网上很多对双向链表解释的文章都是用这个结构:
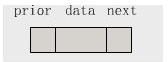
它们的连接情况是这样的:

相当的不直观,今天我要从详细的地址出发来解释双向链表的原理。
现定义一个结构体如下:
struct student
{
char name;
struct student *next;
struct student *prior;
};
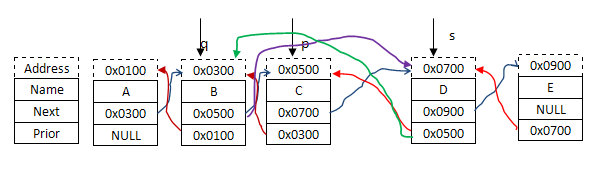
现在有5个人A,B,C,D,E.这五个人构成的链表如下:

虚线部分为地址值,这个是为了描述方便随便写的值,在创建上述的链表时其实不用关心地址值到底是多少,这些地址都会放到某个变量当中,只要对变量进行赋值传递就能实现链表的构建。这里完全是为了分析才这么写的。从图中很容易看出蓝色的箭头组成了一个单链表,红色的箭头又组成了一个单链表(逆向的)。
下面将分析链表的前插与删除的例子,理解了这两个功能,其他的功能都能自己分析出来了。
双链表的前插,下面这是代码和代码分析。
void InsertBefore(student *p,char x)
{ //在带头结点的双链表中,将值为x的新结点插入*p之前,设p≠NULL
student *s = malloc(sizeof(student)); //申请一段内存空间,指针指向首地址0x0600
s->name = x; //定义name为G
s->prior = p->prior; // p->prior表示0x0500,将它赋给s->prior表示s->prior里面的值是0x0500,从而指向0x0500这个地址即q,如紫线
s->next = p; //p是0x0700,将它赋给s->next,s->next中的值为0x0700,也即s->next指向了p,如绿色线
p->prior->next = s; // p->prior 是0x0500,即指针q所指,所以p->prior->next相当于没插入s之前的0x0700,插入s后,将s的首地址即0x0600赋给这个位置,所以此时,由q 到p的蓝线断裂,这个蓝线目标变成了s,如黑线所示,此时q->next值为0x0600,图上没有改过来。
p->prior = s; //同理,p->prior也指向了s,即p->prior中0x0500变成了0x0600(图上没有改过来),红线断裂。变成墨绿色线。至此前插完成。
}

下面再分析删除,删除比较简单,代码如下:
void DeleteNode(student *p)
{ //在带头结点的双链表中,删除结点*p,设*p为非终端结点
p->prior->next=p->next; // 将p->next即0x0700送到q->next中,即0x0500被替换成了0x0700(图中没改过来),如紫线。
p->next->prior=p->prior; // p->prior为0x0300送到了s->prior即原本是0x0500的地方(图中没改过来),如绿线。
free(p); //将p内存释放,同时将之前的四根红蓝线全部断裂,至此完成删除任务。
}