ggplot2 快速入门:基础图形作法
一、实验介绍
1.1 实验内容
从课程《R 语言快速入门》 中,我们已经了解过 Hadley Wickham 的 tidyverse 生态链,知道了完整的数据分析大约包括以下流程:

Source: Hadley Wickham, R for Data Science, 2016. 可视化(Visualise)不仅是数据探索(Explore)中至关重要的一个环节,而且充满趣味和成就感(所见即所得)。我们既可以用图形来验证猜想,也可以从图形中发现不为人知的秘密。因此,从基础的可视化工具开始接触数据科学通常是一个不错的选择。本课程即将带你感受 R 最受欢迎的作图工具包 ggplot2 的魅力,为你的数据科学之路奠定一个良好的开端。 通过本课程的学习,你将
- 理解
ggplot2基本思想和图形语法 - 使用
ggplot2画出优雅的散点图、折线图、柱状图、箱线图等常用图形
1.2 实验知识点
ggplot2- 附加变量
- 几何对象
- 统计变换
- 坐标系
1.3 实验环境
- R 3.4.1
- Xfce 终端
1.4 适合人群
本课程难度较小,适合已经掌握 R 基本语法,想了解 ggplot2 作图方法和入门数据科学的朋友。
二、实验内容
2.1 ggplot2
R 语言包含多种作图工具,每种工具自有一套逻辑体系,ggplot2 则凭借它的优雅与灵活受到大部分数据科学家的喜爱。 在 2.1 节中,你将理解 ggplot2 作图的基本思想,拥有一套完整的语法模版,从模版中你将得知一个图形的要素有哪些。此外,如果你只是想迅速获得对数据的直观感受,我们还将介绍简化的作图方法。
2.1.1 基本思想
我们先进入一个实例,一边应用 ggplot2 中的函数,一边探索它的基本思想。 打开桌面上的 Xfce 终端,从云端下载实验所需数据。car.csv 文件中保存了 2011 年中国各地区每百户家用汽车保有量数据。
$ wget http://labfile.oss.aliyuncs.com/courses/978/car.csv

进入 R 环境
$ sudo R

ggplot2 是 tidyverse 生态链的核心 package,因为实验环境中已经安装有 tidyverse package,所以我们可以直接加载它。如果你是在 RStudio 中操作,记得先用 install.packages() 命令安装 tidyverse。
> library(tidyverse)

上图中,虚线以上部分是 tidyverse 包含的核心 package,虚线以下部分是 tidyverse 和其它 package 冲突的函数,使用这些函数时需要指明来源。接下来我们使用 tidyverse 中的 read_csv() 函数读取实验数据,并保存在 da 中。
> da <- read_csv('car.csv')

值得注意的是,read_csv() 的结果是一个 tibble 对象,tibble 本质上也是 data frame 的一种,行为观测值,列为变量,但和 R 中常见的 data.frame 不同,它有许多良好的性质。比如,我们想查看 da 变量的结构或者前几行,不需要再用 str() 或 head() 函数,而是直接运行 da 就可以了。tidyverse 中大部分数据都是 tibble 结构。
# 查看 da
> da

从上图中我们可以看到,da 是一个 31 行、6 列的 tibble 对象,它的前 10 行被呈现出来。6 个变量依次为省份(或直辖市)、地区(E 为东部、M 为中部、NE 为东北、W 为西部)、家用汽车每百户平均保有量、人均GDP、城镇人口比重、交通工具消费价格指数,变量类型前两个为 char、后四个为 double。关键信息只需一个小小的命令就能被呈现出来,这就是 tibble 人性化的地方。 至此,准备工作已经做好,下面我们就来探索 ggplot2的基本思想。 假设我们想观察各省市家用汽车平均保有量和人均 GDP 之间有什么关系,我们可以作出 car 随 GDP 变动的散点图。 Step 1:
ggplot(data = da)

