精读Regularizing Reasons for Outfit Evaluation with Gradient Penalty
- 1. 本文贡献介绍
- 2. EVALUTAION3数据集
- 3. 完成评估的网络框架
- 3.1 特征提取阶段(feature extraction net)
- 3.2 内联因素兼容性网络层(Intra-factor compatibility network)
- 3.3 因素内部兼容性网络层(Inter-factor compatibility network)
- 4. 对评估的原因分析
- 4.1 CAM和Grad-CAM
- 4.2 本文做法(单神经元贡献)
- 4.3 单属性贡献
- 4.4 normal与bad/good之间的区别
- 4.5 reason strength
- 4.6 损失函数
- 5. 评估反馈生成
- 6. 实验
- 6.1 实验结果
- 6.2 实验结果案例验证
- 6.3 实验结果展示
- 7. 本文个人总结
1. 本文贡献介绍
原文地址:Regularizing Reasons for Outfit Evaluation with Gradient Penalty
- 构建了一个EVALUTAION3数据集;
- 能够对服装进行评价;
- 能够生成对用户友好的反馈解释。
本文工作中,提出了一个服装评估系统,并且对任何服装的评估都存在对应的解释。并且通过添加一个梯度惩罚正则项,使得神经网络分析产生的判断原因与专家标注的原因保持一致。本文根据good/bad和normal对应服装之间的差异进行建模,并将原因作为正则化因子添加到损失函数当中,从而使得网络在不失去性能的前提下,还具有可解释性。并且基于构造的EVALUTAION3数据集进行了详细的实验,证明了本文方法的有效性。
