DeepWalk Online Learning of Social Representations[1]
- ТлЮФДѓИй
- ЮЪЬтЖЈвх
- ЙБЯз
- ЪЙгУDeepwalkбЇЯАНсЕуБэеї
- ЫМТЗДѓИХЪЧетбљЕФ
- detail0ЃКЮЊЪВУДПЩвдНЋгябдФЃаЭжаЕФММЪѕгУдкНсЕуБэеїжаЃП
- detail1ЃКЮЊЪВУДзюДѓЛЏНсЕуЕФЙВЯжТЪПЩвдгУРДИќаТ ?
- detail2ЃКHierarchical treeЃП
- Deepwalk ЮБДњТы
- ВЮПМЮФЯз
ТлЮФДѓИй
- Introduction ЃЈНщЩмСЫТлЮФЕФШЮЮёЃЌИХРЈСЫТлЮФЕФЙЄзїЃЉ
- Problem DefinitionЃЈЖЈвхСЫ
- Learning Social Representation
- Method
- Experimental Design & Experiments
- Related Work
- Conclusinos
ЮЪЬтЖЈвх
дкЩчНЛЭјТЗжаЃЌНсЕуЕФБэЪОЭЈГЃЪЧЯЁЪшЕФЃЌетИјДцДЂКЭМЦЫуЖМДјРДСЫВЛБуЁЃИјЖЈЩчНЛЭјТчжаЃЌбЇЯАЭјТчжаУПИіНсЕуЕФвўБэЪОЃЈlatent representationЃЉЁЃМђЕЅРДЫЕЃЌОЭЪЧгУвЛИіГэУмЕФЯђСПРДБэЪОЭјТчжаЕФНсЕуЁЃетбљЕФЯђСПгІИУОпБИвдЯТетЫФИіЬиЕуЃК
- Adaptability: бЇЯАЕНЕФrepresentationгІИУФмЙЛЪЪгІЭјТчОжВПЕФБфЛЏЃЌЕБЭјТчФГИіОжВПБфЛЏЪБЃЌФмЙЛlocal updatingЃЌВЛашвЊЖдећИіЭјТчжиаТМЦЫуЃЛ
- Community aware: ЯрЫЦЕФНсЕуЃЈНсЙЙЯрЫЦЁЂдкЭјТчжаЕФЮЛжУЯрЫЦЕШЃЉЕФБэеїЃЈrepresentationЃЉгІИУОрРыКмНќЃЛ
- Low dimensional
- Continuous: БэЪОНсЕуЕФЯђСПгІИУЪЧЪЕжЕЯђСПЁЃ
ЙБЯз
- ЕквЛДЮНЋЩюЖШбЇЯАЕФЗНЗЈв§ШыЭјТчЗжЮіжаЃЈЕЋЪЧТлЮФПДЯТРДЃЌИаОѕРяУцОЭskip gramжаЕФШ§ВуЭјТчКЭЬнЖШЯТНЕЗНЗЈФмКЭDLГЖЩЯЕуЙиЯЕЃЉЃЌНЋбЇЯАЕНЕФНсЕуБэеїзїЮЊЭГМЦФЃаЭЕФЪфШыЃЛ
- дкЭјТЗЕФЖрЗжРрШЮЮёЃЈМАЖдУПИіНсЕуНјааЖрЗжРрЃЉжабщжЄСЫDeepwalkЕУЕНЕФНсЕуЯђСПЕФгааЇадЃЌЪЙгУИќЩйЕФЪ§ОнЃЈдРДЕФ40%ЃЉШЁЕУСЫИќКУЕФаЇЙћЃЛ