只定义数据参数data,此时 ggplot() 生成一张空白的画布。
Step 2:
ggplot(data = da, mapping = aes(x = GDP, y = car))
除 data 外,还定义了映射参数 mapping,将 GDP 映射到 x 轴,car 映射到 y 轴,此时图形有了坐标轴。
Step 3:
ggplot(data = da, mapping = aes(x = GDP, y = car)) + geom_point()
除数据和映射参数外,还使用 geom_point() 添加了几何对象,此时图中出现了散点,这些点的分布表示平均汽车保有量和人均 GDP 之间似乎存在正相关关系。 从以上三个分解的步骤中,我们可以体会到 ggplot2 作图的逻辑,即它需要使用一定的几何对象(点、线等)来表示整理好的数据,并且在数据和图像属性(如 x、y轴,颜色,形状等)之间建立一定的映射。
Step 3 中的命令还可以简写为
# 默认 ggplot 的第一个参数为 data,第二个参数为 mapping,aes的第一个值为 x 轴,第二个值为 y轴。
ggplot(da, aes(GDP, car)) +geom_point()
或改写为
# mapping 的参数设定仅在 geom_point() 中使用
ggplot(data = da) +geom_point(mapping = aes(x = GDP, y = car))
2.1.2 语法模版
从 2.1.1 节的尝试中,我们可以总结出 ggplot2 的一套语法模版:
ggplot(data = <DATA>) + <GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))
通过后续的学习,你将得到更加完整的语法模版:
ggplot(data = <DATA>) + <GEOM_FUNCTION>(mapping = aes(<MAPPINGS>),stat = <STAT>,positon = <POSITION>,) + <COORDINATE_FUNCTION> + <FACET_FUNCTION>
2.1.3 图形要素
从完整的语法模版中,我们得知 ggplot2 图形有以下要素:
- 数据
- 几何对象
- 属性映射
- 统计转换
- 位置调整
- 坐标系
- 块面结构
你将在接下来的实验中陆续接触到这些概念。
2.1.4 快速图形作法
如果我们只是想用最少的代码迅速获得对数据的直观感受,可以使用 qplot() 函数。
qplot(GDP, car, data = da)

尽管 qplot() 看起来更简洁,而且理论上可以实现所有 ggplot() 的功能,但是随着图形变得更加复杂,ggplot() 将是一个更好的选择。
2.2 附加变量
从 2.1 节的散点图中,我们似乎找到了 car 和 GDP 的一种正相关关系,这是两个变量之间的关系。 但是,考虑一下,如果我们想往二维图形中添加第三个变量,比如我们想知道各个样本点分别属于什么地区,或者想看不同地区的 car 和 GDP 之间的关系,应该怎么做呢? 两个坐标轴已经被固定了,第三个变量只能通过其它途径反映出来。接下来我们介绍两种途径,一种是属性映射,即把第三个变量作为某种属性赋给图形,另一种是块面图,即按照第三个变量进行分组,在不同组中呈现前两个变量之间的关系。属性映射和块面图都体现了一种分组的思想,只是前者是隐性的,后者是显性的。
2.2.1 属性映射
我们将第三个变量 region 赋值给 color,geom_point() 就会自动把观测值按照 region 分组,每组用不同颜色的点在画布上标出。
ggplot(data = da) +geom_point(mapping = aes(x = GDP, y = car, color = region))

从上图中可以看到,东部省份盘踞在右上角,人均 GDP 和平均汽车保有量都很高,中西部省份则蜷缩在左下角,这体现了我国地区间经济发展的不平衡,共同富裕的发展路线只实现了前面一半,我国仍然处于社会主义初级阶段。 我们把省份名称标注在图上,看看能不能得出更有意思的结论。
ggplot(da, aes(GDP, car)) +geom_point(aes(color = region)) +geom_text(aes(label = province), check_overlap = TRUE)

check_overlap = TRUE 省略了某些省份的名称,保证文本不会有重叠。 从图中来看,最右上角的点毫无疑问是北京。天津和上海两个城市比较特别,拥有很高的人均 GDP,家用汽车平均保有量却相对较低。对这个现象,我们可以做出许多猜想:影响汽车保有量的是否有其它更重要的因素?人均 GDP 是名义值(未经价格调整),也许这两个城市的物价水平很高,导致实际 GDP 较低。或者,这两个城市的其它交通工具较为发达、交通堵塞严重需摇号购车,家用汽车不是人们的首选出行工具…… 左上角的西藏和云南也十分引人注目,它们拥有较低的人均 GDP,家用汽车保有量却相对较高,我们可以猜想,这两个省份地广人稀,家用汽车是必要的出行工具…… 图形启发我们进行了这些猜想,它们不一定正确,需要我们进一步设计研究,但我们已经可以感受到数据可视化的力量。
除了 color,geom_point() 还有其它一些属性,比如点的形状(shape)、透明度(alpha)、大小(size)等。
ggplot(data = da) +geom_point(mapping = aes(x = GDP, y = car, shape = region))

