AutoLoc: Weakly-supervised Temporal Action Localization in Untrimmed Videos
- 作者贡献
- Outer-Inner-Contrastive Loss
- Forward
- Backward
- AutoLoc
- 输入数据准备和特征提取
- Classi?cation Branch
- Localization Branch
- 实验
- 数据集和评估
- 实现细节
- 与最先进的技术比较
- 讨论
作者贡献
- 开发了一个新的弱监督TAL(Temporal Action Localization )框架,称为 AutoLoc 以直接预测每个行为实例的时间边界。
- 提出了一个新的损失( Outer-Inner-Contrastive (OIC) loss)以自动发现训练此类边界预测器所需的片段级监控。
解决:他人做的实验对视频的时间边界定位不够准确
Outer-Inner-Contrastive Loss
Forward
如图所示,对于每个预测片段φ,计算它的OIC损失。每个预测片段包含行为/内边界[
], in?ated 外边界[
],行为类别k。这些边界都是在snippet-level的间隔尺寸(比如,边界x=1对应于第一个片段的位置)

: 表示在行为k的CAS上第x个片段的类激活。
: 在外部区域的平均激活
: 在内部区域的平均激活
则关于片段φ的OIC损失为:
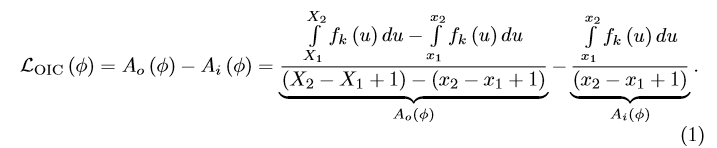
根据图片右下角说明OIC损失通过外部红色区域的平均激活度减去内部绿色区域的平均激活度得到。通过最小化
来奖励内部高激活度和惩罚外部高激活度。
Backward
OIC对内部和外部边界是可微的,通过OIC损失发现的监督可以反向传播到底层边界预测模型。
对于内部边界[
]的梯度如下:
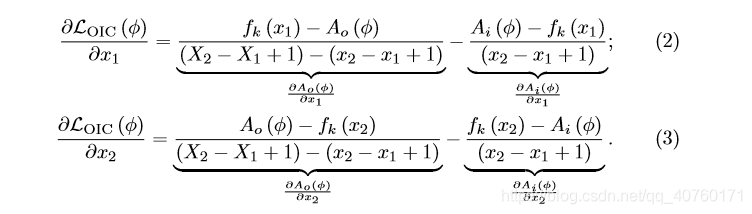
对于外部边界[
]的梯度如下:
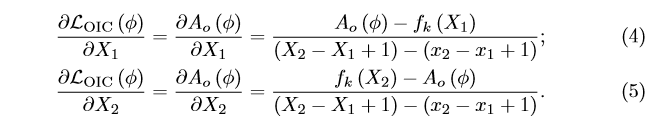
AutoLoc
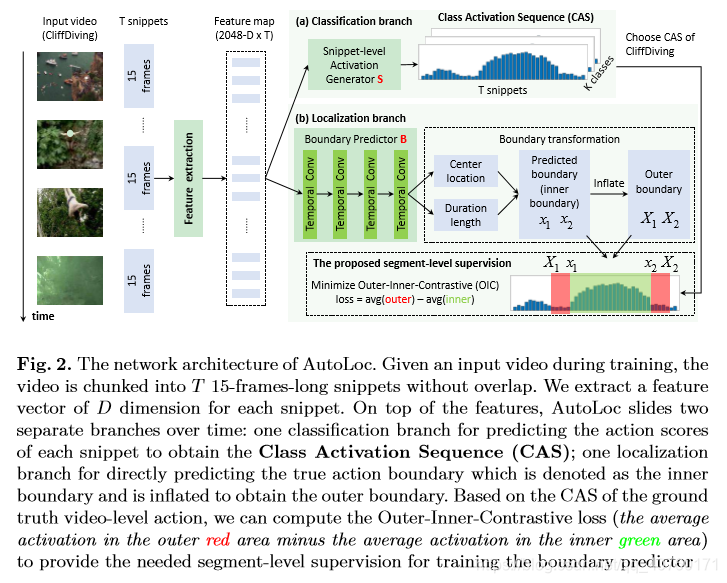
输入数据准备和特征提取
输入数据:每次输入是一个单一的未修剪的视频。对于每个视频,首先将其划分为15帧长且没有重叠的片段,并为每个片段单独提取特性。
特征提取:首先训练一个UntrimmedNet(the soft version),然后使用训练好的网络作为主干进行特征提取。该骨干网由一个接受RGB输入的空间流和一个接受光流输入的时间流组成。对于每个流,使用BN Inception,并在全局池层提取1024维特性。最后,对于每个片段,将提取的空间特征和时间特征连接成一个2048维的特征向量。对于每个有T个片段的输入视频,特征图shape为2048(通道)×T(片段)。
Classi?cation Branch
目标:获得类激活序列(CAS)。
