��Ȼ������һ��������ͣ���ˣ�����ֻ�й�֪�������������ھ�����ʲô���Ҵӽ�������·ݿ�ʼ��ʽд���ͣ�������������һ��¼�Լ��Ĵ�ѧ�����ѧϰ���̣���Ȼ�ҲŴ�һ����һ�߽�����ȿ��գ��ø����С����������Ĵ����ſ�ʼ�˽����ӣ���Ϥ���ӣ��Ȱ����ӣ�ǰ����꣬�ҴӴ�һ�����Դ����������������磨�ߴ������ӵ���ѧ���ԣ����ٵ���������Ӽ������ţ������ŵľ�������������ѧϰ�������ֽ⣬�������磬�ܶ�ʱ���һ��ɻ� ������ѧϰ��������ʲô��ϵ������ѧ�Ķ���Խ��Խ�࣬�۽�Խ��Խ�������ҷ�����Щ�������������С�����ʦΪ���ǵĻ������̵棬��ô���ڣ�����˵�����ж�ô�ĺã����������Щԭ�����ҿ���ֻ��Զ����߸ߴ��ϵ� ����֪ʶ��Ҳ�Dz�����ô�ĵ���η���ˣ�����ʦ�� �����ȴ�ѹ�� ֮�£�һ����һ�ε�ͻ���Լ�����ƪ������Ҫ���ݾ����������������ѧϰ��һƪ���ģ���Ȼ����Ҳ���ҿ��ĵ�һƪ���� ����ȻҲ�ǿĿ������������ҽ��ʹ��һ�������ܿ�ѧ�ĸ��أ�
Towards quantum machine learning with tensor networks
- һ . ͼƬ���ص�����̬��ʾ
- �� . ���ʵ��
- �� . ���ӵ�·
- �� . �㷨
- �� . �Ż�
- 1. ��ʧ����
- 2. ��·�Ż�
��ѧϰ��ƪ����֮ǰ������Ҫ�мĻ����̵棬������һ�� �����Ŷ���ϣ�����ܿ�����
�������֣��ʹ�����_��(?_?? �˳��Ҫ�����
���ļ�Ҫ��
����ѧϰ�����Ӽ����һ�ֺ���ǰ;��Ӧ�ã������ڽ����豸���������ӱ����������ޣ������ʺܸߣ�����ڽ����ʵʩ����Ȼ������ս���������������ھ��价���¶Ի���ѧϰ�������ԣ���������˻������;���˻�̬��������ĵ�·����������ѧϰ��������ѧϰ�����Ӽ��㷽������Щ���������Ѿ��������Ľ����豸�����˺ô����ڴ˻����ϣ���������˻������;���˻�̬��������ĵ�·�����Ӽ��㷽������������ѧϰ��������ѧϰ�������һ��ͳһ�Ŀ�ܣ����������У���������Ӽ�����Դ���ͬ�����ۺ��㷨��չ�����棬��ͬ��ģ�Ϳ��Ա������ѵ����Ȼ��ת�Ƶ����ӻ����н��ж�����Ż������������·�������ṩ���ӱ��ظ�Ч���������У�������ϵ�ṹ��������������ӱ��ص��������������������ݴ�С�ɶ��������������������������ݴ�С�ء���������ֵʵ������ʾ�ý��飬ʹ��Ŀǰ����������Ӳ����ִ�еĻ������-�����Ż�������ѵ������ִ����дʶ����б�ģ�ͣ�������ѵ��ģ�͵Ŀ���������
һ . ͼƬ���ص�����̬��ʾ
����֪������һ��ͼƬ��˵�������Ǹ���Ļ��ǵͻ��ʵģ�������ǵĶ���������� �����ص㣬��ͳ������ڴ�����Щ���ص�ķ����������� ��ͳ�ĵ��ӱ��أ���ô�����Ӽ�����У����Ƕ������صı��� �õı��� ���ӱ��أ���仰�̺��Ķ����Ͷ���ȥ�ˣ�
��α����������ݣ���α������أ���ν����ӱ������������ݶ�Ӧ�����������������������
Ҫ���������������ļලѧϰģ�͡�������Ҫ����ĵ�һ����������ΰ�ͼƬ�����뵽����������ȥ���ڻ���ѧϰ����,ͼƬͨ������ʾΪһ��ά��Ϊ���ظ��� ��ʸ����ʸ����ÿ��Ԫ��ֵ��Ӧ�������ص�ֵ����������������,���������ȵ�ά��Ϊ ,�� �������ȵ����������Ӧ��һ��ά��Ϊ ��ʸ����
��ô�ڹ�����������ලѧϰģ��ʱ,�������ϣ����һ������������Ϊһ��ͼƬ���ص�����Ļ������Ǿ���Ҫ���ȶ���һ���� ά�ռ䵽 ά�ռ������ӳ�䣬������˵�����ǿ���ÿ�����ؿ�����һ��������״̬��ÿ������ֵ��ͨ��һ������ӳ�� ��Ӧ��һ�������״̬ʸ����Ȼ�� ������ϵͳ��״̬�����ø�������״̬ʸ�������������졣
��ͼ���������ַ�����ij���������ƶ������������Ľ�����
 �����ȶ�21���������ݺ�ĿƼ����� ���˼�𣬻����������߰�ʮ�����������һ̨�ڰ��ӻ��Ǿ�������Ԫ������ģ��ڰ��ӻ�����ŵĿ϶��Ǻڰ�ͼƬ������������������Ժڰ�ͼƬΪ����
�����ȶ�21���������ݺ�ĿƼ����� ���˼�𣬻����������߰�ʮ�����������һ̨�ڰ��ӻ��Ǿ�������Ԫ������ģ��ڰ��ӻ�����ŵĿ϶��Ǻڰ�ͼƬ������������������Ժڰ�ͼƬΪ����
����ͼ��ÿһ��С�������һ�����ص㣬��Ȼ������ڰ�ͼƬ�Ĵ�С��4x4�ģ�����Ϊ���ú����õ���������̬��ʾÿ�����أ������㲻̫���⣬���ùܣ������Բ��ö��ȱ���ķ�ʽ�����Щ���أ�����Ϊ�������Ǻڰ�ͼƬ�����ں�ɫ�ģ�����ֱ���� [1,0] ��ʾ����ɫ�����ص㣬������ [0,1] ��ʾ�����ԣ��м�ش��Ļ�ɫ���أ����Ǿ������Ƕ��ߵĵ���̬����ʾ��
�������ͼƬ������ͨ������ �Ҷ�ͼ����
��Ͱ�������ˣ����ǿ���ֱ��Ǩ�Ƶ�Ѧ���̵�è�ϵ��Ǹ�����̬����������������̬��������ĺ���ף����������ĵ���̬��������Ļ�ɫ�ش������ԣ�����������ǾͿ�����һ�����ӵ�����̬����ʾ
���������ˣ�

����ֻ������6�����ص�ͼƬ��
��ÿһ��
��ָ���Ǵ� 1 ��
������
Ҳ��������Ӧ������ӳ���ά�� ������һ��Ҳ�������Ӧ�IJ�ͬϵ���ĵ��������ӵ���̬���������д��
��һ�������ӳ��Ĺ��̣���һ������������ӳ�䵽����̬�Ĺ��̣���������ӳ�����ѧ���
�����������ݵ�ӳ�亯��Ϊ��
������֮��
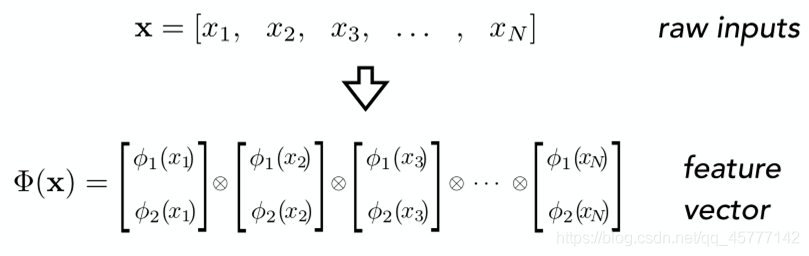
����� x �������������������ݵĽ�ϣ�
�����ľ���ÿһ���������ݣ�������һ������ļ�������ʾ�����еĵ�������ӳ��֮����ֱ���Ե���ʽ�����ǽ����һ�������������Ĺ�ʽ���Ϳ��Եõ�һ��������ӳ�亯����
������һ��˼���⣨��β�����𰸣���
����������˵�Ķ��Ǻڰ���ɶ�Ҷ�ͼ����ô���ڲ�ɫ��RGB��ʽͼ����˵�������ָ���α����أ�
�� . ���ʵ��
��ʵ�����ǵ�ӳ��֮�������������ܽ���Щ�������ݽ��������IJ�����Ҫ��������������Ҫ��Ū�������յ�Ŀ����ʲô��������Ҫȷ������
�����ѧϰ�У�MNIST ��д���ݼ���ʶ��������һ���dz������ķ������⣬��������60000�ŻҶ�ͼƬ����ȫ�Ǻ�������ƪ���ĵ�����!