2. EVALUTAION3数据集
数据集来源:Polyvore dataset
数据集划分:train set, validation set, test set, and test-random-set
基于专家的角度,将服装进行分类为三个层次:
- Bad:服装中存在元素不搭调(比如:错误颜色匹配,印花图案很刺眼等);
- Normal:视觉上没什么特殊也没什么不协调;
- Good:存在某些特殊设计(比如:吸引人的颜色搭配、特殊图案等)
注意: 即便是有特殊的亮点,但是因为某些因素搭配不合适,那也认为是bad。

本文规则: 每一套服装图片都包含:一件上衣,一件下衣。
这个数据集分别代表了训练集、验证集、测试集、以及测试随机集,下表为它们的占比。
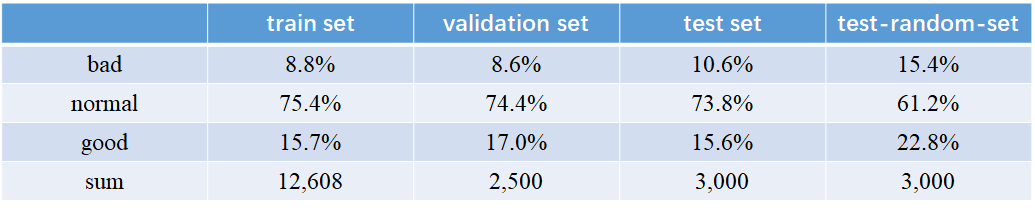
test-random-set: 根据test set 的3000个数据集,将上身和下身随机搭配形成的3000套服装数据集。
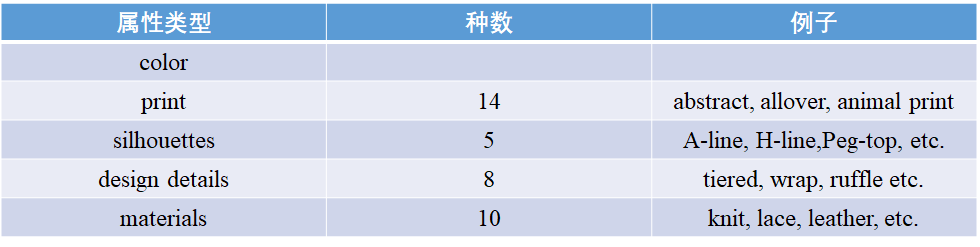
此外,对每一件item都进行了属性标注:
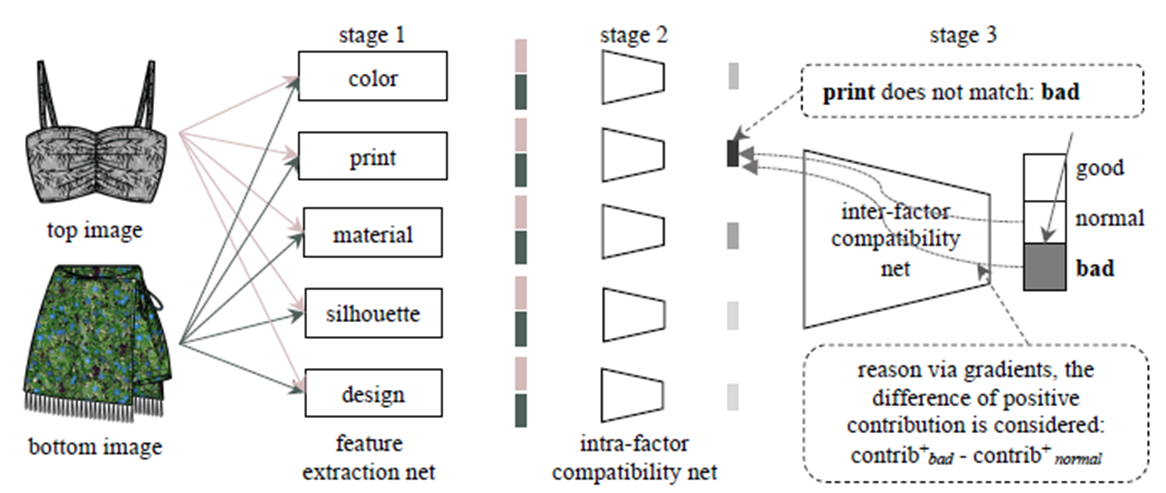
3. 完成评估的网络框架
内部网络框架图如下所示
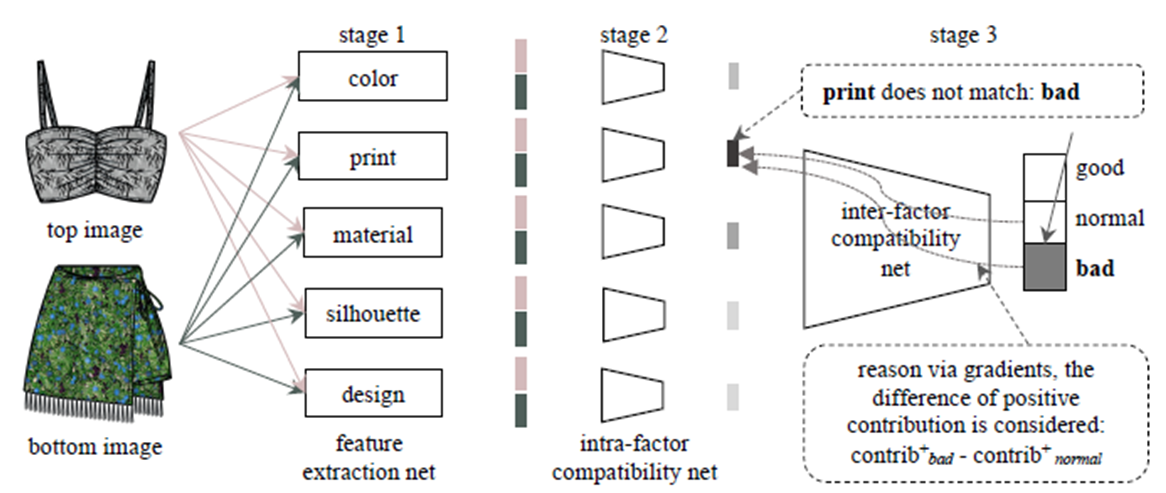
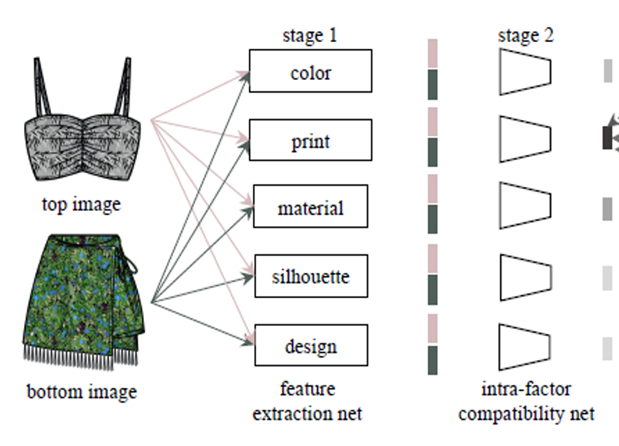
本文狂阿基将该共分为3个stage:feature extraction net、intra-factor compatibility net、inter-factor compatibility net.
