������Դ:Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers��8�� deeper than VGG nets [40] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
ժҪ
���������ѵ���������ӵ����ѡ����������һ��residual learning ģ��������������ѵ����Residualģ������������������x������ͨ������ֱ�������������ʵ��֤������Щ�в�����������Ż��������ڴ�������ӵ���ȵ�ͬʱ��֤���ȡ�������ImageNet���ݼ��϶�residual�������������������������ӵ���152�㣬��VGG������ȵ�8��������Ȼ���нϵ͵ĸ����ԡ���ImageNet���Լ��ϣ���Щ�в�����Ĵ�����Ϊ3.57%���ý����ILSVRC 2015���������һ�������ǻ���CIF AR-10��100���1000������˷�����
�Ժܶ��Ӿ�ʶ��������˵���������Ч��������DZȽ���Ҫ��ָ�ꡣ������COCOĿ�������ݼ��ϵ�ȷ��������28%������Ϊ���Ǽ���������������ILSVRC & COCO 2015������������Ȳв���������ͼ���⡢ͼ��λ��COCOĿ����ͷָ��һ���ĺóɼ���
1. Introduction
Deep convolutional neural networks [22, 21] have led to a series of breakthroughs for image classification [21, 49, 39]. Deep networks naturally integrate low/mid/highlevel features [49] and classifiers in an end-to-end multilayer fashion, and the ��levels�� of features can be enriched by the number of stacked layers (depth). Recent evidence [40, 43] reveals that network depth is of crucial importance, and the leading results [40, 43, 12, 16] on the challenging ImageNet dataset [35] all exploit ��very deep�� [40] models, with a depth of sixteen [40] to thirty [16]. Many other nontrivial visual recognition tasks [7, 11, 6, 32, 27] have also greatly benefited from very deep models.
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [14, 1, 8], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 8, 36, 12] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
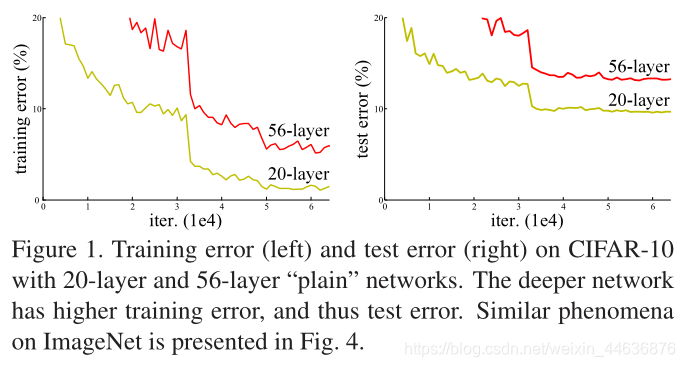
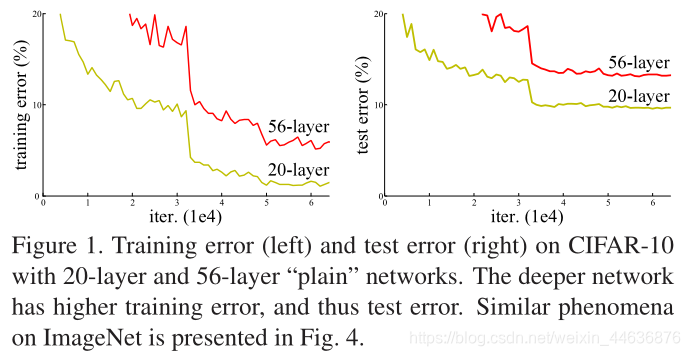
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [10, 41] and thoroughly verified by our experiments. Fig. 1 shows a typical example.
The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time).
In this paper, we address the degradation problem by introducing a deep residual learning framework. Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of
. The original mapping is recast into
. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
The formulation of
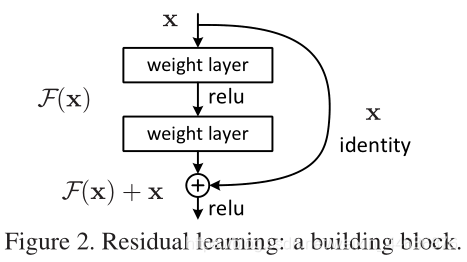
can be realized by feedforward neural networks with ��shortcut connections�� (Fig. 2). Shortcut connections [2, 33, 48] are those skipping one or more layers. In our case, the shortcut connections simply perform identity mapping, and their outputs are added to the outputs of the stacked layers (Fig. 2). Identity shortcut connections add neither extra parameter nor computational complexity. The entire network can still be trained end-to-end by SGD with backpropagation, and can be easily implemented using common libraries (e.g., Caffe [19]) without modifying the solvers.
We present comprehensive experiments on ImageNet [35] to show the degradation problem and evaluate our method. We show that: 1) Our extremely deep residual nets are easy to optimize, but the counterpart ��plain�� nets (that simply stack layers) exhibit higher training error when the depth increases; 2) Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks.
Similar phenomena are also shown on the CIFAR-10 set [20], suggesting that the optimization difficulties and the effects of our method are not just akin to a particular dataset. We present successfully trained models on this dataset with over 100 layers, and explore models with over 1000 layers.
On the ImageNet classification dataset [35], we obtain excellent results by extremely deep residual nets. Our 152layer residual net is the deepest network ever presented on ImageNet, while still having lower complexity than VGG nets [40]. Our ensemble has 3.57% top-5 error on the ImageNet test set, and won the 1st place in the ILSVRC 2015 classification competition. The extremely deep representations also have excellent generalization performance on other recognition tasks, and lead us to further win the 1st places on: ImageNet detection, ImageNet localization,COCO detection, and COCO segmentation in ILSVRC & COCO 2015 competitions. This strong evidence shows that the residual learning principle is generic, and we expect that it is applicable in other vision and non-vision problems.
