论文百度一下 官网可以下载。
题目:Iris Recognition With Off-the-Shelf CNN Features: A Deep Learning Perspective 虹膜识别与现成的CNN特征:深度学习的观点 文章发表在IEEE Access·2017年12月
Abstract
虹膜识别是指根据虹膜特征自动识别个体的过程。虹膜基质表面上的随机性使其成为生物识别的独特线索。通过投射到Gabor小波上,并将随后的相量响应转换成二进制码,可以有效地提取和编码个人虹膜图案的细微纹理差异——这是Daugman首创的一项技术。该结构描述符具有很低的伪匹配率和较低的计算复杂度,是一种鲁棒的特征描述符。然而,最近在深度学习和计算机视觉方面的进步表明,使用卷积神经网络(CNNs)提取的通用描述符能够代表复杂的图像特征。鉴于cnn在ImageNet大规模视觉识别挑战(ILSVRC)和大量其他计算机视觉任务上的优越性能,在本文中,我们探讨了最先进的预训练cnn在虹膜识别上的性能。我们发现,在ND-CrossSensor-2013和castia - iris - thousand这两个虹膜数据集上,原本训练用于分类通用对象的现成CNN特征,在表现虹膜图像方面也表现得非常出色,能够有效地提取识别性视觉特征,并取得了很好的识别结果。我们还讨论了利用深度学习方法来解决虹膜识别问题的挑战和未来的研究方向。
索引术语-虹膜识别,生物识别,深度学习,卷积神经网络。
I. INTRODUCTION
虹膜识别是指根据虹膜模式自动识别个体的过程。虹膜识别算法在大型数据库中显示出非常低的误匹配率和非常高的匹配效率。考虑到(a)虹膜基质复杂的结构模式在个体间差异显著(也就是说个体之间差异性明显的意思),(b)其识别特性的持久性,(应该说的是长久再去识别,一个人的虹膜信息是不会改变的意思)?其有限的遗传外显率[(不懂啥意思)1]-[5],这并不完全令人惊讶。由国家科学技术研究所(NIST)进行的大规模评估进一步强调了在操作场景[6]、[7]中虹膜识别令人印象深刻的识别精度。根据2014年[8]的一份报告,全世界有超过10亿人通过电子手段将他们的虹膜图像登记在了各种数据库中。这包括约10亿人在印度独特身份认证权威(UIDAI)计划,1.6亿人来自印尼的国家身份证计划,1000万人来自美国国防部计划。因此,虹膜很可能在下一代大规模识别系统中发挥关键作用。
最先进的文献:虹膜识别的成功——除了它吸引人的物理特征——植根于有效特征描述符的发展,特别是Daugman的开创性工作[3],[5],[9]中引入的Gabor相位象限特征描述符。Gabor phasequadrant特征描述符(通常称为iriscode)在虹膜识别领域占据主导地位,具有非常低的误匹配率和很高的匹配效率。研究人员还基于离散余弦变换(DCT)[10]、离散傅里叶变换(DFT)[11]、序数测度[12]、类特定权重映射[13]、压缩感知和稀疏编码[14]、层次视觉编码[15]、多尺度泰勒展开[16]、[17]等提出了广泛的虹膜描述符。读者可以参考[18]-[21]来获得广泛的用于虹膜识别的方法列表。
分歧:鉴于古典纹理描述符对虹膜识别的广泛使用,包括伽柏phase-quadrant特征描述符,是有益的后退一步,回答下面的问题:我们如何知道在文献中提出的这些手工制作的特征描述符实际上是虹膜的最佳表征?此外,通过设计一种新的特征表示方案,以较低的计算复杂度获得虹膜识别精度的上界,是否可以获得更好的性能(与基于gaborbased的方法相比)?
