A New HEVC In-Loop Filter Based on Multi-channel Long-Short-term Dependency Residual Networks
Xiandong Meng?, Chen Chen?, Shuyuan Zhu?, and Bing Zeng?
?The Hong Kong University of Science and Technology
Clear Water Bay, Kowloon, Hong Kong, China
?University of Electronic Science and Technology of China,
Chengdu, Sichuan, China
{xmengab, cchenaf}@connect.ust.hk; {eezsy, eezeng}@uestc.edu.cn
摘要
在本文中,我们提出了一种基于多通道长短期依赖残差网络(MLSDRN)的新型HEVC环路滤波器。受人类记忆单元信息存储和信息更新功能的启发,我们的MLSDRN引入了一种更新单元,通过自适应学习过程来自适应地存储和选择长期和短期依赖信息。此外,我们利用记录在比特流中的块边界信息来改善滤波器性能,这也使我们的MLSDRN不能平等地对待视频内容。同时,引入了多通道技术来解决光照差异问题。我们将新型环路滤波器集成到HM参考软件中,并将其应用于亮度和色度分量,仿真结果表明,所提出的环路滤波器可以在关闭ALF的情况下最多将BD-rate降低15.9%。对于亮度分量,新型的环路滤波器在all intra,low delay和random access配置下的BD-rate节省分别为6.0%,8.1%,7.4%。
1 介绍
由于将逐块操作用于图像/视频压缩,因此在压缩的图像/视频信号中始终存在阻塞伪像。 为了平滑两个相邻编码块之间的边界,在最近的视频编码标准(包括H.264 / AVC [1]和H.265 / HEVC [2])中提出并采用了环路滤波器。 到目前为止,已经证明它是一种非常有效的工具,不仅可以提高视频编码的压缩效率,而且可以提高帧内编码的效率,也可以提高帧间编码的效率。
在HEVC的开发过程中,提出了三种环路滤波器,即去块滤波器(DF),样本自适应偏移(SAO)和自适应环路滤波器(ALF)。DF是专门为减少块伪影而设计的,它根据编码信息在8×8块边界上执行。在DF之后,SAO作为非线性滤波器被提供以进一步减少伪影。ALF在HEVC早期曾被提出作为继SAO之后的第三个环路滤波器。但是,由于边界信息的大量开销,它没有包含在最终设计中。尽管已经提出了这些环路滤波器,但是仍然难以保证最佳的编码效率。近来,为了进一步改善视频编码的性能,已经提出了许多环路和后处理滤波器。一般来说,滤波方法可分为两类,即基于模型的优化方法和判别学习方法。对于基于模型的方法,Matsumura等人。 [3]首先在HEVC中引入了非局部均值(NLM)滤波器,以仅基于图像局部平滑度先前模型来补偿现有环路滤波器的缺点。Zhang等人。[4] 提出了一种基于图像非局部先验知识的非局部自适应环路滤波器。对于基于学习的方法,Dai等人。[6] 针对HEVC帧内编码的后处理问题,提出了一种可变滤波残差学习卷积神经网络。在解码器端,Wang等人。[7] 为了进一步提高解码帧的质量,提出了一种后处理深卷积网络。
虽然传统的单通道平面的CNN取得了良好的性能,但实际上存在两个问题。第一个是那些模型中的当前状态仅受其直接的先前状态(短期依赖性信息)影响,而没有考虑所有先前的状态(长期依赖性信息)。最近的证据表明,人脑具有持续性,倾向于存储过去的重要信息,同时,通过研究检索和更新记忆的信息[5]。因此,长期依赖信息也很重要。第二个问题是,尽管非常深的网络可以捕获HR图像中的大多数高频内容,但实际上预测的和GT图像的平均幅度之间存在光线差异。在相对较浅的网络中未观察到类似的现象,该浅网络的整体幅度更为精确。然而,浅层网络无法恢复冗余的高频细节[8]。基于CNNs在计算机视觉领域的成功应用[6-16],针对这些问题,我们提出了一种基于MLSDRN的HEVC环路滤波器。为了研究与最新的环路内滤波器算法的兼容性[4],我们将其作为一种新型的环路内滤波器集成到HM参考软件中。
2 提出的方法
2.1 网络模型
我们提出的MLSDRN由三部分组成:特征提取网络(FENet)、具有堆叠密集连接的多通道更新单元(UCells)[9]和重建融合网络,如图1所示。FENet获取输入图像并将其表示为一组特征图。更新单元集是解决减少块效应任务的主要组成部分,重建融合网络将多通道特征映射转换回原始图像空间。

让我们将x表示为具有阻塞伪像的输入色块,并将y表示为MLSDRN的输出。具体来说,在FENet中使用每个通道具有不同内核大小的卷积层从输入图像x中提取特征,