1.����
��Ⱦ�����������ͼ�������ȡ���˺ܶ��ͻ�ơ��������ͨ��ͨ���˵��˵ķ�ʽ���͡��С����������ͷ�����������һ�𣬲��������ġ����𡱿���ͨ���ѵ��������(���)���ḻ�������ʵ�����ݱ������������������Ҫ����ImageNet��ս������ǰ�е�����ͨ����ȶ��Ƚ�������16-30������������������Ҫģ��Ҳ�кܴ�İ�����
�������Ⱥ���Ҫ����ͬʱҲ��������һ�����⣺��������ѧϰ����ѵ�����һ�����𣿴����֪������Խ����ܻᵼ���ݶ���ʧ��ը�����⣬����һ��ʼ�ͻ��谭���������������ͨ����ʼ�淶�����м�淶������ˣ�ʮ���������ܹ������������з�������ݶ��½�������
�������������ܹ���ʼ����ʱ���˻�������ͱ�¶�����ˣ�����������ȵ����ӣ����ȴﵽ���ͣ�����ܲ�����֣���Ȼ��Ѹ���½����������˻��������ɹ��������ģ��������ʵ������ģ�������Ӹ���IJ�ᵼ�¸��ߵ�ѵ�����Դ����ǽ����˴���ʵ����֤ʵ����һ�㡣ͼ1ʾ����һ������ʾ����
ѵ�����ȵ��½������������е����綼�����Ż���������˼��һ��һ��dz�����������Ӧ��������硣�������ģ�����ǿ�����dz��ģ�͵Ļ��������Ӻ��ӳ��㣬�������������IJ㣬������һ�� deeper ���硣���������磨shallower �� deeper���õ��Ľ��Ӧ����һģһ���ģ���Ϊ����ȥ�IJ㶼�� identity mapping���������Ǵ�dz��ģ���Ƶġ��������Եó�һ�����ۣ������ϣ���ѵ�����ϣ�Deeper ��Ӧ�ñ� shallower ���Խ������粻���dz�������Ч�����ʵ��������������ڿ��е�ʱ�����ҵ��ȹ������õĽ⡣
���ģ�����ͨ������һ����Ȳв�ģ����������˻����⡣�ٶ�ij��������������� x����������� H(x)���� H(x) �������ĸ���DZ��ӳ�䣬��ѧϰ�Ѷȴ��������ֱ�Ӱ����� x ���������Ϊ��ʼ�������ô��ʱ������Ҫѧϰ��Ŀ�����
������ ResNet �൱�ڽ�ѧϰĿ��ı��ˣ�������ѧϰһ��������������������Ž� H(X) ��ȫ��ӳ�� x �IJ�ֵ�����в�
�� �ڼ�������£����һ�����ӳ�������ŵģ���ô���в�Ϊ�����һ�ѷ����Բ�����Ϻ��ӳ��Ҫ���öࡣ
�Ĺ�ʽ����ͨ����shortcut connections��ǰ��������ʵ��(ͼ2)��shortcut connections������һ���������ӡ������ǵ������У�shortcut connectionsֻ��ִ�б�ʶӳ�䣬���ǵ���������ӵ��ѵ���������(ͼ2)����ʶshortcut connections�Ȳ����Ӷ���IJ�����Ҳ�����Ӽ��㸴�Ӷȡ�����������Ȼ����ͨ��SGD���ж˵��˵�ѵ�������ҿ���ʹ�ÿ������ʵ�֣����������������
������ImageNet�Ͻ�����ȫ���ʵ���������˻����Ⲣ�������ǵķ�����ʵ��������:1)����в�����������Ż�������ͨ���Ķѵ����������������ʱ���ֳ����ߵ�ѵ�����;2)�в�������������˾��ȣ������Ľ�����������ǰ�����硣
��CIFAR-10���ݼ���Ҳ�Dz��Ľ������������ǵķ����������������ض������ݼ������dzɹ���ѵ���˳���100�������ģ�ͣ�����̽���˳���1000�������ģ�͡�
�в�������ImageNet�������ݼ��ϵõ��˺ܺõĽ�������ǵ�152��в�������ImageNet������Ϊֹ��������磬ͬʱ���ȵ�VGG�����Ӷȵ͡�����������ImageNet���Լ���top-5�����Ϊ3.57%����ILSVRC 2015���ྺ���л���˵�һ�����������������������ʶ��������Ҳ�кܺõķ������ܣ���ILSVRC & COCO 2015��ı����У�ImageNet ���, ImageNet ��λ, COCO ���, COCO �ָ����˵�һ������Щ�������в�ģ����ͨ�õģ�����Ҳϣ�����������������Ӿ��ͷ��Ӿ����⡣
2. Related Work
Residual Representations. In image recognition, VLAD [18] is a representation that encodes by the residual vectors with respect to a dictionary, and Fisher Vector [30] can be formulated as a probabilistic version [18] of VLAD. Both of them are powerful shallow representations for image retrieval and classification [4, 47]. For vector quantization, encoding residual vectors [17] is shown to be more effective than encoding original vectors.
In low-level vision and computer graphics, for solving Partial Differential Equations (PDEs), the widely used Multigrid method [3] reformulates the system as subproblems at multiple scales, where each subproblem is responsible for the residual solution between a coarser and a finer scale. An alternative to Multigrid is hierarchical basis preconditioning [44, 45], which relies on variables that represent residual vectors between two scales. It has been shown [3, 44, 45] that these solvers converge much faster than standard solvers that are unaware of the residual nature of the solutions. These methods suggest that a good reformulation or preconditioning can simplify the optimization.
Shortcut Connections. Practices and theories that lead to shortcut connections [2, 33, 48] have been studied for a long time. An early practice of training multi-layer perceptrons (MLPs) is to add a linear layer connected from the network input to the output [33, 48]. In [43, 24], a few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients. The papers of [38, 37, 31, 46] propose methods for centering layer responses, gradients, and propagated errors, implemented by shortcut connections. In [43], an ��inception�� layer is composed of a shortcut branch and a few deeper branches.
Concurrent with our work, ��highway networks�� [41, 42] present shortcut connections with gating functions [15]. These gates are data-dependent and have parameters, in contrast to our identity shortcuts that are parameter-free. When a gated shortcut is ��closed�� (approaching zero), the layers in highway networks represent non-residual functions. On the contrary, our formulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned. In addition, highway networks have not demonstrated accuracy gains with extremely increased depth (e.g., over 100 layers).
2.��ع���
�в��ʾ����ͼ��ʶ���У�VLAD�Ǹ����ֵ�Բв��������б���ı�ʾ��Fisher�������Ա�ʾΪVLAD�ĸ��ʰ汾�����Ƕ���ͼ������ͷ����ǿ���dz���ʾ����������������������в������ȱ���ԭʼ��������Ч��
�ڵͼ��Ӿ��ͼ����ͼ��ѧ�У�Ϊ�����ƫ�ַ���(PDEs)���㷺ʹ�õĶ���������ϵͳ���»�Ϊ��߶��µ������⣬����ÿ�������⸺���ڽϴֳ߶Ⱥͽ�ϸ�߶�֮��IJв�⡣��һ���ⷨ�Ƿֲ����Ԥ�������ǻ��������߶ȵIJв���б�ʾ�ġ�ʵ���Ѿ�֤����ʹ�òв����Ȳ�ʹ�õ�Ҫ��öࡣ��Щ�о�������һ���õ�ģ���ع�����Ԥ�����ֶ����ܼ��Ż����̵ġ�
���������ʵ�������������ˡ�������ӡ�����뷨�������о��Ѿá������ڣ�ѵ������֪����mlp��������һ���������������ӵ���������Բ㡣[43��24]���ᵽ��һЩ�м��ֱ�����ӵ����������������ڴ�����ʧ/��ը�ݶȡ�[38��37��31��46]������������ÿ�����ӽ�����в���Ӧ���ݶȺʹ������ķ�������[43]�У�����ʼ������һ����ݷ�֧�ͼ�������ķ�֧��ɡ�
�����ǵĹ���ͬ�� ����Highway Networks�����ٹ�·�����ṩ�˾����ſع��ܵĿ�����ӡ���Щ�����������ݲ����в����������ǵĺ�������������ġ�����յĿ�ݷ�ʽ���رա����ӽ��㣩ʱ����·���еIJ�ͱ�ʾ�Dzв��������෴�����ǵĹ�ʽ����ѧϰ�в�������ӳ�䲻��رգ��������е���Ϣ����ͨ�����Խ����ѧϰ����IJв�������⣬�������粢û�б��ֳ���ȼ������ӣ����磬����100�㣩�Ծ�����ߵ����ܡ�
3. Deep Residual Learning
3.��Ȳв�ѧϰ
3.1. Residual Learning
Let us consider
as an underlying mapping to be fit by a few stacked layers (not necessarily the entire net), with x denoting the inputs to the first of these layers. If one hypothesizes that multiple nonlinear layers can asymptotically approximate complicated functions , then it is equivalent to hypothesize that they can asymptotically approximate the residual functions, i.e.,
(assuming that the input and output are of the same dimensions). So rather than expect stacked layers to approximate
, we explicitly let these layers approximate a residual function
. The original function thus becomes
. Although both forms should be able to asymptotically approximate the desired functions (as hypothesized), the ease of learning might be different.