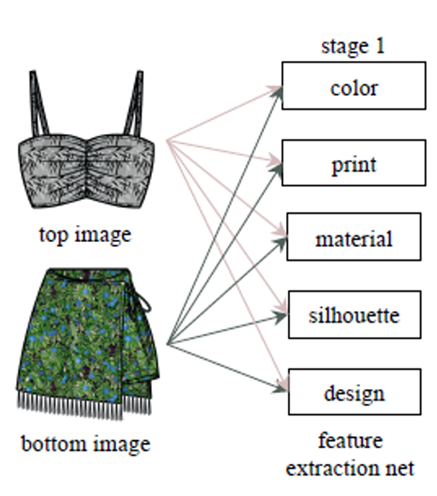
3.1 特征提取阶段(feature extraction net)
第一层是一个服装特征提取网络层,使用的是模型预训练的网络ResNet-18,分别得出每一件单品的五种属性:
-
print、material、silhouette(轮廓)、design。
-
通过Fashion Color system (FOCO)绘制单品颜色分布的直方图,然后选取前五种主要色调作为该单品的color feature(25维)
3.2 内联因素兼容性网络层(Intra-factor compatibility network)
第二层是一个内联因素兼容性网络层
如下图所示,这里拿color作为举例说明:
- 输入:上身的颜色特征、下身的颜色特征
- 三层的全连接层
- 作用:将上身颜色特征和下身深颜色特征输入到第二层网络当中,该网络主要是学习上身和下身,在颜色特征进行交互之后的的结果因子。
每一种属性都是在各自的全连接层中训练得到对应的内联因素兼容性因子,该因子的含义可以理解为上衣和下身在这种属性角度上看,的一个兼容程度。
3.3 因素内部兼容性网络层(Inter-factor compatibility network)
第三次是因素内部兼容性网络层。
将第二层得到的五种属性对应的兼容性因子,进行合并,然后输入到一个3层的全连接层当中,得到一个的分类结果(本文结果为3种)。
输出: 该服装被评估为bad、normal、good的概率。
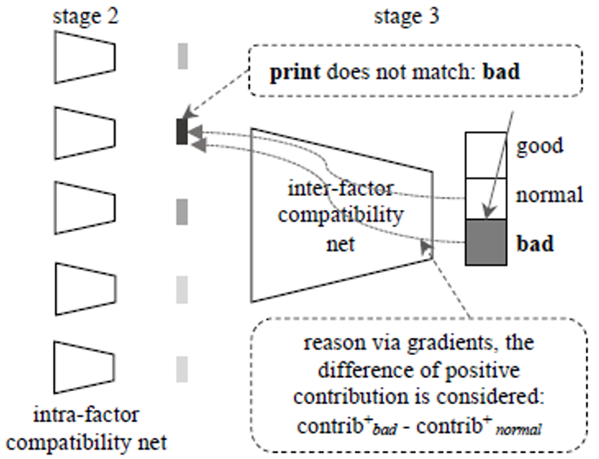
到这里模型属性预测的过程已经基本上了解完毕,但是本文主要还是希望能够找到做出这种判断的原因。
即可解释性分析。
4. 对评估的原因分析
这一节主要是讲解做出如上预测的原因,因为如果能够得到正确的原因,我们才能更好的了解整个模型到底学习到了什么细节。
我建议这部分读这个大佬的文章理解下啥是CAM和Grad-CAM。CAM和Grad-CAM)
