
ЦцвьжЕЗжНтЕФЖЈвх
SVDЃЈSingular Value DecompositionЃЉПЩвдРэНтЮЊЃКНЋвЛИіБШНЯИДдгЕФОиеѓгУИќаЁИќМђЕЅЕФ3ИізгОиеѓЕФЯрГЫРДБэЪОЃЌет3ИіаЁОиеѓУшЪіСЫДѓОиеѓживЊЕФЬиадЁЃ
ЖЈвхЃКОиеѓЕФЦцвьжЕЗжНтЪЧжИНЋвЛИіжШЮЊ ЕФЪЕОиеѓ ЗжНтЮЊШ§ИіЪЕОиеѓГЫЛ§ЕФаЮЪНЃК
Цфжа ЪЧ Нзе§НЛОиеѓЃЈ ЕФСаЯђСПГЦЮЊзѓЦцвьЯђСПЃЉЃЌ ЪЧ Нзе§НЛОиеѓЃЈ ЕФСаЯђСПГЦЮЊгвЦцвьЯђСПЃЉЃЌ ЪЧ ОиаЮЖдНЧОиеѓЃЌГЦЮЊЦцвьжЕОиеѓЃЌЖдНЧЯпЩЯЕФдЊЫиГЦЮЊЦцвьжЕЁЃ
ЪЧвЛИі ЕФЖдНЧеѓЃЌ ЕФЖдНЧЯпдЊЫиЪЧ ЕФЧА ИіЦцвьжЕ ЃЈЗЧИКЃЌНЕађЃЉЁЃ
жЊЪЖЕуЃКШЮвтвЛИіЪЕОиеѓ ПЩвдгЩЦфЭтЛ§еЙПЊЪНБэЪО
Цфжа ЮЊ ОиеѓЃЌЪЧСаЯђСП КЭааЯђСП ЕФЭтЛ§ЃЌ ЮЊЦцвьжЕЃЌ ЭЈЙ§Оиеѓ ЕФЦцвьжЕЗжНтЕУЕНЁЃ
жЊЪЖЕуЃКЦцвьжЕдкОиеѓжаАДееДгДѓЕНаЁХХСаЃЌдкКмЖрЧщПіЯТЃЌЧА10%ЩѕжС1%ЕФЦцвьжЕЕФКЭОЭеМСЫШЋВПЕФЦцвьжЕжЎКЭЕФ99%вдЩЯЕФБШР§ЁЃЮвУЧПЩвдгУзюДѓЕФ ИіЦцвьжЕЕФОиеѓКЭ ЯрГЫРДНќЫЦУшЪіОиеѓЃЌДгЖјЪЕЯжСЫНЕЮЌЁЂМѕЩйЪ§ОнДцДЂЁЂЬсЩ§МЦЫуадФмЕШаЇЙћЁЃ
ЦцвьжЕЗжНтЕФМЦЫу
ЩшОиеѓ ЕФЦцвьжЕЗжНтЮЊ ЃЌдђга
МДЖдГЦОиеѓ КЭ ЕФЬиеїЗжНтПЩвдгЩОиеѓ ЕФЦцвьжЕЗжНтОиеѓБэЪОЁЃ
жЄУїЃК ЕФЬиеїжЕЗЧИКЁЃ
Сю ЪЧ ОиеѓЃЌФЧУД ЪЧЖдГЦОиеѓЧвПЩвде§НЛЖдНЧЛЏЃЌШУ ЪЧ ЕФЕЅЮЛе§НЛЛљЧвЙЙГЩ ЕФЬиеїЯђСПЃЌ ЪЧ ЖдгІЕФЬиеїжЕЃЌФЧУДЖд ЃЌ
Ыљвд ЕФЫљгаЬиеїжЕЖМЗЧИКЃЌШчЙћБивЊЃЌЭЈЙ§жиаТБрКХЮвУЧПЩвдМйЩшЬиеїжЕЕФжиаТХХСаТњзу
ЕФЦцвьжЕЪЧ ЕФЬиеїжЕЕФЦНЗНИљЃЌМЧЮЊ ЃЌЧвЫќУЧЕнМѕЫГађХХСаЁЃ
ПЩМћЃЌЖд НјааЦцвьжЕЗжНташвЊЧѓОиеѓ ЕФЬиеїжЕМАЦфЖдгІЕФБъзМе§НЛЕФЬиеїЯђСПРДЙЙГЩе§НЛОиеѓ ЕФСаЃЌЬиеїжЕ ЕФЦНЗНИљЕУЕНЦцвьжЕ$\sigma _ { i } \Sigma$ЁЃ
жЄУїЃКМйЩш ЪЧАќКЌ ЬиеїЯђСПЕФ ЩЯЕФБъзМе§НЛЛљЃЌжиаТећРэЪЙЕУЖдгІ ЕФЬиеїжЕТњзу ЁЃШє га ИіЗЧСуЦцвьжЕЃЌдђ ЪЧ ЕФвЛИіе§НЛЛљЃЌЧв ЁЃ
ЕБ ВЛЕШгк ЪБЃЌ ЁЃ
ЫљвдЃЌ ЪЧвЛИіе§НЛЛљЁЃгЩгкЯђСП ЕФГЄЖШЪЧ ЕФЦцвьжЕЃЌЧввђЮЊга ИіЗЧСуЦцвьжЕЃЌ ЮЊЗЧСуЯђСПЁЃЫљвд ЯпадЮоЙиЃЌЧвЪєгк ЁЃ
ЖдШЮвтЪєгк ЕФ ЃЌШч ЃЌЮвУЧПЩвдаДГі ЃЌЧв
етбљЃЌ дк жаЃЌетЫЕУї ЪЧ ЕФвЛИіе§НЛЛљЃЌвђДЫ ЁЃ
гЩгк ЪЧ ЕФвЛИіе§НЛЛљЃЌНЋУПвЛИі ЕЅЮЛЛЏЕУЕНвЛИіБъзМе§НЛЛљ ЃЌДЫДІ
НЋ РЉГфЮЊ ЕФЕЅЮЛе§НЛЛљ ЁЃ
ШЁ
гЩЙЙдьПЩжЊЃЌ КЭ ЪЧе§НЛОиеѓЃЌ
МДЃК ЃЌДгЖјЕУЕН ЁЃ
жЊЪЖЕуЃКШЮвтИјЖЈвЛИіЪЕОиеѓЃЌЦфЦцвьжЕЗжНтвЛЖЈДцдкЃЌЕЋВЂВЛЮЈвЛЁЃ