This reformulation is motivated by the counterintuitive phenomena about the degradation problem (Fig. 1, left). As we discussed in the introduction, if the added layers can be constructed as identity mappings, a deeper model should have training error no greater than its shallower counterpart. The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers. With the residual learning reformulation, if identity mappings are optimal, the solvers may simply drive the weights of the multiple nonlinear layers toward zero to approach identity mappings.
In real cases, it is unlikely that identity mappings are optimal, but our reformulation may help to precondition the problem. If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one. We show by experiments (Fig. 7) that the learned residual functions in general have small responses, suggesting that identity mappings provide reasonable preconditioning.
3.1�в�ѧϰ
���ǰ� ������һ���ɶ���ѵ�����ɵĵײ�ӳ�䣬x��ʾ��Щ���е�һ��������롣��������������Բ���Խ����ƽ����Ӻ�������ô���൱�ڼ������ǿ��Խ����ƽ��в������ ��������������������ͬ��ά��������ˣ����Dz�ϣ���ѵ������H(x)��������ȷ������Щ�������һ��ʣ�ຯ�� ����ˣ�ԭʼ������� ��������������ʽ��Ӧ���ܹ������ؽ�������ĺ�����������������������ѧϰ�����׳̶ȿ��ܲ�ͬ��
3.2. Identity Mapping by Shortcuts
We adopt residual learning to every few stacked layers. A building block is shown in Fig. 2. Formally, in this paper we consider a building block defined as:
(1)
Here x and y are the input and output vectors of the layers considered. The function
represents the residual mapping to be learned. For the example in Fig. 2 that has two layers,
in which �� denotes ReLU [29] and the biases are omitted for simplifying notations. The operation F + x is performed by a shortcut connection and element-wise addition. We adopt the second nonlinearity after the addition (i.e., ��(y), see Fig. 2).
The shortcut connections in Eqn.(1) introduce neither extra parameter nor computation complexity. This is not only attractive in practice but also important in our comparisons between plain and residual networks. We can fairly compare plain/residual networks that simultaneously have the same number of parameters, depth, width, and computational cost (except for the negligible element-wise addition). The dimensions of x and F must be equal in Eqn.(1). If this is not the case (e.g., when changing the input/output channels), we can perform a linear projection Ws by the shortcut connections to match the dimensions:
(2)
We can also use a square matrix Ws in Eqn.(1). But we will show by experiments that the identity mapping is sufficient for addressing the degradation problem and is economical, and thus Ws is only used when matching dimensions.
The form of the residual function F is flexible. Experiments in this paper involve a function F that has two or three layers (Fig. 5), while more layers are possible. But if F has only a single layer, Eqn.(1) is similar to a linear layer:
, for which we have not observed advantages.
We also note that although the above notations are about fully-connected layers for simplicity, they are applicable to convolutional layers. The function
can represent multiple convolutional layers. The element-wise addition is performed on two feature maps, channel by channel.
3.2ͨ��������ӵĺ��ӳ��
���ǶԶ����вв�ѧϰ��ͼ2ʾ���˹����顣��ʽ�ϣ����ǿ��ǽ������鶨��Ϊ��
(1)
����x��y�������Dz��������������������
��ʾҪѧϰ��ʣ��ӳ�䡣����ͼ2���������ʾ����
�����Цұ�ʾReLU,ƫ�ʡ���Լ��š�����
��ͨ��һ��������Ӻ�Ԫ�ؼ��ӷ���ִ�еġ��ڼӷ�����������ʹ����һ�����������ӣ����ң�y������ͼ2����
��1��ʽ�еĿ�����ӣ��Ȳ�������������Ҳ��������㸴�Ӷȡ��ⲻ����һ�����������������������������DZȽ�plain����Ͳв�����ʱҲ����Ҫ�����ǿ��ԱȽ�ͬʱ������ͬ������������ȡ����Ⱥͼ���ɱ���plain����Ͳв����磨���˿ɺ��Ե�Ԫ�ؼӷ�����x��F��ά���ڵ�ʽ��1���б�����ȡ��������ͬ������, ���ı�������/�����ͨ���������ǿ���ͨ��shortcut����ִ��һ������ӳ��Ws ��ƥ�����ߵ�ά�ȣ�
(2)
����Ҳ������һ������Ws����ʾEq1������ʵ��֤�����ӳ�����Խ���˻����⣬�����Ǿ��õģ����Wsֻ��ƥ��ά��ʱʹ�á��в��F����ʽ�����ġ������е�ʵ���漰һ������������������ĺ���F��ͼ5�����������Ҳ�ǿ��Եġ������Fֻ��һ���㣬��ʽ��1�������������Բ㣺y=W1x+x����˲����������ơ����ǻ����ֲ����Ƕ���ȫ���Ӳ㣬���ھ�����Ҳ��ͬ�����õġ�����
���Ա�ʾ��������㣬����������ͼ��ͨ��֮��ִ��Ԫ�ؼ��ļӷ���
3.3. Network Architectures
We have tested various plain/residual nets, and have observed consistent phenomena. To provide instances for discussion, we describe two models for ImageNet as follows.
3.3����ṹ
�����ڶ��plain����Ͳв������Ͻ����˲��ԣ������۲��һ�µ������������ǽ���ImageNet�϶�����ģ�ͽ������ۡ�
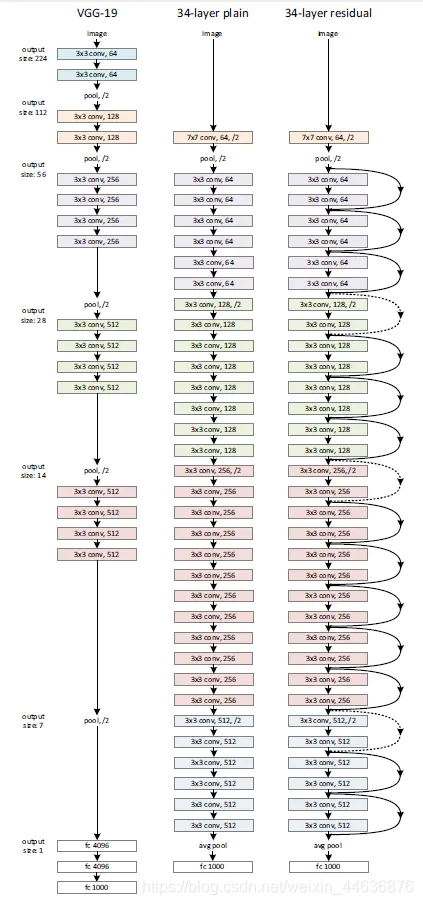
Plain Network. Our plain baselines (Fig. 3, middle) are mainly inspired by the philosophy of VGG nets [40] (Fig. 3, left). The convolutional layers mostly have 3��3 filters and follow two simple design rules: (i) for the same output feature map size, the layers have the same number of filters; and (ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. We perform downsampling directly by convolutional layers that have a stride of 2. The network ends with a global average pooling layer and a 1000-way fully-connected layer with softmax. The total number of weighted layers is 34 in Fig. 3 (middle).