可能的解决方案:一个可能的解决方案是利用最近在深度学习(主要是数据驱动的)方面的进展来发现特征表示方案。通过自动学习虹膜数据的特征表示,可以推断出一种最优的表示方案,从而为虹膜识别任务带来较高的识别结果。深度学习技术通常使用分层的多层网络来引出特征图,从而优化训练数据[22]的性能。这些网络允许从数据中直接学习和发现特征表示方案,并避免了开发手工特征时的一些陷阱。深度学习已经完全改变了许多计算机视觉任务的表现[23],[24]。因此,我们假设,卷积神经网络(CNNs)所代表的深度学习技术,可以用于为虹膜识别问题设计出可以替换的特征描述符。
为什么深虹膜方法还没有广泛应用?已经有一些尝试将深度学习的原理应用于虹膜识别[25],[26]。深度学习方法在虹膜识别问题上的应用之所以有限,是因为深度学习需要大量的训练数据,而这是目前大多数虹膜研究者都无法获得的。此外,深度学习在计算上也非常昂贵,并且需要多个图形处理单元(gpu)的能力。这对这种深度学习方法的实际实施是一种威慑。最重要的是,到目前为止,还没有深入了解为什么深度学习应该为虹膜识别工作,并没有进行系统分析,以确定如何最好地利用深度学习方法设计一个最优结构的深层网络实现高精度和低计算复杂度。如果没有直观的洞察力,简单地叠加多层来设计一个用于虹膜识别的CNN,将是不可行的(由于公共领域缺乏大规模虹膜数据集),非最佳的(由于CNN架构的特殊选择,层的数量,层的配置…)和低效的(由于冗余的层)。
我们认为,与其设计和训练新的神经网络用于虹膜识别,不如使用那些已经在大规模计算机视觉挑战中被证明是成功的神经网络,在没有时间消耗的结构设计步骤的情况下,可以产生良好的性能。最新CNNs的主要来源是ImageNet大尺度视觉识别挑战(ILSVRC)[27],每年组织一次,以评估用于大尺度目标检测和图像分类的最新算法。作为这项挑战的一部分而开发的网络通常在公共领域可用,用于从图像中提取深层特征。研究人员发现,这些现成的CNN特征对于各种计算机视觉任务,如面部表情分类、动作识别和视觉实例检索,都是非常有效的,并不局限于[28]所设计的目标检测和图像分类任务。在本文中,我们将研究自2012年以来在ILSVRC挑战书中获胜的cnn的性能(在2012年之前,获胜的是非cnn方法,其性能不如基于cnn的方法)。
本文的主要贡献如下: ?首先,我们分析了文献中提出的用于虹膜识别的深层结构。?其次,我们将现成的cnn应用于虹膜识别问题,并使用它们给出我们的初步结果。?第三,我们讨论了虹膜识别的挑战和深度学习的未来。
本文的其余部分组织如下:第二部分简要介绍cnn:第二部分- a部分讨论一般cnn的相关工作,而第二部分- b部分讨论已被提出用于虹膜识别的cnn。第三部分描述了在这项工作中使用的现成的cnn,以及我们为调查这些性能而提出的cnns框架。第四节给出实验结果。第五节对今后的工作进行了讨论,并以此作为论文的结尾。
II. RELATED WORK
A. CNNs - Convolutional Neural Networks
近年来,深度学习方法,特别是卷积神经网络(CNNs),在许多计算机视觉任务上取得了突破,如目标检测和识别,图像分割和字幕(这是捕获的意思??)[22]-[24]。通过使用分层的多层网络,试图模拟人类视觉皮层神经元的结构和操作,深度学习已经被证明在从训练数据中自动学习特征表示方案的过程中非常有效,,从而消除了艰苦的工程任务。CNNs属于一种专门用于处理图像和视频的深度学习方法。通过使用卷积层形式的重复神经元块,神经网络不仅能够自动学习图像特征表示,而且优于许多传统手工制作的特征技术[29]。