ЦцвьжЕЗжНтЕФЪЕЯж
1. ЪжЖЏЪЕЯж
# ЪЕЯжЦцвьжЕЗжНтЃЌ ЪфШывЛИіnumpyОиеѓЃЌЪфГі U, sigma, V
import numpy as np# ЛљгкОиеѓЗжНтЕФНсЙћЃЌИДдОиеѓ
def rebuildMatrix(U, sigma, V):a = np.dot(U, sigma)a = np.dot(a, np.transpose(V))return a# ЛљгкЬиеїжЕЕФДѓаЁЃЌЖдЬиеїжЕвдМАЬиеїЯђСПНјааЕЙађХХСаЁЃ
def sortByEigenValue(Eigenvalues, EigenVectors):index = np.argsort(-1 * Eigenvalues)Eigenvalues = Eigenvalues[index]EigenVectors = EigenVectors[:, index]return Eigenvalues, EigenVectors# ЖдвЛИіОиеѓНјааЦцвьжЕЗжНт
def SVD(matrixA, NumOfLeft=None):# NumOfLeftЪЧвЊБЃСєЕФЦцвьжЕЕФИіЪ§ЃЌвВОЭЪЧжаМфФЧИіЗНеѓЕФПэЖШ# ЪзЯШЧѓtranspose(A)*AmatrixAT_matrixA = np.dot(np.transpose(matrixA), matrixA)# ШЛКѓЧѓгвЦцвьЯђСПlambda_V, X_V = np.linalg.eig(matrixAT_matrixA)lambda_V, X_V = sortByEigenValue(lambda_V, X_V)# ЧѓЦцвьжЕsigmas = lambda_V# pythonРяКмаЁЕФЪ§гаЪБКђЪЧИКЪ§sigmas = list(map(lambda x: np.sqrt(x) if x > 0 else 0, sigmas))sigmas = np.array(sigmas)sigmasMatrix = np.diag(sigmas)if NumOfLeft is None:# Дѓгк0ЕФЬиеїжЕЕФИіЪ§rankOfSigmasMatrix = len(list(filter(lambda x: x > 0, sigmas)))else:rankOfSigmasMatrix = NumOfLeft# ЬиеїжЕЮЊ0ЕФЦцвьжЕОЭВЛвЊСЫsigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, :]# МЦЫузѓЦцвьЯђСП# ГѕЪМЛЏвЛИізѓЦцвьЯђСПОиеѓЃЌетРяжБНгНјааВУМєX_U = np.zeros((matrixA.shape[0], rankOfSigmasMatrix))for i in range(rankOfSigmasMatrix):X_U[:, i] = np.transpose(np.dot(matrixA, X_V[:, i]) / sigmas[i])# ЖдгвЦцвьЯђСПКЭЦцвьжЕОиеѓНјааВУМєX_V = X_V[:, 0:rankOfSigmasMatrix]sigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, 0:rankOfSigmasMatrix]return X_U, sigmasMatrix, X_VA = np.array([[4, 11, 14], [8, 7, -2]])
X_U, sigmasMatrix, X_V = SVD(A)
print(A)
# [[ 4 11 14]
# [ 8 7 -2]]print(X_U.shape) # (2, 2)
print(sigmasMatrix.shape) # (2, 2)
print(X_V.shape) # (3, 2)
print(rebuildMatrix(X_U, sigmasMatrix, X_V))