4.1 CAM和Grad-CAM
主要是用来查看哪些输入部分对结果做出的贡献最大。
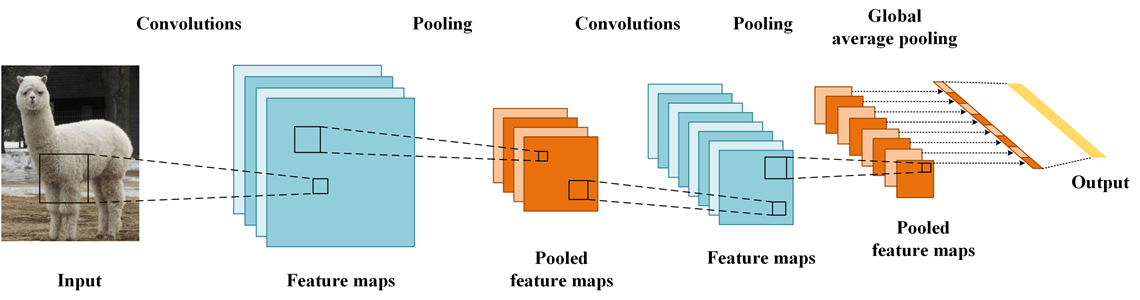
GAP更充分的利用了空间信息,且没有了全连接层的各种参数,鲁棒性强,也不容易产生过拟合;还有很重要的一点是,在最后的 卷积层强制生成了和目标类别数量一致的特征图。
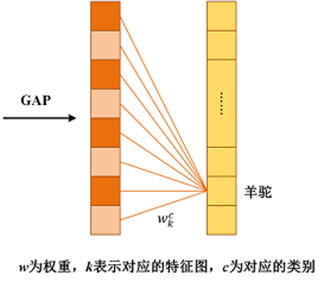
将每一个特征图分别与其各自对应的权重相乘,并相加,得到该图像的一个热力图。
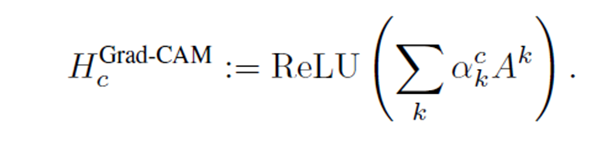
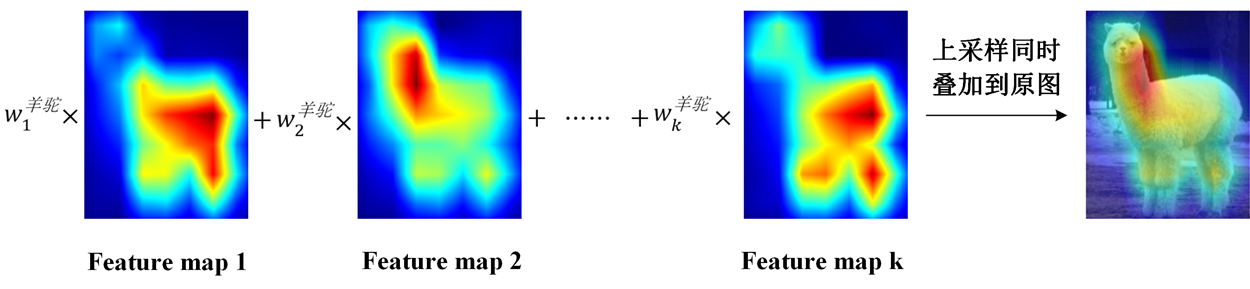
本文重点并不是关注热力图,而是希望关注到人类可解释的因素完成分析。
4.2 本文做法(单神经元贡献)
如下图所示,图表示第三层合成兼容性因子进行最终服装评价预测的过程。
我们先只关注color这一个属性特征,该特征由很多个Neuron组成{
、
…
、
},。
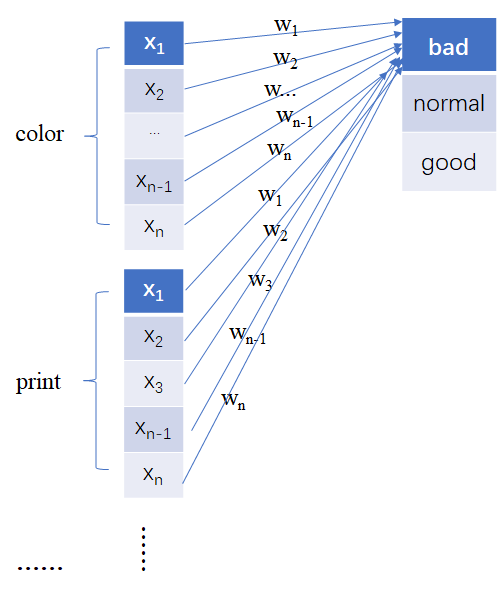
每一个神经元都会对最终做出的判断产生一个贡献值,比如color的第一个神经元
对做出bad结果产生的贡献值可以按照如下公式计算:
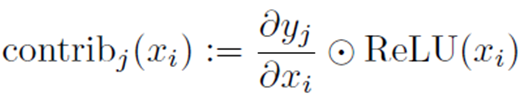
- j 表示三种分类结果{bad,normal,good}
- 表示 最终得到结果 的概率
- 表示 一个神经元
ReLU的原因: 因为只关心对类别 有正影响的那些像素点,如果不加ReLU层,最终可能会带入一些属于其它类别的像素,从而影响解释的效果。
4.3 单属性贡献
本图和上一致
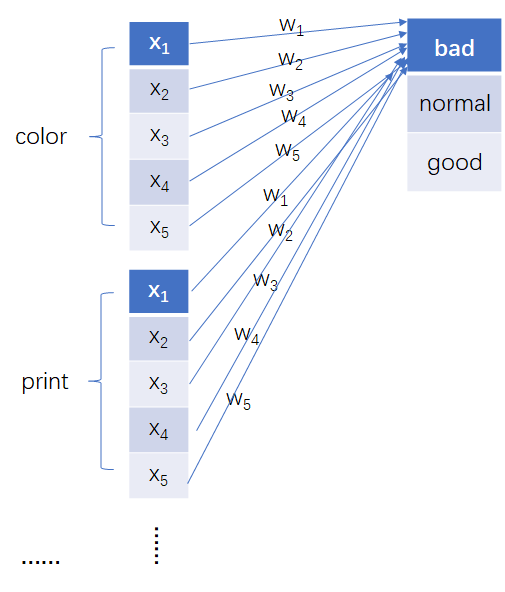
将该属性所有相关的神经元做出的贡献度求取平均得到:单属性对最终结果的贡献。
如下公式:
- 号表示正贡献
- 表示{bad,normal,good}的一种情况
- 表示{color,print,design}的一个元素;