It is worth noticing that our model has fewer filters and lower complexity than VGG nets [40] (Fig. 3, left). Our 34layer baseline has 3.6 billion FLOPs (multiply-adds), which is only 18% of VGG-19 (19.6 billion FLOPs).
plain���������ǵ�plain����ṹ��ͼ3���м䣩��Ҫ��VGG�����������ͼ3������������ҪΪ3��3���˲�������ѭ��������ƹ���i��������ͬ���������ӳ���С�����������ͬ�������˲�������ii���������ӳ���С���룬���˲��������ӱ����Ա���ÿ���ʱ�临�Ӷȡ�����ֱ��ͨ��2���ľ���������²�������������һ��ȫ��ƽ���ز��һ��1000·ȫ���Ӳ��softmax������ͼ3���м䣩�м�Ȩ�������Ϊ34��
ֵ��ע����ǣ����ǵ�ģ�ͱ�VGG�����˲������٣������Ը��͡���ͼ3����ͼ��������34��Ľṹ����36�ڸ�FLOPs����-�ӣ����������ֻ��VGG-19 ��196�ڸ�FLOPs����18%��
Residual Network. Based on the above plain network, we insert shortcut connections (Fig. 3, right) which turn the network into its counterpart residual version. The identity shortcuts (Eqn.(1)) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig. 3). When the dimensions increase (dotted line shortcuts
in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1��1 convolutions). For both
options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
�����
��������plain���磬���Dz��������ӣ�ͼ3����ͼ����������ת��Ϊ��Ӧ�IJв�汾������������������ͬ�ijߴ磨ͼ3�е�ʵ�߿�ݷ�ʽ��ʱ������ֱ��ʹ�ÿ�����ӣ�Eqn.��1��������ά������ʱ��ͼ3�е����߿�ݷ�ʽ�������ǿ�������������
��A����ݷ�ʽ��Ȼִ�к��ӳ�䣬��Ϊ����ά�����㡣�˷�����������������
��B�����ù�ʽ��2���е�ӳ���ݷ�ʽ��ʹά�� ����һ�£�ͨ��1��1������ɣ���
������������������shortcut��Խ���ֳߴ������ͼʱ����ʹ��strideΪ2�ľ�����
3.4. Implementation
Our implementation for ImageNet follows the practice in [21, 40]. The image is resized with its shorter side randomly sampled in [256,480] for scale augmentation [40].A 224��224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted [21]. The standard color augmentation in [21] is used. We adopt batch normalization (BN) [16] right after each convolution and before activation, following [16]. We initialize the weights as in [12] and train all plain/residual nets from scratch. We use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 10 when the error plateaus,and the models are trained for up to 60��104iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout [13], following the practice in [16].
In testing, for comparison studies we adopt the standard 10-crop testing [21]. For best results, we adopt the fully-convolutional form as in [40, 12], and average the scores at multiple scales (images are resized such that the shorter side is in {224,256,384,480,640}).
3.4Ӧ��
���Ƕ�ImageNet��ʵ����ѭ��Krizhevsky2012ImageNet
��Simonyan2014Very�е�ʵ��������ͼ��Ĵ�Сʹ���Ķ̱߳�������Ĵ�[256,480] �в���������ͼ��ijߴ硣��ͼ�����ˮƽ��ת�������ȡ224��224��С��ͼ����ȥÿ�����ص�ƽ��ֵ��ͼ��ʹ�ñ���ɫ��ǿ����ÿ�ξ�����ͼ���ǰ����������������BN��������K. He2015�еķ�����ʼ��Ȩ�أ�����ͷ��ʼѵ�����е�plain����Ͳв����硣ʹ��SGD����С����Ϊ256��ѧϰ�ʴ�0.1��ʼ��ÿ���������ƽ��ʱ����10��ģ��ѵ������
�Ρ�ʹ��0.0001������˥����0.9�Ķ��������Ҳ�ʹ��dropout���ڲ����У�Ϊ�˽��бȽϣ����Dz�ȡ����10-crop���ԡ�Ϊ�˻����ѽ�������Dz���Krizhevsky2012ImageNet��K. He2015�е�ȫ������ʽ�����ڶ���߶��϶Է�������ƽ��������ͼ���С��ʹ�̱�λ��{224��256��384��480��640}����
4. Experiments
4.ʵ��
4.1. ImageNet Classification
We evaluate our method on the ImageNet 2012 classification dataset [35] that consists of 1000 classes. The models are trained on the 1.28 million training images, and evaluated on the 50k validation images. We also obtain a final result on the 100k test images, reported by the test server. We evaluate both top-1 and top-5 error rates.
4.1. ImageNet ����
�����ڰ���1000�����ImageNet 2012�������ݼ����������ǵķ�����ѵ������128����ͼ���Լ���5����ͼ��������10����ͼ���Ͻ��в��ԣ�����top-1��top-5 �Ĵ����ʽ���������
Plain Networks. We first evaluate 18-layer and 34-layer plain nets. The 34-layer plain net is in Fig. 3 (middle). The 18-layer plain net is of a similar form. See Table 1 for detailed architectures.
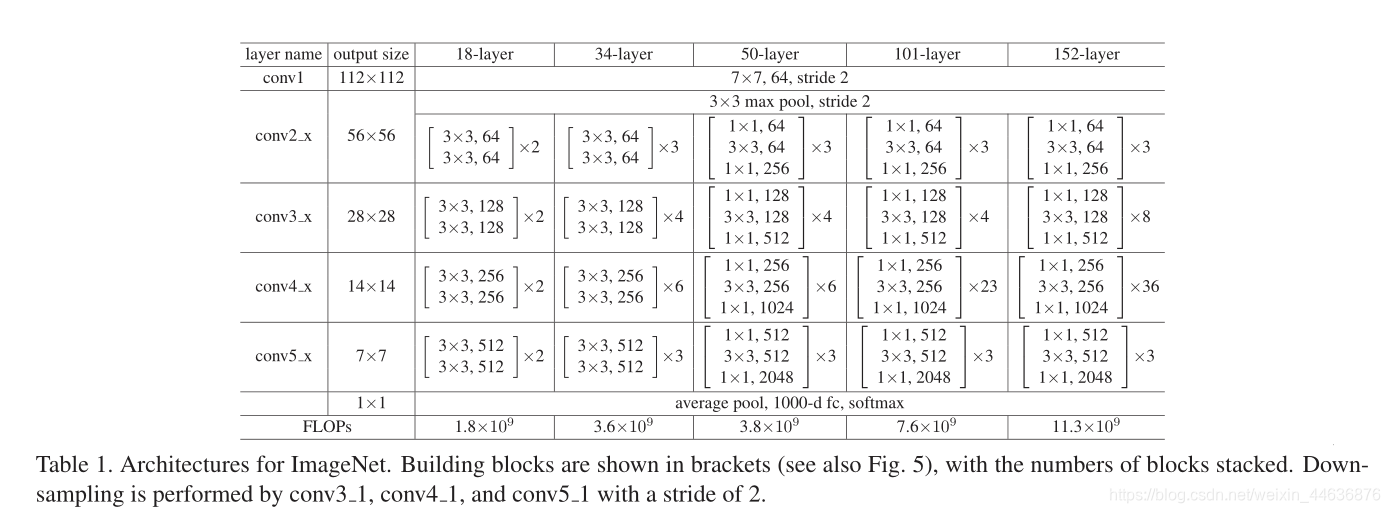
The results in Table 2 show that the deeper 34-layer plain net has higher validation error than the shallower 18-layer plain net. To reveal the reasons, in Fig. 4 (left) we compare their training/validation errors during the training procedure. We have observed the degradation problem - the 34-layer plain net has higher training error throughout the whole training procedure, even though the solution space of the 18-layer plain network is a subspace of that of the 34-layer one.