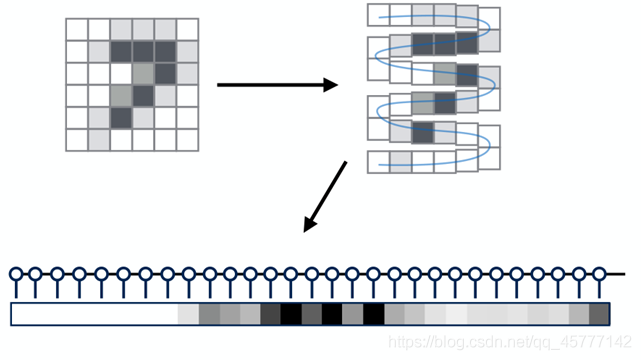 ����ͼƬ����MNISTͼƬ�����ش�СΪ6x6��ͼ��Ϊ����7��һ����дͼƬ��������Ҫͨ��һϵ�в�����ʹ�����ķ��ؽ��Ϊ ����7����˵���ˣ������㷨Ҫʶ������ͼƬ�����ݣ�
����ͼƬ����MNISTͼƬ�����ش�СΪ6x6��ͼ��Ϊ����7��һ����дͼƬ��������Ҫͨ��һϵ�в�����ʹ�����ķ��ؽ��Ϊ ����7����˵���ˣ������㷨Ҫʶ������ͼƬ�����ݣ�
ͬʱ������ͼƬҲΪ���Ƿdz�ֱ�۵�չʾ����һ�������̣������������ų�һ�Ų����MPS�����ڲ�ͬ��ͼƬ���أ���ͬϵ��������̬����֮������λ��Ҳ�Dz�ͬ�ģ��ھ���ѵ���õ�trian ģ��֮���ص�Ӧ������������Ҫ��Ԥ���ǩ����ô�ص�����ˣ������ϵ�����Ԥ���ǩ�Ĺ�������ֵ���о��ģ�
���ǿ�ͼ˵����
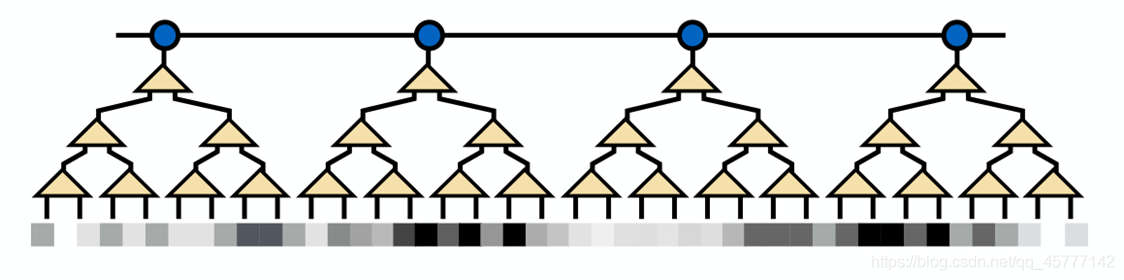
�������õ�����Ҫ������������˼�룬��Ҳ�����������еĺ���˼�룬��Ŀ���Dz��ϵĶ����߶Ƚ�С����Ϣ�Ӷ���ȫ�ֵ���Ҫ��Ϣ��¶��������ԭ�ȵ����ݳ��ֳ�Խ��Խ��۵����ƣ�
�ڿ������ͼ֮ǰ����������ɶ�ǵȾ�����������dz���һ�����壬һͼ���ԣ�
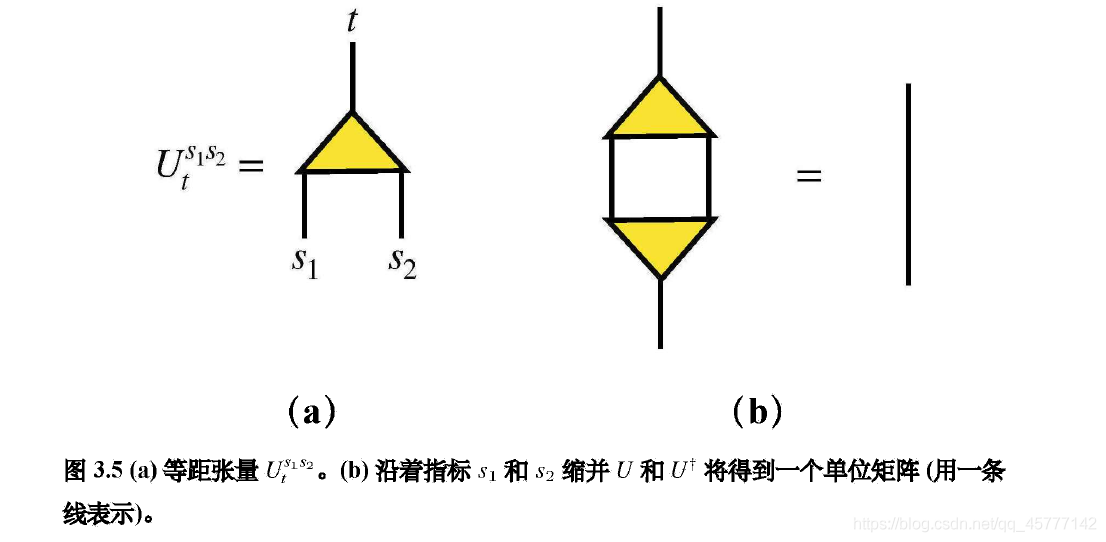 �����ǰ����е�����Ԫ�����ݶ�Ӧ����̬�ĵȾ����������֮�����Ǿ͵õ���һ���Ⱦ�任�㣨Ҳ�������ϸ�ͼ�е�һ�������Σ�ע������Ͳ���������Ŷ�����˵Ⱦ��Ϳ��������ֻ�ÿ��ѵ��������������
(��ʵ���ﻹ��һ������Э���������жԽǻ��Ĺ��̣����ﲻ��Ҫ� ��������˼����)��ͨ�����ϵĵ�����һ���̣����ϵĶ������������Ե���Ϣ�����Ǿ͵õ���һ����״���������磡�����״����ͨ�����ϵ�ͶӰ���Լ����ѹ�����������ı�ʾά�ȣ�ͬʱҲ����������Ҫ�ɷ֣�
�����ǰ����е�����Ԫ�����ݶ�Ӧ����̬�ĵȾ����������֮�����Ǿ͵õ���һ���Ⱦ�任�㣨Ҳ�������ϸ�ͼ�е�һ�������Σ�ע������Ͳ���������Ŷ�����˵Ⱦ��Ϳ��������ֻ�ÿ��ѵ��������������
(��ʵ���ﻹ��һ������Э���������жԽǻ��Ĺ��̣����ﲻ��Ҫ� ��������˼����)��ͨ�����ϵĵ�����һ���̣����ϵĶ������������Ե���Ϣ�����Ǿ͵õ���һ����״���������磡�����״����ͨ�����ϵ�ͶӰ���Լ����ѹ�����������ı�ʾά�ȣ�ͬʱҲ����������Ҫ�ɷ֣�
���ն������ɫԲȦ�����ľ���Ԥ��õı�ǩ��
�� . ���ӵ�·
���ǽ�Ҫ���ǵ��������������MPS���ǿ��������ӵ�·��ȷ��ʵ�֣�ͨ�������Ƕ�Ӧ��������������ӵ�·�Ǿ���������Ƶģ���ʹ�����ܹ���Ч���þ��������������Ͳ��������ż�ά�����ӣ�����MPS������������Χ��״̬�������γ�������ϣ�����ؿռ䣡
���ǽ�Ҫ�о��ĵ�·��������һ��ʼ��û��ȷ���IJ�����ģ�Ͳ�������ֻ�е�·�ļ��νṹ�ǹ̶��ģ�������ô������IJ�����������ض��Ļ���ѧϰ�����Ż������濴ͼ�����£�
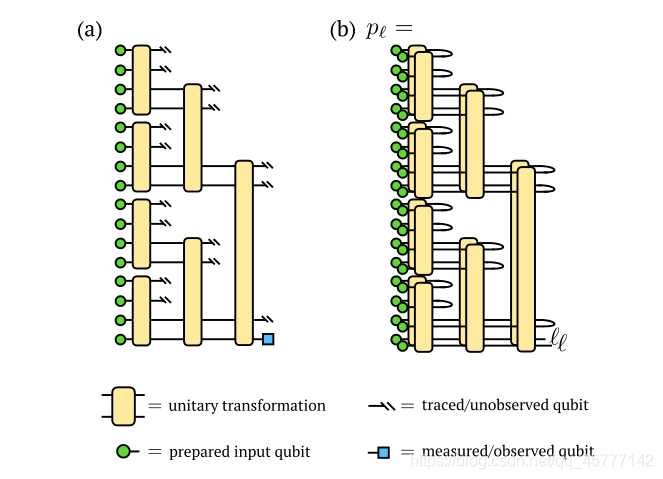 ��ͼ��ǰ����������ǵȼ۵ģ�
��ͼ��ǰ����������ǵȼ۵ģ�
�ȿ���ߵ�ͼ�������һ����16����ɫ��СԲȦ�����Ǵ����ľ���16�����ص�ͼƬ��Ҳ����ÿ��СԲȦ�������������ӵ���̬��ɵ�һ���Ѿ����õ��������ݵ����룬��Ȼ��ÿ�ĸ�Ϊһ������ϱ任������������������ݲ�ͬ�������ÿһ���ϱ任Ҳ�����������Ĵ��Ƕ�������Ӧ�ĸı䣬֮����õ���ǰ��Ĵ�����˼�룬����������������Ϣ������ͼ�е�˫б�ܣ�������Ҳ���Բ���������������������ȡ������ͼ��ʾ�������������������յõ����ǿɲ����۲�����ӱ��أ���Ӧ�ľ������յ������ǩ��
�����Ͼ�������������Ĺ���ת������ͬ�ģ����ԣ�������ͼ���Ǹ��ƺ�Ĺ���ת����ԭ���ĵ�·��ϣ�ԭ���IJ��־���������һ����λ�������Ƕ��ڶ��ͼ��Ĵ��������Կ�������������ֱ�ӱ����������ǩֵ ��
����ͼƬ���Ǹղ����ӵ�·ͼ�ĺ�۱���ĸ�����Ϊһ�飬�ֳ����飬���ұߵ�Ҳ��������ı�ǩֵ��
 ���������һ�����ӵ�·ͼ����MPS��Ӧ �Ķ����������ƽ��������ǰ�������ͼƬ�ı�����һģһ����Ψһ��ͬ�ľ��������·�Ƕ�������������ݰ�����������ǰ���������������ĸо���
���������һ�����ӵ�·ͼ����MPS��Ӧ �Ķ����������ƽ��������ǰ�������ͼƬ�ı�����һģһ����Ψһ��ͬ�ľ��������·�Ƕ�������������ݰ�����������ǰ���������������ĸо���
�� . �㷨
����������һ��ͼƬ���ܽͬ�ĵط���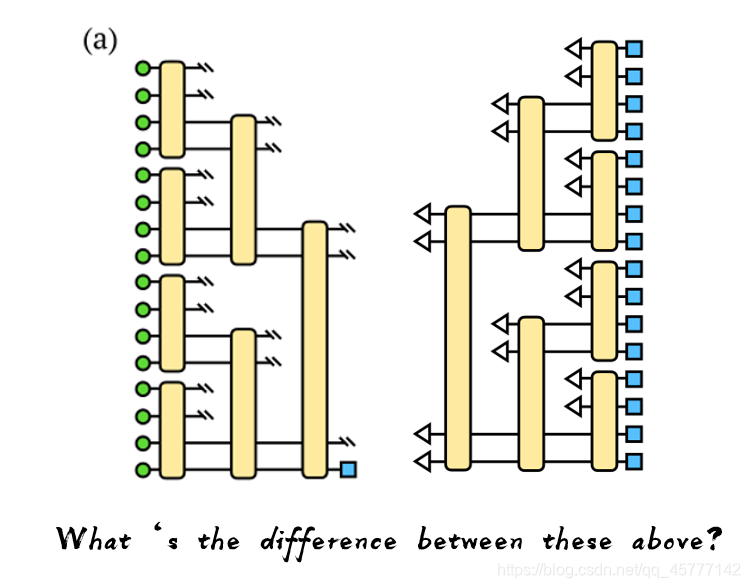
- ����ӳ�������ľ�����ߵ�һ�б�ʾ�������ݵ���ɫСԲȦ �������ұ�ͼ�оͱ���������ˣ�����֪��������ɫԲȦ��˵����������һ�����ӵ���̬������������������������� [0,1] ������һ����̬����һ��ȷ����״̬��
- ��Σ�������Ȼ����������ͼƬ����ԳƵģ�˵�����ǵ���·�������෴�ģ�
- ���ԭ����β��ֻ��һ����ɫ�Ŀɹ۲����ӱ��أ�������ͼ�У�Ҳû�ж�����Ϣ�ˣ��������˿ɹ۲�ı�ǩֵ��
Ŀ��������̣����̿��Ʒ�����������Щ��ͬ�ĸ���ԭ�����㷨�IJ�ͬ��

����������������ӵ�·�ֱ��Ӧ�ľ��� �б��㷨 �� �����㷨 ��
�����б��㷨��˵���Ὣԭ�������ݼ����˷ֳ�train �� test ���ݼ�����train���ݼ���Ϻ�ģ��֮����test���ݽ���Ԥ�⣬��س�����һ�������ֻ��һ��Ԥ���ǩ�������������㷨���ԣ����ǻ���ǰ����һ��ͼƬ�������е�����������ÿһ����ǩ�������� ���жԱ� �����������س����������б�ǩ�� Ԥ����ʣ�����ֻ��Ҫѡ���е������ʱ�ǩֵ���ɣ�
�����и��dz��õ����Ӱ���������⣺