20世纪60年代,胡贝尔和威塞尔发现,动物视觉皮层中的细胞负责探测接收区中的光线,并构建图像[30]。此外,他们还演示了这个视野可以用地形图来表示。后来,福岛提出了新cognitron,可以说是CNN[31]的前身。具有开创性的现代CNN是由Yan Lecun等人在20世纪90年代引入的,用于手写数字识别,其架构被称为LeNet[32]。现代深度网络的许多特性源自于LeNet,其中引入了卷积连接,并使用了反向传播算法来训练网络。2012年Krizhesky等人推出的AlexNet CNN在ImageNet大规模视觉识别挑战(ILSVRC)[33]上明显优于之前的方法,CNN变得异常流行。AlexNet只是具有更深结构的LeNet的一个缩放版本,但是它是在一个更大的数据集(ImageNet有1400万张图像)上进行训练的,并且具有更强大的计算资源(gpu)。(不重要的介绍)
此后,许多新颖的架构和高效的学习技术被引入,使CNNs[34] -[37]更加深入和强大,在广泛的计算机视觉应用中实现了革命性的性能。一年一度的ILSVRC活动已经成为表彰CNN新架构表现的重要场所,尤其是谷歌、微软、Facebook等科技巨头的参与。获奖cnn的深度从2012年的8层逐步增加到2015年的152层,识别错误率从2012年的16.4%大幅下降到2015年的3.57%。这一惊人的进展如图1所示。
经过预处理的cnn已经开源并广泛应用于其他应用,表现出了很好的性能。
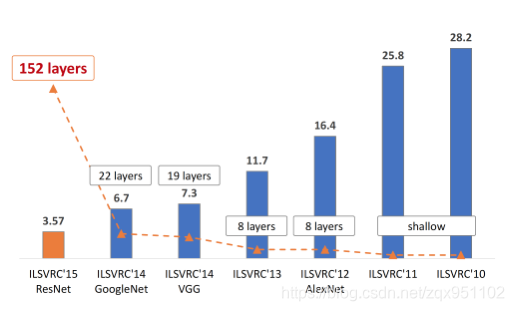
图一2010年至2015年ImageNet大型视觉识别挑战赛获奖作品的演变。自2012年以来,cnn的表现大大优于手工描述符和浅层网络
B. CNNs for iris recognition in the literature
为了提高虹膜识别的性能,许多深度网络被提出。Liu等人提出的DeepIris网络由9层组成,包括一对过滤层、一个卷积层、两个池化层、两个归一化层、两个局部层和一个全连接层[38]。这种深度网络在Q-FIRE[39]和CASIA[40]数据集上都取得了很好的识别率。Gangwar等人使用更高级的层创建了两个DeepIrisNets用于虹膜识别任务**[25]。第一个网络DeepIrisNet-A包含8个卷积层(每个层后面跟着一个批处理归一化层)、4个池化层、3个完全连接层和2个dropout层。第二个网络DeepIrisNet-B增加了两个inception层来增加模型的能力。这两个网络在ND-IRIS-0405[41]和ND-CrossSensor-Iris-2013[41]数据集上表现出了优越的性能。值得一提的是,cnn在虹膜生物识别领域也被用于虹膜分割[42]、[43]、spoof检测[44]、[45]和性别分类[46]。虽然自设计的cnn如DeepIris[38]和DeepIrisNet[25]已经取得了很好的效果,但它们的主要限制在于网络的设计,因为层数的选择受到了训练样本数量的限制。目前可用的最大的公共数据集是nd - crosssensor2013数据集,它只包含116,564张虹膜图像**。这个数字远不及体现深度神经网络的数百万个参数。