你可以使用 ?geom_point 命令查看帮助文档中的 Aesthetics,获取更多属性。
2.2.2 块面图
另一种增加变量的方法是块面图,我们使用 facet_wrap() 将观测值按照 region 分组,就可以看到不同地区的 car 和 GDP 之间的关系了。
ggplot(data = da) + geom_point(mapping = aes(x = GDP, y = car)) + facet_wrap(~ region, nrow = 2)

除了 facet_wrap() 以外,ggplot2 中还有 facet_grid() 函数可以画块面图。你可以在帮助文档中看它们有什么不同。
2.3 几何对象
至今我们接触到的 ggplot2 中的几何对象有点和文本,除了这两个以外较为常用的还有线。下面我们分别来看散点图和折线图。
2.3.1 散点图
上面实验我们画的大多数都是散点图,因此无需赘述,但有种情形值得引起注意。 如果我们面临的是大样本,看看会发生什么。
# mpg 是 tidyverse 中一个内置的数据集,共 234 行,11列
ggplot(data = mpg) +geom_point(mapping = aes(x = displ, y = cty))

数一数会发现,图中点的个数小于 234,这叫做 “overplotting” 问题,有些点被临近的点覆盖掉,而且所有点看起来分布得十分均匀。 如果我们想获得更贴近现实(数据)的散点图,可以设置 position = 'jitter'。
ggplot(data = mpg) +geom_point(mapping = aes(x = displ, y = cty), position = 'jitter')

2.3.2 拟合曲线
使用 geom_smooth 获得一条拟合观测值的曲线:
ggplot(data = da) +geom_smooth(mapping = aes(x = GDP, y = car))

在图中同时呈现散点和拟合的曲线,并且令 se = FALSE 去掉曲线的置信区间:
ggplot(data = da) +geom_point(mapping = aes(x = GDP, y = car)) +geom_smooth(mapping = aes(x = GDP, y = car), se = FALSE)
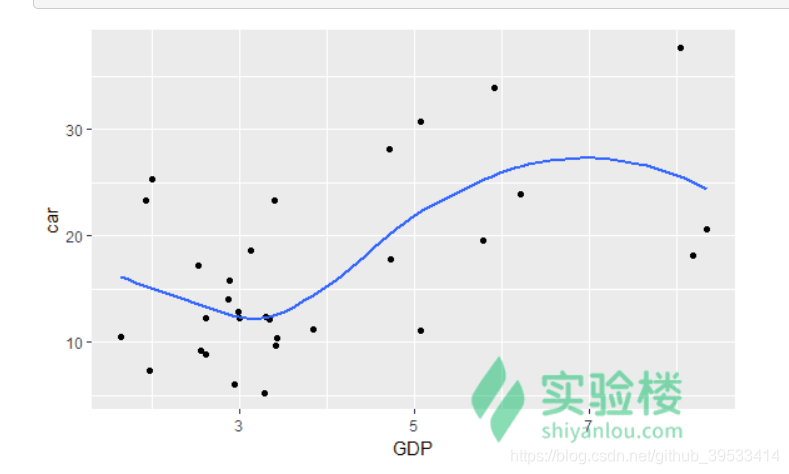
令 method = 'lm' 获得拟合的直线
ggplot(data = da) +geom_point(mapping = aes(x = GDP, y = car)) +geom_smooth(mapping = aes(x = GDP, y = car), se = FALSE, method = 'lm')

