Mycat ��һ����Դ�ķֲ�ʽ���ݿ�ϵͳ�������������������ݿ���Ҫ�洢���棬�� Mycat ��û�д� �����棬���Բ�������ȫ����ķֲ�ʽ���ݿ�ϵͳ�� ��ô Mycat ��ʲô��Mycat �����ݿ��м�������ǽ������ݿ���Ӧ��֮�䣬�������ݴ����뽻�����м�� ��

MyCAT ��ʹ�� JAVA ���Խ��б�д������ʹ��ǰ��Ҫ�Ȱ�װ JAVA ���л���(JRE),���� MyCAT ��ʹ���� JDK7 �е�һЩ���ԣ�����Ҫ������� JDK7 ���ϵİ汾�����С�
����
���� jdk

shell> wget --no-cookies \ --no-check-certificate \ --header \ "Cookie: oraclelicense=accept-securebackup-cookie" \ http://download.oracle.com/otn-pub/java/jdk/8u181-\ b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-\ x64.tar.gz ? // --no-check-certificate ��ʾ��У��SSL֤�飬��Ϊ�м������302�����https�����漰��֤������⣬��У���ܿ�һ�㣬Ӱ�첻��.
��ѹ�ļ�
shell> tar -xf jdk-8u181-linux-x64.tar.gz -C /usr/local/ shell> ln -s /usr/local/jdk1.8.0_181/ /usr/local/java
���û�������
shell> vi /etc/profile.d/java.sh export JAVA_HOME=/usr/local/java export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ע�� CLASSPATH ���и��� . ��Ҫʡ��
ʹ����������Ч
// �����ڵ�ǰ�� shell �Ự����Ч shell> source /etc/profile
ȫ����Ч��Ҫ��������
���� MyCat
����
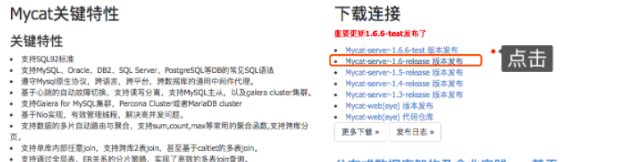
����������·�����ʾ�����ض�Ӧ�İ汾

shell> wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz ? ?
��ѹ
shell> tar -xf Mycat-server-1.6.6.1-release-20181031195535-linux.tar.gz -C /usr/local/ shell> ls /usr/local/mycat/ bin catlet conf lib logs version.txt ? ?
��ʶMyCat �еĸ���
���ܹ�ͼ
DBA ������ά��Ա�����ݽ��з�Ƭ����֮��ԭ�е�һ���⣬���з�Ϊ�����Ƭ���ݿ⣬���еķ�Ƭ���ݿ⼯ Ⱥ�������������������ݿ�洢��

����ͼ����ʾ�����ݱ��ֵ������Ƭ���ݿ��Ӧ�������Ҫ��ȡ���ݣ���Ҫ��Ҫ�����������Դ�����ݡ� ���û�����ݿ��м������ôӦ�ý�ֱ����Է�Ƭ��Ⱥ������Դ�л��������������ݾۺ϶���ҪӦ��ֱ�Ӵ� ����ԭ������רע��ҵ���Ӧ�ã����Ứ�����Ĺ�����������Ƭ������⣬����Ҫ����ÿ��Ӧ�ô���������ȫ�� �ظ������ӡ� �����������ݿ��м����Ӧ��ֻ��Ҫ������ҵ������������ͨ�õ����ݾۺϣ���������Դ�л������м� �����������м���������봦��������ֱ�Ӿ���Ӧ�õĶ�д���ܣ�����һ��õ����ݿ��м��������Ҫ��
����(schema)
ͨ����ʵ��Ӧ����˵��������Ҫ֪���м���Ĵ��ڣ�ҵ����Աֻ��Ҫ֪�� ���ݿ�ĸ���������ݿ��м�����Ա�������һ���������ݿ⼯Ⱥ���ɵ����⡣
���Ƽ���ʱ�������ݿ��м�������Զ��⻧����ʽ��һ������Ӧ���ṩ����ÿ��Ӧ�÷��ʵĿ�����һ�� ���������ǹ����������⣬�������簢�������ݿ������ RDS��

������table��
��Ȼ�����⣬��ô�ͻ����������ֲ�ʽ���ݿ��У���Ӧ����˵����д���ݵı������������������� ���������зֲֺ���һ��������Ƭ���У�Ҳ���Բ��������з֣�����Ƭ��ֻ��һ�������ɡ�
��Ƭ����(rule)
�����з֣�һ��������ֳ����ɸ���Ƭ��������Ҫһ���Ĺ�����������ij��ҵ���������ݷֵ� ij����Ƭ�Ĺ�����Ƿ�Ƭ���������з�ѡ����ʵķ�Ƭ����dz���Ҫ��������ı���������ݴ������Ѷȡ�
���� MyCat
��ʶ�����ļ�
MyCAT Ŀǰ��Ҫͨ�������ļ��ķ�ʽ������������������:
/usr/local/mycat/conf/server.xml�����û��Լ�Mycatϵͳ��ر�������˿ڵȡ������û���Ϣ��ǰ��Ӧ�ó������� mycat ���û���Ϣ��
/usr/local/mycat/conf/schema.xml�������⣬������Ƭ����ʵ��ֱ�ӵ�ӳ���ϵ�����ݡ�
/usr/local/mycat/conf/rule.xml
�ж����Ƭ����
���� server.xml
����Ϊ����Ƭ��
������û���������Ӧ�ó������ӵ� MyCat ʹ�õģ������Զ�������
�����е�schemas ����������Ӧ��ֵ�������ݿ�����֣�Ҳ�����Զ��壬�������������Ҫ�ͺ��� schema.xml �ļ������õ�һ�¡�
shell> vim server.xml
<user name="mycatdb">
<property name="password">123456</property>
<property name="schemas">schema_shark_db</property>
<!-- ���� DML Ȩ������ -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<!--��������һ���û����������õķ��� TESTED �����ݿ��Ȩ���� ֻ��
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
-->
==����������У������������û����ʵ����⣬��ô������ schema.xml �ļ���Ҳ����������⣬���������� mycat ʧ��==
���� schema.xml
�����������ļ��е�ÿ�����ֵ����ÿ��
����ͷֱ�����
<schema name="schema_shark_db" // ��������
checkSQLschema="false" // �����
sqlMaxLimit="100" // ���������
dataNode='dn1'> // ���ݽڵ�����
<!--���ﶨ����Ƿֱ�����Ϣ-->
</schema>
���ݽڵ�
<dataNode name="dn1" // �����ݽڵ������
dataHost="localhost1" // ������
database="shark_db"> // ��ʵ�����ݿ�����
</dataNode>
������
<dataHost name="localhost1"
maxCon="1000" minCon="10" // ����
balance="3" // ���ؾ���
writeType="0" // дģʽ����
dbType="mysql" dbDriver="native" // ���ݿ�����
switchType="1" slaveThreshold="100">
<!--����������ù������������ij�Ա��Ϣ���������Щ�����Ľ���������-->
</dataHost>
�������
<heartbeat>select user()</heartbeat>
�����
<writeHost host="hostM1"
url="172.16.153.10:3306"
user="root" password="123">
<!-- can have multi read hosts -->
<readHost host="hostS2"
url="172.16.153.11:3306"
user="root" password="123"
/>
<readHost host="hostS2"
url="172.16.153.12:3306"
user="root" password="123"
/>
</writeHost>
���������Ϊ�����������ļ���������һ��һ�ӵļܹ�
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="schema_shark_db"
checkSQLschema="false"
sqlMaxLimit="100"
dataNode='dn1'>
<!--���ﶨ����Ƿֿ�ֱ�����Ϣ-->
</schema>
<!--���������ö�д�������Ϣ-->
<dataNode name="dn1"
dataHost="localhost1" database="shark_db">
</dataNode>
<dataHost name="localhost1"
maxCon="1000" minCon="10"
balance="3" writeType="0"
dbType="mysql" dbDriver="native"
switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.16.153.10:3306"
user="mycat" password="QFedu123!">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="172.16.153.11:3306"
user="mycat" password="QFedu123!" />
</writeHost>
</dataHost>
</mycat:schema>
���� log4j2.xml
<!--������־����Ϊ debug , Ĭ���� info-->
<asyncRoot level="a" includeLocation="true">
���� mycat
shell> /usr/local/mycat/bin/mycat start ? ֧��һ�²��� start | restart |stop | status
����ʵ�� master ���ݿ��ϸ��û���Ȩ
mysql> grant all on *.* to 'mycat'@'%' identified by 'QFedu123!'; mysql> flush privileges;
����
�� mycat �Ļ����ϲ����û�Ȩ����Ч��
�����Ƿ���������¼�� ��������
shell> mysql -umycat -p'QFedu123!' -h172.16.153.10 ?
���������Ƿ��ܵ�¼�ϴӷ�����
shell> mysql -umycat -p'QFedu123!' -h172.16.153.11
ͨ���ͻ��˽��в����Ƿ��ܵ�¼�� mycat ��
172.16.153.162 �� mycat ��������ַ
ע��˿ں��� 8066
shell> mysql -umycatdb -p123456 -P8066 -h172.16.153.162
mysql> show databases;
+-----------------+
| DATABASE |
+-----------------+
| schema_shark_db |
+-----------------+
1 row in set (0.00 sec)
�������Զ�д�������
ʹ�� mysql �ͻ��˹���ʹ�� mycat ���˻��������¼ mycat , ֮��ִ�� select ��䡣
[root@master mycat]# mysql -umycatdb -p'123456' -P 8066 -h 172.16.153.162
mysql> show databases;
+-----------------+
| DATABASE |
+-----------------+
| schema_shark_db |
+-----------------+
1 row in set (0.00 sec)
mysql> use schema_shark_db;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select name from t1 where name='shark';
+-------+
| name |
+-------+
| shark |
+-------+
1 row in set (0.01 sec)
mysql>
֮���ѯ mycat ������ mycat ��װĿ¼�µ� logs/mycat.log ��־��
����־��������ѯ�������߲�ѯ �ӿ�� ip ��ַ��Ӧ����������
[root@master mycat]# pwd /usr/local/mycat [root@master mycat]# grep 'name' logs/mycat.log|grep 122.161