为了解决虹膜缺乏大型数据集的问题,可以采用迁移学习的方法。在这里,在ImageNet[47]等其他大数据集上训练过的CNNs可以直接用于虹膜识别领域。事实上,在ImageNet上预先训练的CNN模型,已经成功地转移到许多计算机视觉任务[28]上。**Minaee等人的研究表明,尽管VGG模型在ImageNet上预先训练过将不同类别的物体进行分类,但它在[26]虹膜识别任务中表现得很好。**然而,自从VGG模型在2014年发布以来,文献中已经提出了许多其他的高级架构。在本文中,我们将利用这样的CNN架构-主要是那些已经赢得了ImageNet挑战——应用在虹膜识别任务。
III. METHODS - OFF-THE-SHELF CNN FEATURES FOR IRIS RECOGNITION
考虑到CNN在计算机视觉领域的主导地位和受最近的研究[28]的启发,现成的CNN特性对于多个分类和识别任务的工作非常有效,我们调查的性能最先进的CNN pre-trained ImageNet数据集上的虹膜识别的任务。我们首先回顾了一些流行的CNN结构,然后提出了我们的虹膜识别框架使用这些CNN特征。
A. CNNs in use
现在,我们将详细分析每个架构并突出显示它们的显著属性。
AlexNet :2012年,Krizhevsky等人[33]在大规模的ILSVRC挑战中取得了突破,他们利用了一个深度CNN,明显优于其他手工制作的特性,导致了16.4%的前5个错误率。AlexNet实际上是传统LeNet的一个缩放版本,它利用了大规模的训练数据集(ImageNet)和更多的计算能力(gpu可以在训练中加速10倍)。优化AlexNet的超参数可以获得更好的性能,随后赢得了ILSVCR 2013挑战赛[48]。附录中介绍了AlexNet的详细架构。在本文中,我们提取所有卷积层(5)和所有全连接层(2)的输出来生成用于虹膜识别任务的CNN特征。(也可以自己定义全连接层的参数)
VGG2014年,来自牛津大学的Simonyan和Zisserman展示了在每个卷积层中使用更小的滤波器(3×3)可以提高性能。直觉是,多个连续的小滤波器可以模拟大滤波器的效果。在整个网络中使用小型滤波器的简单性导致了非常好的泛化性能。基于这些观察,他们引入了一种称为VGG的网络,由于其简单性和良好的泛化性能[34],至今仍被广泛使用。已经引入了多个版本的VGG,但最流行的两个版本是VGG-16和VGG-19,分别包含16和19层。(不算池化的)VGG的详细架构在附录中给出。在本文中,我们提取所有卷积层(16)和所有全连接层(2)的输出来生成用于虹膜识别任务的CNN特征。(最后一层分类去掉了)
(GoogLeNet 和VGG都是2014年的)
GoogLeNet and Inception: 2014年ILSVRC获奖作品《GoogLeNet》中,来自谷歌的Szegedy等人介绍了Inception v1架构,该架构在2014年ILSVRC获奖作品《GoogLeNet》中实现,错误率位居前5位,为6.7%。主要的创新是引入了一个inception模块,它的功能是在一个更大的网络[35]内部有一个小网络。新的见解是,在调用昂贵的并行块之前(GPU),使用1×1卷积块来聚合和减少特性的数量。这有助于以更好的方式组合卷积特性,而仅仅堆叠更多的卷积层是不可能的。后来,作者在批处理规范化方面做了一些改进,并重新设计inception模块中的过滤器安排,以创建inceptionv2和v3[49]。最近,他们添加了剩余连接来改进在inceptionv4[50]中的梯度流。(就是借鉴了何凯明的resnet残差思想,创建了InceptionV4结构)在inception-v3的详细架构在附录中给出。在本文中,我们提取所有卷积层(5)和所有inception layers(12)的输出来生成用于虹膜识别任务的CNN特征。
