目录
一、摘要:
二、介绍:
三、处理:
1、特征提取:
2、建模:特征提取后就开始建模,作者分别使用了HMM,CNN,LSTM的架构,最终效果最好的是CNN/LSTM架构 ,本人想用这个模型来做自己的项目,所以就了解一下作者使用的CNN和CNN/LSTM这两个架构,如下:
二维CNN结构:
CNN/LSTM架构:
四、实验结果:
五、结论:
一、摘要:
使用机器学习应用在自动通过脑电图检测癫痫疾病是一个有挑战性的问题,因为多通道信号包含有用的信号(比如说癫痫)很少,其中还有许多干扰信号,我们称为伪迹信号(如眼动信号,咀嚼信号等),会干扰检测结果。目前的系统误报率高得让人难以接受。以前由于缺乏数据,深度学习算法无法有效地应用。但是,现在因为有TUH EEG Seizure Corpus这个数据集的公布,我们希望用深度学习算法应用到癫痫的自动检测上。
在本文中,作者使用这个数据库来建立CNN和LSTM在内的多种混合网络模型。并且提出了一个新的循环卷积结构的模型,在每24小时7次误报的基础上提供30%的灵敏度。作者还在一个基于杜克大学癫痫语料库的有效评估集上进行测试,性能跟TUH EEG Seizure Corpus一致。作者的工作表明,适合处理序列数据的深度学习架构对于识别性能至关重要,并且有望应用在临床应用上。
二、介绍:
脑电图(EEG)是神经学医生用来检测脑部疾病比如癫痫的重要途径。但需要耗费大量人力物力(懒惰是人类生产力提升的根本推动力。)。此论文虽然聚焦在癫痫检测的问题上,但是同样适用于其他EEG的问题。在过去应用了一些机器学习的方法,时频分析方法(Gotman等人。1982)和非线性技术(Schad等人。2008年)由于较高的误检率,并不实用。作者在TUSZ的语料库基础上,提出了一种新的深度学习架构,用来评估了几个标准的癫痫发作检测任务。在保持灵敏度和特异性的同时降低了误报率。作者证明,该系统的性能目前已接近临床使用可接受的程度。
三、处理:
作者展示了处理EEG信号的通用架构。多通道信号以250赫兹的频率采样,使用16位分辨率,转换为基于特征的表示,通过序列建模器进行处理,然后使用各种统计模型进行后处理,这些模型基于专业知识提出。作者评估并实现了高斯混合模型(GMMs)、隐马尔可夫模型(HMMs)和深度学习(DL)的几种体系结构。处理EEG信号的通用结构如下图:
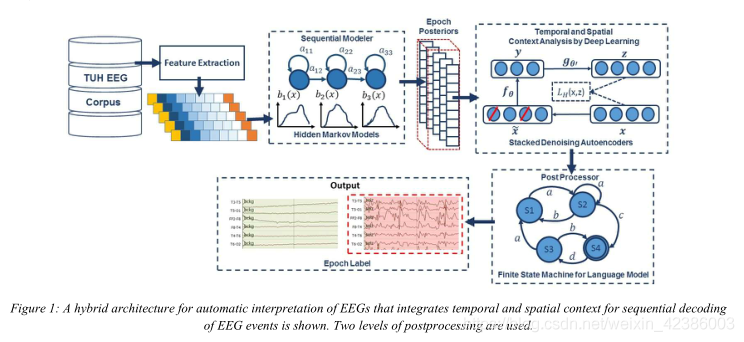
1、特征提取:
虽然可以使用深度学习来直接提取特征,但是本系统使用标准线性频率倒谱系数的特征提取方法(LFCC)(Harati 2015;Lopez 2016)。作者还使用了特性的一阶导数和二阶导数,用以提高性能。作者以1秒为周期分析信号,并将此间隔进一步划分为10帧,每帧0.1秒,以便使用0.2s分析窗口(称为窗口持续时间)每0.1秒计算特征(称为帧持续时间)。特征提取过程的输出是22个通道中每个通道的维数为26的特征向量,帧持续时间为0.1秒。
2、建模:特征提取后就开始建模,作者分别使用了HMM,CNN,LSTM的架构,最终效果最好的是CNN/LSTM架构 ,本人想用这个模型来做自己的项目,所以就了解一下作者使用的CNN和CNN/LSTM这两个架构,如下:
二维CNN结构:
卷积神经网络处理图像和语音识别特别有用,所以将EEG类比图像处理。
- 在图像和语音识别中常见的二维cnn的情况下,到卷积层的输入是W×H×N数据(例如图像),其中W和H是输入数据的宽度和高度,N是信道数(例如在RGB图像中,N=3)。
- 根据图像分类的类比,每个图像是一个信号,其中图像的宽度(W)是窗口长度乘以每秒的样本数,图像的高度(H)是EEG通道的数目,图像通道的数量(N)是特征向量的长度。在作者的系统中,使用了7秒的窗口持续时间。第一卷积层使用16个大小为3×3、步长为1的核来过滤大小为70×22×26的输入。第二个卷积层使用16个大小为3×3、步长为1的核来过滤它的输入。第一个最大池化层将第二个卷积层的输出作为输入,并应用2×2的池大小。这个过程在32和64个内核中重复两次。接下来,应用512个神经元的完全连接层,并将输出送给一个2路sigmoid函数,该函数产生一个两级判定(最后的epoch标签)。
- 作者设计的网络包含六个卷积层、三个最大池层和两个完全连接的层。线性激活函数(ReLU)非线性应用于每个卷积层和全连接层的输出。如下图:
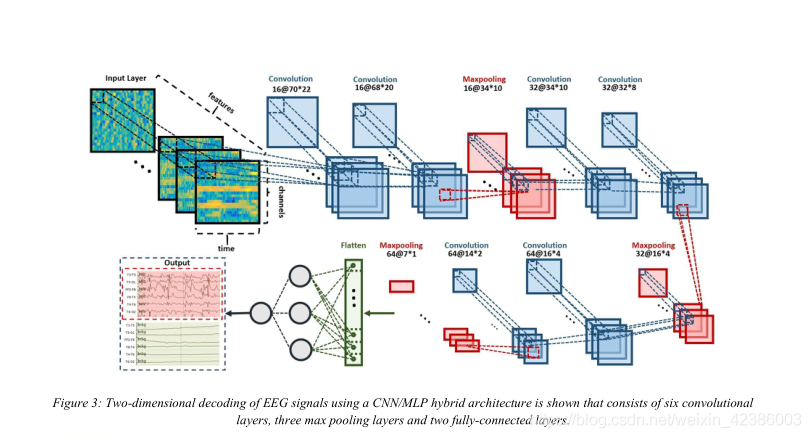
CNN/LSTM架构:
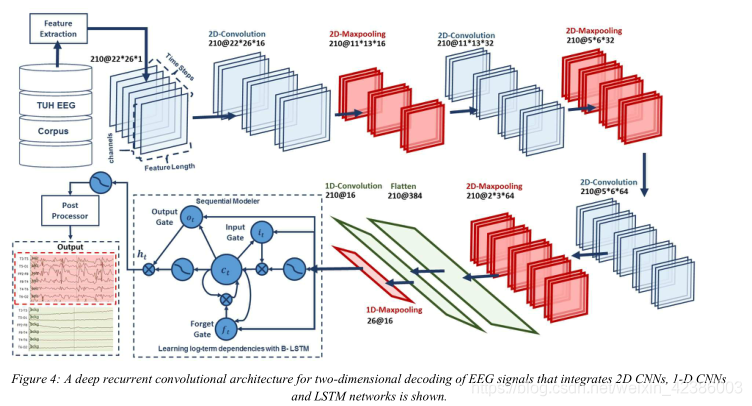
作者集成了2D-CNN、一维CNN和LSTM网络,称之为CNN/LSTM,可以更好地利用长期依赖性。
- 输入数据由时间分布的帧组成,每个帧是宽度(W)等于特征向量长度的图像,高度(H)等于EEG通道数,图像通道数(N)等于1。
- 输入数据由T帧组成,其中T等于窗口长度乘以每秒采样数(每0.1秒取一次特征,1秒是10)|。系统的窗口持续时间为21,第一个二维卷积层使用16个大小为3×3的核,以1的步长过滤210帧(T=21×10)的EEG,这些EEG的大小为26×22×1(W=26,H=22,N=1)。第一个max pooling层以时间分布的260帧为输入,其大小为26×22×16,采用2×2的池大小。这个过程用两个二维卷积层重复两次,两个二维卷积层分别具有32个和64个核,大小分别为3×3,两个2D max池化层的大小为2×2。