方法:建立了一个基于UntrimmedNet的激活生成器。对于每个视频,使用UntrimmedNet中事先训练好的两个FC层分别提取出大小为K(行为)×T(片段)的分类分数序列和T维的attention score序列。对于每个片段,在其attention score低于阈值时,将所有类的分类分数设置为0(在THUMOS 14训练集上通过网格搜索选择7,在ActivityNet上也可以很好地工作);将这种门控分类分数作为激活,其范围在[0,1]。最后,对于每个视频,大小为K(行为)×T(片段)的CAS。
注:使用了UNtrimmedNet的soft selection
Localization Branch
目标:学习直接预测片段边界的参数化模型。
缘由: 最近的全监督TAL方法已经证明了regressing anchors直接预测边界的有效性:anchor是可能片段的假设;分别回归得到预测的边界(1)anchor片段的中心位置和(2)anchor片段的时间长度; multi-anchor mechanism用于覆盖不同时间尺度的可能片段。
方法:设计了一个定位网络B来查看特征图上的每个时间位置,并为每个anchor输出需要的两个边界回归值。使用这些回归值对anchor进行回归,以获得预测的行为边界(内部边界),并通过膨胀内部边界来获得外部边界。最后,在CAS的基础上,引入了一个具有OIC损失的OIC层来生成最终的片段预测。
定位网络B的网络结构:
- 输入为特征图2048(通道)×T(片段)。
- B首先堆叠3个相同的时间卷积层,这些层会随着时间推移滑动卷积滤波器。每个时间卷积层有128个过滤器,每个过滤器的内核大小为3,步长为1,填充为1。
- 每个时间卷积层后面都有一个BN层和一个ReLU层。
- B再增加一个时间卷积层pred输出边界回归值。pred中的过滤器的内核大小为3,步长为1,填充为1。
- 与YOLO类似,B预测的边界被设计成与类无关。这允许我们学习一个通用的边界预测器,它可以在将来为不可见的行为生成 action proposals 。因此,pred中过滤器的总数为2M,其中M为anchor scales的数量。
- 对于每个anchor,B预测两个边界回归值:(1)
表示如何移动anchor的中心位置;(2)
表示如何缩放anchor的长度。
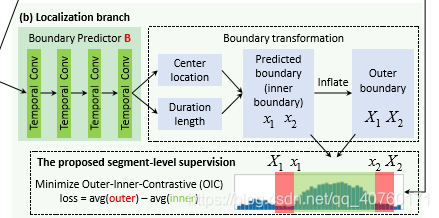
边界变换的细节:由于特征上的每个时间位置和CAS上的每个时间位置都对应于输入片段的相同位置,所以在片段级粒度上进行边界预测。边界预测过程如图3所示。
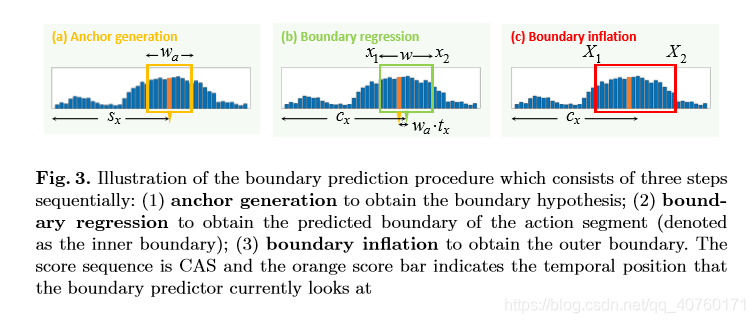
- Anchor generation。在特征图上的时间位置 处,生成一个长度 的假设片段(anchor)。在实践中,使用了multi-scale anchors。根据训练集中真实标签片段的持续时间范围确定它们的尺度。
- Boundary regression。如前所述,对于每个位于时间位置 的anchor,B预测了两个边界回归值 和 。通过回归中心位置 和时间长度 可以得到预测的线段。将预测段的边界表示为内边界,其计算方法为 。此外,将预测的边界 和 裁剪到整个视频的范围内。
- Boundary in?ation。与 之前和 之后的上下文区域相比,真实标签片段在[ ]内侧区域的CAS上通常表现出相对较高的激活度。因此,膨胀内部边界比α获得相应的外边界 。实验探索表明,设置α=0.25是一个不错的选择。