- ЪЕЯжСЫВЂааМЦЫуНсЕуБэеїЕФЗНЗЈЃЈжївЊЪЧRandom walkПЩвдВЂааЃЉЃЛ
ЪЙгУDeepwalkбЇЯАНсЕуБэеї
ИјЖЈвЛИіЭјТчGЃЌЮЊСЫгУвЛИіЪЕжЕЯђСПБэЪОЭјТЗжаЕФвЛИіНсЕуЃЌИУДгФФаЉЗНУцШыЪжФиЃП
ТлЮФжаНЋгябдНЈФЃЕФММЪѕгУРДЧѓНсЕуЕФБэеїЁЃжївЊНшМјЕФЪЧword2vec [2]жаЕФskip gramЁЃ
| skip gram | deepwalk |
|---|---|
| Ъ§ОнМЏжаЕФбљБОЪЧОфзг | RandomWalkВњЩњЕФНсЕуађСаЃЈЯрЕБгкОфзгЃЉЮЊЪ§ОнМЏ |
| ДЪ/зжЮЊvocabulary | НсЕуЮЊЁБvocabularyЁА |
| жааФДЪгыЦфЩЯЯТЮФгІИУгазюДѓЕФЙВЯжИХТЪ | НсЕугІгыЦфЫцЛњгЮзпађСажаЕФНсЕугазюДѓЕФЙВЯжИХТЪ |
ЫМТЗДѓИХЪЧетбљЕФ
ЪзЯШЃЌЫцЛњГѕЪМЛЏУПИіНсЕуЕФБэеїЃЌСюЫљгаНсЕуЕФБэеїЮЊ
ЁЃ
ЭЈЙ§RandomWalkЃЌвдGжаЕФНсЕуvЮЊRandomWalkЕФЦ№ЕуРДВњЩњвЛИіНсЕуађСаЃЌетбљОЭзїЮЊвЛИібљБОWvЁЃНЋетИібљБОЪфШыЕНskip gramРяЃЌЭЈЙ§зюДѓЛЏRandomWalkжаНсЕуЕФЙВЯжИХТЪРДИќаТ
ЁЃАбЫљгаЕФбљБОЖМХмЭъжЎКѓЃЌЕУЕНЕФ
ОЭЪЧЮвУЧЯывЊЕФGЕФУПИіНсЕуЕФБэеїСЫЁЃ
detail0ЃКЮЊЪВУДПЩвдНЋгябдФЃаЭжаЕФММЪѕгУдкНсЕуБэеїжаЃП
етЖМдДгкpower lawЁЊУнТЩЗжВМЁЃ
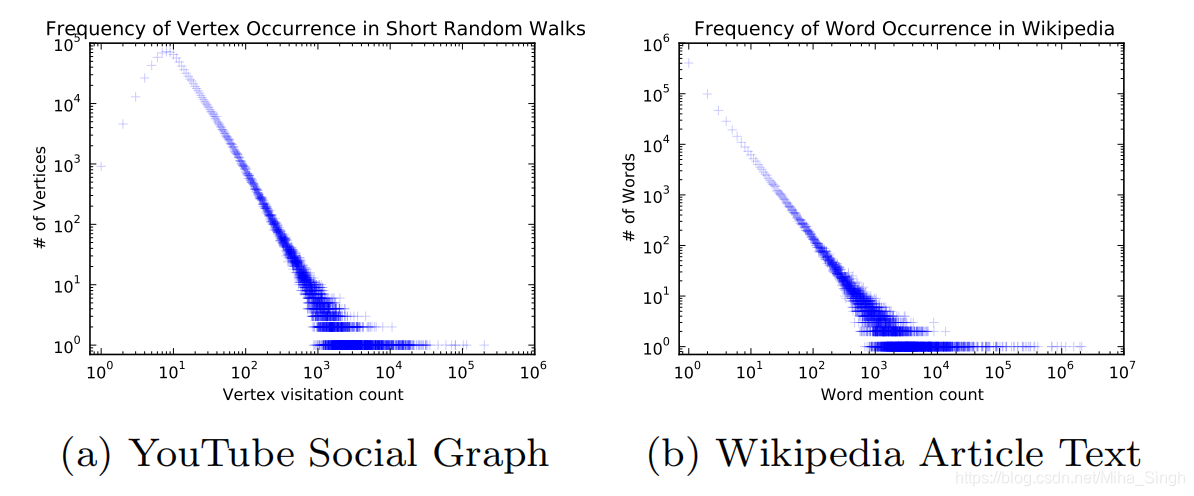
ЮФБОЪ§ОнМЏжаЕЅДЪЦЕТЪЕФЗжВМзёбУнТЩЗжВМЃЌгЩЫцЛњгЮзпађСазщГЩЕФЪ§ОнМЏжаЃЌНсЕуГіЯжЕФЦЕТЪвВзёбУнТЩЗжВМЁЃЩЯЭММДТлЮФжаЕФвЛЗљЭМЃЌЗжБ№ДњБэYouTubeЩчНЛЭјТчжаЫцЛњгЮзпКѓНсЕуЕФЦЕТЪЗжВМКЭWikipediaжаЕЅДЪЕФЦЕТЪЗжВМЁЃетвЛИіЙцТЩЪЧТлЮФжаНЋгябдФЃаЭЕФММЪѕгІгУгкНсЕуБэеїЕФвЛИідвђЁЃ
detail1ЃКЮЊЪВУДзюДѓЛЏНсЕуЕФЙВЯжТЪПЩвдгУРДИќаТ ?
