《SRN: Stacked Regression Network for Real-time 3D Hand Pose Estimation》略读与实践
这篇与《AWR: Adaptive Weighting Regression for 3D Hand Pose Estimation》相似,本质都还是3Dheatmap用来做深度图手部关键点坐标估计,最大不同在于这篇论文是迭代stage的方法不断finetune回归关键点坐标的。
作者认为去掉解码网络结构,模型会更小更快,效果不一定会变差,因为之前典型的具有stage的模型结构特征提取部分都是hourglass结构的,涉及编码和解码两个过程。同时作者还认为dense pixel-wise(heatmap)方案的解码部分并不是很有效,太关注局部特征,如果标签坐标附近有深度值缺失,效果更不可靠。因此需要一种可微分的参数可重置或复用的模块来直接提取空间特征。
官方开源代码:https://github.com/RenFeiTemp/SRN
废话不多说,上整体结构示意图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-grPkbhmF-1594736656991)(1.png)]](https://img-blog.csdnimg.cn/20200714222425509.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FsZ29Nb25zdGVy,size_16,color_FFFFFF,t_70#pic_center)
上图清晰可以看出为了干掉解码结构,每个stage都复用最开始的特征提取模块和深度图数据,结构的核心和难点就是理解上图中的橘黄色模块"Regression module"。
作者也是使用了3D offset vector heatmap和概率heatmap,采用smooth L1 loss。
下面看下官方模型测试效果(妖哥亲测):
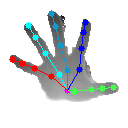
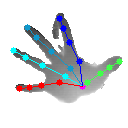
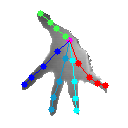

上面四个结果均为最后一个stage的结果,原文中代码有三个stage,最后一个是效果最好的,看上去感觉还可以。
废话不多说,show your code!(核心代码)
def joint2offset(self,joint,img,feature_size=32): #如何将关节点坐标转为3Dheatmapdevice = joint.devicebatch_size,_,img_height,img_width = img.size() # B X 128 X 128#print(' batch_size,_,img_height,img_width ', batch_size, ' ', img_height,' ', img_width)img = F.interpolate(img, size=[feature_size, feature_size]) # 32 X 32#print('img ', img.size())_,joint_num,_ = joint.view(batch_size,-1,3).size() # joint shape 1 X 21 X 3joint_feature = joint.view(joint.size(0),-1,1,1).repeat(1, 1, feature_size, feature_size) # 63 X 32 X 32#print('joint_feature ', joint_feature.size(), ' ',joint_feature)mesh_x = 2.0 * torch.arange(feature_size).unsqueeze(1).expand(feature_size, feature_size).float() / (feature_size - 1.0) - 1.0 # 32 32 [-1, 1]mesh_y = 2.0 * torch.arange(feature_size).unsqueeze(0).expand(feature_size, feature_size).float() / (feature_size - 1.0) - 1.0#print('mesh_y ', mesh_y.size())coords = torch.stack((mesh_y, mesh_x), dim=0) # 2 X 32 X 32coords = torch.unsqueeze(coords, dim=0).repeat(batch_size, 1, 1, 1).to(device)coords = torch.cat((coords, img),dim=1).repeat(1, joint_num, 1, 1) # B X 63 X 32 X 32 (2 + 1) * 21 = 63#print('coords ', coords.size())offset = joint_feature - coords #offset = offset.view(batch_size, joint_num, 3, feature_size, feature_size) # B 21 3 32 32dist = torch.sqrt(torch.sum(torch.pow(offset, 2), dim=2)+1e-8)offset_norm = (offset / (dist.unsqueeze(2)))heatmap = self.offset_theta - dist# heatmap = - dist# 利用深度图提取mask作为嵌入约束mask = heatmap.ge(0).float() * img.lt(1).float().view(batch_size, 1, feature_size, feature_size) # ge >= lt <offset_norm_mask = (offset_norm * mask.unsqueeze(2)).view(batch_size, -1, feature_size, feature_size)heatmap_mask = heatmap * mask.float()return torch.cat((offset_norm_mask, heatmap_mask),dim=1)# x y z + mask = 21 * 4= 84def offset2joint(self, offset, depth): #将3dheatmap转为关键点坐标device = offset.devicebatch_size,joint_num,feature_size,feature_size = offset.size()joint_num = joint_num / 4if depth.size(-1)!