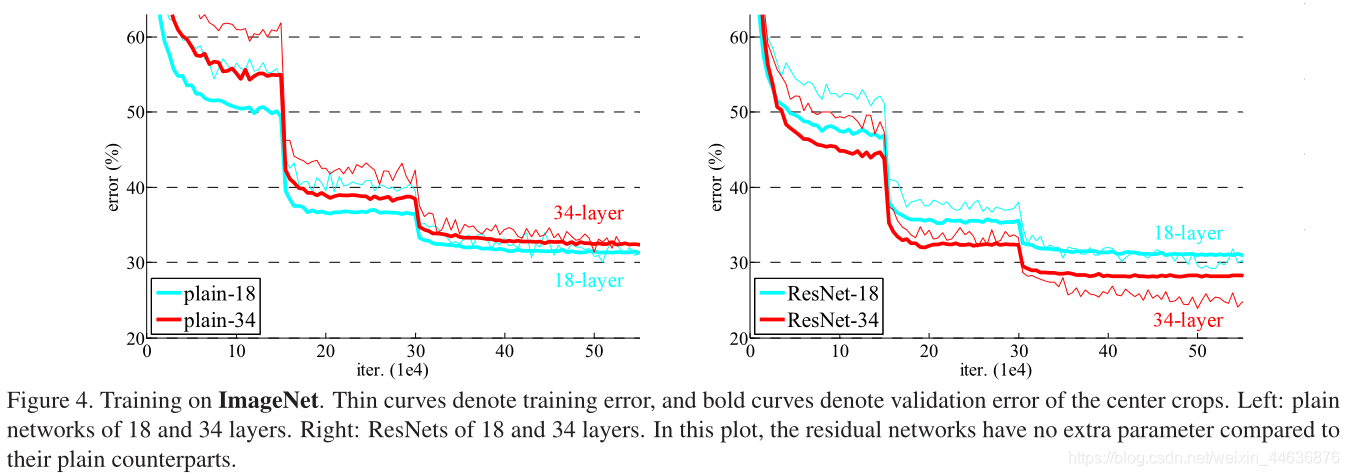
We argue that this optimization difficulty is unlikely to be caused by vanishing gradients. These plain networks are trained with BN [16], which ensures forward propagated signals to have non-zero variances. We also verify that the backward propagated gradients exhibit healthy norms with BN. So neither forward nor backward signals vanish. In fact, the 34-layer plain net is still able to achieve competitive accuracy (Table 3), suggesting that the solver works to some extent. We conjecture that the deep plain nets may have exponentially low convergence rates, which impact the reducing of the training error . The reason for such optimization difficulties will be studied in the future.
��������18���34��plain���硣ͼ3���У�Ϊ34��plain���硣18��plain������ʽ���ơ�����ܹ�����1��
Table 2��չʾ�Ľ��������34��������18���������и��ߵ���֤�����ʡ�Ϊ�˽�ʾ�������������ԭ����Fig.4(��)�����DZȽ�������ѵ�������е�ѵ������֤�����ʡ��ӽ�������ǹ۲�����Ե��˻����⡪��������ѵ��������34 ���������и��ߵ�ѵ�������ʣ���ʹ18������Ľ�ռ�Ϊ34���ռ��һ���ӿռ䡣
������Ϊ�����Ż����Ѳ�̫���������ݶ���ʧ����ġ�ѵ��plain����ʱʹ��BN�����ܱ�֤ǰ�ݵ��ź��Ǿ��з��㷽��ġ����ǻ���֤�˷������ݶ���BN�������õĹ淶�ԡ�����ǰ���ͷ������źŶ�������ʧ��ʵ���ϣ�34��plain������Ȼ�ܹ��ﵽ�����ľ��ȣ���3����������������һ���̶��������á������Ʋ�����plain�������������ָ��˥���ģ�����ܻ�Ӱ��ѵ�����Ľ��͡����������Ż����ǽ����Ժ�����о���
Residual Networks. Next we evaluate 18-layer and 34layer residual nets (ResNets). The baseline architectures are the same as the above plain nets, expect that a shortcut connection is added to each pair of 3��3 filters as in Fig. 3 (right). In the first comparison (Table 2 and Fig. 4 right), we use identity mapping for all shortcuts and zero-padding for increasing dimensions (option A). So they have no extra parameter compared to the plain counterparts.
We have three major observations from Table 2 and Fig. 4. First, the situation is reversed with residual learning �C the 34-layer ResNet is better than the 18-layer ResNet (by 2.8%). More importantly, the 34-layer ResNet exhibits considerably lower training error and is generalizable to the validation data. This indicates that the degradation problem is well addressed in this setting and we manage to obtain accuracy gains from increased depth.
Second, compared to its plain counterpart, the 34-layer ResNet reduces the top-1 error by 3.5% (Table 2), resulting from the successfully reduced training error (Fig. 4 right vs. left). This comparison verifies the effectiveness of residual learning on extremely deep systems.
Last, we also note that the 18-layer plain/residual nets are comparably accurate (Table 2), but the 18-layer ResNet converges faster (Fig. 4 right vs. left). When the net is ��not overly deep�� (18 layers here), the current SGD solver is still able to find good solutions to the plain net. In this case, the ResNet eases the optimization by providing faster convergence at the early stage.
�в���������������������18���34��в����磨ResNets����ResNets�ܹ���plain������ͬ��ֻ����ÿ��3��3�˲�����������һ��������ӣ���ͼ3����ͼ����ʾ���ڵ�һ���Ƚ��У���2��ͼ4��ͼ�������Ƕ����п�ݷ�ʽʹ�ú��ӳ�䣬���ӵ�ά��ʹ������䣨ѡ��A������ˣ�����ͨ��������ȣ�û�����Ӷ���IJ�������2��ͼ4����������������Ҫ�Ĺ۲��������ȣ�ͨ���в�ѧϰŤת�������������34��ResNet��18��ResNet�ã�2.8%��������Ҫ���ǣ�34��ResNet��ʾ���൱�͵�ѵ�������ҿ����ƹ㵽��֤�����С������������������£��˻�����õ��˺ܺõĽ���������跨����������л�þ������档
�ڶ�������ͨ��34�����ResNet top-1���������3.5%����2������Ϊѵ���������� ��ͼ4���������ֱȽ���֤�˲в�ѧϰ�ڼ���ϵͳ�ϵ���Ч�ԡ�
������ǻ�ע�18��plain����Ͳв�����ȷ�ʲ�ࣨ��2������18��ResNet�������죨ͼ4�Ҷ��������硰��̫���������18�㣩ʱ�����е�SGD�ܹ��ܺõĶ�plain���������⣬��ResNet�ܹ�ʹ�Ż��õ������������
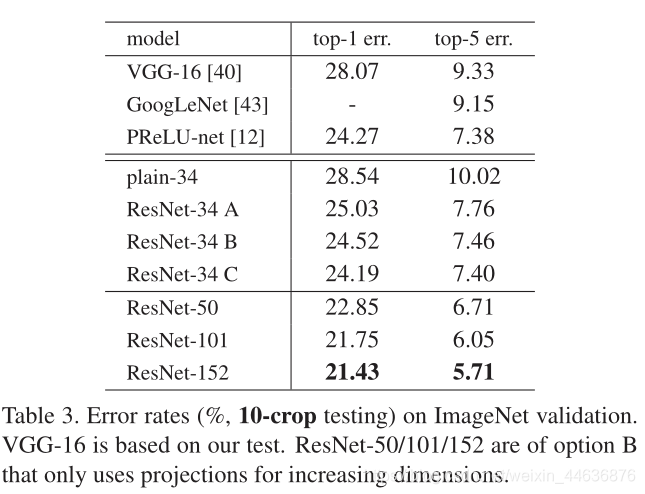
Identity vs. Projection Shortcuts. We have shown that parameter-free, identity shortcuts help with training. Next we investigate projection shortcuts (Eqn.(2)). In Table 3 we compare three options: (A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameterfree (the same as Table 2 and Fig. 4 right); (B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity; and ? all shortcuts are projections.