- 表示该属性r所包含的神经元个数
注意:r中只能包含三种元素,是因为作者将silhouettes,design details,materials统称为design看待。
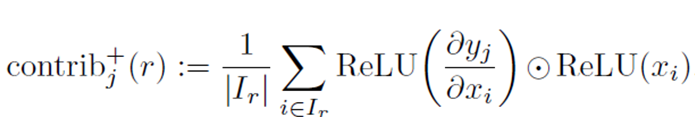
所以,
表示特征r对最终所做judgement的正贡献。
4.4 normal与bad/good之间的区别
因为任何事物的好与坏都是相对图正常而言进行评价的,服装评估也是如此。
也就是说:good肯定是因为某一个亮点,使得该衣服比普通衣服更加突出,从而被专家评定为good。
根据该假说,所以可以提出如下公式:
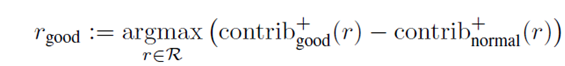

这表示:先对各个特征维度的正贡献进行求差运算,然后求出最大的那个差值。
可以认为good和normal之间不同之处,就最大差值对应的特征属性。(因为该特征属性是一good相比normal的一个亮点 ,好好体会…)
bad方面亦是如此
4.5 reason strength
这一小节其实就是计算每一种特征属性对应的原因强度,如何理解呢?
直接截原文吧,更好解释。
首先,
是一个指示函数,它得值仅为1或0;
- 当系统评估结果和之前专家标注的判断结果是一致的,那么就为1
- 当系统评估结果和之前专家标注的判断结果不一致的,为0

具体为什么这么设计呢?展开该公式可以得到
假设判断为good、专家也评定为good,则原式:
当r为color时,上式就为
这实际上就是计算得到color特征在系统最终最初good的评估结果时,所依靠的原因强度。
打个比方: 我买电脑有很多种原因:写代码、看电视、打游戏、写文档等等都是原因,但是这些原因都是有强弱关系导致我做出最终购买电脑的决定。
而在本文最终的 就代表了我做出该判断的原因强度。
4.6 损失函数
本文共提出了3中损失函数,分别为交叉熵、线性、平方差三种常见类型。

但是这里的损失函数有点类似正则化中的
范式和
范式(有木有= =!)