# [[ 4. 11. 14.]
# [ 8. 7. -2.]]
2. ЪЙгУnumpy.linalg.svdКЏЪ§
import numpy as npA = np.array([[4, 11, 14], [8, 7, -2]])
print(A)
# [[ 4 11 14]
# [ 8 7 -2]]u, s, vh = np.linalg.svd(A, full_matrices=False)
print(u.shape) # (2, 2)
print(s.shape) # (2,)
print(vh.shape) # (2, 3)a = np.dot(u, np.diag(s))
a = np.dot(a, vh)
print(a)
# [[ 4. 11. 14.]
# [ 8. 7. -2.]]
ЦцвьжЕЗжНтЕФгІгУ
1. Ъ§ОнбЙЫѕ
ЦцвьжЕЗжНтПЩвдгааЇЕиБэЪОЪ§ОнЁЃР§ШчЃЌМйЩшЮвУЧЯЃЭћДЋЪфЯТУцЕФЭМЯёЃЌЫќгЩвЛИі ИіКкЩЋЛђАзЩЋЯёЫизщГЩЕФЪ§зщЁЃ

гЩгкДЫЭМЯёжажЛгаШ§жжРраЭЕФСаЃЌШчЯТЭМЫљЪОЃЌвђДЫПЩвдгУИќНєДеЕФаЮЪНБэЪОЪ§ОнЁЃ
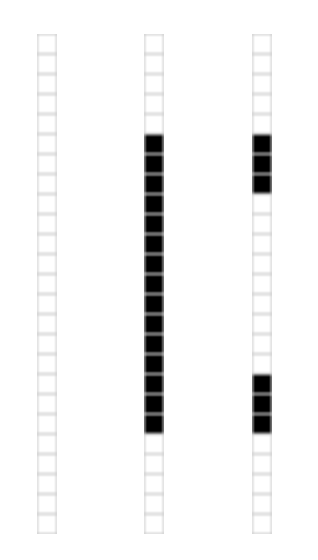
ЮвУЧНЋЭМЯёБэЪОЮЊвЛИі ОиеѓЃЌОиеѓЕФдЊЫиЖдгІзХЭМЯёЕФВЛЭЌЯёЫиЃЌШчЙћЯёЫиЪЧАзЩЋЕФЛАЃЌОЭШЁ 1ЃЌКкЩЋЕФОЭШЁ 0ЁЃ ЮвУЧЕУЕНСЫвЛИіОпга375ИідЊЫиЕФОиеѓЃЌШчЯТЭМЫљЪО

ШчЙћЖд НјааЦцвьжЕЗжНтЃЌЮвУЧЛсЗЂЯжжЛгаШ§ИіЗЧСуЦцвьжЕ ЃЈЗЧСуЦцвьжЕЕФЪ§ФПЕШгкОиеѓЕФжШЃЌдкетИіР§згжаЃЌЮвУЧПДЕНОиеѓжагаШ§ИіЯпадЮоЙиЕФСаЃЌетвтЮЖзХжШНЋЪЧ3ЃЉЁЃ
Опга15ИідЊЫиЃЌ Опга25ИідЊЫиЃЌ ЖдгІВЛЭЌЕФЦцвьжЕЁЃЮвУЧОЭПЩвдгУ123ИідЊЫиРДБэЪООпга375ИідЊЫиЕФЭМЯёЪ§ОнСЫЁЃЭЈЙ§етжжЗНЪНЃЌЦцвьжЕЗжНтПЩвдЗЂЯжОиеѓжаЕФШпгрЃЌВЂЬсЙЉЯћГ§ШпгрЕФИёЪНЁЃ
