A novel binary shape context for 3D local surface description
����Ŀ¼
- A novel binary shape context for 3D local surface description
- 2 BSC for 3D local surface description
- 2.1 Binary shape context descriptor In
- 2.1.1. Adaptive-scale keypoint detection
- 2.1.2. Local reference frame construction
- 2.1.3. Local surface coordinate transformation
- 2.1.4. Projection-feature calculation
- 2.1.5. Projection features difference test
- 2.2 BSC generation parameters
�����popSLAM��
Binary Shape Context (BSC) descriptor
������������������
2 BSC for 3D local surface description
2.1 Binary shape context descriptor In
2.1.1. Adaptive-scale keypoint detection
�������еĵ��ƣ���ÿ��������r�������ڣ�����Э�����PCA�ֽ�֮������������ֵ������ı�ֵ�Ƚϴ�ʱ����Ϊ�������㡣
һ�仰������Щ�ֲ���ĵ㡣
2.1.2. Local reference frame construction
LRF�Ĺ���������Ҫ���塣
- ��ת������
- ������ͨ����������������������
Э�������ļ�����ͨ�������㣬ȡ������r�ڵĵ�������
��������
����������Ϊ���ĵ������뾶������һ��ȷ����
���㼯�ϣ���ǰ��� ���������� ,�������ǰ뾶r�ڵ����е㡣m����Χ�ĵ��������
- ���ڵ㼯�ij������������еĵ㣬��������Ȩ�أ��ֱ��� ,
����

��Ȩ�����ڲ����仯�ĵ��ܶȣ���˵��ܶȵ͵������еĵ���ܶȸߵ������еĵ㹱����
����
������ĸ��ʾΪ���ڰ뾶
�ķ�Χ�ڵĵ��������
��ˣ�����һ���ܶȱȽϴ�ĵ���˵�����ķ�ĸ��ܴ���͵��������ܶ�ϵ����С�����ܶ�С�ĵط�����ĸҲС����Ӧ���������ܶ�Ȩ�ؾͻ���
Ŀ�ģ�Ϊ���ܹ����õĴ�ȫ��������
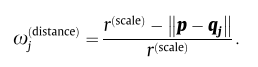
p�������㣬q��������ԽԶ�� �������Խ����ԽС��Ȩ��ԽС��
���Ը�Ȩ�غ;���ɷ��ȡ�ԽԶ��Ȩ��ԽС��
- �����������
�ļ��㣬��ֿ��ǵ�����������Ȩ�صIJ��룺
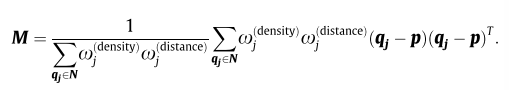
Ȼ��˵���������������Ķ����ԡ���ȥ�ķ����ʹ�������˵����ƣ����ǰ����Աȣ�ѡȡ������ŵĽ⡣
2.1.3. Local surface coordinate transformation
����Ƚϼ����ǰѼ�������ľֲ�����ת����(0,0,1)(0,1,0)(0,0,1)����ϵ�¡�Ϊ�˺�������XoY����ƽ���ϵ�ͶӰ������
2.1.4. Projection-feature calculation
��ת����������ϵ�µĵ��ƽ���ͶӰ��xy xz yz ����ƽ�档
ԭʼ�ĵ㼯��N
��һ����������ĵ㼯��N��
�ֱ�������ƽ����ͶӰ��
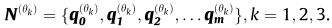
����µ������㼯��
ͶӰ��դ��ΪS��S��Ķ�άƽ�档
��������ͨ���ۻ���Ӧ��Ԫ��ÿ��������������ÿ����Ԫ��ͶӰ���ܶ�������ͶӰ���������
ע�⣬��ͼ4��ʾ��ֱ���ۻ��ڽ������Ӧ�����ᵼ�����������ԡ��߽�ЧӦ��LRF�Ŷ���
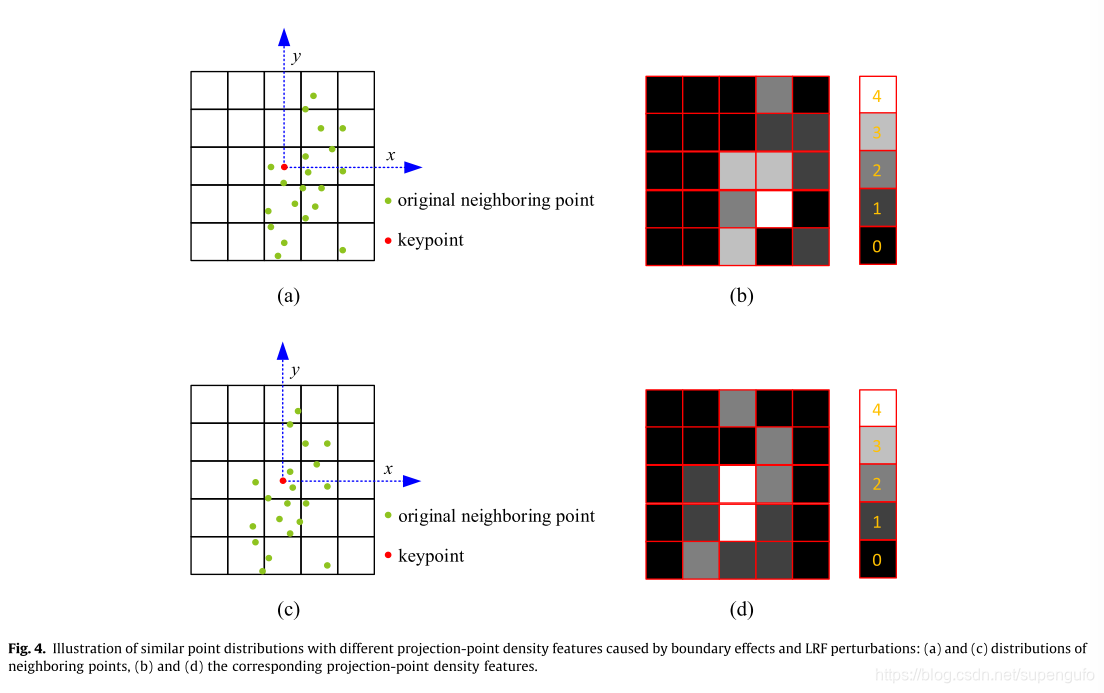
��ߵ��ǵ��ͶӰ�ֲ����ұߵ��Ƕ�Ӧ��ͶӰ���ܶ�������ֱ���ۼ�ÿ��դ���������˶��ٸ��㡣
�������ܶȾ�����һ����������Ǹõ㵽ƽ��ľ���
���Կ����ֲ����ƣ�����ʵ�ʼ�������� ͶӰ�ܶ��������ܴ�
���������������ˡ���˹���ܶȹ��ơ�������ÿ����ļ�ȨͶӰ�ܶȺ;���
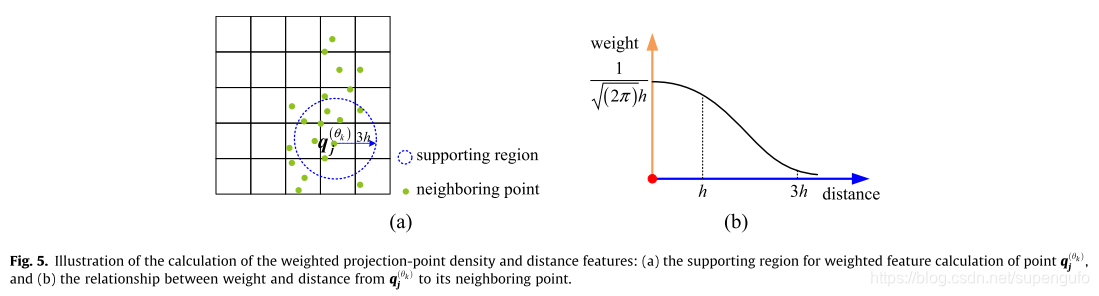
�����ʽ��ֱ��������Ǹõ����Χ��ÿһ�����һ������ϵ����������Ϊ0ʱ�������ۼ� ��Ȼ�������ݼ���
���Ȩ���㹫ʽ���£�
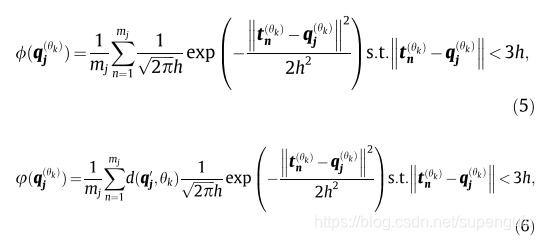
(5)���õ����ȨͶӰ�ܶ�ֵ
(6)���õ����ȨͶӰ����ֵ
Ҫ��ĵ��3h��Χ���������е㡣
��ʡ�Լ�����ʽ��
��ĿǰΪֹ�����Ϲ�ʽ���Ǽ����ÿ����ľ���Ȩ�غ��ܶ�Ȩ�ء���ô���ͶӰ��ƽ���Ի�����ֺڰ�դ��ͼ�أ�������ʾ��
������Ҫע����ǣ���������IJ��������еĵ�ֻ���������ԣ�һ���Ǿ���Ȩ�أ�һ�����ܶ�Ȩ�ء��������դ���ϵ�ͶӰ�����Ǽ���ÿ��դ���ϵ�������Ȩ��ֵ��
Ȼ��Ϳ��Լ���ÿһ��դ��ļ�ȨͶӰ�� **�����������ܶ�������**���㹫ʽ���£�
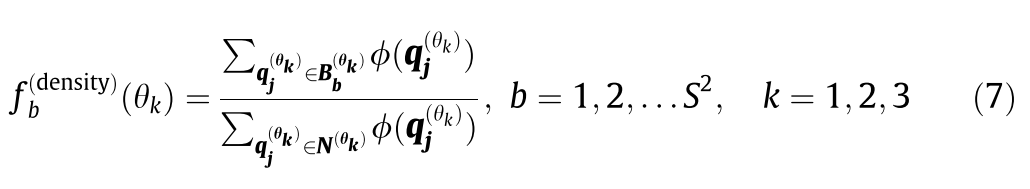
q�ǵ�Bb�ǵ�ǰ���bin�ļ���
����ط��൱���Ƿ��ӷ�ĸ��һ����
��ĸ�Ǽ��㵱ǰƽ�������еķ�Χ��3h���ڵĵ㼯��Ȩ�غ͡�
������ֻ���㵱ǰդ���ڵĵ��Ȩ�غ͡�
Ȼ�����μ��� ��դ��
����Ȩ�صļ�����ͬ��
��Ҫ˵�����ǣ����ַ�����������������ἰ�ı߽����⣬��������Ư�����⡣���ܹ�������Ƶķֲ������ǵ��Ƶ��ܶȲ�ͬ������������ͶӰ���������Ƶġ�
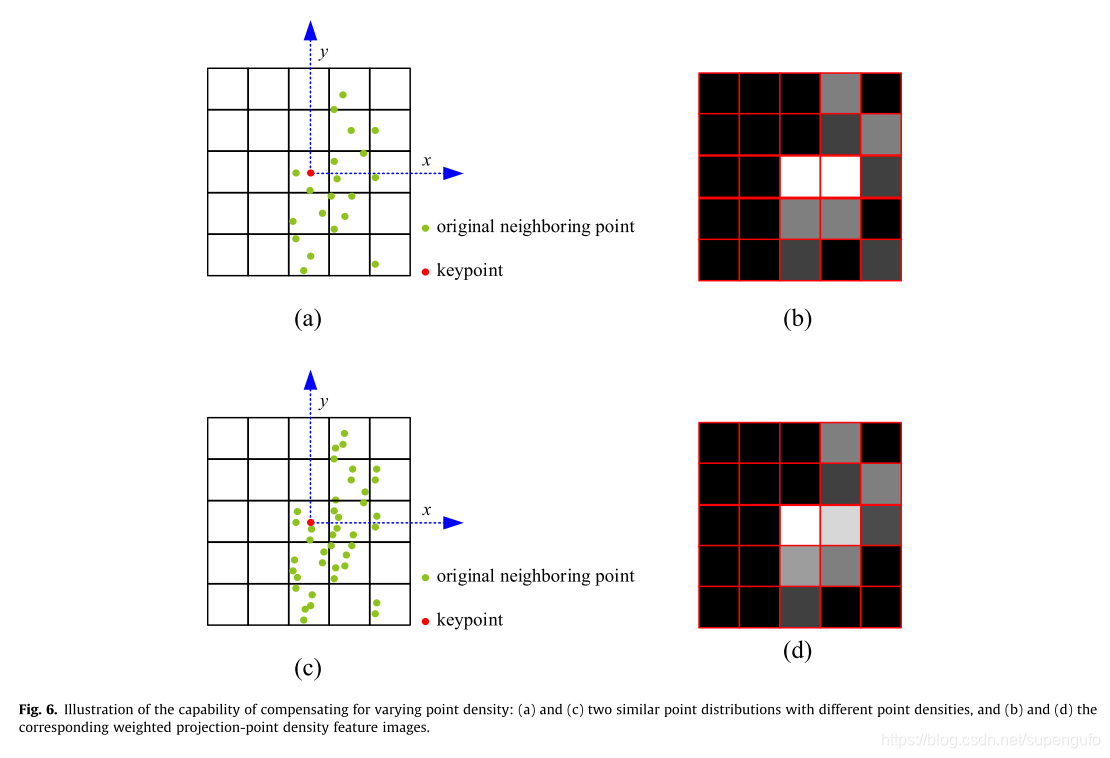
Ȼ����Ϊ�˿��ӻ�ÿһ��դ��������һ�� ����ͼ��
�����ʽ�����������ļ��㣬ֻ��Ϊ�˵�������ʾʹ��
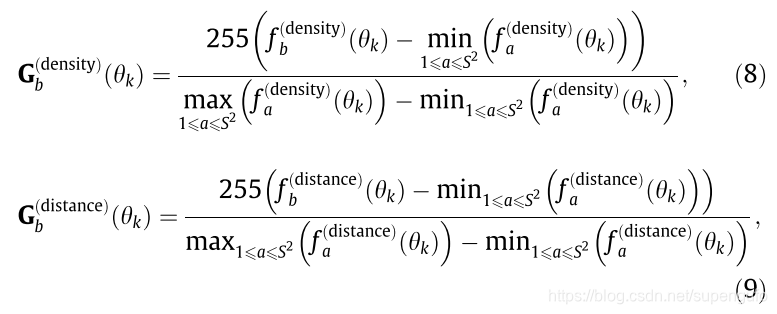
������G�������ļ���Ҷ�ֵ��
���з�ĸ��max-min ������f-fmin������������һ����
Խ���ĵط���Խ�ࡣ�����Ҷ�ֵԽ�ߡ�����ӳ��0������ɫ��
2.1.5. Projection features difference test
������ֵ��
Ŀ�ģ�������ֵ������������������洢��ƥ���Ч�ʣ�������ģ�������ݿ�������Ŀ����ȡ���������������������Բ���ʵ������ͶӰ�����Ķ�ֵ������������������ѡ���������Ӳ��������������IJ����ԣ��������֮������������죬��ô���Խ��Ϊ1������Ϊ0������ÿ��ͶӰ���ϵ�N�����ӣ�����C_2_N��N�����ӣ�������ԣ��ֲ����Բ��ԣ������и��ӵ������꾡��Ͻ��в�����Էdz���ʱ������������ά���ߡ��ڴ�Ч�ʵ͡�ʵ���з��֣��������Բ��Ե�������Сʱ����������������������������ӵı�����������һ�����������������������������κ���Ҫ����Ϣ����ˣ���C_2_N�ֲ����Բ��������ѡ��һ���������Ӽ������ڲ����������ӱ���������ǰ���£�����ʱ����ڴ����ġ�
��xoy ͶӰ���ϵ�ͶӰ��������Ϊ������ϸ�������ֵ���ķ���:
- �� ������У����ѡ�� ��bins�����һ������ ������ʾ��
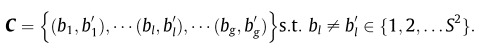
����ط�����˼�ǣ��� ��bins���棬�漴��ѡһ�����Ӽ������в����Բ��ԡ�
Ȼ�������������Ҫ�Աȵ�������һ����دһ������د������������Ӧ��bin������ֵ�IJ�ֵ���㡣
ѡȡg����
Ҳ����˵���������������ڽ��жԱȵ�ʱ����ֻѡһ����bin�����жԱȣ��ŵ���2����
1.���ټ��������ڴ�����
2.һ��������bins���Ѿ��㹻���ﵱǰ�����ˡ�
- �Լ����е�������������
����һ�¹�ʽ���в����Բ��ԡ���ͶӰ����ת��Ϊһ���������ַ�����
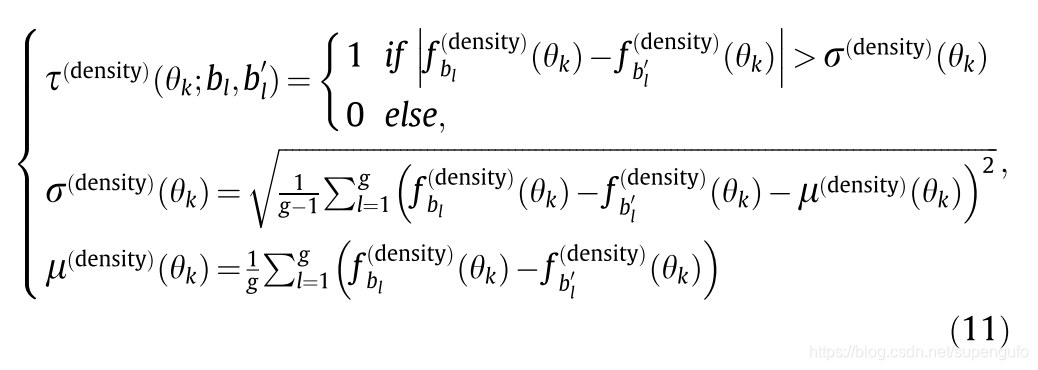
�����ʽ(11)��Ҫ�������Ͽ���
�������˼�ǣ����� ��դ����ȫ����������ԣ��������ѡ��һЩ���м��㣬Ȼ�����������
������Լ����Լ�ƥ�䡣�����ѡ�ԣ������һ����ֵ��Ȼ��ÿ��pair���������������ֵ��ȷ����
��ͬ�������ӣ���Ϊƥ�����Ե�index�ǹ̶��ģ���������������Ķ������ַ���Ҳ��һ���ġ������ǿ�����Բ��˵�ġ�
2.2 BSC generation parameters
�����ǹ��ڸ�����������ô��õġ����ﲻ��չ������