【PaddlePaddle论文复现营】Temporal Pyramid Network for Action Recognition
- 写在前面的话
- 论文简介
- 从视频分类领域中的一个痛点谈起
- 相关工作
- 网络结构
- Feature Source of TPN
- Collection of Hierarchical Features
- Spatial Semantic Modulation
- Information Flow of TPN
- 实现与实验
- 对比实验
- 消融实验
写在前面的话
本文是作者参加百度顶会论文复现营的一次心得体会。百度飞桨邀请了一些顶会作者和业内大咖,带领学员们一起学习如何复现顶会论文,感兴趣的小伙伴们快来加入我们吧。
论文简介

今天介绍的这篇论文《Temporal Pyramid Network for Action Recognition》是来自港中文和商汤的一篇论文,发表在CVPR2020上。论文作者中出现了周博磊和石建萍等大佬的名字,膜就完事儿了。
看到论文题目,我们首先想到的是在检测和分割任务中广泛使用的特征金字塔,它在不同尺度的特征图上提取信息,融合高层语义特征和底层纹理特征,是CV任务的涨点神器。但是特征金字塔是在空域(Spatial)做的,时域(Temporal)金字塔是怎么回事呢?作者是为了解决什么问题,又是怎么实现的呢?让我们一起进入论文吧~
从视频分类领域中的一个痛点谈起
视频分类是CV领域的一个重要领域,可以应用到动作识别等方向。在深度学习方法应用到CV领域后,出现了C3D、I3D、P3D、TSN、TMN、TRN等方法,提出了一些具有代表性的成果。动作识别需要提取两种模态的信息,一个来源于单帧的图像,另外一个来源于多帧图像之间的关系。上述网络都能做到这一点,但是大部分工作都忽略了一点:动作的快慢和节奏。如慢走、走路和跑步在单帧的形态和多帧的关系上都比较近似,这给视频分类带来新的挑战。

如上图所示,即便是同一个动作,如(a)和(b)所示的Moving Something Sown,也有明显的速度差别。作者统计了不同动作类内差异的方差,其中,剪羊毛的类内差异最小,翻筋斗的类内差异最大。这和人做动作时的年龄、情绪、精力等因素有关。作者认为,如果能够对视觉节奏(Visual Tempo)的类内和类间差异进行建模,可能会显著提高动作识别的精度。
相关工作
之前的工作是有提到并试图解决视觉节奏这个问题的。比如SlowFast1,如下图所示,上面的路径是Slow pathway,保有更高的图像分辨率,但是帧较为稀疏;下面的路径是Fast pathway,帧较为稠密、刷新速度较快,但图像分辨率较低。Slow pathway主要用于提取空间语义信息,Fast pathway主要用于提取帧与帧之间的时间关系,同时使用横向连接进行融合。在SlowFast中,视频节奏的差异通过Slow pathway和Fast pathway引入的不同间隔的帧来体现。

DTPN2以不同FPS对视频进行采样,构建自然的时域金字塔,如下图所示。此外,DTPN还采用两分支的层次结构来处理多尺度时间特征,并且还引入了局部和全局的时间语境。(看起来挺有意思,也很复杂,限于篇幅就不展开讲啦)

SlowFast和DTPN都是在输入层进行不同时间尺度的采样来构建时域金字塔,这样要采样并处理很多帧,其中很大一部分可能是重复的特征提取工作,这样增加了很多计算量。本文的主要改进之一就是改为在特征层次来处理时域信息的差异,这样就能够做到单一网络处理所有信息,同时只需要在输入层以单一的速率进行采样,省去了输入层复杂的处理工作。
网络结构
接下来映入眼帘的就是这么一张大图:

看起来结构式蛮复杂的,不要慌,我们结合图示文字先自己分(nao)析(bu)一波,回头再去论文里结合细节看看我们分析的对不对。
- 首先网络的输入是一个 的视频切片, 分别代表视频的高度、宽度和时间维的长度也就是帧数;
- 接下来是Backbone,也就是骨干网络。Backbone负责提取特征,并且将不同尺度的特征图输入到一面一个环节。
- Spatial Modulation,在空间域进行调制,我们看到图中不同颜色的方框变成了同样的大小,也就是把不同尺度的特征图进行降采样到同一尺度,方便后续处理。
- Temporal Modulation,在时间域进行调制。在通道维度进行下采样,这样就获得了不同速率的视频节奏信息,有了时域金字塔的雏形。
- Information Flow,和特征金字塔类似,进行特征聚合,以增强和丰富层次的表示。
- Final Prediction,最后把所有通道的信息拼接到一起,进行预测。
好了,本次的论文解析就到这里了(大雾)网络结构通过作者的一张图示能够很清楚的看到,但是有很多细节我们并不清楚,需要去论文甚至代码中去寻找。譬如Temporal Modulation是怎么做的,Information Flow又是怎么聚合的?作者设计网络结构的时候踩过那些坑?
Feature Source of TPN
Collection of Hierarchical Features
作者是如何获得时域的层次特征呢?
-
第一种想法是非常naive的。从网络的某一层输出特定尺度的特征,然后直接在帧取样上做文章,采样多就代表高频的、速率快的动作,采样少就代表低频的、速率慢的动作:
在上述公式中,以M个不同的采样帧率( , rate)进行采样,分别送到后续的特征提取网络中,有:
因为我们固定从网络的某一层输出特征,也就是特征的 维度是一致的,这样融合不同帧率的时域特征是较为简单的,但是空域的语义信息较为缺乏,如下式所示:
-
第二种就是之前提到的,在不同的层输出不同尺度的特征,这样和特征金字塔一样,包含了不同尺度的语义特征,如下式所示:
与之对应的维度大小为:
其中,从 到 代表从底层到高层的不同尺度特征, 的维度也随之缩小。因此我们必须小心地处理维度的变化。
Spatial Semantic Modulation
在这里作者提到要注意在Spatial Modulation部分引入监督,提高语义表达能力:

Information Flow of TPN

作者提到了四种不同的聚合方式,其中并行方式效果最好。这块实现起来应该是非常麻烦的,后续的复现过程中需要仔细拜读一下作者的代码。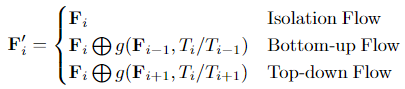
实现与实验
对比实验

这是一个基于3D骨干网络的实现,涨点明显。

基于TSN的实现提升更大:


消融实验
从不同的层输出特征:

不同的聚合方式:

在不同的部位加入TPN:

(包饺子ing) 今天的分享先到这里啦,后续再补充。
Feichtenhofer C, Fan H, Malik J, et al. Slowfast networks for video recognition[C]//ICCV. 2019: 6202-6211.https://arxiv.org/abs/1812.03982v1 ??
Zhang D, Dai X, Wang Y F. Dynamic temporal pyramid network: A closer look at multi-scale modeling for activity detection[C]//ACCV. Springer, Cham, 2018: 712-728.https://arxiv.org/abs/1808.02536 ??