其中f0表示特征提取函数,U0是提取的特征。假设d个UCell被堆叠以充当一个通道中的特征映射,我们有
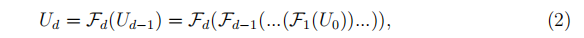
其中Fd表示第d个更新函数,Ud-1和Ud分别是第d个UCell的输入和输出。
然后,我们将所有通道的每个UCell的输出发送到重建融合网络以生成中间输出。 最后,可以通过对中间输出进行加权平均来生成最终输出。 我们将在2.3节中详细介绍。
2.2 更新单元
现在我们将详细介绍UCell。如图2所示,蓝色虚线框表示生成短期依赖信息的递归单元,绿色行表示所有以前的UCell信息,这些信息直接传递到更新门以生成长期依赖信息,更新门自适应地记住和忘记过去的信息。我们将在下面给出UCell设计的一些重要细节。

使用可变滤波器大小提供多尺度信息。 HEVC中的变换是分块的,因此一个系数的量化误差只影响同一块中的像素,可以考虑可变块大小的变换来提供多尺度信息。因此,在我们的UCell中,我们提出了三种适合于HEVC可变块大小变换的可变滤波器大小,即在每个递归中,3DConv a、2DConv b和1DConv c的核大小分别为5×5、3×3和1×1。
用膨胀滤波器扩大感受野。 一般来说,有两种方法可以扩大CNNs的感受野,即增大滤波器的尺寸或增加滤波器的深度。然而,增大滤波器的尺寸不仅会引入更多的参数,而且会增加计算量。因此,在本文中,我们使用最近提出的膨胀卷积技术[14]在接受区域的大小和网络深度之间进行权衡。在每个递归中,滤波器3DConv a、2DConv b和1DConv c的膨胀因子s分别设置为s=3、2和1。
使用更新门自适应地选择依赖项信息。 在UCell中,递归单元中的每个递归Mk_conv都是一个残差块,让我们用Hr(d)和Hr-1(d)来表示第d个UCell中第r个递归的输入和输出,
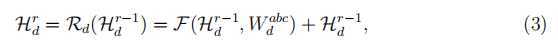
其中F表示残差函数,Wabc(d)是要学习的权重集合。具体来说,递归单元中的每个残差函数都包含一个具有可变内核大小和预激活结构的卷积层,
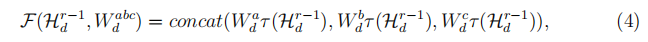
其中Wa(d),Wb(d)和Wc(d)是膨胀的卷积层的权重,为简单起见,省略了偏置项,并且τ表示PReLU激活函数[15]。
假设一个UCell中有L个递归,因为这些递归仅使用直接的前状态,因此我们称它们为短期依赖。 然后,可以将递归单元中的第l个递归公式表示为:
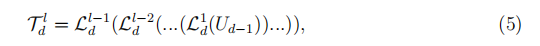
其中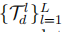 是第d个UCell中递归单元的多级表示。
是第d个UCell中递归单元的多级表示。
每个UCell中的更新门从同一信道的先前UCell接收长期依赖信息,并从当前递归单元接收短期依赖信息,令Ggd = [T 1d,T 2d,…,T Ld,U0, U1,…,Ud-1],则第d个UCell的输出为
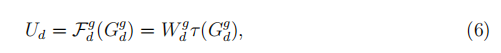
其中τ表示信息控制函数,由Wgd加权。 在此公式中,更新门控制有多少依赖项信息会延续到第d个UCell的输出。 当前一个UCell的门权重接近0时,当前状态被迫忽略前一个状态。 相反,更多的是先前的状态信息将被保留。由于每个UCell有不同的更新门,每个门单元将学习捕获不同接收野尺度上的短期和长期依赖性。这个动作的机制类似于GRU[13]中的门单元,有助于网络记住依赖信息。
2.3 训练
给定训练数据集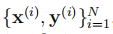 ,我们将每个通道中每个UCell的输出发送到重建融合网络F(rec)以生成中间输出。中间输出用于通过加权平均计算最终输出。我们将MLSDRN设置为具有D个通道,并使用第d个(d = 1,2,…,D)通道来获得d个UCell,我们总共有D(D + 1)/ 2 + 1个目标来最小化。
,我们将每个通道中每个UCell的输出发送到重建融合网络F(rec)以生成中间输出。中间输出用于通过加权平均计算最终输出。我们将MLSDRN设置为具有D个通道,并使用第d个(d = 1,2,…,D)通道来获得d个UCell,我们总共有D(D + 1)/ 2 + 1个目标来最小化。
受[16]的启发,我们使用混合损失函数L1 + SSIM来训练提出的网络。 具体来说,为了以L1范数监督D(D + 1)/ 2中间输出,
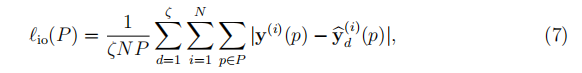