2. ШЅды
ЧАУцЕФР§згеЙЪОСЫШчКЮРћгУаэЖрЦцвьжЕЮЊСуЕФЧщПіЁЃвЛАуРДЫЕЃЌДѓЕФЦцвьжЕЖдгІЕФВПЗжЛсАќКЌИќЖрЕФаХЯЂЁЃМйЩшЮвУЧЪЙгУЩЈУшвЧНЋДЫЭМЯёЪфШыМЦЫуЛњЁЃЕЋЪЧЃЌЮвУЧЕФЩЈУшвЧЛсдкЭМЯёжав§ШывЛаЉШБЯнЃЈЭЈГЃГЦЮЊЁАдыЩљЁБЃЉЁЃ

ЮвУЧПЩвдгУЭЌбљЕФЗНЗЈНјааЃКгУвЛИі ОиеѓБэЪОЪ§ОнЃЌВЂжДааЦцвьжЕЗжНтЁЃЮвУЧЗЂЯжвдЯТЦцвьжЕЃК
ЯдШЛЃЌЧАШ§ИіЦцвьжЕЪЧзюживЊЕФЃЌЫљвдЮвУЧМйЩшЦфЫќЕФЖМЪЧгЩгкЭМЯёжаЕФдыЩљдьГЩЕФЃЌВЂНјааНќЫЦЁЃ
етЕМжТЯТУцЕФИФНјЭМЯёЁЃ

3. Ъ§ОнЗжЮі
ЮвУЧЫбМЏЕФЪ§ОнжазмЪЧДцдкдыЩљЃКЮоТлВЩгУЕФЩшБИЖрОЋУмЃЌЗНЗЈгаЖрКУЃЌзмЪЧЛсДцдквЛаЉЮѓВюЕФЁЃШчЙћФуУЧЛЙМЧЕУЩЯЮФЬсЕНЕФЃЌДѓЕФЦцвьжЕЖдгІСЫОиеѓжаЕФжївЊаХЯЂЕФЛАЃЌдЫгУSVDНјааЪ§ОнЗжЮіЃЌЬсШЁЦфжаЕФжївЊВПЗжЕФЛАЃЌЛЙЪЧЯрЕБКЯРэЕФЁЃ
МйЩшЮвУЧЪеМЏСЫвЛаЉЪ§ОнЃЌШчЯТЫљЪОЃК
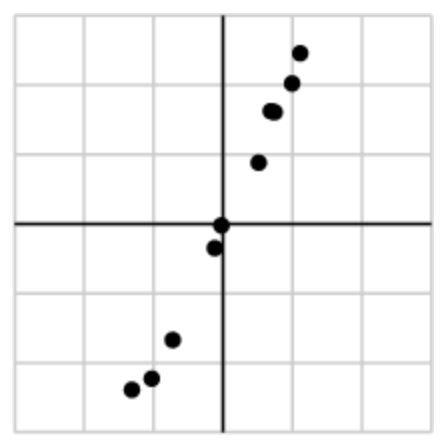
ЮвУЧПЩвдНЋЪ§ОнЗХШыОиеѓжаЃК
ОЙ§ЦцвьжЕЗжНтКѓЃЌЕУЕН ЁЃ
гЩгкЕквЛИіЦцвьжЕдЖБШЕкЖўИівЊДѓЃЌПЩвдМйЩш ЕФаЁжЕЪЧгЩгкЪ§ОнжаЕФдыЩљВњЩњЕФЃЌВЂЧвИУЦцвьжЕРэЯыЧщПіЯТгІЮЊСуЁЃдкетжжЧщПіЯТЃЌОиеѓЕФжШЮЊ1ЃЌвтЮЖзХЫљгаЪ§ОнЖМЮЛгк ЖЈвхЕФааЩЯЁЃ
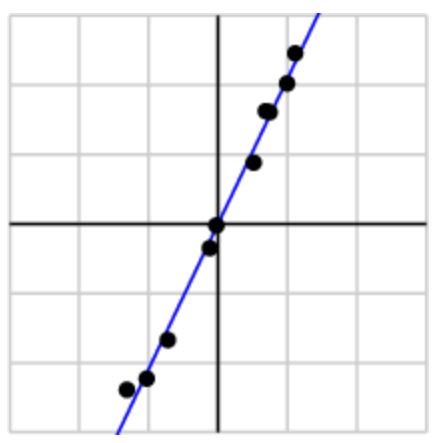
ВЮПМЮФЯз
- https://zhuanlan.zhihu.com/p/54693391
- http://www.ams.org/publicoutreach/feature-column/fcarc-svd