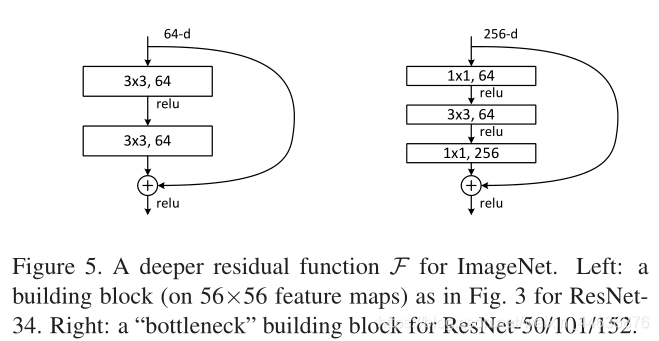
Table 3 shows that all three options are considerably better than the plain counterpart. B is slightly better than A. We argue that this is because the zero-padded dimensions in A indeed have no residual learning. C is marginally better than B, and we attribute this to the extra parameters introduced by many (thirteen) projection shortcuts. But the small differences among A/B/C indicate that projection shortcuts are not essential for addressing the degradation problem. So we do not use option C in the rest of this paper, to reduce memory/time complexity and model sizes. Identity shortcuts are particularly important for not increasing the complexity of the bottleneck architectures that are introduced below.
���vsӳ��������
�Ѿ���֤�������ĺ�ȿ��������������ѵ���ġ������������о�ӳ�������ӷ�ʽ��Eqn.��2�������ڱ�3�У����DZȽ�������ѡ�
��A��������ݼ���������ά�ȣ��������п�����Ӷ��������ģ����2��ͼ4����ͬ����
��B�����ӵ�ά��ʹ��ӳ�������ӣ�������ʹ�ú�ȿ�����ӣ�
��C��������ӳ�������ӡ�
��3��ʾ�������ַ�������plainģ�ͺõöࡣB�Ժ���A��������Ϊ������ΪA�е�0��䲢û�н��вв�ѧϰ��C������B�����ǽ�������ڶ��ӳ�������������˶������������A/B/C֮���ϸ��������ӳ���ݷ�ʽ���ڽ���˻����ⲻ�DZ���ġ���ˣ��ڱ��ĵ����ಿ���У����Dz�ʹ��ѡ��C�������ڴ�/ʱ�临���Ժ�ģ�ʹ�С����ȿ�����Ӷ��ڲ�����������ܵ�ƿ����ϵ�ṹ�ĸ������ر���Ҫ��
Deeper Bottleneck Architectures. Next we describe our deeper nets for ImageNet. Because of concerns on the training time that we can afford, we modify the building block as a bottleneck design . For each residual function F, we use a stack of 3 layers instead of 2 (Fig. 5). The three layers are 1��1, 3��3, and 1��1 convolutions, where the 1��1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3��3 layer a bottleneck with smaller input/output dimensions. Fig. 5 shows an example, where both designs have similar time complexity.
The parameter-free identity shortcuts are particularly important for the bottleneck architectures. If the identity shortcut in Fig. 5 (right) is replaced with projection, one can show that the time complexity and model size are doubled, as the shortcut is connected to the two high-dimensional ends. So identity shortcuts lead to more efficient models for the bottleneck designs.
50-layer ResNet: We replace each 2-layer block in the 34-layer net with this 3-layer bottleneck block, resulting in a 50-layer ResNet (Table 1). We use option B for increasing dimensions. This model has 3.8 billion FLOPs.
101-layer and 152-layer ResNets: We construct 101layer and 152-layer ResNets by using more 3-layer blocks (Table 1). Remarkably, although the depth is significantly increased, the 152-layer ResNet (11.3 billion FLOPs) still has lower complexity than VGG-16/19 nets (15.3/19.6 billion FLOPs).
The 50/101/152-layer ResNets are more accurate than the 34-layer ones by considerable margins (Table 3 and 4). We do not observe the degradation problem and thus enjoy significant accuracy gains from considerably increased depth. The benefits of depth are witnessed for all evaluation metrics (Table 3 and 4).
���ƿ���ṹ
�����������ǽ�����ImageNet��������硣���ڶ�ѵ��ʱ��Ŀ��ǣ����ǽ���������Ϊƿ����ơ�����ÿ��ʣ�ຯ��F������ʹ��3�������2��Ķ�ջ��ͼ5������������ֱ���1��1��3��3��1��1����������1��1�㸺�����Ȼ�����ӣ��ָ���ά�ȣ�ʹ3��3���Ϊ����/���ά����С��ƿ����ͼ5ʾ����������ƾ������Ƶ�ʱ�临�Ӷȡ�
������ȿ�����Ӷ���ƿ����ϵ�ṹ��Ϊ��Ҫ�������ͼ5���ң��еĺ�ȿ�������滻Ϊӳ�������ӣ�ģ�͵�ʱ�临�ӶȺ�ʱ�临�Ӷȶ���ӱ�����Ϊ������ӵ���������ά�ˡ����Ժ�����Ӷ���ƿ������Ǹ�����Ч�ġ�
50��ResNet�����ǽ�34��������2���ģ���滻��3���ƿ��ģ�飬����ģ��Ҳ�ͱ����50���ResNet (Table 1)���������ӵ�ά������ʹ��ѡ��B������������ģ�ͺ���38�ڸ�FLOPs��
101���152��resnet������ʹ�ø����3��鹹��101���152��ResNet����1����ֵ��ע����ǣ���������������ӣ���152��ResNet��113�ڸ�FLOPs����Ȼ��VGG-16/19���磨153/196�ڸ�FLOPs���ĸ��Ӷȵ͡�
50/101/152��ResNet��34��ResNet���ȸ߳��൱�ࣨ��3�ͱ�4������������û�й۲쵽�˻����⣬�������ü�����ԶԾ��������Ϻõ�Ч������ȵĺô�����������ָ���ж������֣���3�ͱ�4����
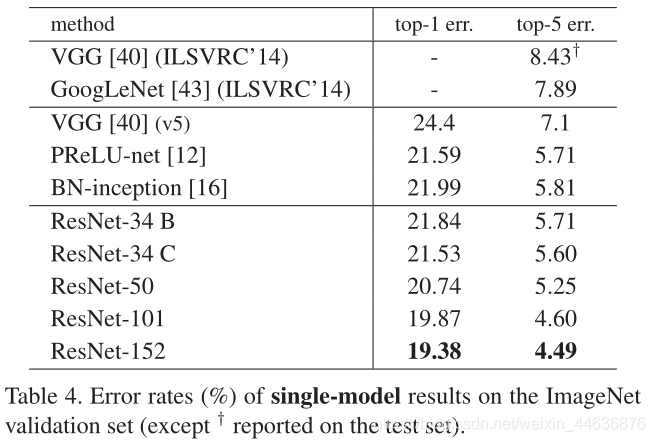
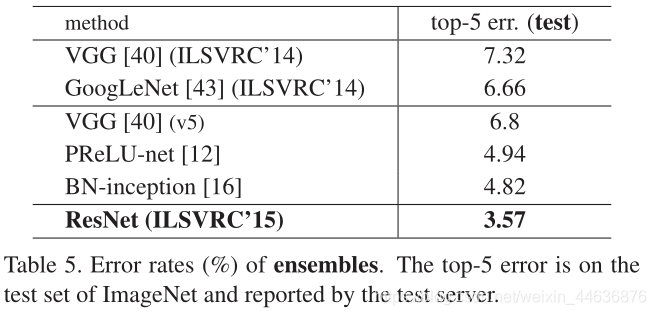
Comparisons with State-of-the-art Methods. In Table 4 we compare with the previous best single-model results. Our baseline 34-layer ResNets have achieved very competitive accuracy. Our 152-layer ResNet has a single-model top-5 validation error of 4.49%. This single-model result outperforms all previous ensemble results (Table 5). We combine six models of different depth to form an ensemble (only with two 152-layer ones at the time of submitting). This leads to 3.57% top-5 error on the test set (Table 5). This entry won the 1st place in ILSVRC 2015.