етЛЙвЊДггябдФЃаЭ[3]НВЦ№ЃЌlanguage model ЕФвЛИіФПБъОЭЪЧЙРМЦвЛИіОфзгЕФИХТЪЃЌвбжЊвЛИіОфзг:
ЕБИјЖЈ
ЪБЃЌзюДѓЛЏЯТвЛИіДЪЮЊ
ЕФИХТЪЃЌМД
РрЫЦЕФЃЌЮЊСЫВЖзНзЁНсЕудкЭјТчжаЕФаХЯЂЃЌЮвУЧЯЃЭћ
ЃЈЦфжаv_{0}v_{1}Ёv_{n}ЮЊЫцЛњгЮзпађСаЃЉФмЙЛзюДѓЛЏЃЈОЁПЩФмЕиЗћКЯецЪЕЪ§ОнЃЉЁЃ
ЕЋЪЧЮвУЧВЂВЛЪЧЕЅЕЅЮЊСЫЧѓвЛИіНсЕуађСаЕФИХТЪЃЌЮвУЧЕФФПБъЪЧЮЊСЫЧѓ GжаУПИіНсЕуЕФБэеї ЁЃЛЙМЧЕУЩЯЮФжаЮвУЧЬсЕНЕФ
Т№ЃПЩЯЮФжаЪЧАбЫќЕБзїАќКЌЫљгаНсЕуБэеїЕФвЛИіОиеѓЃЌЕЋЮвУЧвВПЩвдАбЫќЕБзївЛИігГЩфЃЌЪфШыНсЕуЃЌЗЕЛиИУНсЕуЕФБэеїЃЌМД
ЁЃФЧУДЩЯИіЙЋЪНОЭГЩСЫЃК
ЕЋЪЧЫцзХЫцЛњгЮзпГЄЖШЕФдіМгЃЌМЦЫуетИіжЕЛсБфЕУКмКФЪБЁЃ
дк[2] жаЬсГіСЫCBOWКЭSkipGramФЃаЭЃЌЖМЪЧгУРДЩњГЩДЪЯђСПЕФЗНЗЈЃЌЕЋЪЧCBOWЪЧЭЈЙ§ЩЯЯТЮФдЄВтжааФДЪЕФЗНЗЈРДбЇЯАДЪЯђСПЃЌSkipGramЪЧЭЈЙ§жааФДЪРДдЄВтЩЯЯТЮФЕФЗНЗЈЃЌШчЭМЫљЪОЃК
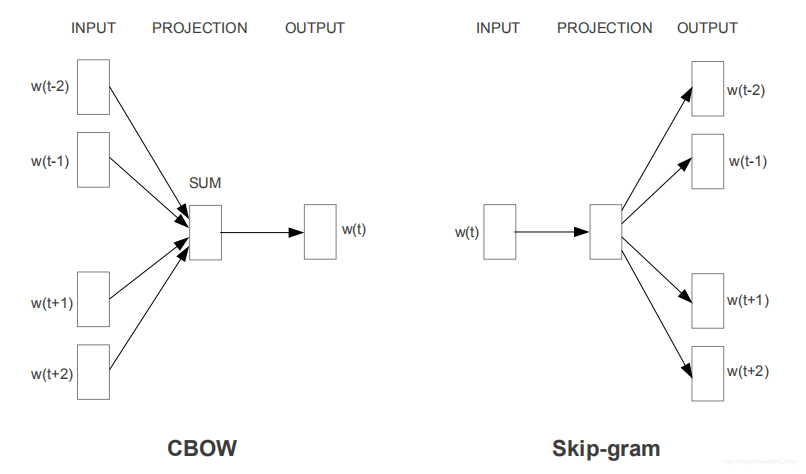
ТлЮФжаВЛШЅЧѓ
зЊЖјШЅЧѓ
ЦфжаwЪЧskip-gramЫуЗЈжаЕФДАПкЕФДѓаЁЁЃ
ТлЮФжав§ШыСЫвЛИіМйЩшЃКНсЕужЎМфЪЧЯрЛЅЖРСЂЕФЁЃв§ШыетИіМйЩшгаСНИідвђЃК
- МйЩшНсЕужЎМфЪЧЯрЛЅЖРСЂЕФИќКУЕФВЖзНСЫЫцЛњгЮзпжаНсЕуМфЕФЁАСйНќ(nearness)ЁБЃЛ
- МгЫйМЦЫуЃЛ
ИљОнетИіМйЩшОЭгаЃК
зюДѓЛЏетИіжЕОЭЪЧЮвУЧЕФФПБъЁЃ
detail2ЃКHierarchical treeЃП
МШШЛЮвУЧвбОЛёЕУСЫвЊгХЛЏЕФФПБъЃЌФЧОЭПЩвджБНгШЅЫуСЫТ№ЃПNoЃЁNoЃЁNoЃЁ
ЖдгкУПвЛИіНсЕуЖдЖМШЅМЦЫу
ЪЧВЛПЩааЕФЁЃТлЮФжав§ШыСЫHierarchical SoftmaxРДНЕЕЭМЦЫуФбЖШЁЃЪзЯШЃЌвдУПИіНсЕудкЫљгаЫцЛњгЮзпађСажаГіЯжЕФЦЕТЪЙЙНЈHuffman treeЁЃ

дкТлЮФжаВЂУЛгаЖдHierarchical SoftmaxНјааЙ§ЖрЕФНщЩмЃЌЕЋЪЧдкword2vecЯрЙиЕФзЪСЯжагаНЯЖрНВНтЁЃ
дкМЦЫу
