LP-3DCNN: Unveiling Local Phase in 3D Convolutional Neural Networks
�����ַ��
https://sites.google.com/view/lp-3dcnn/home(400�����Ҳ���)
�ؼ��ʣ�
Rectified Local Phase Volume (ReLPV) block(У���ֲ���λ���(ReLPV)�飺�ֲ���λģ�顢ReLU�������һ���ѵ������Ȩֵ���)
ReLPV�����3D������
���⣺
(1)��������(2)ģ�ͳߴ��(3)����ϣ�(4)����ѧϰ�����д���һ��������
ԭ����

Layer 1����һ���DZ�����ά�����㣬ֻ��һ����СΪ1��1��1�Ĺ�����������һ������һ����СΪc��d��h��w��feature map��������ת��Ϊһ����СΪ1��d��h��w�ĵ�ͨ��feature map��
��һ��Ϊ��2������3D STFT���������롣��f(x)Ϊ��1���feature map�������СΪ1��d��h��w�����x��һ����������ʾfeature map f(x)�ϵ�λ��
Layer 2����2��ͨ����ʽ(1)����f(x)�ھֲ�n��n��n����NxNx��ÿ��λ�ô�����ά��ʱ����Ҷ�任(STFT)����ȡf(x)�ľֲ���λ�ס�
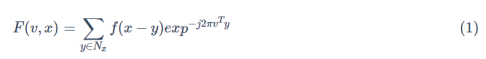
v��R3��һ��Ƶ�ʱ�����j=��-1��ʹ���������ű�ʾ��ʽ(1)
![]()
wvΪƵ�ʱ���v����άSTFT�Ļ�������fxΪ��������Nx����λ�õ�������
ע�⣬���ڻ������Ŀɷ��ԣ����Զ�f(x)�е�����λ��ʹ�ü�һά������Ч�ؼ������άSTFT����������У�������13����͵ķ���Ƶ�ʱ������������¡���ѡƵ�ʱ�����ͼ2��ʾΪ��㡣
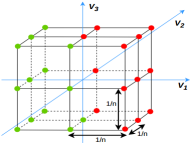
ʹ�õ�Ƶ��������Ϊ����ͨ����������Ϣ��������Ǿ��бȸ�Ƶ�������õ�����ȡ���
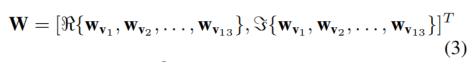
����W��һ��26��n3�ı任�����Ӧ��13��Ƶ�ʱ�����R{��}�ͦ�{��}�ֱظ�����ʵ�����鲿��13��Ƶ�ʵ�(v1,v2,��,v13)����άSTFTʸ����ʽ��

����Fx�Ƕ�����f(x)������λ��x���м��㣬�õ����������ͼ��СΪ26��d��h��w
Layer 3��ʹ��ReLU��������Layer2���������м��
Layer 4������3D�����㣬�˲����ߴ�Ϊ�ߴ�Ϊ1��1��1����������ͼ�ߴ�Ϊ26��d��h��w���������ͼ���ߴ�Ϊf��d��h��w��
Layer 2�ĺ�����û�п�ѵ���IJ�����ѵ���У�ֻ��Layer 1��4��1��1��1�˲������£�W�е�Ȩ�ز��䡣
ReLPV�����������������Ϊ���룺
��������ӳ���ÿ��λ�ü���STFT��������ȡ�ֲ���λ���ľֲ�����Ĵ�С��
ReLPV�����������ӳ���������
STFT�����������任���������������źŽ���ȥ���
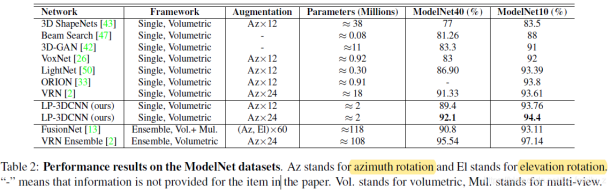
ModelNet�������Ƚ��ļ������бȽ�
��ѭ(VRN)��ϵ�ṹ��˼�����ϵ�ṹ���ü�inception������ϵ�ṹ��resnet�����������ӡ�
ͼ(a)�������������в�ͬ�ֲ���λ�����С(3��3��3��5��5��5)��ReLPV�����ͬ����(128)������ͼ
ͼ(b)�����������ڶ�ǰһ���е�����ͼ�ļ�Ȩƽ��(��1��1��1�������д�����Ȩ) ���� ������λ��Ϣ(ͨ����ReLPV����д�����Ȩ)֮�����ѡ�������������ӣ���ʹ�ݶȸ�ƽ����������ǰ�IJ㡣
ͼ(c)������ģ��ͼ

�ŵ㣺
���ʹ�ͳ��ά������ĸ�ʱ�ո��ӶȺ�ģ���Ӷȡ�
ֻʹ����200�����������Ŀǰ���Ƚ���VRN����ʹ����1800���������ռ�ø��ٵĴ��̿ռ䡣
���ڻ������Ŀɷ��ԣ�����ͨ����ÿ��άʹ�ü�һά������Ч�ؼ���STFT�����Խ��ͼ���ɱ�
ȱ�㣺
ӵ����ӵ�����ܹ������45�㣬1.08�ڸ���������Ҫ��6���ʱ����ѵ����
���µ㣺
1)�����ReLPV�飬��Ч����˱�3D�����㡣ReLPV�������ؼ����˿�ѵ����������Ŀ�����3D��������ȣ��˲����ߴ�ֱ�Ϊ3��3��3��13��13�����ټ�����33��133����
2)��ModelNet10��ModelNet40���ݼ���ʵ�������Ƚ��ľ��ȡ����⣬�ṩ����ʱ��ͼ�������ϵĽ����������UCF-101 split-1����ʶ�����ݼ��ϣ��ڽ�ʹ��15%�����²�����ͬʱ������ǰ�ļ���ˮƽ�����5.68%��
3)�ı�ReLPV��ĸ��ֳ�������������������ں������о�
ʵ������
ModelNet:����ߵıȽ�
Conv3D����3D������MP����������FC��ȫ���Ӳ㣬�����
Voxnet��conv3D(5,32,2)?conv3D(3,32,1)?MP(2)?FC(128)?FC(K)
LPvoxnet��ReLPV(5,32,2)?ReLPV(3,32,1)?MP(2)?FC(128)?FC(K)
SGD��Ϊ�Ż���������Ϊ0.9��
���ཻ����Ϊ��ʧ��
����Щ���������ѵ����ѧϰ�ʴ�0.008��ʼ��ÿ�ν���2��
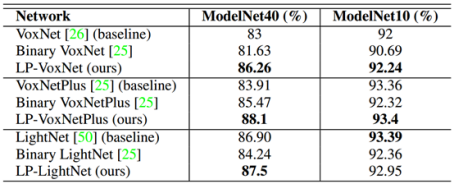
ModelNet�������Ƚ��ļ������бȽ�
������ModelNet���ݼ��д�СΪ32��32��32�����أ�
SGD��Ϊ�Ż���������Ϊ0.9��
���ཻ����Ϊ��ʧ��
ѧϰ��0.008��ʼ�������֤��ʧ�ȶ����������5����
������ʼ����ʼ������Ȩ��
������Az��12��ǿ������ѵ�����磬Ȼ���Ե�ѧϰ���ʶ�Az��24��ǿ���ݽ�����