�����Ƚ������ıȽ����ڱ�4�У����ǽ���֮ǰ����ѵ�ģ�ͽ�����бȽϡ����ǵ�34��ResNets �Ѿ��ﵽ�˷dz��о�������ȷ�ԡ�152��ResNet TOP-5��֤����Ϊ4.49%������������������ǰ�ļ��Ͻ������5�������ǽ�6����ͬ��ȵ�ResNets�ϳ�һ�����ģ��(���ύ���ʱֻ�õ�2��152���ģ��)�����ڲ��Լ��ϵ�top-5�����ʽ�Ϊ3.57% (��5)����һ����ILSVRC 2015 �ϻ���˵�һ���ijɼ���
4.2. CIFAR-10 and Analysis
We conducted more studies on the CIFAR-10 dataset [20], which consists of 50k training images and 10k testing images in 10 classes. We present experiments trained on the training set and evaluated on the test set. Our focus is on the behaviors of extremely deep networks, but not on pushing the state-of-the-art results, so we intentionally use simple architectures as follows.
The plain/residual architectures follow the form in Fig. 3 (middle/right). The network inputs are 32��32 images, with the per-pixel mean subtracted. The first layer is 3��3 convolutions. Then we use a stack of 6n layers with 3��3 convolutions on the feature maps of sizes {32,16,8} respectively, with 2n layers for each feature map size. The numbers of filters are {16,32,64} respectively. The subsampling is performed by convolutions with a stride of 2. The network ends with a global average pooling, a 10-way fully-connected layer, and softmax. There are totally 6n+2 stacked weighted layers. The following table summarizes the architecture:

When shortcut connections are used, they are connected to the pairs of 3��3 layers (totally 3n shortcuts). On this dataset we use identity shortcuts in all cases (i.e., option A),so our residual models have exactly the same depth, width, and number of parameters as the plain counterparts.
We use a weight decay of 0.0001 and momentum of 0.9, and adopt the weight initialization in [12] and BN [16] but with no dropout. These models are trained with a minibatch size of 128 on two GPUs. We start with a learning rate of 0.1, divide it by 10 at 32k and 48k iterations, and terminate training at 64k iterations, which is determined on a 45k/5k train/val split. We follow the simple data augmentation in [24] for training: 4 pixels are padded on each side, and a 32��32 crop is randomly sampled from the padded image or its horizontal flip. For testing, we only evaluate the single view of the original 32��32 image.
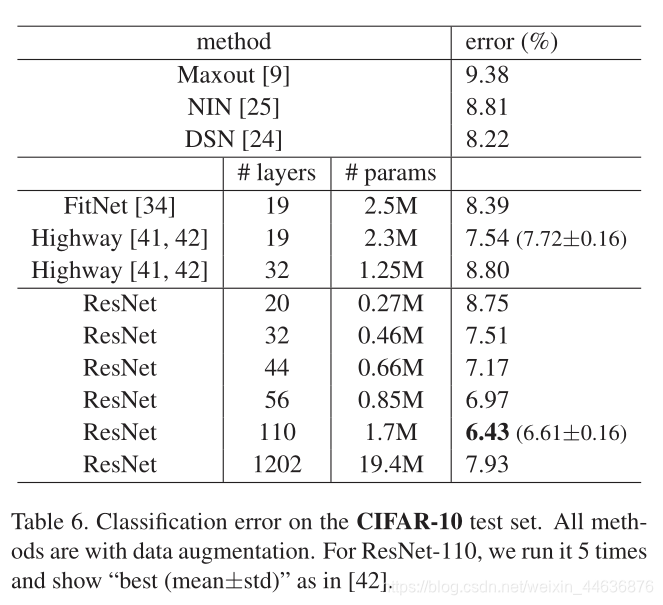
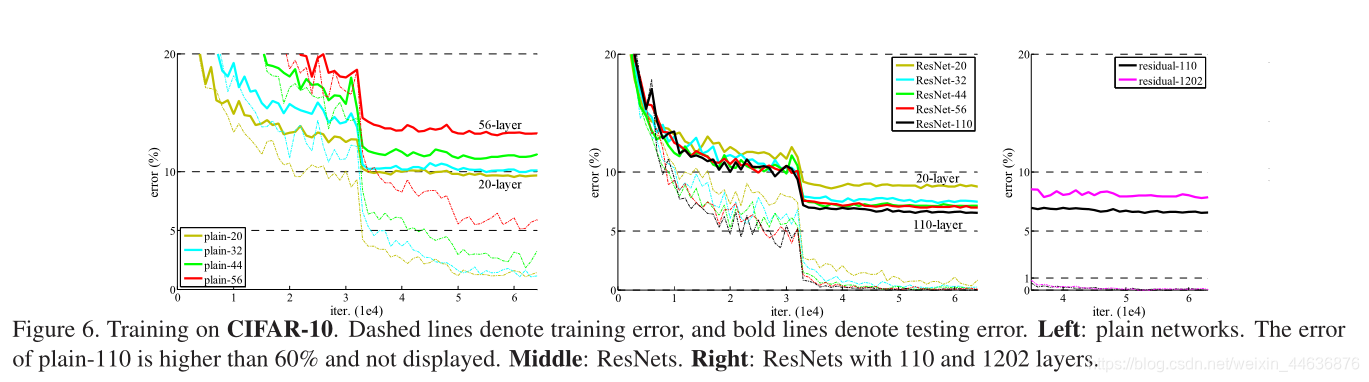
We compare n = {3,5,7,9}, leading to 20, 32, 44, and 56-layer networks. Fig. 6 (left) shows the behaviors of the plain nets. The deep plain nets suffer from increased depth, and exhibit higher training error when going deeper. This phenomenon is similar to that on ImageNet (Fig. 4, left) and on MNIST (see [41]), suggesting that such an optimization difficulty is a fundamental problem.
Fig. 6 (middle) shows the behaviors of ResNets. Also similar to the ImageNet cases (Fig. 4, right), our ResNets manage to overcome the optimization difficulty and demonstrate accuracy gains when the depth increases.
We further explore n = 18 that leads to a 110-layer ResNet. In this case, we find that the initial learning rate of 0.1 is slightly too large to start converging . So we use 0.01 to warm up the training until the training error is below 80% (about 400 iterations), and then go back to 0.1 and continue training. The rest of the learning schedule is as done previously. This 110-layer network converges well (Fig. 6, middle). It has fewer parameters than other deep and thin networks such as FitNet [34] and Highway [41] (Table 6), yet is among the state-of-the-art results (6.43%, Table 6).
