Ŀ¼
�������ѧϰ�ָ�ı���ȱ�ݼ��
����
��ع���
������㷨
�ָ�����
��������
ѧϰ
����
�ָ���������������
Kolektor����ȱ�����ݼ�
ʵ��
����ָ��
ʵ�ֺ�ѧϰϸ��
�ָ�;�������
�����������
Ҫ��ע�͵ľ���
���Ƚ�ˮƽ�ıȽ�
��ҵ����
ʹ���Ƚ��ķָ�����
���Ѿ�������㷨�Ƚ�
��ѵ������������������
��������
���ۺ��ܽ�
��л
�����
PDF\CODE
�������ѧϰ�ָ�ı���ȱ�ݼ��
Domen Tabernik��domen.tabernik@fri.uni-lj.si����
Samo ?ela��
Jure Skvar��
Danijel Skoaj��danijel.skocaj@fri.uni-lj.si��
part of Springer Nature 2019
ժҪ�����ڻ���ѧϰ�ı���ȱ���Զ�����Ѿ���Ϊһ����Ȥ���з�չǰ�����о������Ӿ�����Ӧ����������˷dz�����ֱ�ӵ�Ӱ�졣���ѧϰ�����ѳ�Ϊ���ʺ���������ķ�������������ȱ�ݼ��ϵͳͨ��ѧϰ����������ʾһЩ����ͼ����������ȱ�ݡ����������һ�����ڱ���ȱ�ݼ��ͷָ�Ļ��ڷָ�����ѧϰ��ϵ�ṹ�������ض��ı������Ƽ�������������ʾ������ϵ�ṹ�����ʹģ���ܹ�ʹ��������������ѵ��������ʵ��Ӧ�õ�һ����ҪҪ��ģ������ص����ѧϰ����(�������Ƚ�����ҵ����)�����˱Ƚϣ���������÷����ڱ������Ƽ����ض�����������صķ�����������ʵ��Ҳ�����չʾ���������ע�����������ѵ���������������������ɱ���ʵ������һ���´����Ļ�����ʵ�������ư��������ݼ��Ͻ��еģ�ʵ����������������ķ����ܹ�������ȱ�ݱ����Ͻ���ѧϰ����ʹ�ô�Լ25 - 30��ȱ��ѵ�������������������ѧϰӦ�ð�����ͨ����Ҫ�ijɰ���ǧ��ѵ����������ʹ�����ѧϰ�����ܹ���ȱ�������������Ĺ�ҵ�ϵõ�ʵ��Ӧ�á����ĵ����ݼ�Ҳ�����ṩ���Թ����������������ڱ���ȱ�ݼ����·�����
�ؼ���������ȱ�ݼ�⣻��ۼ�⣻�������ƣ����ѧϰ��������Ӿ����ָ����磻��ҵ4.0
����
�ڹ�ҵ���������У�ȷ����Ʒ����������Ҫ������֮һ�Ǽ���Ʒ�ı��档ͨ�������������������ֹ����еģ������Ǿ�����ѵ��ʶ���ӵı���ȱ�ݡ�Ȼ�������ֿ��Ʒdz���ʱ��Ч�ʵ��£��������������������������ڹ�ȥ������Ļ����Ӿ��������Խ����Щ���⣨(Paniagua et al. 2010; Bulnes et al. 2016����Ȼ�������Ź�ҵ4.0��ʽ�ķ�չ�����������������ߵ��ձ黯����չ����Ҫ���²�Ʒ�Ŀ�����Ӧ������(Oztemel and Gursev 2018������ͳ�Ļ����Ӿ���������֤����������ԡ�ͨ�����ھ���Ļ����Ӿ������У������������ֹ������ģ�����Ӧ�ض�������Ȼ��ʹ����Ϊ�趨�Ļ��ڹ���ķ�����ʹ�û���ѧϰ�ķ�����(��SVM����������KNN)�������ߡ������ֹ�����������������ʮ����Ҫ�Ľ�ɫ��������ַ������������ѧϰ����ǿ�����˲����顢ֱ��ͼ��С���任����̬ѧ���������������������ֹ������ʵ����������ֹ���������ھ��䷽����ռ����Ҫ�ĵ�λ��������Щ���������ʺ����е��������ڻ����Ӿ����������ֹ���Ӧ��ͬ��Ʒ������£����¿������ڳ�����������������������ѧϰ�������ҵ�һ���������ԵĽ�����������п����ķ������Կ�����Ӧ�����͵IJ�Ʒ�ͱ���ȱ�ݣ�ʹ���ʵ�������ѵ��ͼ��
����������ʹ�����Ƚ��Ļ���ѧϰ����������Ӿ�����ȱ�ݵļ�����⡣�����������ѧϰ�����Ѿ���Ϊ������Ӿ���������ķ�����Ӧ���ڱ���������������(Chen and Ho 2016��Faghih-Roohi et al. 2016��Weimer et al. 2013��Kuo et al. 2014)�����ѧϰ��������ȡ�������Ч�������ҿ��������ڲ�ͬ�IJ�Ʒ���뾭��Ļ����Ӿ�������ȣ����ѧϰ����ֱ�Ӵӵײ�������ѧϰ�������Ը��ӽṹ�ı���������ǿ���Ӷ����Զ�ѧϰ������ȫȡ���ֹ��������������ڶ��²�Ʒ�Ŀ�����Ӧ�����ַ����dz��ʺϹ�ҵ4.0��Ҫ������������ߡ�Ȼ��������δ����������Ȼ���ڣ���Ҫ����ע�����ݣ��Լ�ע����Ҫ�ྫȷ����������ܲ����ʺ�ʵ��Ӧ�ã��ڴ������ѧϰ����ʱ������һ���ر���Ҫ�����⣬��Ϊ�������������ѧϰ���������ģ��ͨ����Ҫ��ǧ��ͼ����ʵ�����������ѻ����Щͼ��
����̽�����ʺ��ڱ����������Ƶ����ѧϰ�������ر��ǣ������о������ѧϰ����Ӧ���ڹ�ҵƷ�������Ƽ��(��ͼ1)�����Dz���������������ܳ��������ӹ�ҵ4.0�ر���Ҫ��������������a��ע������b������ѵ�������������ͣ�c����������ĽǶȳ�����̽���˺��ʵ�����ܹ�������������ͨ������һ���������μܹ�����Ⱦ����������Ч����������ġ������һ���µķָ�;������磬�������ʺϴ�������ȱ��������ѧϰ�������ܻ�����Ƚ��Ľ������������ķ�����һ���㷺����������һ���µġ���ʵ�ı���ΪKolektorSDD�ı���ȱ�����ݼ����еġ������ݼ�������һ����ҵ���Ʒ����ȱ�ݼ�����ʵ���⣬�����������ѵ����ȱ��ͼ������������ġ�ͨ��ǿ��������Ҫ�ķ��棬֤��������ķ����Ѿ��ʺ��о���Ӧ�ó���a��Ϊ�ﵽ100%�ļ����������˹����(ͨ��������˹������֤)����b�������ע��ϸ�ں͵���������˹��˹��ɱ���ѵ�������������Լ���c������ļ���ɱ������о���������Ƶ���������������ص�������ҵ��Ʒ�����ֱ��ָ����硣