- 第三个最大池的输出平坦到210帧,大小为384×1。然后,一维卷积层使用16个大小为3的核对平坦层的输出进行滤波,将空间维数降低到210×16。然后我们应用一个尺寸为8的一维最大池层,将维数降低到26×16。这是一个深的双向LSTM网络的输入,其中输出空间的维数是128和256。。最后一个双向LSTM层的输出被输入一个2路sigmoid函数,该函数产生分类结果。为了克服过度拟合的问题并迫使系统学习更稳健的特征,在层之间使用了dropout和高斯噪声层。为了增加非线性,使用指数线性激活函数ELU。Adam优化器与均方误差损失函数一起用于训练过程。
结构如图所示:
四、实验结果:
作者使用TUHS数据集作为训练集和测试集,Duke数据集作为评估的测试集。因为这是在两个不同设备下采集的,能更好地评估出模型的泛性能力。语料介绍如下:
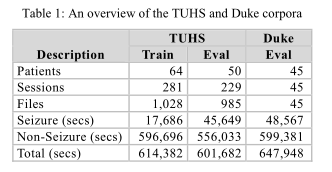
作者使用了几个模型,对比其性能:
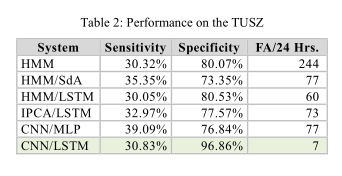
正确率(TP)定义为参考注释中确定为发作并由系统正确标记为发作的样本数。真负向(TN)是指被正确地标识为非癫痫的样本数。误报率(FP)定义为系统错误预测为癫痫发作的样本数,而假负向(FN)定义为错误地标记为非癫痫发作的样本数。表2中显示的灵敏度计算公式为TP/(TP+FN)。特异性计算公式为TN/(TN+FP)。虚警率是每24小时的FP数,也就是每24小时有多少的误报样本。
最好的整体系统是CNN和LSTM的结合。
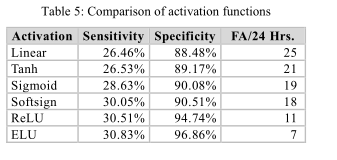
作者还对比了在CNN和LSTM的基础架构上(TUSZ语料),使用不同的优化算法和激活函数时,模型的表现:

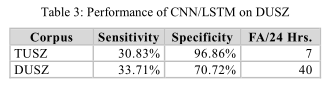
作者还比较了同样条件下,CNN/LSTM这个架构分别在DUKE和TUSZ语料上的表现:
五、结论:
在这篇论文中,作者介绍了多种用于eeg自动分类的深度学习架构,包括一个整合CNN和LSTM的混合架构。虽然这种结构比其他深层结构提供了更好的性能,但其性能仍然不能满足临床医生的需要。人类在此类任务中的表现在65%的敏感度范围内,每24小时出现12次错误警报(Swisher等人。2015年)。在发作间期和发作后阶段观察到各种各样的伪影。对这些具有不同形态的事件的训练模型有可能显著减少剩余的假警报。这也是需要继续努力注释TUSZ更大一部分的原因之一。