2.3.3 折线图
使用 geom_line() 画折线图:
ggplot(data = da) +geom_line(mapping = aes(x = GDP, y = car))
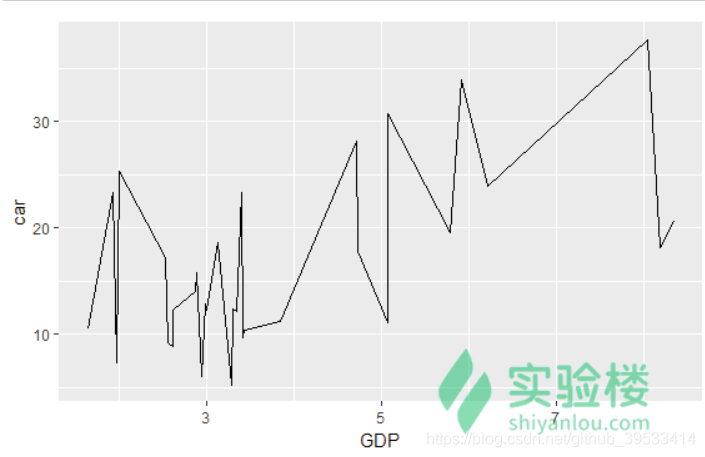
这样的图看起来没有任何意义。事实上,在时间序列数据的可视化时使用 geom_line() 会比较合适。 economics 也是 tidyverse 的内置数据集,我们画出失业率随日期变动的折线图:
ggplot(data = economics) +geom_line(mapping = aes(x = date, y = unemploy/pop))

2.3.4 图层叠加
在前面的实验中,你已经接触了一些图层叠加的操作,比如带有拟合曲线的散点图、标注文本的散点图等。 图层叠加是 ggplot2 中一个非常重要的理念,正是它让 ggplot2 变得灵活,让我们可以不拘泥于固定的图例设置,自有地创造出想要的图形。 下面我们再来看一个例子,这个例子让点和曲线的颜色都根据 region 进行了分组:
ggplot(da, aes(GDP, car, color = region)) +geom_point() +geom_smooth(se = FALSE)

需要说明的是,为了简化实验,我们用的是 2011 年的截面数据,因此样本量较小,分组后每组包含的样本就更少了,这样拟合出来的曲线毫无说服力(因此你会看到 There were 11 warnings 的警告信息)。在正式研究中,我们也许会采用面板数据(panel data)扩大样本容量。 为了更加熟练地掌握图层叠加操作,请尝试画出课后练习中的图形。
2.4 统计变换
无论是散点图还是折线图,我们都能在图形上看出原始数据来,统计变换则不同,它需要先进行一定的统计操作,再把结果反映在图形上。
2.4.1 柱状图
对观测值进行分类统计,我们可以用 geom_bar() 画出柱状图。柱状图只需要指定 x 坐标(离散的分类变量),另一个坐标为 count(计数)。
ggplot(da) +geom_bar(mapping = aes(x = region))

有时候我们拿到的并不是原始数据,而是已经分类计数好的数据,这时候应该怎么办呢? 假设 demo 是我们拿到的数据,通过令 stat = 'identity',可以画出和上面一样的柱状图来。
demo <- tribble(~region, ~freq,"E", 10, "M", 6, "W", 12, "NE", 3
)ggplot(demo) +geom_bar(mapping = aes(x = region, y = freq), stat = 'identity')
2.4.2 直方图
假设我们想统计的变量不是离散的,而是一个连续变量,这时候就可以用 geom_histogram() 画直方图。
ggplot(da, aes(GDP)) +geom_histogram(binwidth = 0.5)