����
ERROR | wrapper | 2019/06/23 22:52:15 | Startup failed: Timed out waiting for a signal from the JVM. ERROR | wrapper | 2019/06/23 22:52:15 | JVM did not exit on request, terminated
���ļ� conf/wrapper.conf
wrapper.startup.timeout=300 //���r�r�g300�� wrapper.ping.timeout=120
���ڸ��ؾ���Ͷ�д���������
balance ����
���ؾ�������,Ŀǰ��ȡֵ�� 3 ��:
1. balance="0", ��������д�������,���ж����������͵���ǰ���õ� writeHost �ϡ�
2. balance="1", ȫ���� readHost �� writeHost ���� select ���ĸ��ؾ���,��˵,��˫ ��˫��ģʽ(M1->S1,M2->S2,���� M1 �� M2 ��Ϊ����),���������,M2,S1,S2 ������ select ��� �ĸ��ؾ��⡣
3. balance="2", ���ж�������������� writeHost��readhost �Ϸַ���
4. balance="3", ���ж���������ķַ�����Ӧ�� readhost ִ��,writerHost �� ������ѹ��,ע�� balance=3 ֻ�� 1.4 �����Ժ�汾��,1.3 û�С�
writeType ����
1. writeType="0", ����д�������͵����õĵ�һ�� writeHost,��һ�������л���������ĵڶ��� writeHost,�������������л����Ϊ.
2. writeType="1",����д����������ķ��͵����õ� writeHost,#�汾1.5 �Ժ���������Ƽ���
����:
ʵ�ֶ�д���������
balance="3"
writeType="0"