最终整个模型的损失函数由两部分构成:
- 对服装的评估结果进行预测产生的损失
- 对评估的原因进行预测产生的损失

5. 评估反馈生成
文中指出反馈是根据结合了专家的知识而生成的,但在论文中给的图大致流程实际上就是套用了模板,将关键词进行替换得到最终评估原因反馈。
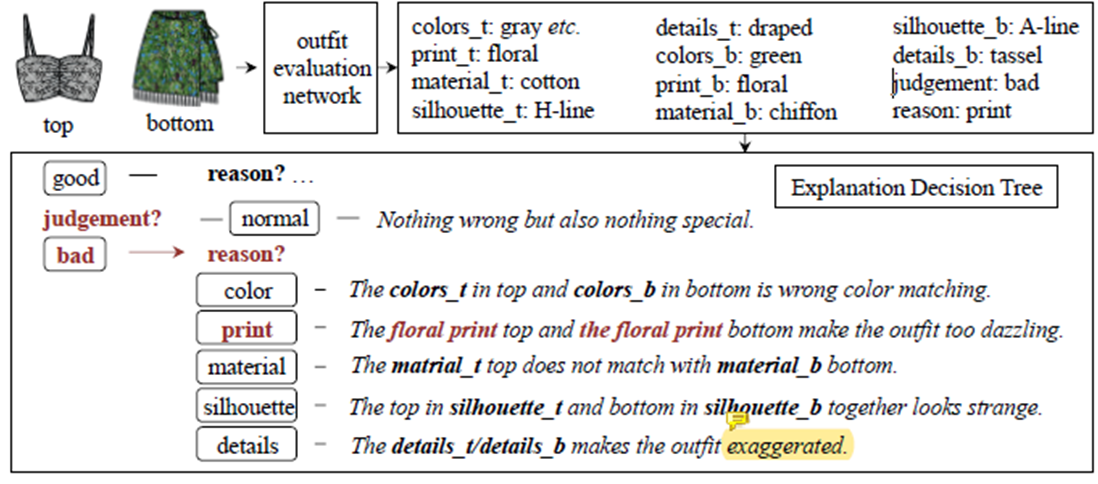
比如输入一套衣服,之后大概步骤如下:
- 得出上衣的五种属性,以及下身的五种属性值;
- 得出判断结果和判断结果的依据原因;
- 根据评估原因进入不同的决策分支,评估结果为三种,所以有3种不同的分支;
- 进入对应结果分支后,根据判断依据原因,选择对应的模板语句;
- 将上身和下身对应的属性填入模板,即得到最终的反馈语句。
拿本案例作为解释:
- 这里案例评估为
bad,原因为print; - 根据结果为
bad进入对应决策分支; - 根据原因
reason选择对应模板语句
- The xxx print top and the xxx print is wrong color matching. - 根据上衣和下身对应属性进行填充,得到如下反馈语句:
- The floral print top and the floral print is wrong color matching.
6. 实验
6.1 实验结果
首先搞清楚评价指标:
- judgment accuracy(评估结果预测准确率)
- reason accuracy(依据原因预测准确率)
如下图所示,表示实验结果
第一列: 为各种模型第一行和第二行为其他论文中的模型,第三行为本文文中只考虑判断损失而不考虑原因预测损失的模型,之后三行就分别表示原因预测使用的是那种损失函数情况。

最终得到的结果可以得出:
含有惩罚项损失且基于交叉熵作为损失计算的方法,模型效果最优(最后一行)。
6.2 实验结果案例验证
如下图所示
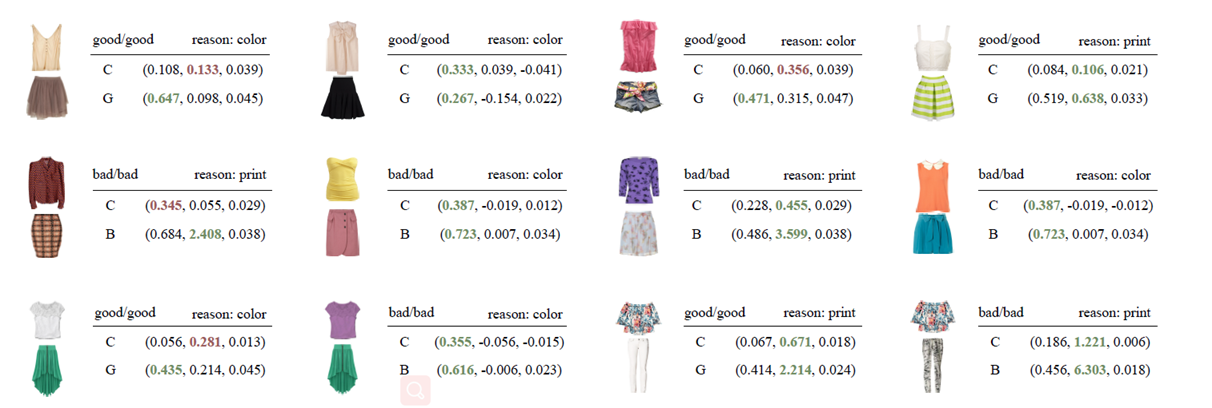
第一行,全部表示专家标注认为good,且系统评估也是good的服装案例。
拿第一个单品做解释:
good/good resaon:color
- 第一个good表示专家标注该种服装搭配为good
- 第二个good表示本系统评估结果认为该种服装搭配为good
- resaon -> color: 表示专家评估为good的原因是因为这套服装的颜色是亮点。
C(0.108, 0.133, 0.039)
-
c:表示使用公式C计算而得出的三种属性特征(color、print、design)对最终产生该判断所做出的影响。
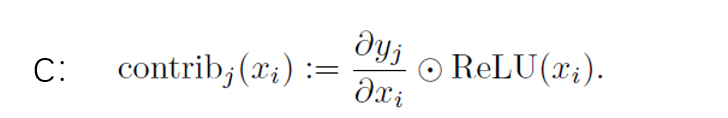
-