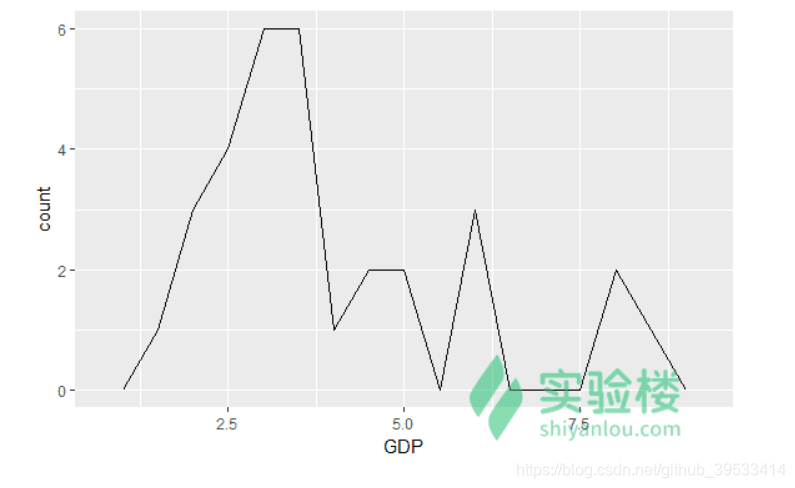
注意设置合适的 binwidth 很重要,你需要根据不同的数据尝试多个 binwidth,选择一个最合适的。 除了直方图外,我们也可以用 geom_freqpoly() 画频率折线图,它与直方图的功能基本一致。
ggplot(da, aes(GDP)) +geom_freqpoly(binwidth = 0.5)
2.4.3 箱线图
箱线图很受统计学家喜爱,因为它以尽可能简单的方式直观地反映了许多数据特征。下图展现了从数据的实际分布到箱线图的过程。
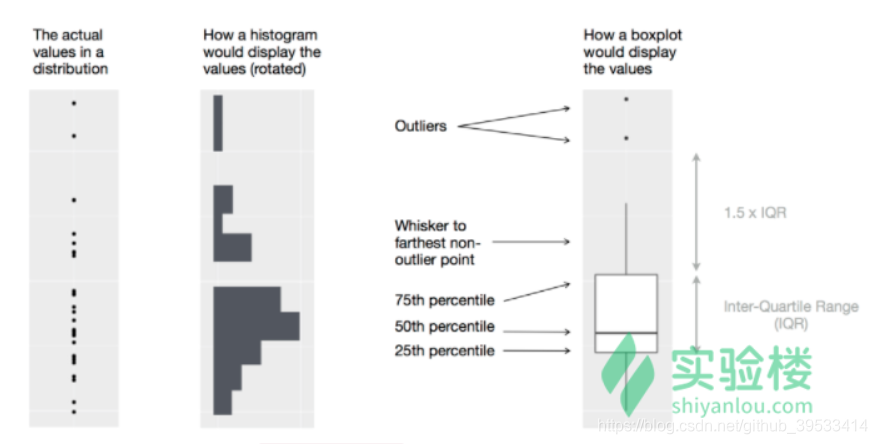
Source: Hadley Wickham, R for Data Science, 2016. 我们使用 geom_boxplot() 画箱线图:
ggplot(da, aes(region, GDP)) +geom_boxplot()

2.5 坐标系
2.5.1 坐标标签
我们可以使用 xlab()、ylab() 函数为坐标轴添加标签:
ggplot(da, aes(GDP, car)) +geom_point() +xlab('Per Capita GDP') +ylab('Car Ownership (%)')

如果想去掉坐标轴标签,可使用 xlab(NULL)、ylab(NULL):
ggplot(da, aes(GDP, car)) +geom_point() +xlab(NULL) +ylab(NULL)

2.5.2 坐标范围
如果我们只想看人均 GDP 在 2 至 4 之间,平均汽车保有量在 10 至 20 之间的省份,可以使用 xlim()、ylim() 函数限定坐标轴范围:
ggplot(da, aes(GDP, car)) +geom_point() +xlim(2, 4) +ylim(10,20) +geom_text(aes(label = province), check_overlap = TRUE)

2.5.3 交换坐标和极坐标
如果我们想交换横纵坐标,可以使用 coord_flip() 函数。特别是当我们在画柱形图或箱线图,横坐标刻度标识很长时,可以交换横纵坐标,这样文字就不会挤在一起。 我们还可以使用 coord_polar() 将笛卡尔坐标系转化为极坐标系。
bar <- ggplot(da, aes(region)) +geom_bar(mapping = aes(fill = region), show.legend = FALSE, width = 1) +xlab(NULL) +ylab(NULL)bar + coord_flip()
bar + coord_polar()


三、课后练习
请尝试画出如下图形(将代码和截图保存在实验报告中):
1. 
2. 
3.

4. 
四、总结
本实验介绍了 ggplot2 作图的基本思想和语法模版,通过实例展示了如何使用 ggplot2 画出优雅的散点图、折线图、柱形图、直方图、箱线图等基础图形,对其中蕴含的映射理念和图层思想做了详细的讲述。