 �б�ʽģ�;�����Ҫȷ��һ������ɽ��������,���б�ģ�͵ķ����Ǵ���ʷ������ѧϰ��ģ��Ȼ��ͨ����ȡ��ֻ���������Ԥ�����ֻ����ɽ��ĸ���,������ĸ��ʡ�
�б�ʽģ�;�����Ҫȷ��һ������ɽ��������,���б�ģ�͵ķ����Ǵ���ʷ������ѧϰ��ģ��Ȼ��ͨ����ȡ��ֻ���������Ԥ�����ֻ����ɽ��ĸ���,������ĸ��ʡ�
����ʽģ�;�������������ģ���Ǹ���ɽ�����������ѧϰ��һ��ɽ���ģ��,Ȼ��������������ѧϰ��һ�������ģ��,Ȼ�����ֻ������ȡ����,�ŵ�ɽ��ģ���п������Ƕ���,�ڷŵ�����ģ���п������Ƕ���,�ĸ����ʴ�����ĸ���
���ԣ�������Ƕ���˵���ͽ�����Ϊɶ�������������ͬ��
�� . �Ż�
��ƪ���ĵ�ǰ�벿�ָ������ǻ��ڼලѧϰ������������ͼ���������һЩԭ���������㷨֮��ĺ��ĵ㣬���ĵĺ�벿����Ҫ���ľ����Ż��Ĺ��̣������Ż���ʧ���� �������ø�ȷ�������Ż����ӵ�·��ʹ�����Ч�����߽�ϣ���ʹͼ������ȷ�ָ�Ч��
1. ��ʧ����
���ǵ�����Ŀ����ѡ���·�IJ������������ǾͿ���ͨ���������е�·������Ч��Ϊ�����ݷ�����ȷ�ı�ǩ���������Dz��ò�������ʧ�������������ʧ����������ͨ���ڻ���ѧϰ��ʹ�õ�MSE ��Щ��һ��������������������һ�£�
��ע����Щ���ŵĺ��壺 �������ǵ�·ģ�͵IJ�����ɵ�������x ��ѵ�����ݼ���Ԫ�أ� �Ƕ��ڸ�������� x �������ǩΪ �ĸ��ʣ� ������������ x ��Ӧ�����ص���ȷ��ǩ ��
�������ȶ��嵱Ԥ��������ʵ�������ͬʱ������ѡȡ���������IJ��������£���Ϊ������Խ�ߣ�Խ���۲�;�������
���������ǾͿ��Զ��嵥�������������ݼ�����ʧ������
����������Ҫ���볬����
��
����Ҳ�ǻ���ѧϰ�����Ǿ���ʹ�õģ�������������ȥ����ģ����ϵ�ʱ���ڷ��س����ĸ���ֵ������ٻ�����Щƫ������
������ģ��һ�����ݴ��ԣ���һ���ķ�Χ�ڣ����ǻ���ʹ��
���ص�����ֵ������֮�⣬������ʵֵ��Ԥ��ֵ�IJ�ֵ����ͬ�Ĵ�С���ǻ���費ͬ��Ȩ�أ���Ҳ����
�����ã�
��ô�������е�ѵ��ͼƬ���������������ʧ�������ٽ��й�һ�������͵õ����£�
��Ȼ�����Ǹ���Ȥ����ѵ�����ǵĵ�·�ܺõ��ƹ㵽δ�۲쵽�����룬��ˣ�����Ҫ�����������Ż��������ݷֲ���������ѵ�����ݵ��Ӽ����Ż���ʧ���������뱣�ֲ���IJ������ݼ����бȽϡ�
���⣬���ڵ��ͻ���ѧϰ�����ѵ�����Ĵ�С�dz���(��MNIST���ݼ��������Ϊ60000��ʾ��)����˼���ÿ���Ż�����������ѵ�����ݵ���ʧ�Dz���ʵ�ʵġ�ȡ����֮���ǣ�������ѭ����ѧϰ�ı�����������ÿ�ε��������ѡ��һС��ѵ��ʾ����
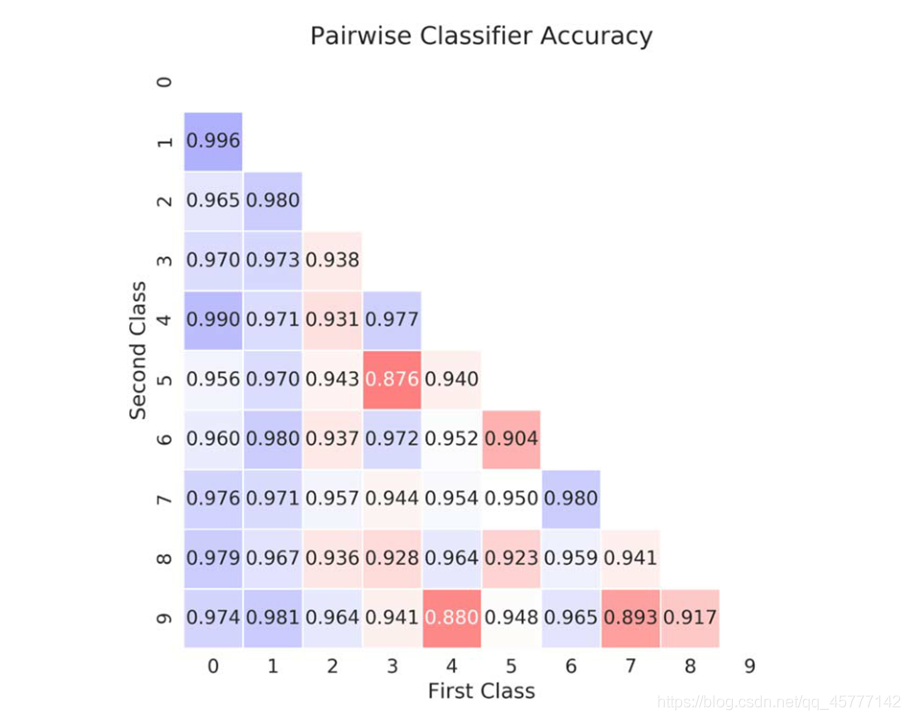 ���Ƕ���֮ǰ��MNIST��д���ݼ�����������ط�������֮�� �õ���һ����д����ȷ��Ԥ��ķ����������涼��ģ��Ԥ���ȷ�ʣ�
���Ƕ���֮ǰ��MNIST��д���ݼ�����������ط�������֮�� �õ���һ����д����ȷ��Ԥ��ķ����������涼��ģ��Ԥ���ȷ�ʣ�
2. ��·�Ż�
�ڴ��µĿ�����ʧ����֮��ȷ�������IJ������dzɹ�ʵ���ˣ���ô����Ч�ʵ��Ż����⣬������Ҫ�Ľ�ԭ�ȵĵ�·�ṹ������ǰ��˵������ ������ٸ� �������� ����Ҫ������ٸ��µ�����̬ ���Ǻ������� ����̬�����Խ�� ����������Ѷ�Ҳ����Խ�� �ķѵ�ʱ��Ҳ��Խ�� ��
�ٻص�����֮ǰ���ܵ�·��ʱ�����������IJ����õ��˴�������˼�룬���Զ�������������������ӱ��أ���ȻҪ������һ�֣���ô������Щ��ʧ�����ӱ��أ��ܲ��ܲ����ض��ķ��������ǽ����ظ����� �أ�
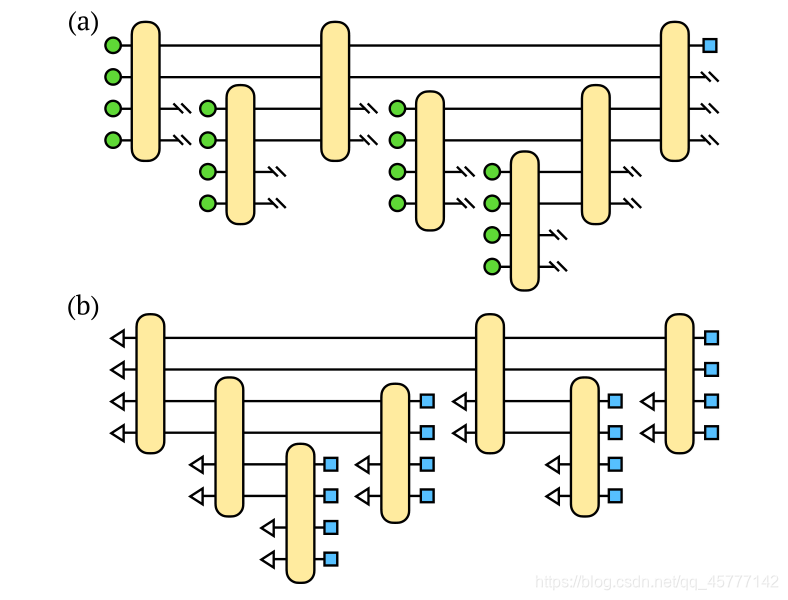 ��ϸ�����ͼ����ԭ����������������̬���棬�����ּ���ʹ������������̬���������ؼ���������һ�����ϱ任��
��ϸ�����ͼ����ԭ����������������̬���棬�����ּ���ʹ������������̬���������ؼ���������һ�����ϱ任��
��������:  ������������Ƕ���֮ǰ��������·�У�����������״̬���� �������� ��Ȼ��Ҫ N ������̬�����أ������� ���ӵ������Ͳ�������ز���֮�����ǿ��Խ�ԭ����Ҫ�� ���ӱ�����Ŀ�Զ��������������������
������������������֮��� �������ߡ� ��
������������Ƕ���֮ǰ��������·�У�����������״̬���� �������� ��Ȼ��Ҫ N ������̬�����أ������� ���ӵ������Ͳ�������ز���֮�����ǿ��Խ�ԭ����Ҫ�� ���ӱ�����Ŀ�Զ��������������������
������������������֮��� �������ߡ� ��
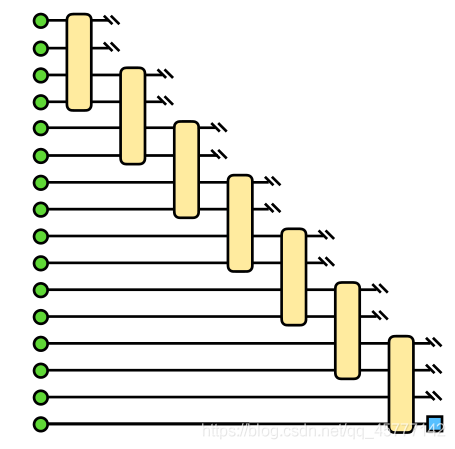
��ô���ڸղ��Ǹ�ͼ��V=2��ԭ����Ҫ��������16���µ����ӱ��أ����� ����ֻ��Ҫ 8��������ͼ��ʾ��
 ����ԭ��������̬������֮������ظ����ã��ϺõĻ����˶�����̬����֮���������������һϵ�����⣬����������Ч�ʣ�
����ԭ��������̬������֮������ظ����ã��ϺõĻ����˶�����̬����֮���������������һϵ�����⣬����������Ч�ʣ�
��ô���������������ͼƬ���ԣ�����������Ҫ��������ٸ����ӱ����أ����ȡ������ÿ�α���������̬�������ߣ��ˣ�
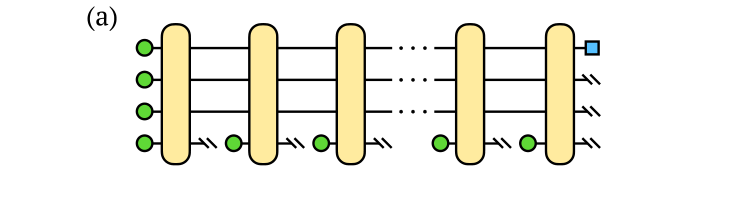
���ͼƬ��ȷ�ĸ������ǣ�����������������Ŀ��ȵ�qubits ���������qubit ���Ƿ�����������������������е������ĸо��ˣ���Ҳ�������Ӽ������ ��̬֮����
�����ƪ���Ļ���������·���������������ڵ�������������������ҪһЩ��ǿ������֪ʶ���ƿƹ���ʾ tmd ֱ��Ȱ�ˣ������о����� �������䣡
�õģ���ƪ���ĵĴ�ž�����Щ ��ϣ�������Ƕ��ָ�㣡