??����̸SVM��hard-margin��soft-margin��ϸ�Ƶ���KKT�������˼��ɣ��У����������Ӳ������⣺
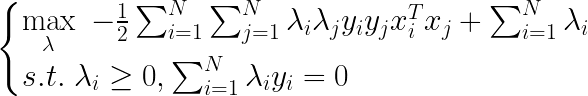
���������������⣺
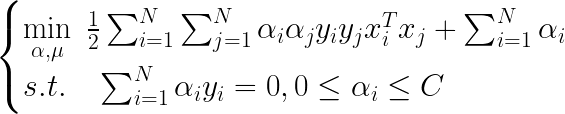
���Ƕ����������������������ճ���
����⣬�������Ǿ�����һ��
SMO�㷨
- 1.SMO�㷨�Ļ���˼��
- 1.1ʲô��SMO�㷨
- 1.2������ı���
- 2.SMO�㷨��ʵ��
- 2.1�����������ι滮����ⷽ��
- 2.1.1ԭʼ����ķ���
- 2.1.2Լ������+����
- 2.2������ѡ��
- 2.2.1��һ��������ѡ��
- 2.2.2�ڶ���������ѡ��
- 2.2.3������ֵb�Ͳ�ֵ
- 3.�ܽ�SMO�㷨
- 4.SMO�㷨�����е�һ�����
1.SMO�㷨�Ļ���˼��
1.1ʲô��SMO�㷨
??SMO�㷨Ҫ����ľ����������ι滮���⣺
SMO��sequential minimal optimization��������С�Ż����㷨��һ������ʽ�㷨�������˼·�ǣ�������еı����Ľⶼ��������������KKT��������ô�����������Ľ�͵õ��ˣ���ΪKKT�����Ǹ����Ż������н�ij�Ҫ�������������Ǿ�ѡ�������������̶����������������������������һ�����ι滮���⣬������ι滮��������������������Ľ�Ӧ�ø��ӽ�ԭʼ���ι滮����Ľ⣬��Ϊ���ʹ��ԭʼ���ι滮�����Ŀ�꺯��ֵ��С��
1.2������ı���
??�����ᵽ������Ҫ�̶�����������������������ѡ���˼·��ʲô��һ��������Υ��KKT���������صĵ��Ǹ���������һ��������Լ�������Զ�ȷ���� ��ˣ�SMO�㷨��ԭ���ⲻ�Ϸֽ�Ϊ�����Ⲣ����������⣬�����ﵽ���ԭ�����Ŀ�ġ�
??����SMO�㷨�����������֣���������������ι滮�Ľ���������ѡ�����������ʽ�㷨�����潫���ν��ܡ�
2.SMO�㷨��ʵ��
2.1�����������ι滮����ⷽ��
??����˵����Ҫ�̶��������������Dz�����ѡ�� ����������Ȼ��
2.1.1ԭʼ����ķ���
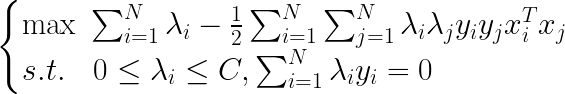
���ǹ̶�
��ʼ�����б���������Ŀ�꺯�����з������ۣ�һ�����������
�������Щ���࣬���Ƕ�Ŀ�꺯������չ����
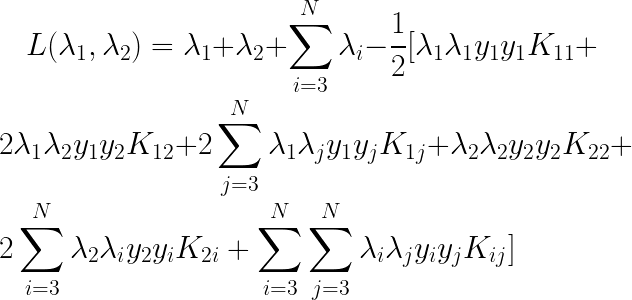
�������Լ����һ��dz����������ս����Ӱ�죬���ǿ���ȥ��������
��Ϊ1�����ǽ�һ������
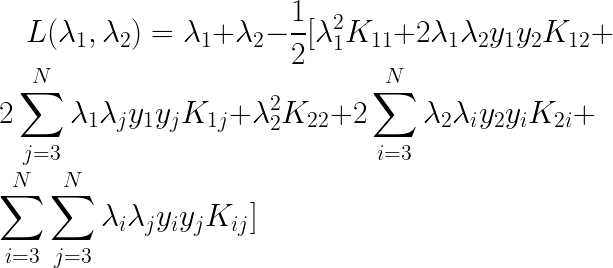
������
��������Ϊһ������������
����
���������룬����ֻ��
�ĺ�������ע������ij���C������ijͷ�ϵ��û�а���ϵ��������
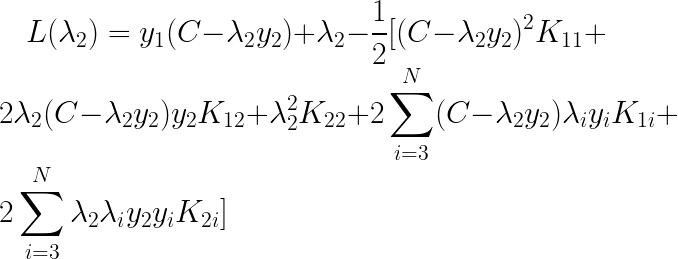
Ȼ����
��
�ã�
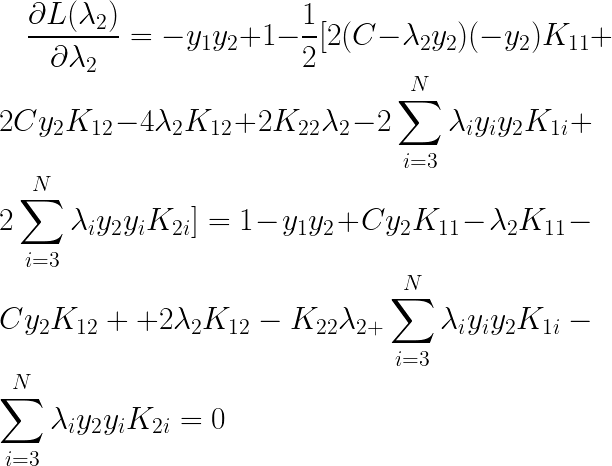
���ǽ�
�ƶ���һ��õ���
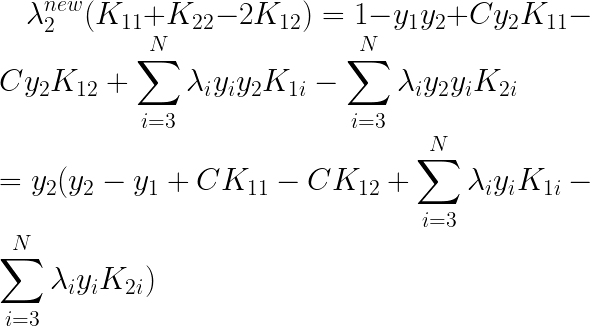
��Ϊ�ǵ�����������ÿ�ε�
����new�ģ�������Ϊ��
�����Խ�C�������룺
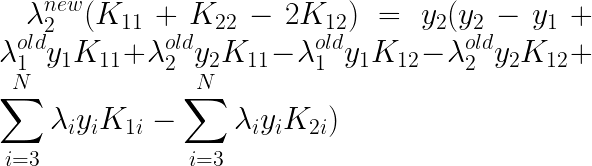
�ٴλ���ǰ�棺

���ǣ�
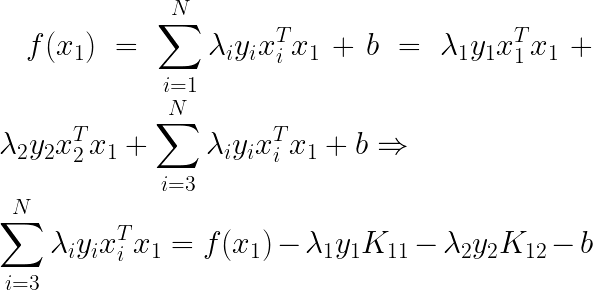
ͬʱҲ���Եõ���
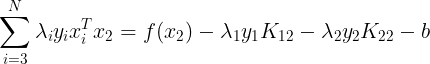
����������ʽ�Ӵ��뵽��
�õ���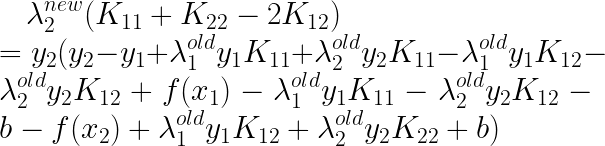
�кܶ������ֱ��������
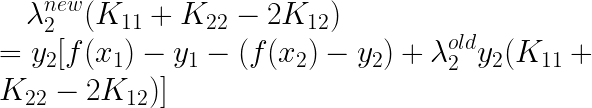
������
���������ս���ˣ�

���²�һ�£���ʽ���̫��д�ˡ�����������
2.1.2Լ������+����
??��ǰ�棬��������һ��
�������ʽΪ��
�����أ��������������в�û�п���
��һ��Լ�����������dz��������Ž�Ϊδ�����������Ž⣬��Ϊ��

��ô�������Ǽ���Լ�������ٿ���������ֻ����������
��Լ�������ö�ά�ռ��е�ͼ�α�ʾ��Լ������Ϊ��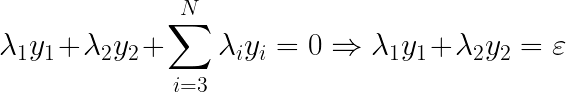
�Լ�
��
��������Ƶ��������õ���C�����ﲻ����ͷ�ϵ��C���������Ի�һ����ĸ
����ʾ����ˣ�����Լ��������

���Կ��������ǽ���������������һ�������ڣ�����Ϊ������ӻ������Ϊһ������k�����ԣ�ʵ���϶��ߵ����Ž����һ��ֱ���ϣ���ֱ�����б߽�ģ� ������ǾͿ��Եõ�
�ı߽磬������ʾ��
2.2������ѡ��
������������ ������ѡ�����ģ��Ǿ�����ôѡ�أ�
2.2.1��һ��������ѡ��
??SMO�㷨��ѡ��
�Ĺ���Ϊ���ѭ����ѡȡԭ���ǣ���ѵ��������ѡȡΥ��KKT���������ص������㡣 ����һ��KKT������
ע�⣺�����
����

��KKT�����������ۣ�
��1��
����
��˵������
����֧��������
��2��
����ʱ
��֧�������ˡ�����Ϊʲô�����C����Ϊ
�����������
������Ϊ
������
����
��˵������
�ڷָ�߽��ϡ�
��3��
�������
��֪
������Ϊ
������
��
�Ե������������һ�����ۣ�
- ���� �������ڼ���߽��볬ƽ��֮�䡣
- ���� �������ڳ�ƽ���ϡ�
- ���� �������ڳ�ƽ����һ�࣬˵���������
���ѭ���������£�
- ���ȱ������������㣬����в��������� �������㣬��ѡ������Ϊ��һ��������
- �����������㶼����������ϵ����ô��ѡ������ �������㡣
2.2.2�ڶ���������ѡ��
??SMO�㷨��ѡ��
�Ĺ���Ϊ�ڲ�ѭ�����������ѭ�������ҵ��˵�һ������
������Ҫ�ҵڶ�������
��ѡȡ������
���㹻��ı仯�� ǰ������֪����
�ɼ�
������
������
���˵�ʱ��
Ҳȷ���ˣ�����Ҫ��
���ֻ��Ҫ��
Ϊ��ʱ��ѡ����С��
��Ϊ
�� ��
Ϊ��ʱ��ѡ������
��Ϊ
��Ϊ�˽�ʡ����ʱ�䣬���Խ����е�
���������ӿ������
����������£�����ڲ�ѭ����������ʽѡ����һ��ʹ��
����
�������½��ܲ���������ô���Ǿ����»�һ���������������ڼ���߽��ϵ������㣬ѡ��һ��ʹ��Ŀ�꺯���½����Եĵ�������Ϊ
��Ҫ�ǻ��������⣬�Ǿ����½������ѭ��������ѡ��
��
���ڲ�ѭ������֪�������ǵü���
����
2.2.3������ֵb�Ͳ�ֵ
??��������һϵ�и��ӵ����㣬�����ҵ��������Ż���ı�����ÿ�������ҵ�������������Ҫ���¼�����ֵb������̸SVM��hard-margin��soft-margin��ϸ�Ƶ���KKT�������˼��ɣ��У��������������2.2.6�У�����˵����
ǰ����ʱ�����Ѿ��õ��ˣ�
�����b*��˼·��ǰ��һ������ȡһ��֧������
������֪��֧���������㣺

������������һ����ȷ����
���������ѡ����һ��
��֧����������ô
�ľ���ֵ��������֪���ģ��������ֻ��ѡ��һ��
��֧���������ܽ��b�������������KKT���������ۣ�ֻ�е�
ʱ��
�ų��������������Ҫע�⣬Ӳ�����bʱ���ǿ���ѡ������һ��֧������������������У�����ֻ��ѡ������
��
����֧����������֧�����������ܽ��b������ʵ��һ����Ϊ�ƶ����� b �Ĺ���
??��ֵb����
ʱ��õġ�����
ʱ��������ֵ����ʽ�е�k���Ծ���1����ô���У�
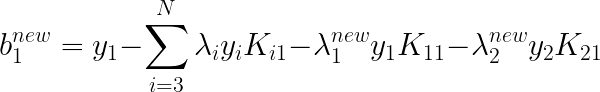
����
�ı���ʽ�����ǿ���д����
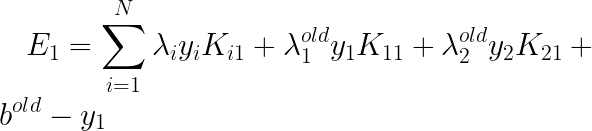
����ʽ��ǰ�������дΪ��
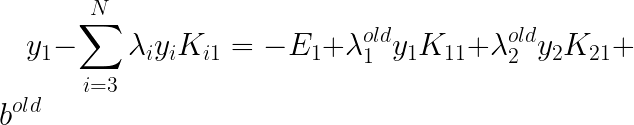
����
�������
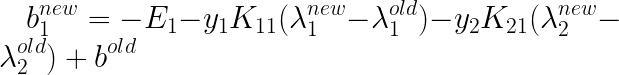
ͬ��������
����
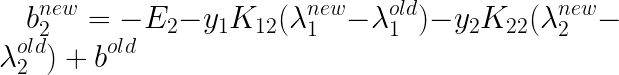
���
ͬʱ���㣬��ô
�����
����0����C����ô
�Լ�����֮�������������KKT��������ֵ������һ��ѡ�����ǵ��е���Ϊ�µ���ֵ
��
��ÿ����������������Ż�֮������ҲҪ���¶�Ӧ��Eֵ���������DZ������б��У�E�ĸ���Ҫ�õ�
�Լ�����֧��������Ӧ��
��
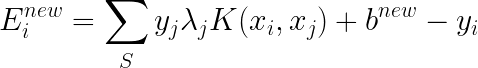
j������֧���������±꣬S��֧���������ϡ�
3.�ܽ�SMO�㷨
??SMO�㷨������Ϊѵ�����ݼ�T����������ΪN��ÿ�������ı�ǩΪ1����-1������Ϊ �����Ϊ���� �Ľ��ƽ⡣
- ȡ��ֵ�������� ��Ϊ0���� =0����k=0
- ���������ѡȡ�Ż���������ѡȡ����Ҫ�Ż��ı��� ��������ǵ����Ž� ������ Ϊ
- ���ھ���
��Χ������ֹͣ������
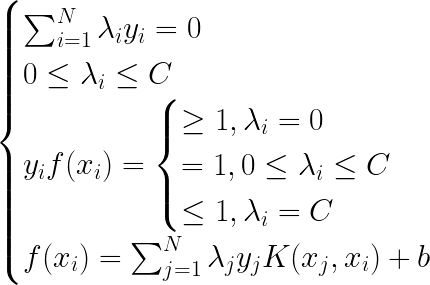
��ô���Ǿ�ֹͣ��������ǰ�� �������յ� ����������ֹ�����������ڶ�����
4.SMO�㷨�����е�һ�����
??�㷨���漰������
�����զ�㣿�����㣺
��Ϊ�������е�
�����г�ֵ�ģ���������IJ�����ÿһ�ε���ʱ����ȷ����ֵ��ֻ����ÿ�ε�����Ҫ���¡