ЪБЃЌНЋЦфзЊЛЏЮЊдкЙЙНЈКУЕФHuffman treeжаЃЌДгИљНкЕуЕНвЖзгНкЕуЕФИХТЪЁЃР§ШчМЦЫу
ЪБЃЌДгИљНкЕуЕНвЖзгНсЕу
ЫљОЙ§ЕФНсЕуЮЊ
ЃЌдђ
ФЧУДЮЪЬтРДСЫЃЌ
ИУдѕУДЫуФиЃП
ТлЮФжаЪЧетбљНщЩмЕФЃКИјУПИіФкВПНсЕуИГгшвЛИіЖјЗжРрЦїЃЌетИіЗжРрЦїОіЖЈбЁдёИУНсЕуЕФзѓгвзгНсЕуЕФИХТЪЁЃЫљвдДгИљНкЕуПЊЪМЕНвЖзгНсЕуЃЌЯрЕБгкДгИљНсЕуЕФзпЕНвЖзгНсЕуЃЌВЛЖЯНјааЯђзѓЁЂЯђгвЕФбЁдёЁЃЫљвд
ЕФМЦЫуЗНЗЈЮЊЃК
ЕФИИНсЕу
бЁдёЗНЯђЪБбЁдё
ЕФИХТЪЁЃ
Deepwalk ЮБДњТы


ДгЫуЗЈЕФЮБДњТыПЩвдПДГіЃЌЫљгаНсЕуЕФБэеї
ДгОљдШЗжВМжаНјааВЩбљЃЌШЛКѓЙЙНЈHuffman treeЃЌЮБДњТыжаHuffman treeЕФЙЙНЈЪЕдкrandomwalkжЎЧАЃЌЕЋЪЧдкТлЮФжаЬсЕНСЫНјвЛВНМгЫйЫуЗЈЕФЗНЗЈОЭЪЧвРОнЫцЛњгЮзпЕФЪ§ОнМЏЙЙНЈHuffman treeЁЃЭЈЙ§ЫцЛњгЮзпЛёЕУЫцЛњгЮзпађСаЕФЪ§ОнМЏКѓЃЌОЭЭЈЙ§skip-gramКЭSGDЗНЗЈИќаТ
ЁЃ
DeepwalkЕФдДТыЃКdeepwalk
ЙигкdeepwalkдДТыЕФвЛИіЮЪЬтЃК
дкWindows10ЦНЬЈдЫааДњТыЪБЃЌгавЛИіbugЃКAttributeError: ЁЎNoneTypeЁЏ object has no attribute ЁЎnodesЁЏЁЃ
двђЪЧвђЮЊDeepwalkжаЪЙгУСЫЖрНјГЬЃЌдкpythonЕФЖрНјГЬМфФЌШЯЪЧВЛЙВЯэБфСПЕФЁЃОпЬхЕФНтОіЗНЗЈПЩвдПДDeepwalkЕФGitHubжаЕФ issues 54ЁЃ
ВЮПМЮФЯз
[1] Perozzi, Bryan, et al. ЁАDeepWalk: Online Learning of Social Representations.ЁБ Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014, pp. 701ЈC710.
[2] Mikolov, Tomas, et al. ЁАEfficient Estimation of Word Representations in Vector Space.ЁБ ICLR (Workshop Poster), 2013.
[3] Bengio, Yoshua, et al. ЁАA Neural Probabilistic Language Model.ЁБ Journal of Machine Learning Research, vol. 3, no. 6, 2003, pp. 1137ЈC1155.