һ�����
Finite State Transducers ��� FST�� ������������״̬ת������FSTĿǰ������ʶ�����Ȼ���������������ȷ��㷺Ӧ�á�
���磬����Ȼ���Դ����У�����������һЩ���ijЩ���ݷ��������ĵIJ��������磺���c�ĺ������x�Ļ������c��Ϊb��FST���ǻ�����Щ�����ϵ���ѧ�������������ɸ��������ϳ�һ�����̵Ĵ���������Ч����ڹ����ϵͳ(rule-based system)��Ч�ʡ�
�书���������ֵ�Ĺ��ܣ�STL �е�map��C# �е�Dictionary�������������O(1)�ģ��������������ҵ�key���ȡ�ĿǰLucene4.0�ڲ���Termʱ���õ��˸��㷨��ȷ����Term���ֵ��е�λ�á�
FST ���Ա�ʾ��FST<Key, Value>����ʽ�����ǿ�����O(length(key))�ĸ��Ӷȣ��ҵ�key����Ӧ��ֵ������֮�⣬FST ��֧����Value������key�Լ�����Value���ŵ�key�ȹ��ܡ��ڲ������ŵ�Valueʱ�����õ������·����Dijikstra�㷨,����ͼ��������ء�
������ظ���
�����Զ�����Finite Automata, FA�� ����һ������״̬��״̬ת�Ƶļ�����ɣ���ÿһ��ת�ƶ�������һ����ǩ���������FA������״̬��������Finite State Acceptor��FSA�������ڸ������������У�FSA���ء����ա����ߡ������ա�����״̬��
ͼ1��a����һ��FSA��ʾ������ڵ�ͻ��ֱ��Ӧ״̬��״̬��ת�ơ����磬FSA��ͨ��0,1,1,2,5����һ���������С�a,b,c,d�������������յ���a,b,d�����У����FSA��ʾ��һ���ܱ����յ��ķ������м��ϡ�ͼ1��a����FSA��Ӧ���������ʽab*cd|bcd*�����Ǽ���״̬0������ʼ״̬��״̬5������ֹ״̬��������ر�ָ���������д��ߵ���Բ������ʼ״̬��ϸ��˫��Բ������ֹ״̬��
����״̬ת������Finite State Transducers, FST�� ��FSA����չ����ÿһ��״̬ת��ʱ����һ�������ǩ���������������ǩ�ԣ���ͼ1��b������һ��FST�����ӡ�ͨ�������ı�ǩ�ԣ�FST������һ������ת����һ��������е���һ��������е�ת����ͼ1��b����FST���������С�a,b,c,d��ת��Ϊ��һ���������С�z,y,x,w����
��Ȩ����״̬���ջ���Weighted Finite-State Acceptors, WFSA�� ��ÿһ��״̬ת��ʱ����һ��Ȩ�أ���ÿ�εij�ʼ״̬���г�ʼȨ�أ���ÿ�ε���ֹ״̬������ֹȨ�أ�Ȩ��һ����ת�ƻ��ʼ/��ֹ״̬�ĸ��ʻ���ʧ��Ȩ�ػ���ÿ��·�������ۻ������ڲ�ͬ·�������ۼӡ�ͼ1��c����һ��WFSA�����ӣ�ÿ��״̬ת�Ƶ�Ȩ�ر�ʾΪ������-��ǩ/Ȩ�ء�������ʼ����ֹ״̬��Ȩ�ر�ʾΪ��״̬ ����/Ȩ�ء�������ͼ�У���ʼ״̬0�ij�ʼȨ��Ϊ0.5����ֹ״̬5����ֹȨ��Ϊ0.1�����磬��ͼ�е�WFSA����ת��״̬��0,1,1,2,5�����ۻ�Ȩ��0.51.20.732*0.1=0.252���յ�һ�����С�a,b,c,d����
��Ȩ����״̬ת������Weighted Finite-State Transducers, WFST�� ��ÿ��״̬ת��ʱͬʱ���������ǩ��Ȩ�أ�ͬʱ����FST��WFSA�����ԣ�ͼ1��d����һ��WFST�����ӣ�����ÿ�ε�״̬ת�Ʊ�ǩ���ԡ�����-��ǩ: ���-��ǩ/Ȩ�ء�����ʽ����ת�ƣ���ʼ����ֹ״̬Ҳ��Ӧ�ķ�����Ȩ�ء��ڸ�ͼ�е�WFST�����������С�a,b,c,d����0.252���ۻ�Ȩ��ת��Ϊ���С�z,y,x,w����
WFSTͨ��һ��8Ԫ�� (��,��,Q,I,F,E,��,��) ���壺
(1) �� ��һ�����������ǩ��
(2) �� ��һ�����������ǩ��
(3) Q ��һ������״̬��
(4) I?Q ��һ���ʼ״̬��
(5) F?Q ��һ����ֹ״̬��
(6) E?Q��(�ơ�{?})��K��Q �Ƕ�������ת�ƣ�����" ? "��һ��Ԫ���ű�ǩ�������������ŵ����������K ��һ��Ȩ��Ԫ�ؼ��ϣ�
(7) ��:I��K ��Ȩ�س�ʼ������
(8) ��:F��K ��Ȩ����ֹ������
ͨ�����϶��壬ͼ1��d����WFST���Ա��������£�
(1) ��={a,b,c,d,e}
(2) ��={v,x,y,w,z}
(3) Q={0,1,2,3,4,5}
(4) I={0}
(5) F={5}
(6) E={(0,a,z,1.2,1),(0,b,y,0.8,3),(1,b,y,0.7,1),(1,c,x,3,2),(2,d,w,2,5),(3,c,x,0.2,4),(4,d,w,1.2,4),(4,e,v,0.6,5)}
(7) ��(0)=0.5 (8) ��(5)=0.1
���� E �е�ÿ��ת���ɣ�Դ״̬�������ǩ�������ǩ��Ȩ�أ�Ŀ��״̬����ɣ����Դ����������п�֪��FSA, FST, WFSA����WFST��������ʽ����Щ��ʽҲ�������������Ƶ�Ԫ���ʾ��
���������ʹ洢FST����
Ϊ���ô�Ҷ�FST��һ����������ʶ�����Ǿ�һ��������������˵����
���Ǽ��贴��һ��ӳ�䣺
Key �� Value
��cat�� - > 5,
��deep�� - > 10,
��do�� - > 15,
��dog�� - > 2,
��dogs�� - > 8,
���ھ���FST�㷨��˵��Ҫ��Key���밴�ֵ����С������뵽FST�У�ԭ����Ҫ����Ϊ�ڴ��������ݵ�����£����Dz�̫���ܰ�����FST���ݽṹ��ͬʱ�����ڴ��У�����Ҫ�߽�ͼ�߽����õ�ͼ�洢���ⲿ�ļ��У��Ա��ʡ�ڴ档�������ǵ�һ��Ҫ�����е�Key�������Ҹ����������˵���Ѿ���֤���ֵ����˳��
���ݴ����ӵ��������ǿ��Խ�����ͼ��ʾ��FST��
��ע�����ͼ�ϵ�labelӦ��ָ��aͷ�ϣ�
����ͼ���Կ�����ÿ�������������ԣ�һ����ʾlabel��key��Ԫ�أ�����һ����ʾValue(out)��ע��Value��һ�������֣�����һ����һ���ַ�������Ҫ��Value������������ԣ��������������2 + 8 = 10���ַ����ĵ�����Ϊ�� aa + b = aab��
�������ͼ֮�����ǾͿ��Ժ����IJ��ҳ�����һ��key��Value�ˡ����磺����dog�����Dz��ҵ�·��Ϊ��0 �� 4 �� 8 �� 9�� ��Ȩֵ��Ϊ�� 2 + 0 + 0 + 0 = 2���������һ�����ʾnode[9].finalOut = 0�����ԡ�dog����ValueΪ2�������磺����do�����Dz��ҵ�·��Ϊ��0 �� 4 �� 8����Ȩֵ��Ϊ��2+0+13=15���������13��ʾnode[8].finalOut = 13��
����������Ѿ���FST����һ�����Ե���ʶ������������ϸ����FST�Ľ�ͼ���̣�
1����һ���սڵ㣬��ʾFST����ڣ����е�Key���������ڿ�ʼ��
2�� �������δ������Key����ö��Key��ÿһ��label��
�����������£�
�����ǰ�ڵ���ں���label�ıߣ������Value�����ñߵ�outֵ����Value = Value �C out������temp=out�CValue��out =Value��ʹ��һ���ڵ�����б�out������temp�������һ�ڵ���Final�ڵ� ��FinalOut += temp������һ���ڵ�
���� �½�һ���ڵ�����out = Value�� Value = 0��
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
����˴��е㲻̫���ף��뿴���������ӵĹ������̣�



ͨ��������㷨���ǿ�����FST ��������Ҫ������Ҫ�����ֵ����С�������������¿�ͷ˵��������FSTֻ��һ��ӳ�䣬ֻ�ܳ�Ϊ����Ӧ�ó����һ�����ߣ����Ծ��������������ռ�����ǹ��౦����ڴ�ռ䣬�������Ҫ�Ѳ��õĽڵ���뵽�ļ��С��������ǵ�������ʲô���Ľڵ���Dz�Ҫ�Ľڵ��أ�Ҫ����������ûع����Ǹղŵ��㷨���̡�
���Ƿ��ִ洢cat�ַ����������ڵ��Դӿ�ʼ����deep�����Ҳû�õ����������ɺ�ô��������Ǹ��ɺϣ���ô����ʼ����do�����Ҳû�õ����洢eep�������ڵ㣬�����ɺ�ô����������ɺϣ��ǵ�����ʲôԭ���أ����������ֵ��������֣���
����Ϊ�����DZ�֤�����е�Key���ǰ����ֵ���ӽ����ģ����Ե�����һ����Key��ʱ����ǿ���������¼ӵ�Key����һ�������Key�Ĺ���ǰ��Ȼ��Ϳ��� ��һ�������Key��ȥ����ǰʣ�µIJ��ִ����ļ����ˡ�
���ϣ���֪FST��ǿ��ģ����ڴ������ģ��������DZ��뱣֤��������
�ġ���NLP�е�FST�Ĵ�������
FST��һЩNLP task�����ر����ã�����˵�Ҹ���������������
- ��c�����xʱ����c��Ϊb cx��bx
- ��aǰ����rsʱ����a��Ϊb rsa��rsb
- ��bǰ����rs��������xyʱ,��b��Ϊa rsbxy��rsaxy
���Ե����ǵ�input string��rsaxyrscxyʱ���������������������ǾͿ����������µı任��
rsaxyrscxy��rsaxyrsbxy rsaxyrsbxy��rsbxyrsbxy rsbxyrsbxy��rsaxyrsaxy
Ȼ���Ҿͻᷢ�֣��ڶ������ı任�ĵ������ֱ��ȥ�ˣ�����FST�ͳ����ˣ�FST�ṩ��һ��������Щ��Ч�ķ�����
���Ȱ�ÿһ��rule����һ��FST��ʾ������ÿ��״̬������ߵ����Ա�ʾ����input character�Լ���Ӧ��output character. ��ʾ��ʽ��input/output. ������������3��rules�����ǿ��Եõ���������FST��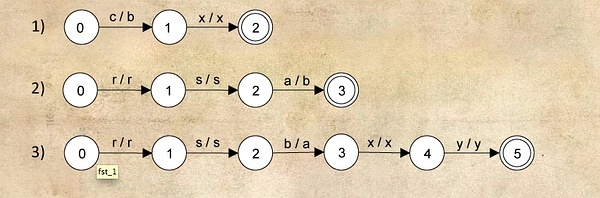
��������Ϊ����FST���������κ����ⳤ�ȵ��ַ��������ܹ����ݹ�����б�Ҫ�IJ��������Ǿ�Ҫextend FST.
�Ըոյ�rule 1Ϊ������ֻ��Ϊ�˱任cx��bx��������ҲҪ��handle������ǰ��ġ�rsaxyrs����Щcharacters������������Ǹ�y�����ԣ����ǿ��Լİ���Щò���������ʱ�ص�characters����һ��its own individual edge����, ��עΪ?/?��Ȼ���æű�ʾ���������������һ�¸ո�������FST��չ��Ľ����
�Ե�һ��ͼΪ������������rsaxyrscxy��Ȼ��cǰ�����һ����rsaxyrs�����������Ǻ��ҹ���û�й�ϵ������������ʲô�ͻ���ʲô��Ȼ������c�ַ��ˣ����Ǿ���c/�� ����ʾ����ʱ�������������һ���ַ������������ǿ�����1�Ǹ��ڵ㣬����ڵ�ֱ�������linkָ��ȥ����x/bx��ʾ����x�Ļ����Ǿ����bx��?/c?��ʾ����Ϊ��x��������ַ�����ԭ�����(�����c���ַ�����)��c/c��ʾ����c�����c(�൱�ڼ����ж��Һ����Ǹ���ʲô)��
�õ�����������չ��FST֮��Ҫȥ�ϳ�һ��single FST�ˣ���FST�ϳ��㷨���������ͳ����˱��ĵķ�Χ���ڱ�����ͨ���ϲ����Եõ��������composed FST:
���final FST�ܴﵽ������rule��Ч���������ص���ת��ֻ��Ҫͨ��FST����һ�α�������û�е����κε�Ч��ת���� ԭ����Щ���������ķѵ�ʱ������������������������ַ������й�ϵ��������FST�ķѵ�ʱ��ֻ��input string�ַ����й��ˡ�
�ο���ַ��
Finite State Transducers ���
����ʶ�������(1)���Զ�����뻷
�����ʼǣ�Finite State Transducer��FST��in NLP
����WFST������ʶ���е�Ӧ�ã����Բο�������ϵ�У�
�߽�����ʶ���е�WFST��һ��
����ʶ�������(1)���Զ�����뻷
��
Speech Recognition Algorithms Using Weighted Finite-State Transducers
�Ȿ��