0.108:表示
color对最终产good该判断所做出的贡献值(影响分) -
0.133:表示
print对最终产good该判断所做出的贡献值(影响分) -
0.039:表示
design对最终产good该判断所做出的贡献值(影响分)
G:(0.647,0.098,0.045)
- G:表示使用公式G计算而得出的三种属性特征(color、print、design)对最终产生该判断所做出的影响。
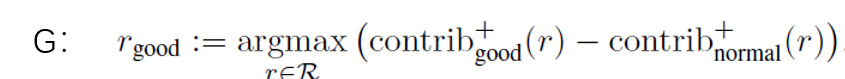
- 0.647:表示
color对最终产生good该判断的原因强度 - 0.098:表示
print对最终产生good该判断的原因强度 - 0.045:表示
design对最终产生good该判断的原因强度
介绍完了含义,该看看具体有什么用了。
看C那一行中棕色高亮为第二个数值,表明使用C公式计算的贡献影响值print最大,也即是说根据这种贡献计算方式,得出系统评估为good的原因为print;这与专家做出的判断原因(color)相悖。也就是不一致。
但是看G那一行中绿色高亮部分,对应的为color属性,也就是说:系统按照这种计算方式,可以得知系统做出最后判断的原因为color, 这与专家的推断原因是一致的,也就是说,模型学习真正有学习到,并且做出的结果判断是有凭据的。
吼吼!!!可解释性分析的魅力来啦…
6.3 实验结果展示
如下图为最终结果的展示
比如第一行:
- 判断结果为
good - 判断依据原因为
Print - 根据原因选择对应
Print属性值,根据解释模板,生成最终的反馈。

7. 本文个人总结
对以上部分进行整体总结,以后也好回顾回顾这篇文章的内容。

(1)构造了一个数据集
该数据是名为Polyvore dataset的开源数据集,然后请了一些服装时尚搭配领域的专家打标注,对每一套服装进行了(bad,normal,good)三种评价,并且对每种评价做出了评估原因的标注。
(2)服装评价系统的搭建
下图为关键网络架构,主要是整个模型将数据集转化为最终分类结果的架构图。
| 传统做法 | 本文做法 |
|---|---|
| 对已经训练完的模型进行可解释性分析 | 将模型的解释一通投入到模型当中训练,使得最终的解释不断修正 |
提出: 将最终决策原因作为损失函数的正则惩罚项,使得网络在不失去性能的前提下,还具有可解释性。
(3)生成判断反馈
本文还使用了专家给定的文本模板,对所进行的判断,提供可解释的、用户体验友好的反馈。
(4)进行了比较详细的实验
通过自己所构建的EVALUTAION3数据集,使用了6中不同情况,进行结果测试,最终得出采用本文方法(添加了原因作为正则化因子,损失函数为交叉熵)效果表现得最优。