其中ζ= D(D +1)/ 2表示中间输出数,p是图像块中像素的索引,P是图像块,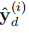 是第d个UCell中i块的中间输出,可以制定为,
是第d个UCell中i块的中间输出,可以制定为,

让wu(d)表示通道d中的第u个中间输出对最终输出的重要性,用于用L1-范数监督最终输出,
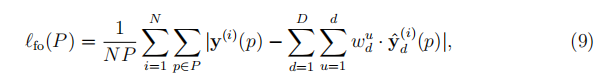
现在,最终损失函数的L1-范数可以表示为
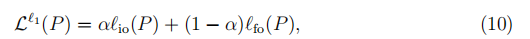
其中,根据经验将α设置为α= 1-1 /(ζ+ 1)。 等式 (10)为简单起见可以重写为
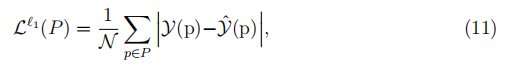
其中,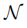 是简化系数,
是简化系数,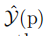 和
和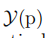 分别是处理后的色块中的像素值和GT值。
分别是处理后的色块中的像素值和GT值。
因此,块中每个像素p的反向传播导数具有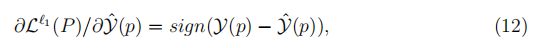
像素p的SSIM定义为
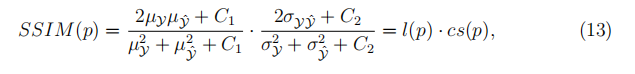
为简单起见,我们将SSIM(MSSIM)的多尺度版本定义为
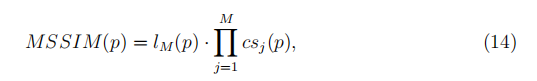
其中L(m)和CS(j)是我们在SSIM的尺度M和J中在等式(13)中定义的术语,并且我们可以在其中心像素P处逼近色块P的损失。
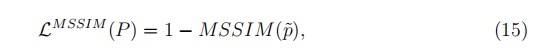
然后,基于MSSIM的损失函数的导数可以写成
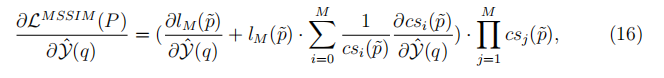
式中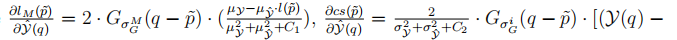
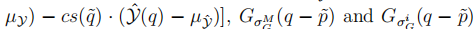 ,i=1,2,…,M为高斯分布与像素q相关联的系数。
,i=1,2,…,M为高斯分布与像素q相关联的系数。
最后,结合两个损失函数的特点,我们得到
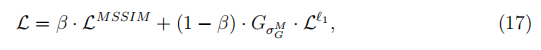
其中L是最终损失函数,我们忽略了所有损失函数对色块P的依赖性,并依据经验地设置M=4,β=0.25。
2.4 先前的边界比特流信息
在HEVC中,对于亮度和色度样本,DF仅应用于在8×8样本网格上对齐的边。 具体而言,对于亮度样本,根据过滤强度选择不过滤,弱过滤和强过滤三种情况之一。过滤强度由几个语法元素的值控制。然而,通过实验发现,在HEVC中为每个样本网格确定的滤波模式并不总是最佳的。 在实验中,我们检查了相邻块两侧的所有类型的滤波模式,并且在通用测试条件(CTC)下分别在RA和LD配置下使用了二十种广泛使用的视频序列(每个序列60帧)。我们发现在HEVC中确定的DF滤波模式对于每个块边界得到最优滤波模式的概率只有35%-40%,这留下了很大的改进空间(RA和LD配置分别节省5.5%和8%的BD速率)。
基于以上讨论,我们使用记录在比特流中的更多块边界先验信息来训练我们的模型。众所周知,HEVC在压缩中采用可变大小的TU和CU。 通过率失真优化(RDO)选择大尺寸的CU和TU,以实现平滑区域,从而相应地生成少量残差信息。 在边缘或锐化区域中往往会产生大量的残差信息,通常选择较小的CU和TU。由于HEVC仅将DF应用于与PU或TU边界相邻的样本,因此在边缘或锐化区域中将更改更多像素,在平滑区域中将更改较少的像素。因此,我们在比特流中使用TU和CU的边界信息来进一步提高滤波器性能并确保模型的鲁棒性。 这种机制自适应地使我们的MLSDRN在阻塞边界上不平等地处理视频内容。
3 实验
3.1 执行
在实验中,我们使用了Hollywood2场景数据集[17],它是视频界最著名的数据集之一,有570个训练序列和582个测试序列。使用570个训练序列来训练我们的模型,对于每个序列,我们只取中间的30个连续帧,在AI、LD和RA配置下,用HM参考软件分别在22、27、32和37个不同的量化参数(QP s)下对每个视频进行压缩。对于每个QP,要训练出一个单独的网络,并且为了使模型更具鲁棒性,我们使用视频序列的更多时间信息,也就是说,我们分别使用QP ? 1,QP和QP +1提取训练数据进行每个QP模型的训练 。 我们仅在Y通道上训练模型并在三个YUV通道中恢复,但是我们的方法可以扩展到任意数量的通道。