���ĵ����½ṹ�������£�����ع������ָ�������ع�������������ķ���������ϸ�����˷ָ�;������硣�ڷָ�;����������۲�����ϸ�����˶�����������Ĺ㷺���ۣ����ڡ������Ƚ��IJ��ֵıȽϡ����������Ƚ�����ҵ������������˱Ƚϡ�������������ۺͽ��۲��ֽ��������ۡ�

��ع���
������AlexNet�ã����ѧϰ������ʼ�������Ӧ���ڱ���ȱ�ݷ������⣨(Krizhevsky et al. 2012����Masci���ˣ�2012���Ĺ������������ڱ���ȱ�ݷ�����ԣ����ѧϰ�������ڴ�ͳ�Ľ��ֹ���Ƶ�������֧�����������ϵĻ����Ӿ�����������ͨ��ʹ�þ������ľ���������Լ��ָ���ȱ�����ͽ���ͼ�������һʵ��֤������һ�㣬��ȡ��������ijɼ�����������û��ʹ��ReLU��batch�������������ǵĹ���������dz�����硣FaghihRoohi����(2016)ʹ�������Ƶļܹ��������·����ȱ�ݡ�����ʹ��ReLU��Ϊ�����������Ըֹ�ȱ�ݷ���ľ�������Լ��������ģ������������
�ھ���������ִ�ʵ���У�Chen��Ho(2016)Ӧ����OverFeat (Sermanet��Eigen 2014)������������ֲ�ͬ���͵ı���������ʶ���˴���������ݣ�������������һ����Ҫ���⣬�����ʹ��һ�����е�Ԥѵ��������������һ���⡣����������ILSVRC2013���ݼ��е�120�����ͨ�Ӿ�����ͼ����ѵ��OverFeat���磬Ȼ��ʹ�ø�������б���ȱ�ݵ�ͼ�����������ȡ����������֧������������������Ļ�����ѧϰ��������֤����Ԥѵ������������LBP����������������Ľ��Ʊ���ֲڶ�����ʽ�㷨�����ǿ��Խ�һ���Ľ��ý����Ȼ�������ǵķ�����û����Ŀ������ѧϰ���磬���û�г���������ѧϰ��DZ����
Weimer����(2016)���������ڱ�����ļ��ֲ�ͬ��ȵ����ѧϰ��ϵ�ṹ������Ӧ�õ������ֻ��5�㵽11�㲻�ȡ����ǵ�����������6�ֲ�ͬ���͵ĺϳ�����ϣ������ʾ������������κξ��䷽�����Ժϳ����ݼ���ƽ�����ȴﵽ99.2%�����ǵķ���Ҳ�ܹ�����λ�ڼ������صľ�ȷ��֮�ڣ����ǣ����ǵĶ�λ����Ч�ʺܵͣ���ÿ��ͼ������ȡС��patch��Ȼ���ÿ��������ͼ��patch���з��ࡣ
Raki����(2018)�����һ�ָ���Ч��ȱ�ݷָ����硣����ʵ����һ��10���ȫ�������磬ͬʱʹ��ReLU��batch��һ����������ȱ�ݽ��зָ���⣬�����ڷָ����������֮�ϣ������һ�����ӵľ����������ȱ���Ƿ���ڶ�ÿ��ͼ������˷��ࡣ��ʹ�����ǿ�����߶Ժϳɱ���ȱ�����ݼ��ķ��ྫ�ȡ�
�����Lin����(2018)�����LEDNet�ܹ�������ʹ��30000�ŵͷֱ���ͼ������ݼ����LEDоƬͼ��ȱ�ݡ����������������ѭAlexNet�ܹ�������ȥ������ȫ���ӵIJ㣬ȡ����֮���Ǽ������༤��ӳ��(CAMs)��������Zhou����(2016)�����������������ѧϰֻʹ��ÿ��ͼ���ǩ��ʹ���ֶ�λ��ȱ�ݡ��봫ͳ������ȣ��������LEDNet��ȱ�ݼ��������������ߡ�
����ط�����ȣ���������ķ�����ѭ�ָ�����;�������������ƣ�������Raki����(2018)�ļܹ���Ȼ�����÷����Էָ�����;�������Ľṹ����һЩ�ı䣬Ŀ�������ӽ���Ұ�Ĵ�С����ǿ���粶Сϸ�ڵ���������һЩ��ع���(Raki et al. 2018��Weimer et al. 2016)��һ��������������DZ�Ӧ������ʵ��������ӣ�������ʹ����Ϊ�ϳɵ����ӡ����о���ʹ�õ����ݼ�Ҳֻ����������ȱ��ѵ������(��30����ȱ�ݵ���Ʒ)�����������ٸ�(Raki et al. 2018��Weimer et al.2016)����ǧ(Lin et al. 2018)����ʹ��һЩ��ص���ϵ�ṹ����LEDNet(Lin et al. 2018)��ֻʹ��ÿ��ͼ��ע�ͺʹ��������������������ڵ�ǰ���������������������٣�ʹ��������Ƶ�ѡ�������Ҫ�����������������ֲ�ͬ�ı������������ָ������Ч������DeepLabv3+ (Chen et al. 2018)��U-Net (Ronneberger et al. 2015)���������������ͨ����������ָͨ��ʹ�ö�ImageNet (Russakovsky et al. 2015)��MS COCO (Lin et al. 2014)���ݼ���120������ͼ�����Ԥѵ����DeepLabv3+���磬Ҳ������ʹ��Ԥѵ��ģ�͵�Ӱ�졣
������㷨
�����쳣���������һ����ֵͼ��������⡣�������ڱ����������ƣ�����������£�ÿ��ͼ�����쳣�ľ�ȷ����ͨ����ȱ�ݵľ�ȷ��λ����Ҫ��Ȼ����Ϊ�˿˷����ѧϰ�������������ٵ����⣬��������ķ���������Ϊ������ƣ���ͼ2��ʾ����һ��ʵ����һ���ָ����磬�Ա���ȱ�ݽ������ض�λ����Ч�ؽ�ÿ��������Ϊһ��������ѵ��������ѵ�����ؼ����ϵ���ʧ���Ӷ�������ѵ����������Ч��������ֹ�˹���ϡ��ڶ��ν��ж�ֵͼ����࣬����һ�����ӵ����磬�����罨���ڷָ�����֮�ϣ�ʹ�÷ָ�����ͷָ��������������һ�������Ϊ�ָ����磬�ڶ��������Ϊ�������硣

�ָ�����
��������11���������3�����ز���ɣ�ÿ���㶼���ֱ��ʽ�����1 / 2��ÿ����������涼��һ��������һ����һ��������ReLU�㣬�ⶼ���������ѧϰ�����е������ٶȡ�������һ����ÿ��ͨ����һ��Ϊ���е�λ��������ֵ�ֲ���ǰ�Ÿ�������ʹ�����ں˴�С�����������ֱ�ʹ��
��
���ں˴�С��Ϊ��ͬ�IJ���䲻ͬ������ͨ��������ܹ�����ϸ������ͼ2��ʾ�����ü������ͨ������
�����㣬�õ����յ������ģ���⽫����һ����ͨ�����ӳ�䣬������ͼ��ķֱ��ʽ�����8�����÷���û��ʹ��Drop-out����Ϊ�������е�Ȩֵ�����ṩ���㹻������
�÷ָ����������ص����ڴ�ֱ���ͼ���м��С�ı���ȱ�ݡ�Ϊ��ʵ����һ�㣬���������������Ҫ��Ҫ����a���ڸ߷ֱ���ͼ������Ҫ�ϴ�Ľ���Ұ����b����Ҫ��С������ϸ�ڡ���Raki����(2018)����ع�����ȣ�����˼ܹ��ļ����ش�仯�����ȣ��ڽϸߵIJ�������һ���²�����ͽϴ�ĺ˳ߴ磬���������ӽ���Ұ�Ĵ�С����Σ�ÿ���²���֮��IJ�����Ϊ�ڽṹ�ĽϵͲ���ӵ�и��ٵIJ㣬�ڽϸ߲���ӵ�и���IJ㡣�������˽���Ұ������������������ʹ�����ض����Ǵ�粽�ľ�����ʵ���²����������ȷ��С����Ҫ��ϸ�������²��������д�����������ھ��ж������²��������������Ϊ��Ҫ��
��������
��������Ľṹʹ�÷ָ�����������Ϊ������������롣�����ȡ�ָ���������һ��������(1024ͨ��)������������ӵ�һ����ͨ���ָ����ӳ�䡣�⽫����1025��ͨ���ľ���������ʾʣ�������룬���а������ز�;������ں˴�С�ľ����㡣��������ظ�3�Σ���һ���ڶ�������������ֱ�Ϊ8��16��32ͨ��������ϵ�ṹ����ϸ������ͼ2��ʾ��ѡ���ͨ���������������ֱ��ʵĽ��Ͷ����ӣ����ÿһ��ļ�����������ͬ�ġ����һ������ķֱ��ʱ�ԭʼͼ��ķֱ���С64�����������ִ��ȫ������ƽ���ػ�������64�������Ԫ�����⣬�ָ����ӳ���ϵ�ȫ�����غ�ƽ���صĽ�������ӳ����������Ԫ��Ϊ�ָ�ӳ���Ѿ���֤������������ṩ��һ����ݷ�ʽ��������ƵĽ����66�������Ԫ������Ȩֵ��ϵ����յ������Ԫ�С���������������ѭ������Ҫԭ�������ȣ����ö��������²����ķ�������֤�˶Դ�������״�ĺ�����������ʹ�����粻���ܹ����ֲ�����״�����һ��ܹ������ͼ��������ȫ����״����Σ��������粻��ʹ��1��1�˽����ŵ�Լ��ǰ�ӷָ�������������һ����������������������ʹ��1��1�˽����ŵ�Լ���õ������շָ����ӳ�䡣���ṩ��һ���ݾ�����������������������ڲ���Ҫ�������ʹ�ô���������ͼ�����������˲�������ʱ�Ĺ���ϡ���ݹ���ʵ�����������棺һ���ھ�������Ŀ�ʼ���֣��ָ����ӳ�䱻���뵽��������ļ�������������У���һ���ھ�����������ղ��֣�ȫ��ƽ�������ֵ�ָ����ӳ����Ϊ����ȫ���Ӳ�����롣��Ra
ki����(2018)����ع�����Ƚϣ��������翪ʼ�Ŀ�ݷ�ʽ�ͼ����Ͳ����ľ�������һ����Ҫ�������뱾������Ĺ�����ȣ������ھ��߲���ֻʹ�õ��㣬��ʹ���²������ھ����в�ֱ��ʹ�÷ָ����ӳ�䣬����ͨ��ȫ�����ֵ��ƽ���ػ����ʹ�á��������˾�������ĸ����ԣ�����ֹ��������ȫ����״��
ѧϰ
�ָ����类ѧϰΪһ�������Ʒָ����⣬��ˣ��������ڵ������ص�ˮƽ�Ͻ��еġ����������ֲ�ͬ��ѵ������:(a)ʹ�þ��о��������ʧ(MSE)�Ļع��(b)ʹ�þ��н�������ʧ�Ķ�Ԫ���ࡣģ��û���������������ݼ���Ԥ��ѵ��������ʹ����̬�ֲ������ʼ����
���ý�������ʧ����ѵ���������硣ѧϰ��ָ������Ƿֿ����еġ����ȣ�ֻ�Էָ�������ж���ѵ����Ȼ��ָ������Ȩֵ��ֻ�Ծ�����������ѵ����ͨ��ֻ�����߲���������˷ָ������д���Ȩֵ�����Ĺ�������⡣ѧϰ���߲�α�ѧϰ�ָ��θ���Ҫ������GPU�ڴ�����ƣ���ѧϰ���߲�ʱ������С������ÿ��ֻ��һ����������������ѧϰ�ָ��ʱ��ͼ���ÿ�����ض�����Ϊһ��������ѵ�������������Ч����С�����˼�����ͬʱ�����˷ָ�����;��������ѧϰ������������£���ʧ����������������Ҫ�����á�ͬʱѧϰֻ�е������ر�������������ʱ�ſ�����������ʧ���õķ�Χ��ͬ����ÿ���ز��ÿͼ���ľ�ȷ��һ������������Ҫ�����á������ȷ�ع淶��������ʧ��֤��������ʵ���б�ʹ�õ�����ѧϰ���Ƹ���ʵ�֣�����Ҳû�д����κ��������档��ˣ�����ѧϰ���Ʊ�֤���Ǹ��õ�ѡ���������ʵ�鶼��������һ���ơ�
����
�������������һ���Ҷ�ͼ������ṹ�������С�أ�������ȫ��������(Long et al. 2015)����Ϊ��feature map�в�ʹ��ȫ���Ӳ㣬������ͨ��ȫ��ƽ�������ػ������ռ�ά��֮���ʹ�á���ˣ���������IJ�ͬ������ͼ������Ǹ߷ֱ��ʻ�ͷֱ��ʡ�����̽��������ͼ��ֱ���:��
��
���������ģ�ͷ��������������һ������Ǵӷָ���������ķָ����롣�÷ָ���ģ��������������ص�ȱ�ݸ��ʣ��������ֱ������������ֱ��ʽ�����8�������ڸ߷ֱ���ͼ����
���ؿ�ķ������Խ����ǰ�����⣬��������ӳ��û�в�ֵ��ԭʼͼ���С���ڶ����������[0,1]��Χ�ڵĸ��ʷ�������ʾ�ɾ������緵�ص�ͼ���г����쳣�ĸ��ʡ�
�ָ���������������
�������ڹ�ҵƷ�������Ƽ���еõ��˹㷺�����ۡ��������Ƚ������ݼ���ϸ�ڣ�Ȼ�����������������ϸ�ڡ�
Kolektor����ȱ�����ݼ�
��ȱ�ٴ��б�ע����ʵ�Ĺ����ĵı���ȱ�����ݼ�������£�������һ���µ����ݼ�����ΪKolektor����ȱ�����ݼ�(KolektorSDD)�������ݼ�����KolektorGroupd.o.o�ṩ��ע�͵�ȱ�ݵ绻����(��ͼ1)��ͼ����ġ������˵���ڵ��ӻ����������ϵı���۲쵽�۲��ֻ����ơ�ÿ���������ı����������ɰ��Ų��ص���ͼ��Ϊ��֤ͼ��ĸ�������ͼ�������ܿػ���������ģ��ֱ���Ϊ���ء����ݼ���50����ȱ�ݵĵ绻������ɣ�ÿ������8����صı��档�����ܹ��õ���400��ͼƬ������ÿһ����Ŀ��ȱ��ֻ��һ��ͼ���пɼ�������ζ����50��ͼ����ȱ���ǿɼ���(����ȱ�ݻ�������Ʒ)��Ϊÿ��ͼ���ṩ����ϸ�����ؼ�ע�����롣ʣ�µ�350��ͼƬ�DZ���û��ȱ�ݵķ������ӡ����пɼ�ȱ�ݺ���ȱ��ͼ���������ͼ3��ʾ��
���⣬���ݼ�ʹ�ü��ֲ�ͬ���͵�ע�ͽ���ע�͡������Ϳ�������������ķ�����ע�͵�ȷ���ڹ�ҵ��������Ϊ��Ҫ��Ҫ��������ע�����ķѵ�������Ϊ�ˣ�ͨ��ʹ�ò�ͬ���ں˴�Сʹ����̬ѧ������չԭʼע�ͣ���������������ע�����ͣ�5��9��13��17���ء�ע�⣬����Ӧ����ԭʼ�ֱ��ʵ�ͼ���ڷֱ���Ϊԭ��һ���ʵ���У�ע�������ڷŴ���С�ˡ����е�ע�ͣ�һ���ֹ�ע��(a)���ĸ�����ע��(b e)����ͼ4��ʾ��

ʵ��
�����������ڲ�ͬ��ѵ�������½���������������ͬ���͵�ע�͡�����������ת�Ͳ�ͬ�ķָ�������ʧ������
�ܵ���˵���������ĸ��������½���������
- ����ע�����ͣ�
- �ָ������������ʧ��������(�������ͽ�����)��
- ����ͼ������ִ�С(ȫ�ߴ�Ͱ�ߴ�)��
- ����ͼ����ת����ת90�Ρ�
ÿ�������鶼���Դ��ĸ�����������������ܡ���ͬ��ע��������������ע�;��ȵ�Ӱ�죬����ͬ��ͼ��ֱ��������Խϵ͵ļ���ɱ������Է������ܵ�Ӱ�졣���⣬�������˲�ͬ����ʧ������Ӱ�죬�Լ���0.5�ĸ�����תͼ��������ѵ�����ݵ�Ӱ�졣
�ڴ˻����ϣ�������ȱ�ݼ������ת��Ϊ��ֵͼ��������⡣��ҪĿ���ǽ�ͼ���Ϊ����:(a)����ȱ�ݺ�(b)������ȱ�ݡ�
��Ȼ���Դӷָ������еõ����ؼ���ȱ�ݷָ�������ڹ�ҵ��������������Ҫ������������ܺ������ؼ������෴��ֻ����ÿ��ͼ��Ķ�ֵͼ��������ָ���������ڿ��ӻ�Ŀ�ġ�
����ָ��
����ͨ�����ν�����֤��ִ�У�ͬʱȷ��ͬһʵ���Ʒ������ͼ����ͬһ����֤�У���˲���ͬʱ������ѵ�����Ͳ��Լ��С�����������ͬ�ķ���ָ��(a)ƽ������(AP)��(b)ƽ�����(FN)��(c)����(FP)����������������������бȽϡ�ע�⣬������ָ�����пɼ�ȱ�ݵ�ͼ������ָ����û�пɼ�ȱ�ݵ�ͼ����������ʹ�õ���Ҫ��������ƽ�����ȡ����FP��FN�����ʣ���Ϊƽ�������Ǽ����ھ�ȷ-�ٻ������µ����������һ����һ��ֵ��ȷ�ز�ģ���ڲ�ͬ��ֵ�µ����ܡ���һ���棬������������(FP��FN)ȡ���������ڷ���������ض���ֵ�����DZ������ڴﵽ���F-measure����ֵ�ϵĴ����������������⣬��ע�⣬ѡ��AP������ROCcurve(AUC)�µ�������ΪAP��ȷ�ز��˾��д�����(������)�����ݼ������ܡ�(����ȱ��)����Ʒ��AUC����ƷҪ�١�
ʵ�ֺ�ѧϰϸ��
����ܹ���TensorFlow�����ʵ��(Abadi et al. 2015)���������綼ʹ�ò�������������ݶ��½�����ѵ����ƽ��ƽ�����(MSE)����0.005��ѧϰ�ʣ���������ʧ����0.1��ѧϰ�ʡ�ÿ�ε���ֻʹ��һ��ͼ��batch��������С������Ϊ1����Ҫ�����ڴ�ͼ���С��GPU�ڴ�����ơ�
��ѧϰ�����У�ѵ�����������ѡȡ�ģ�����ѡȡ���̽������ģ���ȷ������۲쵽��ȱ��ͼ��ͷ�ȱ��ͼ������ƽ�⡣
����ͨ����ÿһ��ż�������л�ȡ��ȱ�ݵ�ͼ����ÿһ�����������л�ȡ��ȱ�ݵ�ͼ����ʵ�ֵġ��û���ȷ��ϵͳ�Ժ㶨�����ʹ۲�ȱ��ͼ��;����ѧϰ�Dz�ƽ��ģ�������û��ȱ�ݵ�����������ѧϰ���Ը�������Ϊ�����ݼ����и����һ��û��ȱ�ݵ�ͼ��Ӧ��ָ�����ǣ���µ�ѵ�����Ƕ���epochs���ģ���Ϊ��ȱ��ͼ�����������ȱ��ͼ��������8����������յ���ͬ��ȱ��ͼ��֮ǰ�����е���ȱ��ͼ��
�������綼��ѵ����6600������33��ȱ��ͼ��ÿ��ѵ�����ڵ�һ�ͽ���֮���ȱ�ݺͷ�ȱ��ͼ����ÿһ������ת��Ϊ100��epoch��ֻ�е�������ȱ�ݵ��������ٱ��۲�һ��ʱ��һ��ʱ���ű���Ϊ�����ˣ�����������û��ȱ�ݵ������뱻�۲쵽��
�ָ�;�������
���ȶ��ɵ�һ�εķָ�����͵ڶ��εľ���������ɵ�������������ۡ���ϸ�����ͼ5��ʾ����ͼ��ʾ�˲�ͬ��ɫ��ע�����͵�ʵ�������Լ�����������ʹ��ͼ����ת��ʵ������������鱨����ȫͼ��ֱ��ʵ�ʵ�飬������鱨����һ��ֱ��ʵ�ʵ�顣�������˳ߴ�(dilate=5)����������ʧ������ȫͼ��ֱ��ʺͲ���תͼ�������£��õ���������õ�ע�͡����������µ�����ﵽ��99.9%��ƽ������(AP)�����������(FP)��һ��������(FN)��
������������ѧϰ���õ�Ӱ�����ͨ���۲�ÿ���������ñ仯��ƽ�����ָĽ���������Ӱ�����ܱ������¸�������:(a)����ʧ�����ı��ָ�����ľ��������ʧ,(b)�ı�һ����С��ͼ��ֱ��ʵ�ͼ��ֱ���,��(c)�ĸı��������ݴ�û����ת��ת��90�ꡣAP������ʵ���е�ƽ���Ľ������ͼ6��ʾ������һ���ض������ø��ģ����磬��ͼ��ֱ��ʴ�������ͼ��ֱ��ʸ���Ϊͼ��ֱ��ʵ�һ�룬����ͨ�������������������п������õ�AP����ý��(��ͼ5��ʾ)��Ȼ���������ֻ�ı���������õ�ʵ��֮���AP���죬���磬ʹ�ð�ͼ��ֱ��ʵ�ʵ���ʹ��ȫͼ��ֱ��ʵ�ʵ�飬�������ö���һ���ġ����ܵ�����Ľ���ͨ��AP����������������õIJ����ƽ��ֵ��ʵ�ֵġ������������ı���Ҳ�ֱ𱻼�¼��
��ʧ�������Ա�ͼ5�еľ��������ʧ(MSE)�ͽ�������ʧ��������������ؿ�����ʹ�ý�������ʧ����ѵ�������������õ����ܡ��ⷴӳ��AP������FP/FN�����У��Լ���ͼ6�������������õ�ƽ�������صĸĽ��С�ƽ�����ԣ���AP�Ͻ����شﵽ��7% (pp)��


ͼ��ֱ�������ͼ6��ʾ������ͼ��ֱ��ʵ������APƽ���½���5%����ϸ�۲�ͼ5���Է��֣���С��ͼ�����MSE��ʧ����ѵ���������кܴ�ĸ���Ӱ�죬���ý���ѵ����������û�С������ضԽ��͵�ͼ��ֱ��ʲ���ô���У�������ijЩ����£����ͷֱ��ʵ�ͼ��������Ժ�һЩ(��AP�д�ԼΪ1%)��ͼ����ת����һ���棬�����תͼ��û�б�֤�������õģ�Ҳû�д����κ�������������������ijЩ����£��������Ϊ1%��Ȼ��������������£������½��ø��ࡣ
ע����������Ա�ͼ5�в�ͬע�����ͣ��ڽ�Сע��(ԭʼע�ͻ�С������)��ѵ���Ϳ��ǽ�������ʧʱ�������ܵĸ���Ӱ�첻�����ֲ�����MSE��ʧ�����и�Ϊ���ԡ��ܵ���˵����õĽ���ƺ���ʵ�������е�������չ�ٶ���չ��ע�͡�
�����������
ͬʱҲ�����˾���������������ܵĹ��ס���һ������ͨ���Ƚ�ǰһ�ڵĽ����ָ����磬�������Ǿ��������������ġ�����������磬һ���Ķ�ά�����������ع鱻ʹ�á����ݷָ����ӳ���ȫ������ֵ��ƽ����ֵ����һ����ά����������Ϊ���ع�����������ع����ڷָ�����ѵ����ɺ�ӷָ������е���ѧϰ�ġ�
�����ͼ7��ʾ������ע���н�������ʧ��ģ��ʱ�������ԣ������÷ָ�����������Ѿ�ȡ���˽Ϻõ�Ч����ͨ��dilate=9ע�ͻ�õ�������ôﵽƽ������(AP)Ϊ98.2%���������(FP)���ļ�����(FN)��Ȼ�������������ڴ����ʵ���ж��Ľ�����һ��������������MSE��ʧ�Ĺ��ϴ�ֻʹ�÷ָ������ʱ��MSE��ʧ������ƽ�����ȴﵽ��С��90%AP�����ǵ�ʹ�þ�������ʱ��MSE��ʧ������AP�ﵽ��95%���ϡ����ڽ�����ѵ�������磬��������Ҳ���������ܵ���ߣ������ڷָ�����������Ѿ��ܺã��Ľ�������С����������ƽ��AP�����3.6%���ﵽ98%���ϡ���������ֵ����������������Ҳ��ͬ�������ƣ���������������ʱ���ָ�����ƽ��4�����������ٵ�ƽ��2��������ࡣ
��Щ��������˾����������Ҫ���á�����������ָ��ƺ�û���㹻����Ϣ��Ԥ��ͼ����ȱ�ݵĴ��ڣ������������һ������һ���棬������ľ��������ܹ������һ��ķḻ�����л�ȡ��Ϣ������ͨ�����߲㣬�ܹ�����ȷ�������з�������������������ж�����²���Ҳ������������ܣ���Ϊ�������˽���Ұ�Ĵ�С��ʹ���������ܹ�����ȱ�ݵ�ȫ����״��������״�Է������Ҫ���������طָ��Ҫ��

Ҫ��ע�͵ľ���
������һ�ڵ�ʵ�����������ע�ͱȾ�ϸע��ִ�еø��á����ڽ�ͨ���������ֵ�ע�ͶԷ������ܵ�Ӱ���һ��̽����һ�㡣Ϊ�ˣ����������ֶ������͵�ע�ͣ���Ϊ:(a)���б߿�Ĵ�ע�ͺ�(b)������ת�߿�Ĵ�ע�͡����ֱ�ע����ͼ8��ʾ���˹�ע����ִ���������͵�ע�������ѵ�ʱ����٣������ڹ�ҵ������Ч�����á�
�����ͼ9��ʾ������֮ǰ��ʵ��֤��MSE��ʧ���������������Ա�ʵ��ֻʹ�þ��н�������ʧ�����硣ʵ�����������ע�͵�ִ��Ч�������;�ϸע��һ���á����Ϊbig��ע�ͱ����Բ���APΪ98.7%����3������࣬����ע�͵�APΪ99.7%����2������ࡣע�⣬���ʹ�ø�С��ͼ��ֱ��ʣ�������ע�Ͷ�����ʵ�����Ƶ�APs�����������������ͬ��
��Щ�����������һ����ͨ������ϸ��ע�ͻ�õĽ��������������һ���У�ֻ��һ�������������99.9%��AP������ϸ��ע��ȷʵ�ܻ�ø��õĽ�������ǣ����ǵ����ּ����ϸ��ע�ͻ��ѵ�ʱ��̫����ʹ�ôֲڵ�ע����Ȼ�ǿ��еģ�����������ʧ��С����û����ʧ��

���Ƚ�ˮƽ�ıȽ�
����ع����ı����£��Լ�������ģ�ͽ����˽�һ��������������������ķ����ı��֡�����������ʾ��һ�����Ƚ�����ҵ��Ʒ���������ָ������ڲ�ͬ��ѵ�������µ����ܡ���Ϊÿһ�����Ƚ��ķ����ṩ����õ���ѵ���ã������������������ܹ����бȽϣ��⽫�ڱ��ڵ������С�
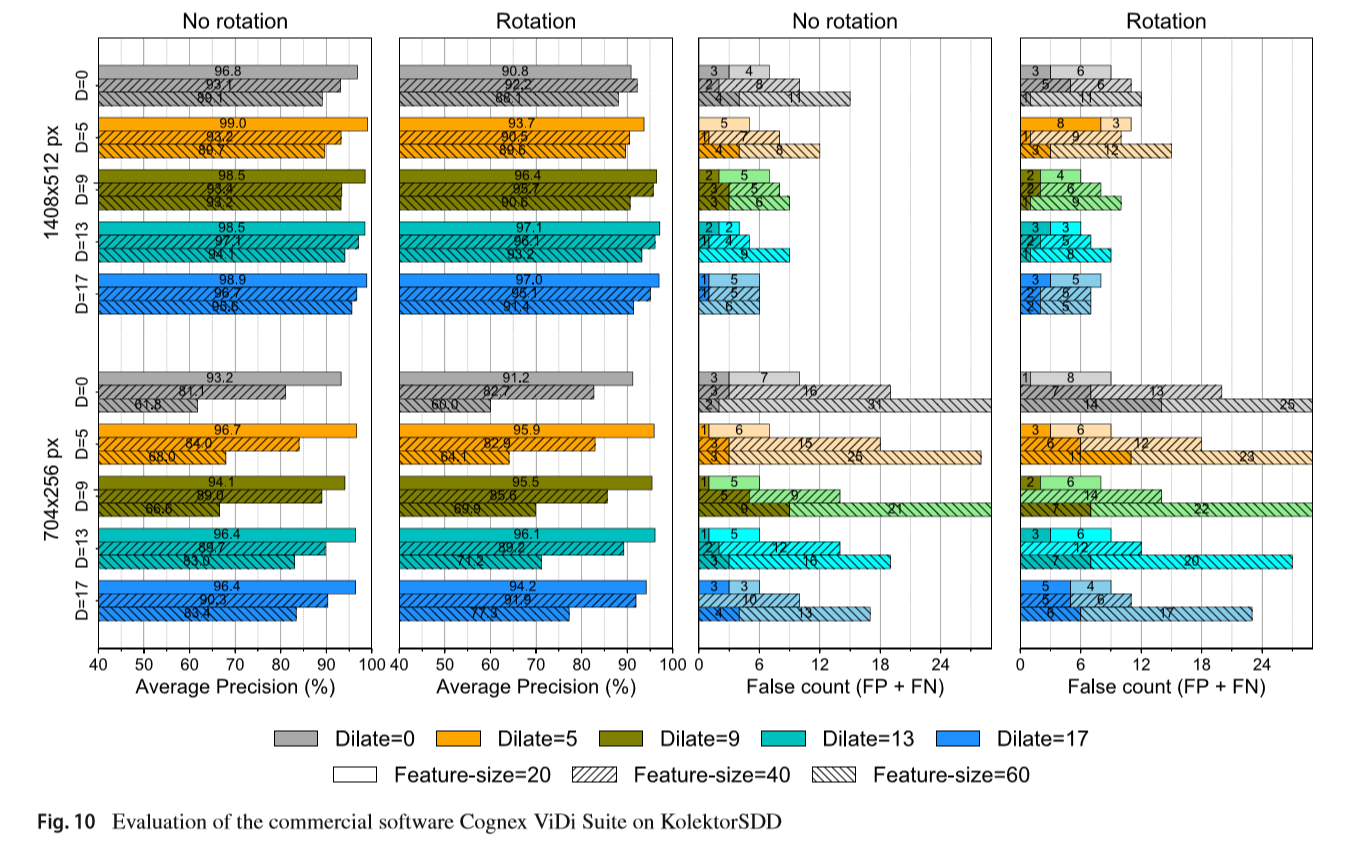
��ҵ����
�����������ǻ������ѧϰ�����Ƚ��Ĺ�ҵͼ�������ҵ����Cognex ViDi Suite (Cognex2018)��Vidi��˾��2012���CSEM����ӱ������CSEM��һ��˽Ӫ�ġ���ӯ������ʿ�о��ͼ�����֯������2017�걻Cognexin�չ�������������������ͬ�����ѧϰ���ߣ�ViDi blue(�̶�����λ)��ViDi Red(�ָ���쳣���)��ViDi green(����ͳ�������)��
Vidi Red��һ�������쳣��⡢�����Ӿ����ͷָ�Ĺ��ߡ��ù��߿������ල��ලģʽ�����С���ǰһ�������ֻ��Ҫ��ȱ��������ͼ���ں�һ�������ֻ��Ҫȱ��������ͼ���û����Դ��ĸ���ͬ������������ֲ���:����(�����ߴ磬��ɫ)��ѵ��(�����¼�Ԫ������ѡ��)���Ŷ�(��ת���������ݺ�ȣ����У���ת�����ȣ��Աȶ�)�ʹ���(�����ܶȣ�������)��
�ڱ����У�����ʹ��Cognex ViDi Suite v2.1��ʵ�鶼���ڼලģʽ��ʹ��ViDi Red���߽��еġ��������ڲ�ͬ��ѧϰ�����½��й㷺�����������ҵ���ѵ��������Ա�����һ������ķ������й�ƽ�ıȽϡ�����ѧϰ���ÿ����ڴ�������
- ����ע�����ͣ�
- ����������С(20,40,60����)��
- ��������ͼ���С(ȫ�ߴ�Ͱ�ߴ�)��
- ����������ת/����ת90�Ρ�
��ͬ�����������ڡ��ָ�;����������������ֵ����ã���֮ͬ�����ڲ�ͬ����ʧ����û�б���������Ϊ����û���ṩ�����ϸ�Ŀ��Ƽ���ȡ����֮����������ͬ��С����������Щ�����Ѿ���֤���ڱ���������ݼ�������������Ҫ�����á�������С��20��60������֮�������������˵�����Ҫ������ʹ��С��15���ص�������������60���ص���������������Ľ����
ʵ��ϸ��������ͨ����������ѵAPI����ViDi����ѧϰ���������ġ����е�ʵ�鶼����C#��������½��еġ�������ͨ�����ؽ�����֤����֮ǰʵ����ͬ��ѵ��/���Էָ���ִ�еģ�ʹ�ûҶ�ͼ����ɫͨ��������Ϊ1����100��epoch��ѧϰ��������ѵ�����ݼ�������ͼ�����ѵ������ˣ�training selection = 100%��ģ����������ģʽ�±������������ģ����У�ʹ�ò������ݼ�������simple regions=enabled��sampling density=1���Ᵽ֤�������ѧϰģ������ʹ�õĴ��������ǵȼ۵ġ����ڲ���sampling density������ʹ�ù�Ӧ���Ƽ���Ĭ��ֵ��Ҳ�������Խ������ƶ�Ϊ���۵ĸ��ܼ��IJ���ֵ��ʵ�飬���Ⲣû����߽����
����������ͼ10��ʾ���ڲ�ͬ��ѧϰ�����У�ʹ��dilate=5d�ı������ѵ����ģ�ͣ�ʹ����С�������ߴ�(20������)������תͼ���ʹ��ԭʼͼ��ߴ���������ܡ���ģ�͵�AP�ﵽ99.0%����5������࣬��FNΪ5,FPΪ0��ֵ��ע����ǣ�һ��ģ��ֻ�����4������࣬����������AP�ϵ͡�
��ע�ߴ����ڲ�ͬ�ı�ע�����У����ͱ�ע����������δ���ͱ�ע��Ȼ�����ڲ�ͬ��������֮�䣬����������С��dilate=5��dilate=17֮��ֻ��0.1 pp�IJ��졣
�����ߴ���ͨ���Ƚϲ�ͬ��������С�����۱�ע������Σ�����С������ģ��ʼ�����ھ��д�������ģ�͡���һ������ھ��и�ͼ��ֱ��ʺ�����С�ı���ȱ�ݵ����ݼ������⣬��ֱ���ͼ���ʵ�����������������£��������ı������Բ���С�����������һ�����ۣ�����������ߴ粻�ܲ�С��ϸ�ڣ�������Ҫ�ķ��ࡣ
ͼ���С����ת�����ʵ�黹��������ֱ���ͼ��������ת����������90%�����ݶ�����������ܡ�������������£����ܶ������½������ܶ��ߵ������½�����С��
ʹ���Ƚ��ķָ�����
�������������������������ķָ����磬��DeepLabv3+ (Chen etal. 2018)��U-Net (Ronnebergeretal.2015)��DeepLab�ܹ���ѡΪ�ڵ�ǰ����ָ���ϴﵽ���Ƚ������Ԥѵ��ģ�͵Ĵ�������U-Net�ܹ���ѡΪ��ȷ���طָ��ģ�͵Ĵ��������߿��Բο�Chenetal.(2018)��ù���DeepLabv3+�����ĸ���ϸ��Ϣ��Ҳ���Բο�(Ronneberger etal. 2015)��ù���U-Netģ�͵���ϸ��Ϣ������ģ���ڲ�ͬ�ı�ע�½���������������ʧ����ֻ�����˽����أ�����ֻʹ����û��������ת��ȫ�ֱ���ͼ���С����Ϊ��Щ������֮ǰ��ʵ���б�֤������õġ�
ʵ��ϸ����ͨ���滻����ķָ�֣������ַָ��Ƕ�뵽��������ķ����С�Ƕ�뵽��������е���������Ķ��ǻ���TensorFlowʵ�ֵġ���Щʵ����ʹ�õ�DeepLabv3+���ڰ���65���������Xception (Chollet 2017)�ܹ����ڵ�һ�߶���ѵ����������ʹ��16�����������ʵ����ʹ�õ�U-Net�Ǿ����Ľ���U-Net�ܹ�����24�������㣬Ψһ�����Ƕ�ÿ����������������������һ����ԭU-NetҲ��ȫ����ֱ�������ָ������ȫ�ֱ��ʵ����ؼ���ȷ�ָ���ϱ�ʵ�����Ҫ��������ӳ��ֱ��ʽ�����8������������������е�����ֱ�����ͬ��
�����������ָ����磬�ָ��;��߲��Ƿֿ�ѵ���ģ�������������ķ�����ʹ������������֤��֮ǰ����ʵ����ͬ��ѵ��/���Էָ�����ַ���Ҳ��logistic�ع�������������������ۣ������֤�������ܽϲʹ��ImageNet (Russakovsky et al. 2015)��COCO���ݼ�(Lin et al. 2014)Ԥѵ����ģ�ͳ�ʼ��DeepLabv3+����IJ�������U-Net����IJ����ǰ�����̬�ֲ������ʼ���ģ������ڱ�������ij�ʼ�����������綼ѵ����100��epoch��ѧϰ�������������ģ����ͬ������û�ж����������ʹ��0.1��ѧϰ�ʣ�����СΪ1��ÿһ������ȱ��ͼ��ͷ�ȱ��ͼ��֮�佻����С�
����������ͼ11��ʾ���ڱ������У�������õ�ģ�ͣ���DeepLabv3+ʹ��dilate=9��ע�ͽ���ѵ����AP�ﵽ98.0%���������F-measure�»��2��FP��4��FN���ܵ���˵�����Ŵ��ע�Ϳ��Եõ���õĽ�������ô��ں˷Ŵ��ע�͵õ��Ľ�����ƽ�����ԣ����۱�ע������ʲô��DeepLabv3+��ƽ������Ҳ��U-Net�ܹ��߳�2���ٷֵ㡣

���Ѿ�������㷨�Ƚ�
����������Ƚ��ķ����뱾���������������˱Ƚϡ�����ָ�;����������ϵķ��������˱Ƚϡ�Ϊ�˽��й�ƽ�ıȽϣ����ڱ�������з������Ǹ���ǰ�������������ѵ������ѡ��ġ��������еķ���������ʹ��ԭʼͼ���С(1408 512�ֱ���)��������ͼ����ת��ʹ����С�������ߴ�20���ص���ҵ������ʹ�ý�������ʧ���������������ķ��������ڱ�ע���ͣ���ͬ�ķ����ڲ�ͬ�ı�ǩ�ϱ�����á���ҵ�����ͱ�������ķָ�;������緽����dilate=5��ǩ��ѵ��ʱ������ã���DeepLabv3+��U-Net��dilate=9��ǩ��ѵ��ʱ������á�Ϊÿ��ѡ��ѡ��������������1��ʾ��
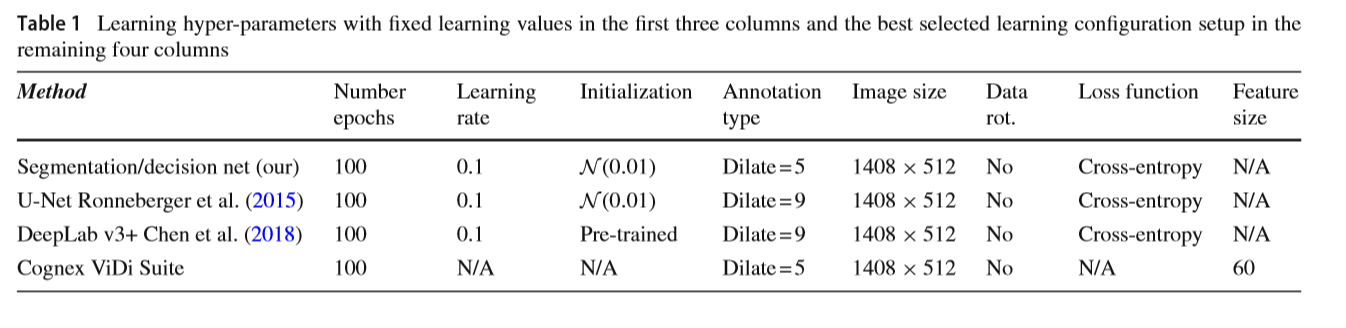
�������ͼ12��ʾ��������ߵ�������ʾ��������ķ���������ָ���϶������������Ƚ��ķ�������ҵ��Ʒ�����ܵڶ��ã������ֱ��ķָ���������ģ�DeepLabv3+�ܹ�������������U-Net���۲�����f -����µ���������������Է���������ķָ�;��������ܹ����������ٵ�ֻ��һ������࣬������ķ�����������5������������ࡣ
ͼ13��14���������з�����һЩ�����ͼ�������Ժͼ����Լ�⣬��ͼ13��ʾ���ڵ�һ���У������᷽��������һ��ȱʧ��⡣�������������һ��С��ȱ�ݣ������ѱ���������û�б��κ�ʣ��ķ�����������ʣ�µ����ӣ���������ķ����ܹ���ȷ��Ԥ��ȱ�ݵĴ��ڣ����������һ���п�����һ��Сȱ�ݡ�ͬʱ���÷���Ҳ�ܺܺõض�λȱ�ݡ�����ط�����Ҳ���Թ۲쵽���õĶ�λ��Ȼ������ȱ�ݴ��ڻ��ڵ�Ԥ��ܲע�⣬��ijЩ����£������ܴ�Ȼ����Ϊ����ȷ�ؽ����е�ȱ�ݴӷ�ȱ���з����������ֵҲ��Ҫ���õúܸߣ���͵����˶���ȱ��ͼ���������ͼ14�ܺõ�˵������һ�㣬������ʾ�˼��������⡣���˱�������ķ�������ҵ�����⣬������صķ��������Թ۲쵽�ߵļ����ԡ��ر��ǣ�U-Net���ص�������д�������������ʹ���ϸ��ӵľ������磬Ҳ������ȱ�ݺͼ�ȱ����ȫ���롣��һ���棬����ķ���û���κμ��������⣬�ܹ���ȷ��Ԥ����Щͼ����û��ȱ�ݡ�


������������ڹ�ҵ������ʹ�������ģ��ʱ��ȷ���������е�ȱ����Ŀ����Ҫ�ģ���ʹ����������ļ�����Ϊ���ۡ�����֮ǰ�Ķ�����û�в�����Щ�����µ����ܣ���˱��ڽ���һ��˵�������Ҫ��©����(����©����)������õ������������Ҫ���ٻ���Ϊ100%����Щ�����Խ����������Ҫ����������������֤����Ŀ����������ֱ��ָ���˴ﵽԤ��ȷ������Ĺ�������
�����ʾ��������400��ͼ���У������������ģ������ȱʧ����ֻ������3�������ԡ������������ͼ���0.75%����һ���棬��ط�����Ч���ϲ��ҵ��Ʒ��Ҫ�ֹ���֤7��ͼ�����ָ�����DeepLabv3+��U-Net�ֱ���Ҫ68����108���ֶ���֤��ע�⣬���������������ֶΰ���ʹ�ý���ľ������硣ʹ�����ع����������ľ�������ᵼ�������������½���
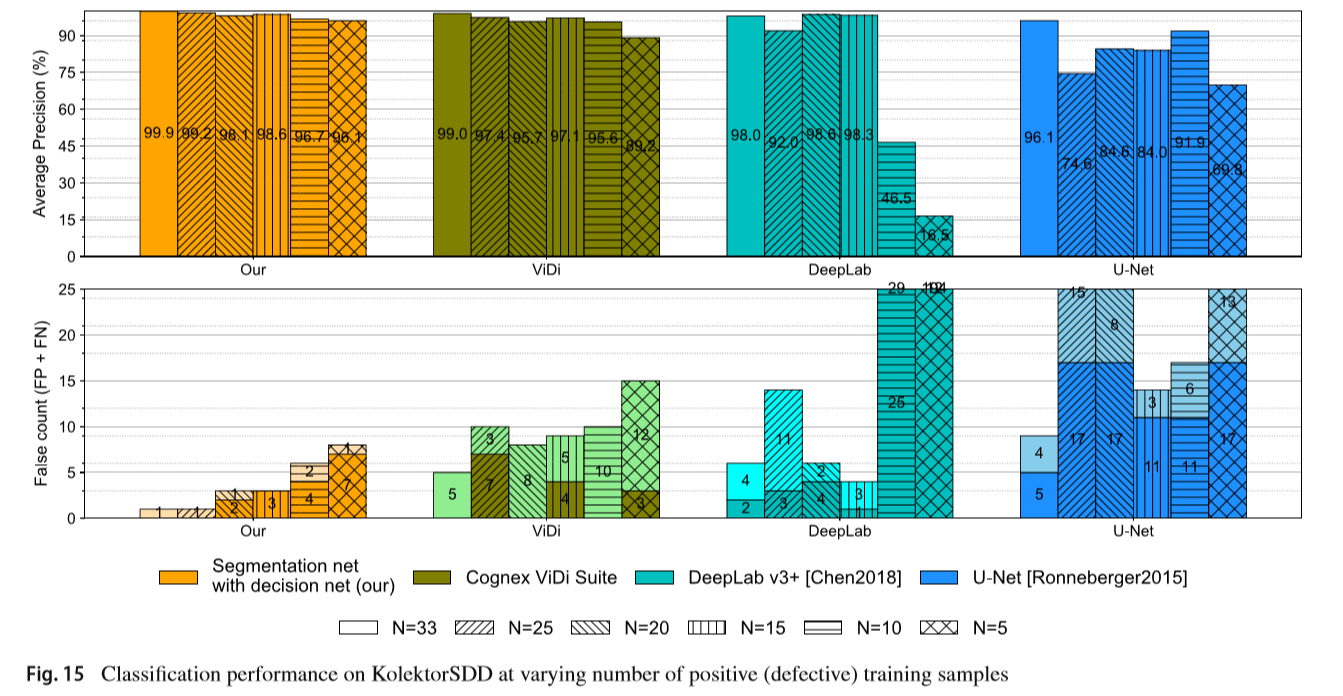
��ѵ������������������
�ڹ�ҵ�����£�һ���dz���Ҫ������Ҳ�������ȱ��ѵ���������������������Ҳ�����˽�С��ѵ��������ģ��Ч����������ʹ������������֤��ͬ����ѵ��/���Է���ʹ��������֮ǰ��ʵ�飬�����Ч��ʹ��33������(ȱ��)������ÿ���۵�ʱ�����е�ѵ��������Ȼ�������ѵ����������������Ч�صõ�ÿһ��ѵ����������СNΪ25��20��15��10��5������ÿһ��ѵ���IJ��Լ����ֲ��䡣ȡ����ѵ�����������ѡȡ�ģ������з���ȡ����������ͬ����֮ǰ������ʵ��һ����������ͬ����ѵ���Ͳ��Գ���������ķָ��������������������Cognex ViDi Suite���������Ƚ��ķָ���������˱Ƚϡ����еķ�������ʹ����ǰ�����и�����ʵ����ȷ�������ѵ�������������ġ�ʹ��dilated=5��ע��(����dilated=9���ڷָ�����)��ȫͼ��ֱ��ʣ���������ʧ����ͼ����ת�������ͼ15��ʾ���ڽ�ʹ��25����ȱ�ݵ�ѵ������������£��ָ�;������籣����99%���ϵ�AP��һ�������������ʹ�ø��ٵ�ѵ������ʱ��������½�������ʹ��5����ȱ�ݵ�ѵ������ʱ���÷������ܴﵽ96%���ҵ�AP��Ȼ������Cognex ViDi���п��Թ۲쵽�����Ե������½�������������£���N=25��APʱ������Ѿ��½���97.4%����ֻʹ��5����ȱ�ݵ�ѵ������ʱ����ҵ������APֵ�Ե���90%��ͼ15���°벿����ʾ���������Ҳ��ͬ�������ƣ���ɫ���������ԣ�dzɫ���������ԡ���һ���棬��ʹ�ý��ٵ�ѵ������ʱ��DeepLab v3+��U-Net�����ܱ�������ķ����U-Net������Ѹ���½�����DeepLab��ʹֻ��15����ȱ�ݵ�ѵ�������������൱�õĽ������Ҫע����ǣ���20����15����ȱ�ݵ�ѵ�������У�������������������ѵ�������еõ��Ľ����˵��DeepLab���ض���ѵ�������Ƚ����У�ȥ����Щ����������������ܡ�U-Net��ѵ�����������ļ������Ը����У������ƽ�������ϴ�75%���Ը���90%���ȡ�Ȼ��������10����5����ȱ�ݵ�ѵ��������DeepLab������AP�ֱ�Ϊ46%��16%��ʵ������������ѵ���������ٵ�����£��÷������ܱ��ֽϺõ��ȶ����ܡ�
��������
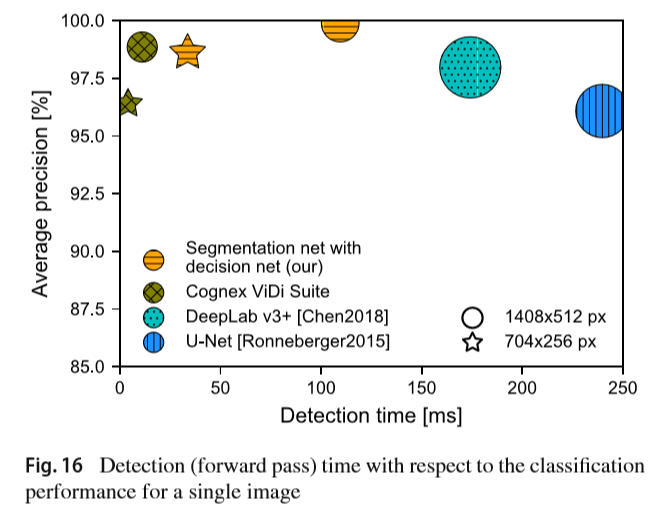
��������ķ����ڼ����������������еķָ����������ҵ�����ྺ����ͼ16�����������ƽ�����ȵ�����ͨ��ʱ�䡣
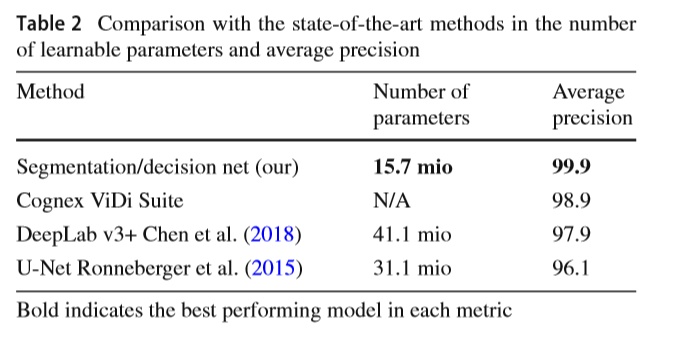
