��Դ���ӣ�https://www.bilibili.com/video/BV1r4411f7td?p=16
��������
������һ���뷨�Ƚ����У���һ��ģ�������10����ͬ������ʮ��ȫ�ܱ�����
������Ԥ�������ֿ��ܶ���һ�����ڲ�ͬ��ģ���к����Dz�һ����
NLP&AI����һ����ʲô��

�����������̵Ļ���ѧϰ->����ѧϰ�����ѧϰ->��Ե�����������ܹ�����->��
������ѧϰ�ľ�����
- ����{dataset��task��model��metric}�����������ܵõ��˺ܴ����
- ֻҪ
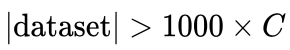 �����ǾͿ��Եõ���ǰ�����Ž�� (C��������ĸ���)�����80%-90%��
�����ǾͿ��Եõ���ǰ�����Ž�� (C��������ĸ���)�����80%-90%�� - ���ڸ�һ��� Al��������Ҫ�ڵ���ģ���м���ѧϰ
- ģ��ͨ���������ʼ��������Ԥѵ�� :disappointed:

Ԥ��ѵ�ͷ���֪ʶ��ΰ��ģ�
������������Ȩ�ش�ͷ��ʼ�Ƿdz����ѵģ����Լ��ر��˵������Ǹ��ܺõ�ѡ��

Ϊʲô��NLP��Ȩ�غ�ģ����û�з�����ô�ࣿ
- NLP��Ҫ�����������������ԣ���У��Ӿ���++
- ��Ҫ���ںͳ��ڼ���
- NLP����Ϊ�м�����͵���������ȡ�ý�չ
->��ÿ������������������ڻ��ֵĺ����ԣ�����ʵ���ϲ�����͵����⣬���DZ������ɰ�AB�ֿ�������������ģ����磺����ʵ��ʶ��ʹ��Ա�ע�ܶ�����Ƶģ����Ǻܶ��˰����ǵ���������ȫ��һ�������⣩
- һ�����˼ල��������Խ�����������𣿲����ԣ�������Ȼ��Ҫ�ල
ΪʲôҪΪNLP����ͳһ�Ķ�����ģ�ͣ�
- ������ѧϰ��һ��NLPϵͳ���谭
- ͳһģ�Ϳ��Ծ������ת��֪ʶ��������Ӧ��Ȩ�ط�����ת�ƺ������ѧϰ��
- ͳһ�Ķ�����ģ�Ϳ���
- ��������Ӧ������
- ����������ʱ��
- ���ͱ����ø����˽��������
- DZ�ڵ�ת�����ѧϰ
��������ʵ��ʶ���еĴ��Ա�ע���ڷ�������������кܴ�İ���
�����ͬһ������б�����NLP����
- ����
- ����ʵ��ʶ��aspect specific sentiment
- ���ַ���
- �Ի�״̬���٣���������
- Seq2seq
- �������룬�ܽᣬ�ʴ�

��Ȼ����ʮ��ȫ�ܣ�decaNLP��
����������ʮ��������

�� 10 �ͬ������д���� QA ������ͼQuestion��Answer������ʽ������ѵ������ԣ��Ѷ�����ѧϰ�����ʴ�

Meta-Supervised learningԪ�ලѧϰ ��![]()
ʹ������q��Ϊ����t����Ȼ��������ʹģ��ʹ��������Ϣ����������
y��q�Ĵ𰸣�x�ǻش�q�������������
���decaNLPģ��
�����ʽ�Ǹ����������жϣ�Ȼ��ѡ��ģ�ͣ�������������ѡ���������ģ�͡�������������������һ����if��䣬Ȼ�����Ǹ�ϣ���������ģ����һ��������ģ�ͣ������Ƕ������������ģ�ͣ�
����
- û�������ض���ģ����������Ϊ���Ǽ�������ID��δ�ṩ��
- �����ܹ����ڲ����е�����ִ�в�ͬ������
- Ӧ��Ϊ����������������������ƶϵĿ�����
decaNLP�Ķ������ʴ�����

��һ�������Ŀ�ʼ
��һ������
һ�����ɴ𰸵�һ�����ʣ�ͨ��
- ָ��������
- ָ������
- ���ߴӶ���Ĵʻ����ѡ��һ������
ÿ��������ʵ�ָ���л�����������ѡ�����л�
�������ʴ����磨MQAN��

�̶��� GloVe ��Ƕ�� + �ַ����� n-gram Ƕ�� [��ʽ] Linear [��ʽ] Shared BiLSTM with skip connection

��һ�����е���һ�����е�ע�����ܽᣬ��ͨ�����������ٴη���

����BiLSTM�Լ���ά����������ѹ���㣬��һ��BiLSTM

����BiLSTM�Լ���ά����������ѹ���㣬��һ��BiLSTM

�Իع������ʹ�ù̶��� GloVe ���ַ� n-gram Ƕ�룬������ѹ�����һ��LSTM�����μӱ����������������

LSTM������״̬���ڼ����������������еı�����ָ��ע�����ֲ�����

�������ĺ�����Ĺ�ע��Ӱ������������ 1��gamma�����Ǹ��ƻ��Ǵ��ⲿ�ʻ����ѡ��2��lambda�����Ǵ������Ļ����������и���

��˫���ͷ��ʾ˫�����˼��
���õ����ݼ��ȣ�


�����ؼ�����������ƶ��ɹ��ı�������ÿ�������ı���һ�������Ի���������֮ǰ�ġ���
��������ͬ���ݼ���ͬ�ܹ��������Dz�ͬ���ݼ���ͬ�ܹ�

��������ʱ������ijЩ���������������������˴˸��ţ���ôѵ�����̻ᷢ�����ص�������������
��ѹ�����ڵ�����Ͷ����������в���Ч��
QA��SRL�к�ǿ����ϵ
ָ�������DZ�Ҫ��
�������������������
��ϵ�����ģ���뵥���������ģ��֮�����һ���IJ��
��ѵ���ԣ�ȫ����





��ѵ���ԣ�Anti-Curriculum Pre-training/���γ�Ԥѵ����





���ѣ��ڵ������������������ٴε���
����ɫ������Ԥѵ���ΰ���������
QA �� Anti-curriculum ���γ�Ԥѵ���Ľ�����ȫ������ѵ����MT��Ȼ����⣬����ͼ

��С��ࣺ�����һЩʵ��

MQANָ������

�𰸴������Ļ���������ȷ�ĸ��ƣ�û�л���ģ��Ӧ��ִ���ĸ������ʹ���ĸ�����ռ�
��decaNLP����Ԥ��ѵ��������ձ���
 ��������IWSLT language pairs�������µ�����NER������
��������IWSLT language pairs�������µ�����NER������
Ԥѵ��MQAN���㴥��������Ӧ��
�� Amazon and Yelp reviews �ϻ���� 80% �� ��ȷ��
�� SNLI �ϻ���� 62% ���������İ汾����� 87% �ľ�ȷ�ʣ���ʹ�������ʼ���ĸ� 2%��
���������
����ָ��ʹ�����ǿ��Դ�������ĸı䣨���磬����ǩת��Ϊ����/֧�ֺ�����/����/��֧�֣��������κζ������
ʹģ������ѵ��������Ӧ������,���磺

decaNLP������NLP�Ļ�
Ϊ���NLP����ѵ��������ش�ģ��
���������
- ��һ�����������
- ������ѧϰ
- ������Ӧ
- Ǩ��ѧϰ
- Ȩ�ط�����Ԥѵ������������NLP��ImageNet-CNN����
- �����ѧϰ
��ع�����С���֣�

