节点 get the same inputs in the same order,使用replicated log是一个很不错的注意,log具有持久化、保序的特点,是大多数分布式系统的基石。
?因此,可以这么说,在raft中,leader将客户端请求(command)而不是值,封装到一个个日志项(log entry),将这些log entries复制(replicate)到所有follower节点,然后大家按相同顺序应用(apply)log entry中的command,则状态肯定是一致的。
下图形象展示了这种log-based replicated state machine:
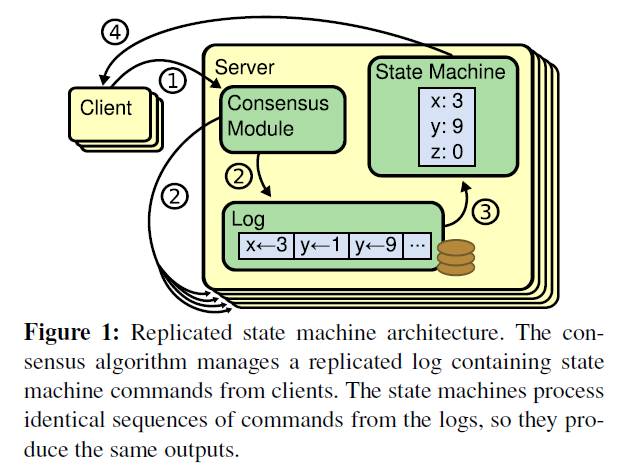
State Machine 可以理解为是命令运行后的值区域或者说是一个值状态等。
流程提交过程:

- 接收到客户端请求后,领导者基于客户端请求中的指令,创建一个新日志项(log entry),并附加到本地日志中。
- 领导者通过日志复制 RPC,将新的日志项(log entry)并行复制到其他的服务器。
- 等待领导者将日志项,成功复制到大多数的服务器上。
- 领导者会将这条日志项应用到它的状态机中(state machine)。
- 领导者将执行的结果返回给客户端。
- 当跟随者接收到心跳信息,或者新的日志复制 RPC 消息后(注:心跳信息和日志复制信息中会携带提交信息),如果跟随者发现领导者已经提交了某条日志项,而它还没应用,那么跟随者就将这条日志项应用到本地的状态机中。
思考?:为什么是日志复制,日志复制能复制数据?日志复制里面存储的数据格式是如何?
Raft协议中,副本数据是以日志的形式存在,日志中存储的是日志项,日志项是一种数据格式,它主要包含用户指定的数据,也就是指令(Command),还包含一些附加信息,比如索引值(Log index)、任期编号(Term)。那你该怎么理解这些信息呢?如下:

指令:一条由客户端请求指定的、状态机需要执行的指令。你可以将指令理解成客户端指定的数据。
索引值:日志项对应的整数索引值。它其实就是用来标识日志项的,是一个连续的、单调递增的整数号码。(进行日志纠错 一致性检测的时候需要使用)
任期编号:创建这条日志项的领导者的任期编号。
理解了日志复制过程,以及日志格式, 那么如果宕机故障等导致日志不一致的情况 该如何是好?Raft 协议又如何处理?
回想一下,我们上文一直提到的日志连续性,是不是想到了什么,遵循约定号的规则,对于违反规则的地方,那么就是问题节点,是不是跟我code时候,约定大于配置类似。找到一个合适的方式来判定不一致的节点,这里利用的就是顺序性。
简单的说 : 每个新的日志项会带有上一个日志项的任期(PreLogTerm)和索引值(PreLogEntry),follewer节点会先检查自己上一个日志项(log entry) 和 这次新到来日志项(log entry )带有的信息是否一致。
大致流程如下:
- 领导者通过日志复制 RPC 消息,发送当前最新日志项到跟随者(为了演示方便,假设当前需要复制的日志项是最新的),这个消息中包含的 PrevLogEntry(上一个日志项的索引值) 值为 7,PrevLogTerm(上一个日志项的任期) 值为 4。
- 如果跟随者在它的日志中,找不到与 PrevLogEntry 值为 7、PrevLogTerm 值为 4 的日志项,也就是说它的日志和领导者的不一致了,那么跟随者就会拒绝接收新的日志项,并返回失败信息给领导者。
- 这时,领导者会递减要复制的日志项的索引值,并发送新的日志项到跟随者,这个消息的 PrevLogEntry 值为 6,PrevLogTerm 值为 3。
- 如果跟随者在它的日志中,找到了 PrevLogEntry 值为 6、PrevLogTerm 值为 3 的日志项,那么日志复制 RPC 返回成功,这样一来,领导者就知道在 PrevLogEntry 值为 6、PrevLogTerm 值为 3 的位置,跟随者的日志项与自己相同。
- 领导者通过日志复制 RPC,复制并更新覆盖该索引值之后的日志项(也就是不一致的日志项),最终实现了集群各节点日志的一致。
网络分区导致多leader 怎么办
答:raft协议中有一个约定,不能提交之前任期内log 记录作为commit点。
原因是如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
简单来说:就是follewer 节点只听从当前任期内leader 的数据变更,所以任期(term) 这个也是一个核心概念,后续如果old leader 连入进来会发现当前任期大于自己任期,自己将会变成follewer节点。
?继续思考下一个问题:raft协议是基于日志追加和不可回滚性来实现(append-only),那么日志文件越来越多咋办?