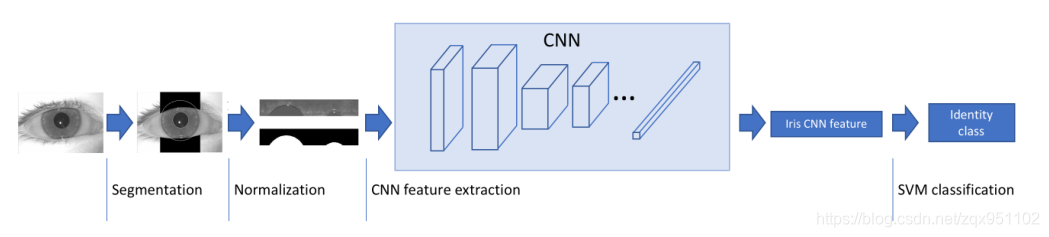
图2所示。使用现成的CNN特征的虹膜识别框架。利用两个圆形轮廓线对虹膜图像进行分割,然后利用伪极变换对图像进行几何归一化,得到固定的矩形图像。接下来使用现成的cnn提取特征,然后使用支持向量机进行分类。
ResNet 2015年ILSVRC 2015年获奖者:微软的He等人在2015年引入了残差连接(residual connection)或跳过连接(skip connection)的概念,将连续两个卷积层的输出输入绕过到下一层[36]。这种剩余连接改善了网络中的梯度流,允许网络变得非常深,有152层。该网络在2015年的ILSVRC挑战赛中以3.57%的错误率排名前5。附录中给出了ResNet-152的详细架构。在本文中,我们提取所有卷积层(1)和所有瓶颈层(17)的输出来生成用于虹膜识别任务的CNN特征。
DenseNet: 2016年Facebook的Huang等人提出了DenseNet,以前馈方式将CNN的每一层连接到每一层。正如作者所指出的,使用密集连接的架构会带来几个好处:“缓解消失梯度问题,加强特性传播,鼓励特性重用,并大幅减少参数的数量”。DenseNet-201的详细架构在附录中给出。在本文中,我们提取一个选定的密集层数(15)的输出来生成用于虹膜识别任务的CNN特征。
值得注意的是,文献[29]、[51]中还有其他几个强大的CNN架构。然而,我们仅选择上述架构来说明预训练的cnn在虹膜识别任务中的表现。
B. Iris recognition framework using CNN Features
图2总结了我们用来研究用于虹膜识别的现成CNN特征的性能的框架。
分割:首先通过提取虹膜内外边界的两个圆形轮廓进行虹膜区域的虹膜局部化。积分-微分算子是最常用的圆探测器之一,它在数学上可以表示为:
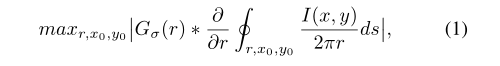
其中I(x, y)和G分别表示输入图像和高斯模糊滤波器。符号?表示一个卷积运算,r表示圆心位置(x0, y0)的圆弧ds的半径。所述的操作通过迭代搜索参数(x0, y0, r)定义的轮廓的最大响应来检测圆形边缘,在大多数情况下,虹膜区域可以被上下眼睑和睫毛模糊。在这样的图像中,利用上述算子可以将轮廓积分路径由圆变为圆弧进行眼睑局部化。噪声口罩区分虹膜像素和非虹膜像素(如睫毛、眼睑等)在给定的图像。在分割阶段生成相应于每个输入图像的噪声掩模,并用于后续步骤。
归一化:虹膜内外边界所包围的区域会因瞳孔的扩张和收缩而变化。在比较不同的虹膜图像之前,需要尽量减少这种变化的影响。为此,通常将分割出的虹膜区域映射到固定维数的区域。Daugman提出使用橡胶片模型将分割的虹膜转换为固定的矩形区域。这个过程是通过将虹膜区域I(x, y)从原始的笛卡尔坐标(x, y)重新映射到无量纲极坐标(r, lai)来实现的,其数学表达式为:
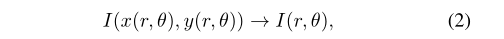
式中,r为单位区间[0,1],伏莱为范围[0,2,[]的角度。x(r, lv)和y(r, lv)被定义为瞳孔(xp(lv), yp(lv))和边缘边界点(xs(lv), ys(lv))的线性组合,
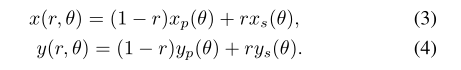