=feature_size:depth = F.interpolate(depth, size=[feature_size, feature_size])offset_unit = offset[:,:joint_num*3,:,:].contiguous().view(batch_size,joint_num,3,-1)heatmap = offset[:,joint_num*3:,:,:].contiguous().view(batch_size,joint_num,-1)mesh_x = 2.0 * torch.arange(feature_size).unsqueeze(1).expand(feature_size, feature_size).float() / (feature_size - 1.0) - 1.0mesh_y = 2.0 * torch.arange(feature_size).unsqueeze(0).expand(feature_size, feature_size).float() / (feature_size - 1.0) - 1.0coords = torch.stack((mesh_y,mesh_x), dim=0)coords = torch.unsqueeze(coords, dim=0).repeat(batch_size, 1, 1, 1).to(device)coords = torch.cat((coords,depth),dim=1).repeat(1, joint_num, 1, 1).view(batch_size,joint_num,3,-1)value,index = torch.topk(heatmap,30,dim=-1)index = index.unsqueeze(2).repeat(1,1,3,1)value = value.unsqueeze(2).repeat(1,1,3,1)offset_unit_select = torch.gather(offset_unit,-1,index)coords_select = torch.gather(coords,-1,index)dist = self.offset_theta-valuejoint = torch.sum((offset_unit_select*dist + coords_select)*value,dim=-1)joint = joint / torch.sum(value,-1) # meansift 而不是利用argsoftmaxreturn joint
再看一下网络前传多个stage的代码:
def forward(self, img, GFM_, loader, M=None, cube=None, center=None, decode_net=None):device = img.devicefeature = self.pre(img) # 128->32#print('feature ', feature.size()) # B 64 32 32remap_feature = torch.Tensor().to(device)#print('feature ', feature.size())pos_list = []remap_feature_list = []for (i, type)in enumerate(self.stage_type): # iter 3c5 = self.features[i](torch.cat((feature, remap_feature),dim=1)) # 512 X 4 X 4#print('c5 ', c5.size())if type == 0:y = self.avg_pool(c5) # 512 X 1 X 1y = self.fcs[i](y.view(y.size(0), -1)) y = y.view(y.size(0), -1, 3) # 21 X 3#print('y ', y.size())elif type == 1:y = self.avg_pool(c5)y = self.fcs[i](y.view(y.size(0), -1))y = self.handmodelLayer.calculate_position(y).view(y.size(0), -1, 3)#论文只是使用了这一方案elif type == 2:y = GFM_.offset2joint(c5, img)y = y.view(y.size(0), -1, 3)pos_list.append(y)feature_temp = self.repara_module(img, y, c5, GFM_, loader, M, cube, center, decode_net=decode_net) # 84 X 32 X 32#print('feature_temp ', feature_temp.size())if self.dim_accumulate:remap_feature = torch.cat((remap_feature, feature_temp), dim=1)#print('remap_feature ', remap_feature.size())else:remap_feature = feature_tempremap_feature_list.append(remap_feature)return pos_list, remap_feature_listdef repara_module(self, img, pos, c5, GFM_,loader, M, cube, center, decode_net=None):#print('feature_type ', self.feature_type)if self.feature_type == 'heatmap':heatmap = GFM_.joint2heatmap2d(pos, isFlip=False)depth = heatmap * pos[:, :, 2].view(pos.size(0), -1, 1, 1)feature = torch.cat((heatmap,depth),dim=1)elif self.feature_type == 'heatmap_nodepth':heatmap = GFM_.joint2heatmap2d(pos, isFlip=False)feature = heatmapelif self.feature_type == '3Dheatmap':pos_xyz = loader.uvd_nl2xyznl_tensor(pos, M, cube, center)feature = GFM_.joint2offset(pos_xyz, img, feature_size=self.feature_size)[:,self.joint_num*3:,:,:]# 论文只使用了这一方案elif self.feature_type == 'offset':feature = GFM_.joint2offset(pos, img, feature_size=self.feature_size)#print('self.feature_size ', self.feature_size)elif self.feature_type == 'joint_decode':feature = decode_net(pos)elif self.feature_type == 'offset_decode':offset = GFM_.joint2offset(pos, img, feature_size=self.feature_size)feature = decode_net(offset)elif self.feature_type == 'feature_upsample':feature = self.feature_net(c5)return feature
以上就是本偏博客简单介绍的SRN深度图手部关键点坐标估计的内容,感兴趣的童鞋可以仔细阅读论文和实验,欢迎大家来找我交流,拍砖。