获取最终预测的OIC层:最后,引入一个OIC层,使用OIC损失来测量每个段包含行为的可能性,然后删除不可能包含行为的片段。在测试期间,这个OIC层输出一组预测片段。在训练过程中,该OIC层进一步计算总OIC损失,并将梯度反向传播到底层边界预测模型。
具体地说,给定一个输入视频,Classi?cation Branch生成它的CAS,而Localization Branch预测候选的与类无关的片段。(注意,由于B中所有的时间卷积层都是用stride = 1随时间滑动的,所以feature map上每个时间位置预测的片段集和CAS上每个时间位置的激活是成对的,对应的是同一个输入片段。)
因此:
- 在每个片段的时间位置上,B预测了M个与类无关的anchor。
- 对于每个行为,在CAS上迭代执行以下步骤,以获得最终的类特定的段预测。(在训练中,只考虑真实标签行为,而在测试中,考虑所有行为。)
- 如果一个时间位置在CAS上的激活值低于0.1,将放弃所有与这个时间位置相对应的预测。
- 对于每一个剩余的位置,在其M个anchor分段预测中,只保留OIC损失最小的位置,这意味着选择最有可能的尺度的anchor。
- 对于所有保留的片段预测,删除OIC损失大于-0.3的片段预测。使用重叠IoU阈值为0.4对所有段预测执行非最大抑制(NMS)。所有这些阈值都是由THUMOS的14训练集上的网格搜索选择的,在ActivityNet上也可以很好地工作。
在训练过程中,总损失是每个保持的片段预测所产生的OIC损失的总和。可以计算每个保留段预测所触发的梯度,然后将它们累加起来更新底层的边界预测器b。每一部分的预测包括(1)预测操作类,(2)置信度得分也设置为1 - OIC损失,和(3)通过从片段级粒度(连续值之前四舍五入到最近的整数)到时间转换内部边界[ ]得到开始时间和结束时间。
实验
数据集和评估
数据集:
- THUMOS’14: THUMOS’14中的时间行为定位任务包含20个动作。它的验证集有200个未修剪的视频。每个视频至少包含一个动作。使用这200个视频作为训练的验证集。训练后的模型在包含213个视频的测试集上进行测试
- ActivityNet v1.2:为了便于比较,跟随Wang等人使用了ActivityNet 1.2版本,该版本涵盖了100个活动类。训练集有4819个视频,验证集有2383个视频。在训练集上进行训练,在验证集上进行测试。
评价标准:根据测试视频,系统输出行为片段预测的等级列表。每个预测包含行为类、开始时间和结束时间,以及置信度得分。遵循惯例来评估平均精度(mAP)。只有当(1)被预测类是正确的,且(2)其与真实标签段的时间重叠IoU超过评估阈值时,才认为每个预测是正确的。不允许对同一真实标签段进行重复检测。
实现细节
- 使用Caffe实现AutoLoc。
- 使用随机梯度下降算法来训练自动定位。
- 通过实验研究,在训练一个epoch后,训练过程可以在THUMOS’14和ActivityNet数据集上快速收敛。