想想Mysql 作数据恢复的时候一般是怎么弄得?dump(快照) + binlog,也就是 快照 + 日志追加方式 来实现数据恢复
其实Raft协议中也差不多
日志压缩
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft采用对整个系统进快照行来处理,快照之前的日志都可以丢弃。
每个server独立的对自己的系统状态进行快照,并且只能对已经committed log entry(已经应用到了状态机)进行快照,快照有一些元数据,包括last_included_index,即快照覆盖的最后一条commited log entry的 log index,和last_included_term,即这条日志的termid。这两个值在快照之后的第一条log entry的AppendEntriesRPC的一致性检查的时候会被用上,之前讲过。一旦这个server做完了快照,就可以把这条记录的最后一条log index及其之前的所有的log entry都删掉。
snapshot的缺点就是不是增量的,即使内存中某个值没有变,下次做snapshot的时候同样会被转存到磁盘。
当leader需要发给某个follower的log entry被丢弃了(因为leader做了快照),leader会将快照发给落后太多的follower。或者当新加进一台机器时,也会发送快照给它。
发送快照时使用新的RPC,InstalledSnapshot。
做snapshot有一些需要注意的性能点:
- 不要做太频繁,否则消耗磁盘带宽。
- 不要做的太不频繁,否则一旦server重启需要回放大量日志,影响availability。系统推荐当日志达到某个固定的大小做一次snapshot。
- 做一次snapshot可能耗时过长,会影响正常log entry的复制。这个可以通过使用写时复制的技术来避免快照过程影响正常log entry的复制。
小结
上述介绍总结下来大致为以下几点
- Election Safty :每一个任期内只能有一个领导人
- Leader Append-Only:leader只能追加日志条目,不能重写或者删除日志条目
- Log Maching:如果两个日志条目的index和term都相同,则两个如果日志中,两个条目及它们之前的日志条目也完全相同
- Leader Completeness:如果一条日志被commited过,那么大于该日志条目任期的日志都应该包含这个点,也就是说当一个新的leader产生时它一定包含着前一个leader所处理过的commited点。
- State Machine Safety :如果一个server将某个特定index的日志条目交由状态机处理了,那么对于其他server,交由状态及处理的log中相同index的日志条目应该相同
Raft将共识问题分解成两个相对独立的问题,leader election,log replication。流程是先选举出leader,然后leader负责复制、提交log(log中包含command)
??为了在任何异常情况下系统不出错,即满足safety属性,对leader election,log replication两个子问题有诸多约束
leader election约束:
- 同一任期内最多只能投一票,先来先得
- 选举人必须比自己知道的更多(比较term,log index)
log replication约束:
- 一个log被复制到大多数节点,就是committed,保证不会回滚
- log entry 是连续的
- leader一定包含最新的committed log,因此leader只会追加日志,不会删除覆盖日志
- 不同节点,某个位置上日志相同,那么这个位置之前的所有日志一定是相同的
- Raft never commits log entries from previous terms by counting replicas.
??本文是自己学习极客时间 《分布式协议与算法实践 》作的总结,整体评价,课程还行,如果有什么错误之错,请留言告知,感谢。