规范化的另一个好处是眼睛的旋转(例如,由于头部的运动)在匹配过程中被简化为简单的翻译。相应的噪声掩码也被规范化,以便在后面的阶段更容易匹配。
图3所示。样本图像来自LG2200(第一行)和CASIA-Iris-Thousand(第二行)数据集。
CNN特征提取:将归一化后的虹膜图像送入CNN特征提取模块。如前所述,本研究使用五种最先进和现有的CNNs (AlexNet、VGG、谷歌Inception、ResNet和DenseNet)从归一化虹膜图像中提取特征。注意,每个CNN都有多个层。每一层对图像中的可视内容进行不同级别的建模,较晚的层编码更精细和更抽象的信息,较早的层保留较粗糙的信息。cnn在计算机视觉任务中表现出色的一个关键原因是,这些有数千万或数百层和数百万个参数的深度网络非常擅长捕捉和编码图像的复杂特征,从而获得卓越的性能。为了研究虹膜识别任务中每一层的表示能力,我们将每一层的输出作为特征描述符,并报告相应的识别精度。(***这是啥意思?每一层都把特征输出?然后测试识别精度??可疑的操作奥,底层特征都是线特征。高层特征都是抽象的特征,这是想选那层特征比较好吗??***)
SVM分类:将提取的CNN特征向量送入分类模块。我们使用一个简单的多类支持向量机(SVM)[52],因为它在图像分类中的流行度和效率。针对N类的多类支持向量机被实现为一个对所有的策略,这相当于结合N个二值支持向量机分类器,每个分类器将一个类与所有其他类区分开来。测试样本被分配给边际最大的类。(现在用svm不多了,后面可以直接自己定义一个分类器层,去分类。很多迁移学习网络都是这样设置的。)
IV. EXPERIMENTAL RESULTS
A. Datasets
我们在两个大型虹膜数据集上进行实验:1)LG2200数据集:ND-CrossSensor-Iris-2013是文献中图像数量最大的公开虹膜数据集[41]。nd - crosssensor2013数据集包含由LG2200虹膜摄像机从676名受试者采集的116,564张虹膜图像。2) CASIA-Iris-Thousand:包含来自1000名受试者的20,000张虹膜图像,使用IrisKing[40]公司的ikembo -100相机采集。图3描述了来自这两个数据集的一些示例图像。
B. Performance metric and baseline method绩效度量和基线方法(说白了就是评价的标注是靠识别率还是什么)
如何确定性能,我们依赖于识别率。识别率按正确率的比例计算,以预先定义的误接受率(FAR)分类样本。在本研究中,我们选择报告FAR = 0.1%的识别率。
我们用于比较的基线特征描述符是Gabor相位象限特征[3]。与此描述符耦合的流行匹配操作符是汉明距离[3]。该基线在LG2200和casia - iris - 1000数据集上分别实现了91.1%和90.7%的识别准确率。
C. Experimental setup
将受试者的左虹膜和右虹膜图像分为两类。因此,LG2200数据集有1352个类,而casia - iris - 1000有2000个类。我们随机选择每个类对应的70%的数据进行训练,剩下的30%进行测试。必须注意的是,训练图像仅用于训练多类支持向量机;使用训练数据对预训练的cnn完全不做任何修改。这是使用预先训练好的cnn的主要优势之一。(也就是说训练集训练的是svm分类器,对cnn这些网络架构不影响)