- 与Faster R-CNN相同,在每个小批,处理一个完整的未修剪的视频。学习速率最初设置为0.001,并且每200次迭代减少一个数量级。设置重量衰减为0.0005。我们为THUMOS 14选择了anchor的片段长度为1、2、4、8、16、32,为ActivityNet选择anchor的片段长度为16、32、64、128、256、512。
- 使用CUDA 8.0和cuDNN v5。使用一个单一的NVIDIA GeForce GTX TITAN X GPU。
与最先进的技术比较
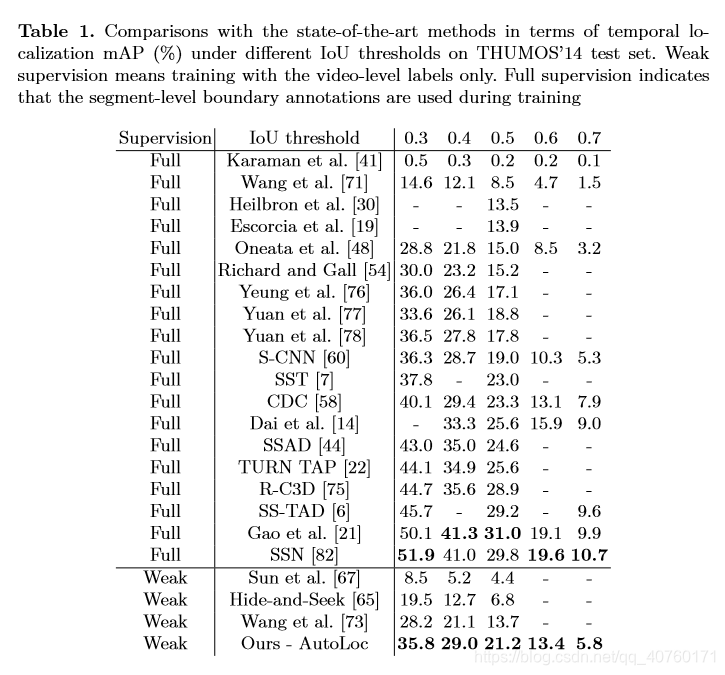
THUMOS’ 14的结果如表1所示。
ActivityNet v1.2的结果如表2所示。

讨论

问题1:提议的OIC损失有多有效?
为了评估提议的OIC丢失的有效性,我们在片段级粒度上枚举了所有的候选片段(例如,一个片段从第2个片段的位置开始,在第6个片段的位置结束)。我们利用OIC损失来衡量每个部分包含行为的可能性,然后选择最可能的行为。具体地说,对于每一段,我们计算它作为每一个行为的OIC损失。然后,删除具有高OIC损失的片段,并通过NMS删除重复的预测。我们称这种方法为OIC选择。如表3所示,虽然OIC的效果不如AutoLoc,但OIC的选择仍然显著提高了目前的研究结果。因为OIC损失明显地倾向于内部高激活度和外部低激活度的部分,而且这种低OIC损耗的部分通常与真实标签部分很好地对齐。这证实了OIC损失的有效性。
问题2:内部区域和外部区域的对比有多重要?
OIC损失的核心思想是鼓励内部区域的高激活度,同时惩罚外部区域的高激活度。我们考虑另一个变量,它也可以发现分段级监督,但不模拟内部和外部之间的对比。具体来说,我们将AutoLoc中的OIC丢失改为仅在内部丢失,这只鼓励了片段内部的高激活度,而不考虑上下文区域。如表3所示,性能下降了很多。
因此,在设计训练边界预测器的损失时,考虑内部区域和外部区域的对比是非常重要和有效的。值得注意的是,观察内部和外部之间的对比的想法与使用高斯(LoG)过滤器的拉普拉斯(Laplacian)来检测blob有关。计算OIC损失的操作是将CAS与图4所示的step函数进行有效的卷积,可以将其视为LoG filter的一种变体,以方便网络训练。从数学上我们可以证明对数滤波器的积分和阶跃函数的积分在(- Inf,+Inf)范围内均为零。在此基础上,利用multi-anchor mechanism 和边界回归方法对blob detection 中的尺度选择进行了探讨。尽管OIC的损失很简单,但它在实践中对于确定可能的行动部分是相当有效的。
问题3:与直接优化测试视频的边界相比,在训练视频上学习模型有什么好处?
因为直接优化是根据测试视频的CAS来优化预测边界的,可能不是很准确。最终,直接优化会覆盖这种不准确的CAS,从而导致不完全的边界预测。在AutoLoc中,B已经接受了多个训练视频的训练,因此对CAS中的噪声具有较强的鲁棒性。因此,即使测试视频的CAS不完美,AutoLoc仍然可以预测出良好的边界。此外,直接优化要求对测试视频的边界预测进行优化直到收敛,因此其测试速度比AutoLoc慢得多。例如,在ActivityNet上,直接优化在25次训练迭代(25次向前传递和25次向后传递)之后收敛。而AutoLoc直接使用训练好的模型对测试视频进行推理,因此在测试过程中只需要一个前向遍历。