4.2. CIFAR-10����
���Ƕ�CIFAR-10���ݼ������˸�����о��������ݼ�����10���࣬ѵ����5����ͼ���Լ�1����ͼ��������ѵ������ѵ�������ڲ��Լ��Ͻ��������������ǹ�ע������֤����ģ�͵�Ч��������������õĽ�����������ֻʹ�üĿ�����¡�Plain����Ͳв�����Ŀ���� Fig.3(��/��)��ʾ�������������
�ļ������ؾ�ֵ��ͼ��һ����
�ľ����㡣Ȼ������ʹ��6n��
�ľ�����Ķѵ����������Ӧ������ͼ�����֣�{32,16,8}��ÿһ�־����������Ϊ2n ������Ӧ���˲��������ֱ�Ϊ{16,32,64}��ʹ��strdeΪ2�ľ���������²�����������������һ��ȫ�ֵ�ƽ��pooling���һ��10��İ���softmax��ȫ���Ӳ㡣һ����6n+2���ѵ��ļ�Ȩ�㡣����Ľṹ���±���

��ʹ�ÿ�ݷ�ʽ����
������ԣ���3n��������ӣ�����������ݼ��У���������������¶�ʹ�ú�ȿ�����ӷ�ʽ����ѡ��A������ˣ����ǵIJв�ģ�;�����plainģ����ȫ��ͬ����ȡ����ȺͲ���������������K. He2015�е�Ȩֵ��ʼ���Լ�BN�����Dz�ʹ��Dropout��mini-batch�Ĵ�СΪ128��ģ����2��GPU �Ͻ���ѵ�������Ǵ�0.1��ѧϰ�ʿ�ʼ���ڵ�32k��48k�ε���ʱ����10����ѵ������Ϊ64k�����Ǹ���45k/5kѵ����/val����ȷ���ġ�����ʹ�ü��������䷽������ѵ����ÿ�����4�����أ������ͼ�����ˮƽ��ת������ü�
��Сͼ��Ϊ�˲��ԣ�����ֻ����ԭʼ
ͼ��ĵ�����ͼ��
���DZȽ���n={3,5,7,9}����20��32��44��56�����硣ͼ6������ʾ��plain����Ľ��������Խ��plain�����ѵ�����Խ����������������ImageNet��ͼ4����ͼ����MNIST������������Ż�������һ���������⡣ͼ6���м䣩��ʾ��ResNet�Ľ����ͬ��������ImageNet�����ӣ�ͼ4����ͼ����ResNet�跨�˷����Ż������ѣ�����֤����������ȵ����ӣ����ȵõ�����ߡ�
���ǽ�һ���о�n=18���������ʱResNet��110�㡣����������£����Ƿ��ֳ�ʼѧϰ��0.1����ʼ����������������0.01Ԥ��ѵ��ֱ��ѵ�����С��80%����Լ400�ε�������Ȼ��ص�0.1����ѵ����ʣ���ѧϰ��֮ǰ��һ�������110�����������Ժܺã�ͼ6���м䣩���������������խģ�ͣ���FitNet�� Highway (��6)��ȣ����и��ٵIJ�����Ȼ��ȴ�ﵽ����õĽ�� (6.43%, �� 6)��
Analysis of Layer Responses. Fig. 7 shows the standard deviations (std) of the layer responses. The responses are the outputs of each 3��3 layer, after BN and before other nonlinearity (ReLU/addition). For ResNets, this analysis reveals the response strength of the residual functions. Fig. 7 shows that ResNets have generally smaller responses than their plain counterparts. These results support our basic motivation (Sec.3.1) that the residual functions might be generally closer to zero than the non-residual functions. We also notice that the deeper ResNet has smaller magnitudes of responses, as evidenced by the comparisons among ResNet-20, 56, and 110 in Fig. 7. When there are more layers, an individual layer of ResNets tends to modify the signal less.

����Ӧ����
ͼ7��ʾ�˲���Ӧ�ı�ƫ�std������Ӧ��ÿ��3��3 BN֮������������Ժ�����ReLU/addition��֮ǰ�����������ResNets������������Ҳ��ʾ�˲в������Ӧǿ�ȡ�ͼ7ʾ��ResNetͨ�������ǵ�plain������и�С����Ӧ����Щ�����֤�����ǵĻ�����������3.1�ڣ������в�����ܱȷDzв�����ӽ���0�����ǻ�ע������ResNet���н�С����Ӧ������ͼ7��ResNet-20��56��110�����и����ʱ������ResNet�������ڼ����źŵ��ġ�
Exploring Over 1000 layers. We explore an aggressively deep model of over 1000 layers. We set n = 200 that leads to a 1202-layer network, which is trained as described above. Our method shows no optimization difficulty, and this 103-layer network is able to achieve training error <0.1% (Fig. 6, right). Its test error is still fairly good (7.93%, Table 6).
But there are still open problems on such aggressively deep models. The testing result of this 1202-layer network is worse than that of our 110-layer network, although both have similar training error. We argue that this is because of overfitting. The 1202-layer network may be unnecessarily large (19.4M) for this small dataset. Strong regularization such as maxout [9] or dropout [13] is applied to obtain the best results ([9, 25, 24, 34]) on this dataset. In this paper, we use no maxout/dropout and just simply impose regularization via deep and thin architectures by design, without distracting from the focus on the difficulties of optimization. But combining with stronger regularization may improve results, which we will study in the future.


̽������1000������
����̽����һ������1000������ģ�͡����ǽ���n=200����1202�����磬�����簴������ʽѵ�����������
����������ͬ���ܹ��Ż��������ܹ��ﵽѵ�����<0.1%��ͼ6����ͼ���������������൱�ã�7.93%����6����
�����ּ����ģ�ͣ���Ȼ����һЩ�����Ե����⡣��1202������IJ��Խ�������ǵ�110������IJ��Խ��Ҫ���Ȼ����ѵ������ࡣ������Ϊ������Ϊ����ϡ�1202������������С���ݼ���˵����̫���ˣ�19.4M�����ڸ����ݼ���ʹ��ǿ������maxout��dropout���Ż������ѽ�����ڱ����У�����û��ʹ��maxout��dropout��ֻ��ͨ����Ƽ�ͨ�����խģ��ʵʩ����������ɢ���Ż����ѵĹ�ע�����ǽ����Ժ��о���ϸ�ǿ�����Խ����������á�
4.3. Object Detection on PASCAL and MS COCO
Our method has good generalization performance on other recognition tasks. Table 7 and 8 show the object detection baseline results on PASCAL VOC 2007 and 2012 [5] and COCO [26]. We adopt Faster R-CNN [32] as the detection method. Here we are interested in the improvements of replacing VGG-16 [40] with ResNet-101. The detection implementation (see appendix) of using both models is the same, so the gains can only be attributed to better networks. Most remarkably, on the challenging COCO dataset we obtain a 6.0% increase in COCO��s standard metric (mAP@[.5, .95]), which is a 28% relative improvement. This gain is solely due to the learned representations.
Based on deep residual nets, we won the 1st places in several tracks in ILSVRC & COCO 2015 competitions: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation. The details are in the appendix.
4.3 PASCAL ��MS COCO�ϵ�Ŀ����
���ǵķ���������ʶ�������Ͼ������õķ������ܡ���7�ͱ�8��ʾ��PASCAL VOC 2007��2012��COCO��Ŀ�����������Dz���Fast R-CNN��Ϊ��ⷽ�����������DZȽϹ�ע��ResNet-101����VGG-16�Խ������������������ģ�͵ļ��ʵ����һ���ģ����������ֻ�����������������á���ֵ��ע����ǣ��ھ�����ս�Ե�COCO���ݼ��ϣ�COCO�ı�����ֵ��mAP@[.5��.95]��������6.0%����������28%������������ȫ������ѧϰ�ı��֡�������Ȳв�����������ILSVRC&COCO 2015�����л���˶�������ĵ�һ����ImageNet��⡢ImageNet��λ��COCO����COCO�ָ�������¼��
5.�����
References