对于虹膜分割和归一化,我们使用的是来自萨尔茨堡大学[53]的开源软件USIT v2.2。本软件将每幅虹膜图像作为输入,对其进行内外圆分割,并将分割后的区域归一化为大小为64×256像素的矩形。
对于CNN的feature extraction,我们使用PyTorch[54]来实现我们的方法。PyTorch是Facebook最近发布的深度学习框架,结合了Torch和Python的优点。该框架的两个最先进的特性是动态图计算和命令式编程,这使得深度网络编码更加灵活和强大。在我们的实验中,PyTorch提供了广泛的预训练的现成的cnn,使得我们的特征提取任务更加方便。
为了进行分类,我们使用了LIBSVM库[55]和一个在scikiti - learning库[56]中实现的Python包装器,它允许轻松地与特征提取步骤集成。(LIBSVM库这个库好像是方便调用svm分类器的,pytorch中要引入sklearn)
D. Performance analysis
如前所述,不同的层编码不同级别的可视内容。**为了研究每一层的性能,我们使用每一层的输出作为特征向量来表示虹膜,然后估计识别的准确性。**识别精度如图4所示,分别针对两个数据集:LG2200和CASIA-Iris-Thousand。(这句话解释了我上面的疑问。)先不管这数据的真实性吧,逻辑上解释通了
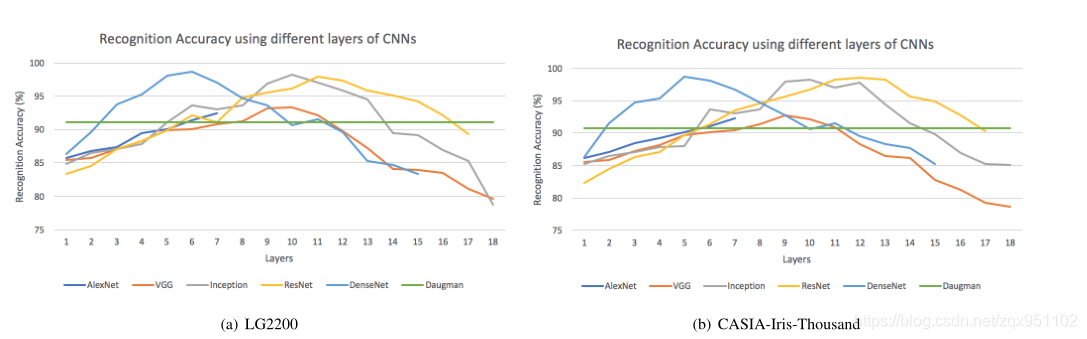
图4所示。(a) LG2200和(b) CASIA-Iris-Thousand两个数据集的cnn不同层的识别精度
有趣的是,所有cnn的识别精度在某些中间层达到顶峰。在LG2200数据集上:第10层用于VGG,第10层用于Inception,第11层用于ResNet,第6层用于DenseNet。在CASIA-Iris-Thousand数据集上:第9层用于VGG,第10层用于Inception,第12层用于ResNet,第5层用于DenseNet。“峰值层”的差异可以通过每个CNN的属性来解释。由于Inception使用复杂的Inception层(实际上每一层都是一个更大的网络中的一个网络),所以它会比其他的更快地收敛到峰值。相比之下,ResNet与它的跳过连接非常擅长允许梯度流通过网络,使得网络在更深的深度上表现良好,导致虹膜识别准确率出现较晚的峰值。DenseNet具有丰富的密集连接,使神经元易于相互作用,使得在虹膜识别任务中,在所有神经网络中识别准确率最高。(也就是说不同的网络架构,提取特征效果表现在不同层输出的特征上)
可以看到,峰值结果不会出现在神经网络的后期层。这可以解释为归一化虹膜图像不像ImageNet数据集中的图像那么复杂,在ImageNet数据集中,大量对象中存在较大的结构变化。因此,对归一化虹膜进行编码并不需要有大量的层。因此,在中间层实现了最高精度。
在所有5个CNNs中,DenseNet在LG2200数据集第6层识别准确率最高,达到98.7%,在casaria - iris - thousand数据集第5层识别准确率最高,达到98.8%。在LG2200数据集上,ResNet和Inception在第11层和第10层的峰值识别准确率分别达到98.0%和98.2%;在CASIA-Iris-Thousand数据集的第12层和第10层,分别是98.5%和98.3%。VGG结构简单,在LG2200和CASIA-Iris-Thousand数据集的第9层上,识别准确率分别只有92.7%和93.1%。AlexNet不断提高的识别精度表明,其体系结构中考虑的层数可能不能完全捕捉到虹膜图像中的鉴别性视觉特征。(这些数据看看就行了。。。。没想明白网络的初始权值咋设置的,是初始化训练还是直接加载的ImageNet的权重,应该是直接按ImageNet权重来的吧)
