《AWR: Adaptive Weighting Regression for 3D Hand Pose Estimation》略读与实践
这是一篇深度图手部关键点坐标估计的文章(以下简称AWR),目的是利用带有关键点深度坐标的所谓3D heatmap来直接回归出21个手部关键点的三维坐标,相当于所谓结合detection-based和 regression-based 两种方法。至于说什么adaptability,其实就是所谓可微的heatmap,类似文章之后介绍SRN就知道了。
官方代码:
https://github.com/Elody-07/AWR-Adaptive-Weighting-Regression
先上一张给出的会意图,方便理解:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2dYBQMdn-1594736515246)(awr1.png)]](https://img-blog.csdnimg.cn/20200714222211772.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FsZ29Nb25zdGVy,size_16,color_FFFFFF,t_70)
AWR文章作者认为直接采用神经网络回归手部关键点坐标的方案可以捕获全局特征,尤其在极端角度,比如自遮挡这种情况,效果有所保证,但是考虑到最后是将特征图转为全连接层的形式,会破坏掉之前的空间结构信息,使其坐标想达到特别精确变得困难。采用基于检测的方案(heatmap或者偏移向量场方案)然后通过求最大值位置或者mean-shift找出每个通道特征图所代表的关键点坐标值,即全卷积网络没有全连接层,认为这样可以保留空间结构信息,还能更好地利用局部特征,但是这种方案问题在于后处理(求最大值)与模型不是end-to-end的,在模型训练的时候只是直接求特征图输入与固定计算的权重分布的loss。作者认为这样学习固定的权重分布会使得模型性能减弱且当关键点附近有深度值缺失时,表现不稳定。所以提出AWR具有end-to-end训练的特点,连续可微,使得权重分布或者说是局部感受野区域自适应。
再来看整体网络结构与流程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i8r2JXs8-1594736515248)(awr2.png)]](https://img-blog.csdnimg.cn/20200714222223140.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FsZ29Nb25zdGVy,size_16,color_FFFFFF,t_70#pic_center)
作者在想设计这个heatmap的格式,所以考虑距离手部关键点坐标距离近的点应该比距离远的拥有更高的权重,而且,如果手部关键点附近有些深度值缺失,甚至严重缺失,权重分布的范围应该更扩大一些才好(这就是所谓的自适应),所以就有以下公式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VV2gsnsS-1594736515250)(awr3.png)]](https://img-blog.csdnimg.cn/2020071422223321.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FsZ29Nb25zdGVy,size_16,color_FFFFFF,t_70#pic_center)
上图就是本文的核心概括,这样一来输入数据是深度图,手部关键点坐标标签还是xyz或uvd,heatmap只存在于中间数据格式的转换。至于说先预训练所谓dense representation supervision then finetune the network with joint supervision.效果比直接训练好,使用smooth L1 loss等等,这都不重要了。
有个需要注意也是大家得出一般结论的细节:学习偏移量比直接回归标签值效果好。
其实还有个细节就是网络结构图里也能看出来,就是使用了深度图提取了mask,相当于嵌入先验约束。
至于效果什么的,我贴几张自己感兴趣的官方模型的实测结果:
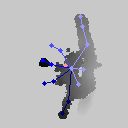
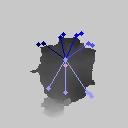
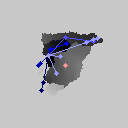
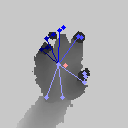
接下来给上一段核心代码(也就是之所以能发论文的代码):
def offset2joint_softmax(self, offset, img, kernel_size): # offset: channel 84 = 21 * (uvd + ht)batch_size, feature_num, feature_size, _ = offset.size()jt_num = int(feature_num / 4) # 21 img = F.interpolate(img, size = [feature_size, feature_size]) # (B, 1, F, F)# unit directional vectoroffset_vec = offset[:, :jt_num*3].contiguous() # (B, jt_num*3, F, F) (x, y, z) vector 目的是为了学习坐标值# closeness heatmapoffset_ht = offset[:, jt_num*3:].contiguous() # (B, jt_num, F, F) heatmap 目的是为了计算权重(概率)mesh_x = 2.0 * (torch.arange(feature_size).unsqueeze(0).expand(feature_size, feature_size).float() + 0.5) / (feature_size - 1.0) - 1.0mesh_y = 2.0 * (torch.arange(feature_size).unsqueeze(1).expand(feature_size, feature_size).float() + 0.5) / (feature_size - 1.0) - 1.0coords = torch.stack((mesh_x, mesh_y), dim=0)coords = coords.unsqueeze(0).repeat(batch_size, 1, 1, 1).to(offset.device)#加入xy平面坐标网格,同时加上深度图. 凑齐xyz,得到立体3D的“heatmap”coords = torch.cat((coords, img), dim=1).repeat(1, jt_num, 1, 1) # (B, jt_num*3, F, F) coords = coords.view(batch_size, jt_num, 3, -1) # (B, jt_num, 3, F*F)mask = img.lt(0.99).float() # (B, 1, F, F) # mask操作 嵌入约束offset_vec_mask = (offset_vec * mask).view(batch_size, jt_num, 3, -1) # (B, jt_num, 3, F*F)offset_ht_mask = (offset_ht * mask).view(batch_size, jt_num, -1) # (B, jt_num, F*F)offset_ht_norm = F.softmax(offset_ht_mask * 30, dim = -1) # (B, jt_num, F*F) 30是为了更好区分,无实际意义 这是核心的核心dis = kernel_size - offset_ht_mask * kernel_size # (B, jt_num, F*F) 距离偏差越大,权重越小 符合该逻辑关系均可(在单位区间内完备)#向量偏移乘以概率权重加上参考坐标得到真实坐标计算值再乘以mask修正后的概率权重,求其特征图之和得到对应坐标值(uvd)jt_uvd = torch.sum((offset_vec_mask * dis.unsqueeze(2) + coords) * offset_ht_norm.unsqueeze(2), dim=-1)return jt_uvd.float()
由于作者开源项目并没有提供训练代码,仅参考其现已开源部分(截止2020/07/14)可能与论文存在差异,可能水平有限,欢迎讨论(battle)。