����ڵ���NVIDIA TITAN X (Pascal) GPU�ϻ�á�ʵ�����������÷�����DeepLab v3+��UNet�ٶȿ�ö࣬���нϸߵľ��ȡ�����ͨ�����ٵIJ���ʵ�ֵģ�����ͼ16�еı�Ǵ�С�еõ��˷�ӳ��Ҳ���2��ʾ�������������ģ�ͣ������ܽ�ʹ��15.7��mio�����Ϳ���ʵ�֣���U-Net��DeepLab v3+�IJ�������ǰ�ߵ������࣬�ֱ�Ϊ31.1 mio��41.1 mio������Cognex ViDi���IJ��������Dz��ɹ����ġ�������ķ�������ҵ����Ҳ��ʾ��һ��ķֱ�����ͼ16�е����DZ�ǡ���������÷�����ȫ�ֱ��ʵĿ�3������ֱ���Ϊ33ms��ȫ�ֱ���Ϊ110ms����������Cognex ViDi Suite��������죬ÿ��ͼ��Ĵ���ʱ��Ϊ10ms��Ȼ������ʹ��һ���ͼ��ֱ���ʱ����������������ģ��ֻ��Ҫ����һ��ļ�����۾Ϳ��Ի�����Ƶ����ܡ���ע�⣬�������ģ����TensorFlow�����ʵ�����������ܣ���û��Ӧ���κμ����Ż���������ȫ�ؼ�����ҵ�����Ѿ������˸߶��Ż����Ծ����ܼ��ټ���ɱ���
���ۺ��ܽ�
�Ӿ��幤ҵӦ�õĽǶȳ�����̽����һ�ֻ��ڷָ���������ѧϰ����ȱ�ݼ�ⷽ���������һ�����εķ�����
��һ������ȱ�ݵ����ؼ���ǩ��ѵ��һ���ָ����磬�ڶ������ڷָ�����Ļ����Ͻ���һ���ж�����ͼ���Ƿ�����쳣�ľ������硣������ķ��������˹㷺�����ۣ����Ʒ��ҵ��Ʒ��������һ������������������ȱ�ݱ���Ϊ���ϵĶ��ѡ�����������Ѿ���Ϊ�����ݼ������ṩ����ΪKolektor����ȱ�����ݼ�(KolektorSDD)���÷����ڸ������뼸���Ƚ��ķ��������˱Ƚϣ�����ר�����������ֻ������ѧϰ�ı��ָ����
��KolektorSDD�ϵ�ʵ���������ֻ��һ����������ط�����ȣ��������ģ��ȡ���������ĺý��������ط���ȡ��������������������������Թ���������Ĵ��зָ�;��������������ƣ��Լ��Ľ��Ľ���Ұ��С������˲�ȱ��ϸ�ڵ���������صķ���ȱ����Щ���������磬�������ķָ��U-Net����Ұ��С���ޣ�����Ұ��Сֻ��45���أ������ķ����Ľ���Ұ��СΪ205���ء���ȻDeepLabv3+����˽���Ұ�Ĵ�С�������Ĵ�����̫��IJ�������ᵼ��ģ������ϣ����������ڵ��������ݼ���Ԥ��ѵ���ġ�
��һ���棬������������ҵ������������Ϊ�÷�����ϸ����δ������Ȼ����ʵ���������ʹ�õͷֱ���ͼ��ʱ����ҵ�������������Աȱ�������ķ�������ʵ���������ҵ�������Ѳ���ȱ�ݵ�ϸ�ڣ�������Ҫ���ߵķֱ�����������õ����ܡ�
Ȼ������ʹ��ʹ�ø߷ֱ���ͼ�������£���������뱾�ķ�����ͬ�����ܡ�
�÷�����ͨ����33��ȱ��������ѧϰ�ͻ�������õ����ܡ�ͼ17��������ȷ����ļ������ӡ����ң���ʹ��25��ȱ����Ʒ����Ȼ���Ի�����õ����ܣ�������������£���صķ���ȡ���˽ϲ�Ľ���������������������ѧϰ���������ھ�������ȱ�������Ĺ�ҵӦ�á����⣬Ϊ�˽�һ�����ǹ�ҵ������Ӧ�ã�����������������Ҫ����:(a)ʵ��100%����ʵ����ܣ�(b)ע�͵�ϸ�ں�(c)����ɱ�����100%����ʵ��������������������ģ����400��ͼ����ֻ��Ҫ3��ͼ������ֹ���⣬�����Ϊ0.75%������ֵ�ע��Ҳ����ʵ����ϸע�����Ƶ����ܡ���ijЩ����£������ע��������ʹ�ø��õ����ܡ���������ƺ��Ƿ�ֱ���ģ�Ȼ����һ�ֿ��ܵĽ��Ϳ��Դ����ڷ���ÿ�����صĸ���Ұ��С���ҵ�������һ����Զ��ȱ����������أ�cepcepfield��Ȼ�Ḳ��ȱ�������һ���֣���ˣ������ȷע�ͣ��������ҵ��Լ����Ҫ����������һ���ۿ��Ե����ڽ�������Ӧ������ʱ�����ֹ��������������½����Ͷ����ɱ�����������ߵ�����ԡ�
Ȼ����������ķ����������ض����͵������ر�أ��üܹ���Ϊ������Ƶģ���Щ������Ա���Ϊ���ؼ�ע�͵ķָ����⡣�������������������⣬�����ڷֶεĽ��������̫�ʺϡ����磬���ӵ�3D������������ƿ�����Ҫ��������ȱʧ�IJ�������Щ�������ͨ����ⷽ�����������Mask RCNN (kaim et al. 2017)��
���о�֤�������᷽�����ض�����(���Ƽ��)���ض����������ϵ����ܣ�������ܹ����ǽ���Ը��ض�������ơ�����Ҫ�κ��ľͿ���ѧϰ�µ�������ϵ�ṹ����Ӧ����ͼ�����������ӵı���,Ҳ����Ӧ���ڼ��������ͬ��ȱ��ģʽ,�绮��,�ۼ�������Υ����Ϊ,�ṩ�㹻����������ѵ�������ǿ��õ�,�ض���ȱ�ݼ���������,������Ϊ����ָ����⡣Ȼ����Ϊ�˽�һ��������һ�㣬��Ҫ�µ����ݼ�����������֪��DAGM���ݼ�(Weimer et al. 2016)��Ψһһ�ֹ������õĴ�ע�͵����ݼ������ж��ֱ����ȱ�����ͣ��ʺ���������ѧϰ�ķ������÷����ڸ����ݼ���ȡ���˺ܺõĽ�����������ݼ����ۺ����ɵģ�Ҳ�Ǹ������õ��Ľ�����͵ġ���ˣ�δ����Ŭ��Ӧ�ü����ڻ�����ʵ������Ӿ���������ȡ�µĸ������ݼ��ϣ����ѧϰ(������)�������Ա���ʵ��ȫ������;������չʾ�����ݼ����������ĵ�һ����
��л
������õ��������о���Ŀ�ͼƻ��IJ���֧��:��˹�������ǹ�����ŷ������չ����ͬ������GOSTOP��ĿC3330-16-529000, ARRS�о���ĿJ2-9433 (DIVID)��ARRS�о���ĿP2-0214�����ǻ�Ҫ��лKolektor Orodjarna d. o. o.��˾Ϊ���ǵ����ݼ��ṩ��ͼƬ�����ṩ�˸�������ע�͡�
�����
���������ò��ֵġ���ݡ����ṩ�˳����ӣ�ֱ�ӵ�����ɣ����ֿ�ֱ�����ء