V. DISCUSSIONS AND CONCLUSION
在本文中,我们从深度学习的角度探讨了虹膜识别的任务。我们的实验表明,现成的预训练CNN特征,即使最初训练用于对象识别问题,也可以用于虹膜识别任务。通过利用来自ILSVRC挑战的最先进的cnn并将其应用于虹膜识别任务,我们在两个大的虹膜数据集中实现了最先进的识别精度,即ND-CrossSensor-2013和CASIA-Iris-Thousand。这些初步的结果表明,可以成功地将现成的CNN特征转移到虹膜识别问题中(这个有意义),从而有效地提取虹膜图像中具有鉴别性的视觉特征,消除了费力的特征工程任务。CNNs在自动化特性工程中的好处是关键是学习新的虹膜编码方案,可以受益于大规模的应用
**Open problems:**这项工作以及之前在DeepIris[38]和DeepIrisNet[25]上的工作表明,CNNs在虹膜识别鉴别特征编码方面是有效的。(本文以及前人工作表明cnns模型是可以提取特征编码的。)尽管如此,在将深度学习应用于虹膜识别问题时,仍存在一些挑战和开放问题。
**Computational complexity:**由于网络中使用了数百万个参数,所以CNNs在训练阶段的计算复杂度非常高。事实上,需要强大的gpu来完成训练。这与手工制作的虹膜特征,尤其是Daugman的Gabor特征相比是不利的,Daugman的Gabor特征可以在一秒钟内提取并比较通用CPU上的数千个虹膜编码。因此,模型约简技术,如剪枝和压缩,可能需要消除冗余的神经元和层,并减少网络的大小。 (这个说的不准确,模型大多数参数都在全连接层,论文作者,调用的全连接,那参数肯定很多,alexnet参数是公认的很多,相比DenseNet参数也没这么多的可怕吧,不过确实在cpu跑DenseNet。。。。很酸爽 哈哈哈 慢慢等几天就运行完了。)
Domain adaptation and fine-tuning:使用现成的cnn的另一种方法是通过微调,这将需要冻结早期的层,只需要再训练一些选择后的层来适应cnn对虹膜图像的表示能力。相对于一般的图像特征,微调是为了学习和编码虹膜特异性特征。此外,还可以采用域自适应的方法将图像域的表示变换为虹膜图像域的表示。(微调可以试试奥,需要冻结这些网络的前面层,留下高层的网络调节参数,如何分类器)明天在接着整理吧 先写这么多 我明天在整理一下!!!!
**Few-shot learning:**如果用于虹膜识别的网络必须从头开始设计和训练,那么训练图像数量有限的问题可以通过一种叫做少镜头学习的技术得到部分解决,这种技术可以使网络在看到每个类的少量样本后表现良好。
Architecture evolution: 进化理论和深度强化学习的最新进展允许网络改变自身,并为手头的问题生成更好的实例。这种方法可以用来发展现有的cnn,以产生更适合虹膜识别的强大网络。
**Other architectures:**在深度学习领域,有其他架构如无监督深度信念网络(DBN),堆叠自动编码器(SAE)和递归神经网络(RNN)。这些结构有其自身的优点,可以用于虹膜图像的特征提取。它们可以单独使用,也可以与经典的cnn结合使用,以提高虹膜模板的表达能力。
额,我也想投个二区Access 好歹也是二区呢 哈哈哈 加油 !! 先打个气!!慢慢来